









🎯来源: https://mp.weixin.qq.com/s/X7gxlcY-PaQ97MiEJmKfbg
对给定的大量无标注图数据,图对比学习算法旨在训练出一个图编码器,目前一般指图神经网络(Graph Neural Network, GNN)。由这个 GNN 编码得到的图表示向量,可以很好地保留图数据的特性。
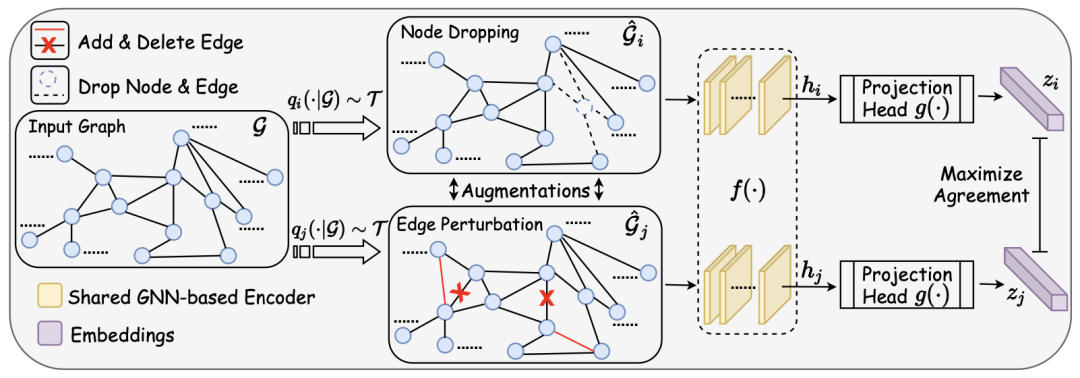
Graph Contrastive Learning with Augmentations. NeurIPS 2020.
算法步骤:
1. 随机采样一批(batch)图
2. 对每一个图进行两次随机的数据增强(增删边/舍弃节点)得到新图(view)
3. 使用待训练的 GNN 对 View 进行编码,得到节点表示向量(node representation)和图表示向量(graph representations)
4. 根据上述表示向量计算 InfoNCE 损失,其中由同一个 graph 增强出来的 view 的表示相互靠近,由不同的 graph 增强得到的 view 的表示相互远离;【特征被加强】
【启发式图数据增强】由于图数据经过GNN 后会产生 节点表示 和 图表示 两个层次的表示向量Contrastive Multi-View Representation Learning on Graphs. ICML 2020. 设计实验对不同层次的对比进行分析,发现将节点表示与图表示进行对比会取得更好的效果。芜湖~
【Learning方法图数据增强】JOAO:通过对抗训练(adversarial training)的方式,迭代训练选择每种数据增强方式【半自动】的概率矩阵,并对应更换 GraphCL 中的映射头(projection head)。实验结果表明,对抗训练学习得到的概率矩阵和此前 GraphCL 关于数据增强选择的实验结果趋势相近,并在不需要过多人工干预的情况下达到了有竞争力的结果。
【全自动】自动学习数据增强时对图做扰动的分布。Adversarial Graph Augmentation to Improve Graph Contrastive Learning 作者从数据增强如何保留图的信息出发,假设增强出的两个 View 之间并不是互信息越大越好,因为这些互信息中可能包含大量噪音。作者引入信息瓶颈 (Information Bottleneck)原则,认为更好的 View 应该是在共同保留图本身的特性这一前提下,彼此之间的互信息最小。即在训练中,学习如何通过增强保留 graph 中的必要信息,并同时减少噪音。基于这一原则,作者设计了 min-max game 的训练模式,并训练神经网络以决定是否在数据增强中删除某条边。【剪枝策略?】
【训练中负例的选择】方法在训练过程中同时进行聚类;为负样本设计了打分函数,将负样本从易到难地排序,并依次学习【候选】。 CuCo: Graph Representation with Curriculum Contrastive Learning

















 2966
2966

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









