










大家在使用大语言模型(例如 Qwen、DeepSeek)时,细心的用户可能会留意到这样一个现象:直接向模型传入一张图片,所获得的结果往往比单纯输入文字时更贴合我们的预期。
这背后的原因是什么?因为现在的多模态视觉-语言模型(例如:Qwen2.5-VL)能很好地把图像和文字关联起来,图像直观且包含的信息量大,再加上模型经过大量图文数据的训练,还针对图像任务进行了优化,这正好符合咱们人类更习惯通过看图来理解的认知特点。
多模态视觉-语言模型
多模态视觉-语言模型是什么?
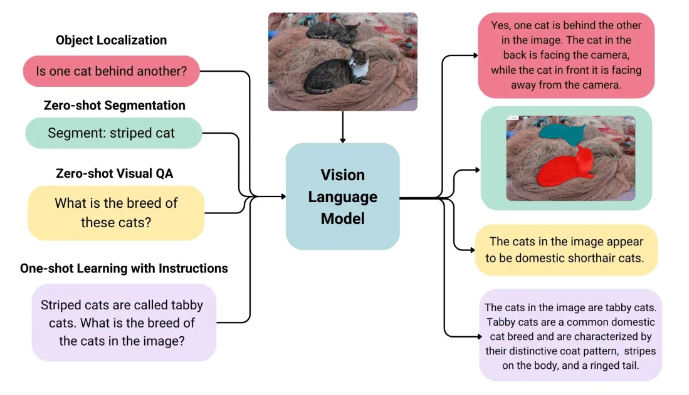
多模态视觉-语言模型(Vision-Language Model, VLM)是一种能够同时理解图像(或视频)与文本,并建立两者关联的人工智能模型。它突破了传统单一模态(纯文本或纯视觉)模型的局限,实现跨模态的联合推理、生成与分析能力。
一、核心原理:跨模态语义对齐
VLM 的核心是通过深度学习技术建立视觉与语言的关联映射。
(1)特征提取
视觉编码器(如 ViT)将图像分割为图块(patches),提取空间特征;
文本编码器(如 Transformer)将文本转化为词向量;
(2)模态融合
跨模态注意力机制:视觉特征与文本特征通过交叉注意力动态交互;
共享表征空间:将两种模态特征投影到同一语义空间(如 CLIP 的对比学习);

二、技术架构演进
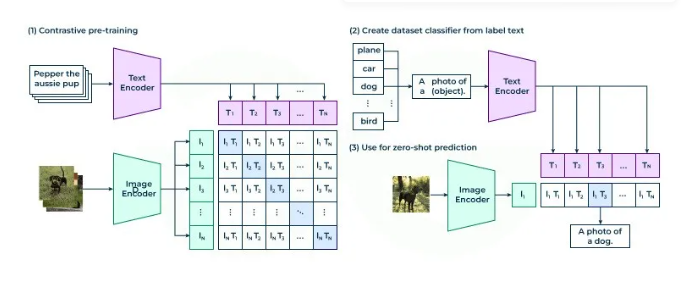
第一阶段:图文分类时代(2019-2021)
模型像一本标签词典,只能判断图像和文本是否相关(如“狗”配狗图),但无法深入理解关系。
例如:CLIP(像考试中的“连线题”),但只会给图片贴标签,不能描述细节或推理。
第二阶段:图文翻译时代(2022-2023)
视觉特征被压缩成密码(Token)传给语言模型,再由语言模型“翻译”成文字。
例如:LLaVA(如同把图片传真给AI,AI看着传真件描述内容),能生成图文描述(如“图中红车在加油站”),但推理能力弱。
第三阶段:视觉原生时代(2024)
直接处理原始高清图(任意形状/大小),像人眼一样聚焦关键细节(如发票金额/仪表盘数字)。能够动态压缩(千块像素 → 8个精华Token,提速7倍 ),支持高分辨率(卫星图/医疗影像无损解析)
例如:Qwen2.5-VL,从看缩略图升级到4K高清+智能缩放。
第四阶段:多模态Agent时代(2025+)
视觉和语言融合成统一语言,AI能直接操作现实(如截图→分析→点按钮)。这时图像即Token,图片和文字变成同一种“单词”,无缝协作闭环行动,实现看到界面→理解需求→自动执行(如订机票/修图)。
从单纯“描述问题”升级到真正“动手解决问题”,这是我们满怀憧憬的美好期待——期待能构建出统一的视觉大模型,甚至更进一步,打造出通用的大模型(AGI)。

Qwen2.5-VL
Qwen2.5-VL视觉-语言模型是什么?
Qwen2.5-VL是由阿里巴巴通义千问团队开发的开源视觉-语言多模态大模型(Vision-Language Model),属于Qwen系列的视觉语言模型。它通过深度融合图像、视频与文本信息,实现跨模态的理解、推理与交互能力。

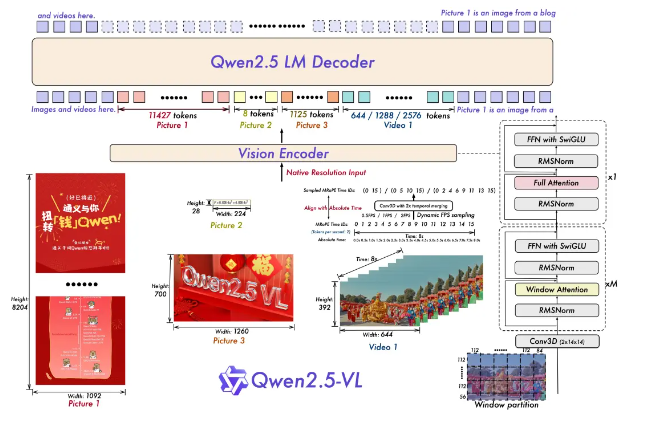
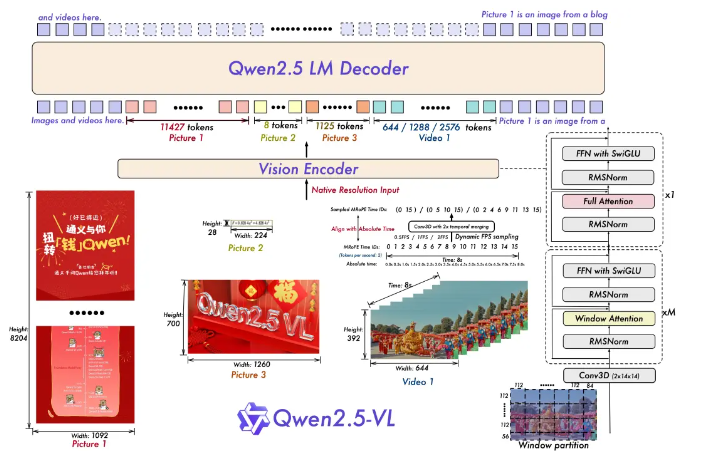
一、视觉编码器(Vision Encoder):
(1)使用“FFN with SwiGLU”(基于SwiGLU激活函数的前馈网络)和“RMSNorm”(归一化层),这些模块优化了特征融合和稳定性(类似Transformer架构)。
(2)“Window Attention”(窗口注意力机制),如标注“Window partition”,将图像分割为56x56或112x84的窗口进行局部注意力计算,显著降低了计算开销(比全局注意力快约7倍)。
(3)对于视频,引入“Conv3D (2x14x14)”层(3D卷积),结合“Align with Absolute Time”的绝对时间编码,以时间戳(如0-8s)对齐视频序列。这实现“秒级事件定位”,比如在长视频中精确找到“骑手未戴头盔”的片段。核心功能
二、图像/视频转换(Native Resolution Input):
负责将图像/视频转换为模型可理解的视觉特征(token)。图中标注“Native Resolution Input”强调了无需重新调整图像大小,直接处理任意尺寸和比例(如128高度、224宽度),这提升了原始数据的保真度。
三、语言模型集成(Qwen2.5 LM Decoder):
视觉特征输出后,传递到“Qwen2.5 LM Decoder”(基于通义千问语言模型的解码器),完成多模态推理(如图像描述、事件问答)。图中显示了完整的处理流程:视觉编码器提取特征 → 语言模型解码 → 生成文本输出(如结构化数据、时间点定位等)。
更多大模型精彩讲解与课件讲解可以关注公众号:大模型星球 (回复:977C)解锁
当然也可以直接扫码添加小助理领取本篇文章的资料已大模型路线图!

















 446
446

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









