






Pytorch
Datasets and Dataloaders
Datasets 存储数据及其对应的标签,DataLoader 在数据集上包装了一个可迭代对象,以方便访问数据。
Pytorch 中包含许多内置的数据集在 torch.utils.data.Dataset 中,包含 COCO、Cityscapes 等,详细:内置数据集。
以 Fashion-MNIST 为例,介绍如何载入一个数据集,包含参数:
- root:训练/测试数据集存放目录。
- train:是否是训练数据。
- download:是否下载数据集到 root 中。
- transform:指定数据形式和标签。
import torch
from torch.utils.data import Dataset
from torchvision import datasets
from torchvision.transforms import ToTensor, Lambda
import matplotlib.pyplot as plt
training_data = datasets.FashionMNIST(
root="data",
train=True,
download=True,
transform=ToTensor()
)
test_data = datasets.FashionMNIST(
root="data",
train=False,
download=True,
transform=ToTensor()
)
# 使用下面语句调用
img, label = training_data[sample_idx]将 Dataset 作为参数传给 DataLoader,DataLoader 用来读取小批量样本,并且可以打乱小批量内的顺序,来防止模型过拟合。
from torch.utils.data import DataLoader
train_dataloader = DataLoader(training_data, batch_size=64, shuffle=True)
test_dataloader = DataLoader(test_data, batch_size=64, shuffle=True)
# Display image and label.
train_features, train_labels = next(iter(train_dataloader))
print(f"Feature batch shape: {train_features.size()}")
print(f"Labels batch shape: {train_labels.size()}")
img = train_features[0].squeeze()
label = train_labels[0]
plt.imshow(img, cmap="gray")
plt.show()
print(f"Label: {label}")如果需要使用自己的数据集,必须实现三个函数 __init__,__len__ 和 __getitem__。
# img_dir 是图片存放目录,annotations_file 是 CSV 标注文件。
import os
import pandas as pd
import torchvision.io as tvio
class CustomImageDataset(Dataset):
def __init__(self, annotations_file, img_dir, transform=None, target_transform=None):
self.img_labels = pd.read_csv(annotations_file)
self.img_dir = img_dir
self.transform = transform
self.target_transform = target_transform
def __len__(self):
return len(self.img_labels)
def __getitem__(self, idx):
img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx, 0])
image = tvio.read_image(img_path)
label = self.img_labels.iloc[idx, 1]
if self.transform:
image = self.transform(image)
if self.target_transform:
label = self.target_transform(label)
sample = {"image": image, "label": label}
return sample__init__ 函数只在初始化数据集对象时执行一次,包含图片、标注文件和 transform。
__len__ 函数返回数据集中的图片数量。
__getitem__ 函数返回 idx 位置的图片和标签,read_image 读图片,self.img_labels 从 CSV 中读对应的标签数据。返回包含 tensor 类型的图片和对应标签的字典。
transform() 和 target_transform() 作用是对数据进行变换使其适合训练,前者用来变换图片,后者用来变换标签。
from torchvision import datasets
from torchvision.transforms import ToTensor, Lambda
ds = datasets.FashionMNIST(
root="data",
train=True,
download=True,
transform=ToTensor(),
target_transform=Lambda(lambda y: torch.zeros(10, dtype=torch.float).scatter_(0, torch.tensor(y), value=1))
)ToTensor() 将一个 NumPy 数组变换为 FloatTensor 并将像素值归一化到 [0.,1.]。
Lambda 表达式将标签数据变为一个 one-hot 向量。
model layers
神经网络包含许多层和模块来处理数据,torch.nn 中包含了所有需要用的网络层,每一个模块都是 nn.Module 的子类。
import os
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
# 查看 GPU 是否可用
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print('Using {} device'.format(device))初始化在 __init__ 中,在 forward 中完成对数据的处理。
class NeuralNetwork(nn.Module):
def __init__(self):
super(NeuralNetwork, self).__init__()
self.flatten = nn.Flatten() # 将 2D 的图像数据“展平”成 1D
self.linear_relu_stack = nn.Sequential(
nn.Linear(28*28, 512), # 线性层
nn.ReLU(), # 激活层
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10),
nn.ReLU()
)
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits创建一个实例并将其分配到 device 上,生成数据调用模型进行计算。
# 前面声明了 device,device = 'cuda' if torch.cuda.is_available() else 'cpu'
# 将模型放在 GPU 上运行
model = NeuralNetwork().to(device)
X = torch.rand(1, 28, 28, device=device) # 将数放在 GPU 上运行
logits = model(X)
print(logits)
pred_probab = nn.Softmax(dim=1)(logits)
print(pred_probab)
y_pred = pred_probab.argmax(1)
print(f"Predicted class: {y_pred}")输出模型每层信息,遍历层及参数。
print("Model structure: ", model, "\n\n")
for name, param in model.named_parameters():
print(f"Layer: {name} | Size: {param.size()} | Values : {param[:2]} \n")Automatic differentiation
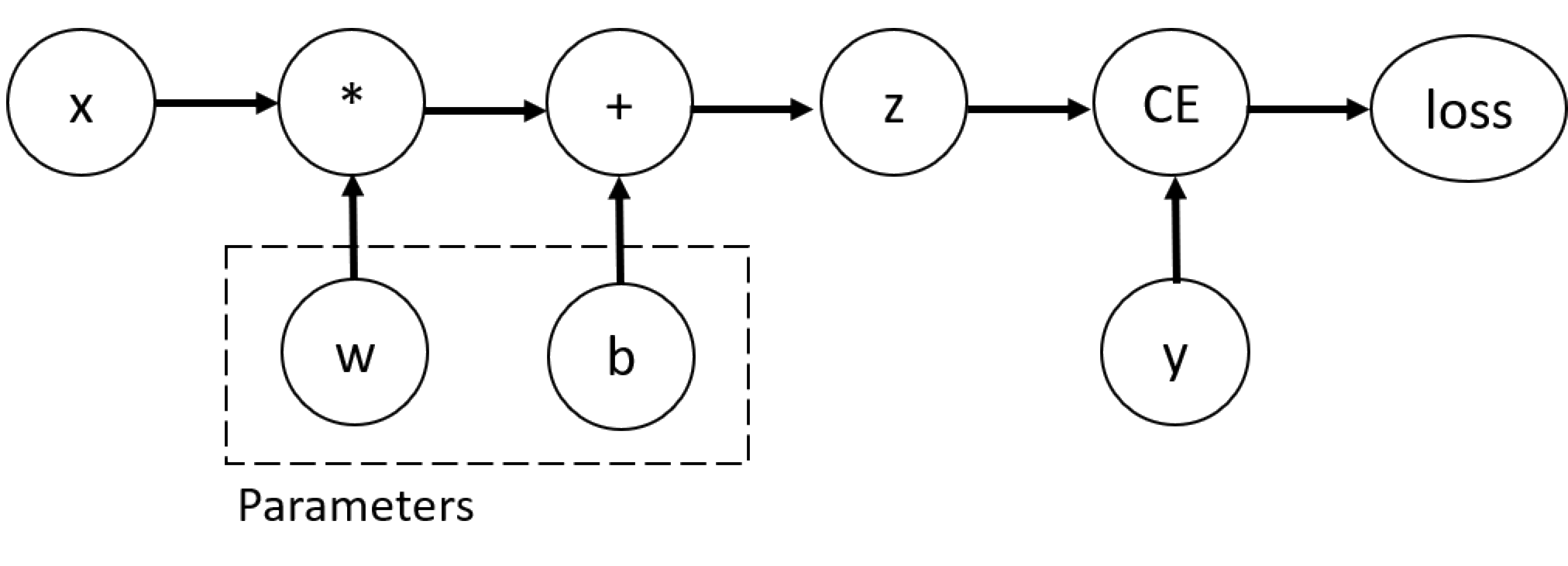
训练神经网络需要用到反向传播算法,根据损失函数的梯度来更新参数。Pytorch 中使用 torch.autograd 来求出计算图的梯度,以 x 为输入,w 和 b 为参数来计算梯度并输出参数的梯度值:
import torch
x = torch.ones(5) # input tensor
y = torch.zeros(3) # expected output
w = torch.randn(5, 3, requires_grad=True) # 也可以使用 w.requires_grad_(True)
b = torch.randn(3, requires_grad=True)
z = torch.matmul(x, w)+b
loss = torch.nn.functional.binary_cross_entropy_with_logits(z, y)
loss.backward() # 计算梯度
print(w.grad)
print(b.grad)其计算图如下
通常情况下梯度只能计算一次,但如果想要计算多次梯度的话,需要将 loss 的 retain_graph 置为 True。
# 假如有两个Loss,先执行第一个的backward,再执行第二个backward
loss1.backward(retain_graph=True) # 如果不加括号内会报错
loss2.backward() # 执行完这个后,所有中间变量都会被释放,以便下一次的循环也可以使用 .grad.zero_() 来清除梯度。
inp = torch.eye(5, requires_grad=True)
out = (inp+1).pow(2)
out.backward(torch.ones_like(inp), retain_graph=True)
print("First call", inp.grad)
out.backward(torch.ones_like(inp), retain_graph=True)
print("Second call", inp.grad)
inp.grad.zero_()
out.backward(torch.ones_like(inp), retain_graph=True)
print("Call after zeroing gradients", inp.grad)
# 其结果是
First call tensor([[4., 2., 2., 2., 2.],
[2., 4., 2., 2., 2.],
[2., 2., 4., 2., 2.],
[2., 2., 2., 4., 2.],
[2., 2., 2., 2., 4.]])
Second call tensor([[8., 4., 4., 4., 4.],
[4., 8., 4., 4., 4.],
[4., 4., 8., 4., 4.],
[4., 4., 4., 8., 4.],
[4., 4., 4., 4., 8.]])
Call after zeroing gradients tensor([[4., 2., 2., 2., 2.],
[2., 4., 2., 2., 2.],
[2., 2., 4., 2., 2.],
[2., 2., 2., 4., 2.],
[2., 2., 2., 2., 4.]])使用微调策略需要冻结参数或者需要梯度回传时,可以使用 torch.no_grad() 或 detach() 来阻止梯度回传,下面代码依次输出 True、False 和 False。
z = torch.matmul(x, w)+b
print(z.requires_grad)
with torch.no_grad():
z = torch.matmul(x, w)+b
print(z.requires_grad)
z = torch.matmul(x, w)+b
z_det = z.detach()
print(z_det.requires_grad)
autograd 保存了数据和执行的操作在一个有向无环图中,叶子节点是输入 tensor,根节点是输出 tensor,从根节点到叶子节点使用链式法则很容易就可以计算出梯度。
在前传时,autograd 同时进行了如下操作:
- 计算需要执行操作的结果。
- 求出有向无环图中操作的梯度函数。
当有向无环图的根节点调用 backward() 方法,开始梯度回传。梯度回传时 autograd 同时做了如下操作:
- 计算每一个 .grad_fn 的梯度,.grad_fn 指代该 tensor 反向传播函数的引用。
- 将他们累加到对应 tensor 的 .grad 参数中。
- 使用链式法则将梯度回传到叶子节点。
Learn about the optimization loop
训练模型是一个迭代的过程,模型在每一个 epoch 做出判断、计算 loss、收集参数的梯度最后用优化策略来完成对参数的更新。
超参数是优化策略包含的参数,不同的超参数会影响模型的训练和收敛,这里的超参数包含三个:learning rate、batch size 和 epochs。
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor, Lambda
training_data = datasets.FashionMNIST(
root="data",
train=True,
download=True,
transform=ToTensor()
)
test_data = datasets.FashionMNIST(
root="data",
train=False,
download=True,
transform=ToTensor()
)
train_dataloader = DataLoader(training_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
class NeuralNetwork(nn.Module):
def __init__(self):
super(NeuralNetwork, self).__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28*28, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10),
nn.ReLU()
)
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
model = NeuralNetwork()
learning_rate = 1e-3
batch_size = 64
epochs = 5每完成一次优化循环的迭代,叫做一个 epoch。每一个 epoch 包含两个部分:
- Train Loop,在训练集上训练,尽量收敛到最优。
- Validation/Test Loop,在测试或验证集上检查是否模型的性能有提升。
通常的损失函数包括对回归任务的 nn.MSELoss 以及对分类任务的 nn.NLLLoss,nn.CrossEntropyLoss() 包含了这两个损失函数。
loss_fn = nn.CrossEntropyLoss()我们通过注册需要训练的模型参数来初始化优化器,并传入学习率超参数。
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)在训练中,优化主要包含在三个步骤里:
- 调用 optimizer.zero_grad() 来重置梯度,在每一个 iteration 将其清零,之后梯度默认累加。
- 调用 loss.backwards() 来预测损失,PyTorch 存储每个参数梯度的损失。
- 有了梯度之后,调用 optimizer.step() 根据参数的梯度来调整参数。
def train_loop(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
for batch, (X, y) in enumerate(dataloader):
# Compute prediction and loss
pred = model(X)
loss = loss_fn(pred, y)
# Backpropagation
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch % 100 == 0:
loss, current = loss.item(), batch * len(X)
print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")
def test_loop(dataloader, model, loss_fn):
size = len(dataloader.dataset)
test_loss, correct = 0, 0
with torch.no_grad():
for X, y in dataloader:
pred = model(X)
test_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= size
correct /= size
print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")初始化损失函数和优化器,将其传到 train_loop 和 test_loop。
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
epochs = 10
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------------")
train_loop(train_dataloader, model, loss_fn, optimizer)
test_loop(test_dataloader, model, loss_fn)
print("Done!")Save and load the model
Pytorch 通过内置的状态字典来存储学习到的参数,可以通过 torch.save 来调用。
import torch
import torch.onnx as onnx
import torchvision.models as models
model = models.vgg16(pretrained=True)
torch.save(model.state_dict(), 'data/model_weights.pth')载入模型参数之前,需要创建一个相同的模型,使用 load_state_dict 方法。
model = models.vgg16() # we do not specify pretrained=True, i.e. do not load default weights
model.load_state_dict(torch.load('data/model_weights.pth'))
model.eval()如果要将参数和模型一起保存,可以将 model(而不是 model.state_dict())传递给 save 函数。
torch.save(model, 'data/vgg_model.pth')
model = torch.load('data/vgg_model.pth') # 可用这种方法调用导出模型到 ONNX 形式,imput_image 是模型的输入, 任何非 tensor 参数都将硬编码到导出的模型中;任何 tensor 参数都将成为导出的模型的输入,并按照他们在 args 中出现的顺序输入。
input_image = torch.zeros((1,3,224,224))
onnx.export(model, input_image, 'data/model.onnx')一次完整的训练过程:
PyTorch基础5——自定义损失函数_半臻的博客-CSDN博客_pytorch自定义损失函数
矩阵相乘
包含 torch.dot(), torch.matmul(), torch.mul(), torch.mm(), torch.bmm() 以及 @ 和 * 等方法。
- torch.dot()
将两个向量相乘后相加得到一个标量,必须都是一维的。
a = torch.tensor([2, 3])
b = torch.tensor([1,2])
c = torch.dot(a,b)
print('a:',a.shape)
print('b:',b.shape)
print('torch.dot:',c,c.shape)
--------------------------------------------------
a: torch.Size([2])
b: torch.Size([2])
torch.dot: tensor(8) torch.Size([])- torch.matmul()
是两个 tensor 数学意义上的矩阵相乘。如果两个 tensor 都是一维的,则相加后相乘得到一个数。如果两个 tensor 的 size 不同,则需要满足矩阵相乘维数条件。与 “@” 等价。
# This computes the matrix multiplication between two tensors. y1, y2, y3 will have the same value
y1 = tensor @ tensor.T
y2 = tensor.matmul(tensor.T)
y3 = torch.rand_like(tensor)
torch.matmul(tensor, tensor.T, out=y3)- torch.mul()
会先将数据进行广播,得到维度一样的 tensor,实现矩阵的点乘。与 “*” 等价。
# This computes the element-wise product. z1, z2, z3 will have the same value
z1 = tensor * tensor
z2 = tensor.mul(tensor)
z3 = torch.rand_like(tensor)
torch.mul(tensor, tensor, out=z3)import torch
a = torch.ones(3,4)
print(a)
b = torch.Tensor([1,2,3]).reshape((3,1))
print(b)
print(torch.mul(a, b))
-----------------------------输出--------------------------
tensor([[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]])
tensor([[1.],
[2.],
[3.]])
tensor([[1., 1., 1., 1.],
[2., 2., 2., 2.],
[3., 3., 3., 3.]])- torch.mm()
矩阵相乘,不会进行广播,必须满足矩阵相乘维数条件,两矩阵最多是2维。
a = torch.randn(2, 3)
b = torch.randn(3, 3)
c = torch.mm(a,b)
print('a:',a.shape)
print('b:',b.shape)
print('torch.mm:',c.shape)
-------------------------------------
a: torch.Size([2, 3])
b: torch.Size([3, 3])
torch.mm: torch.Size([2, 3])- torch.bmm()
批矩阵相乘,不会进行广播,必须满足矩阵相乘维数条件。a 和 b最多只能3维,且a,b中必须包含相同的矩阵个数,即a,b第一维度必须相同。
a = torch.randn(10, 2, 3)
b = torch.randn(10, 3, 4)
c = torch.bmm(a, b)
print('a:', a.shape)
print('b:', b.shape)
print('torch.bmm:', c.shape)
--------------------------------------------
a: torch.Size([10, 2, 3])
b: torch.Size([10, 3, 4])
torch.bmm: torch.Size([10, 2, 4])torch.cat() 和 torch.stack() 函数
torch.cat 和 torch.stack 的区别在于 torch.cat 沿着给定的维度拼接,而 torch.stack 会新增一维。
例如当参数是3个10x5的张量,torch.cat 的结果是30x5的张量,而 torch.stack 的结果是3x10x5的张量。
torch.cat 是将两个张量(tensor)拼接在一起,cat 是 concatnate 的意思,即拼接,联系在一起。torch.stack 是将两个张量堆叠。
C = torch.cat( (A,B),0 ) #按维数0拼接(竖着拼)
C = torch.cat( (A,B),1 ) #按维数1拼接(横着拼)
D = torch.stack( (A,B),0 ) #在0维增加一个维度,再将A、B分别增加一维放在这个维度上
D = torch.stack( (A,B),0 ) #在1维增加一个维度,再将A、B分别增加一维放在这个维度上使用 torch.cat((A,B),dim) 时,除拼接维数 dim 的数值可不同外其余维数数值需相同,方能对齐。torch.stack 必须要求两个张量 shape 相同。
import torch
A=torch.ones(2,3) #2x3的张量(矩阵)
print(A)
输出:
tensor([[ 1., 1., 1.],
[ 1., 1., 1.]])
D=2*torch.ones(2,4) #2x4的张量(矩阵)
C=torch.cat((A,D),1)#按维数1(列)拼接
print(C)
输出:
tensor([[ 1., 1., 1., 2., 2., 2., 2.],
[ 1., 1., 1., 2., 2., 2., 2.]])
C=torch.stack((A,D),0) # 会报错
M=torch.ones(3,4)
N=2*torch.ones(3,4)
P=torch.stack((M,N),0) # shape为 (2,3,4)
Q=torch.stack((M,N),1) # shape为 (3,2,4)
R=torch.stack((M,N),2) # shape为 (3,4,2)import torch
A=torch.ones(2,3) #2x3的张量(矩阵)
D=2*torch.ones(4,3) #4x3的张量(矩阵)
C=torch.cat((A,D),0) #按维数0(行)拼接
print(C)
输出:
tensor([[1., 1., 1.],
[1., 1., 1.],
[2., 2., 2.],
[2., 2., 2.],
[2., 2., 2.],
[2., 2., 2.]])torch.clamp() 函数
返回范围内的一个数值。可以使用 clamp 函数将不断增加、减小或随机变化的数值限制在一系列的值中。
torch.clamp(input, min, max, out=None) → Tensor
clamp(22, 4, 6)
返回 6,因为 22 大于 6 而 6 是范围的最大数值。
clamp(2, 4, 6)
返回 4,因为 2 小于 4 而 4 是范围的最小数值。torch.view() 和 torch.reshape() 函数
相当于numpy中的reshape,重新定义矩阵的形状。
import torch
v1 = torch.range(1, 16)
v2 = v1.view(4, 4) 其中v1为1*16大小的张量,包含16个元素。v2为4*4大小的张量,同样包含16个元素。注意view前后的元素个数要相同,不然会报错。
import torch
v1 = torch.range(1, 16)
v2 = v1.view(-1, 4) 和图例中的用法一样,view中一个参数定为-1,代表动态调整这个维度上的元素个数,以保证元素的总数不变。因此两个例子的结果是相同的。
但 torch.reshape() 与 torch.view() 的区别是 reshape 之后的 tensor 就不与原始 tensor 共享内存了;并且 torch.view() 需要作用在内存连续的 tensor 上,可以用 tensor.contiguous() 将其转化到连续的内存上,但是这样做相当于新开辟了一个内存空间(深拷贝)。
torch.contiguous() 函数
torch.view() 只能用在 contiguous 的 Variable 上。如果在 view() 之前用了 transpose()、permute() 等,需要用 contiguous() 来返回一个 contiguous copy(深拷贝),这样会使 tensor 变量在内存中的存储变得连续。有些 tensor 并不是占用一整块内存,而是由不同的数据块组成,而 tensor 的 view() 操作依赖于内存是整块的,这时只需要执行 contiguous() 这个函数,把 tensor 变成在内存中连续分布的形式。在 pytorch 的0.4版本中,增加了 torch.reshape(),这与 numpy.reshape 的功能类似。它大致相当于 tensor.contiguous().view()。
torch.squeeze() 和 torch.unsqueeze() 函数
squeeze(arg)表示第arg维的维度值为1,则删除该维度,否则tensor不变。即若tensor.shape()[arg] = 1,则去掉该维度。unsqueeze(arg)与squeeze(arg)作用相反,表示在第arg维增加一个维度值为1的维度。
torch.nonzero() 函数
找出tensor中非零的元素的索引。返回一个包含输入input中非零元素索引的张量.输出张量中的每行包含input中非零元素的索引。
import torch
label = torch.tensor([[1,0,0],
[1,0,1]])
print(label.nonzero())
输出:
tensor([[0, 0],
[1, 0],
[1, 2]])
torch.max() 函数
output = torch.max(input, dim),input 是 softmax 函数输出的一个 tensor,dim 是 max 函数索引的维度0/1,0是每列的最大值,1是每行的最大值。函数会返回两个 tensor,第一个 tensor 是每行的最大值,第二个 tensor 是每行最大值的索引。
import torch
a = torch.tensor([[1,5,62,54], [2,6,2,6], [2,65,2,6]])
print(a)
# 输出
tensor([[ 1, 5, 62, 54],
[ 2, 6, 2, 6],
[ 2, 65, 2, 6]])
torch.split()
将 tensor 切分成分块结构。
torch.split(tensor, split_size_or_sections, dim=0)
split_size_or_sections 为需要切分的块的大小,可以为 int/list。从列维度 split:
a = torch.rand([5, 4])
a
'output'
tensor([[0.6162, 0.3467, 0.7211, 0.0599],
[0.9489, 0.5007, 0.3920, 0.8523],
[0.6555, 0.0196, 0.4648, 0.0774],
[0.0678, 0.1809, 0.9995, 0.6153],
[0.5673, 0.4132, 0.6386, 0.6662]])
# 表示从列维度开始split,split_size_or_sections 为2表示从每一行中取2个数作为单独的一个块
torch.split(a, 2, 1)
'output'
(tensor([[0.6162, 0.3467],
[0.9489, 0.5007],
[0.6555, 0.0196],
[0.0678, 0.1809],
[0.5673, 0.4132]]),
tensor([[0.7211, 0.0599],
[0.3920, 0.8523],
[0.4648, 0.0774],
[0.9995, 0.6153],
[0.6386, 0.6662]]))
# 表示从每一行中取3个数作为单独的一个块
torch.split(a, 3, 1)
'output'
(tensor([[0.6162, 0.3467, 0.7211],
[0.9489, 0.5007, 0.3920],
[0.6555, 0.0196, 0.4648],
[0.0678, 0.1809, 0.9995],
[0.5673, 0.4132, 0.6386]]),
tensor([[0.0599],
[0.8523],
[0.0774],
[0.6153],
[0.6662]]))从行维度 split:
a = torch.rand([5, 4])
a
'output'
tensor([[0.6162, 0.3467, 0.7211, 0.0599],
[0.9489, 0.5007, 0.3920, 0.8523],
[0.6555, 0.0196, 0.4648, 0.0774],
[0.0678, 0.1809, 0.9995, 0.6153],
[0.5673, 0.4132, 0.6386, 0.6662]])
# 表示从行的维度开始split,每1行作为split后单独的一个块
torch.split(a, 1, 0)
'output'
(tensor([[0.6162, 0.3467, 0.7211, 0.0599]]),
tensor([[0.9489, 0.5007, 0.3920, 0.8523]]),
tensor([[0.6555, 0.0196, 0.4648, 0.0774]]),
tensor([[0.0678, 0.1809, 0.9995, 0.6153]]),
tensor([[0.5673, 0.4132, 0.6386, 0.6662]]))
# 每2行作为split后单独的一个块
torch.split(a, 2, 0)
'output'
(tensor([[0.6162, 0.3467, 0.7211, 0.0599],
[0.9489, 0.5007, 0.3920, 0.8523]]),
tensor([[0.6555, 0.0196, 0.4648, 0.0774],
[0.0678, 0.1809, 0.9995, 0.6153]]),
tensor([[0.5673, 0.4132, 0.6386, 0.6662]]))转置函数 torch.transpose() 和 torch.permute()
torch.transpose(x) 合法,x.transpose() 合法;tensor.permute(x) 不合法,x.permute() 合法。
torch.transpose() 一次只能操作两个维度,其参数代表换位的维度是哪个;torch.permute() 可以操作多个函数,其参数代表维度交换后的位置信息:
x = torch.randn(2,3) 'x.shape → [2,3]'
y = torch.randn(2,3,4) 'y.shape → [2,3,4]'
# 对于transpose
x.transpose(0,1) 'shape→[3,2] '
x.transpose(1,0) 'shape→[3,2],这两个语句的效果是相同的'
y.transpose(0,1) 'shape→[3,2,4]'
y.transpose(0,2,1) '报错,操作不了多维'
# 对于permute()
x.permute(0,1) 'shape→[2,3]'
x.permute(1,0) 'shape→[3,2],这两个语句的效果是不同的'
y.permute(0,1) "报错,number of dims don't match in permute"
y.permute(1,0,2) 'shape→[3,2,4],必须写满所有的维度才不报错'torch.optim.lr_scheduler.MultiStepLR()
torch.optim.lr_scheduler.MultiStepLR()用法研究_jiongta9473的博客-CSDN博客
pytorch 中的 BCELoss() 和 KLDivLoss()
pytorch BCELoss()、KLDivLoss()的参数 及 “对于size_average、reduce、reduction参数的研究”_jiongta9473的博客-CSDN博客
KL 散度(Kullback–Leibler divergence),又称相对熵,是描述两个概率分布 P 和 Q 差异的一种方法:
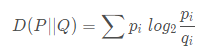
torch.nn.functional.kl_div(input, target, size_average=None, reduce=None, reduction='mean')
torch.nn.KLDivLoss(input, target, size_average=None, reduce=None, reduction='mean')第一个参数传入的是一个对数概率矩阵,第二个参数传入的是概率矩阵。并且因为 KL 散度具有不对称性,存在一个指导和被指导的关系,因此这连个矩阵输入的顺序需要确定一下。如果现在想用 Y 指导 X,第一个参数要传 X,第二个要传 Y。就是被指导的放在前面,然后求相应的概率和对数概率。
torch 中的张量操作
有空总结下...
pytorch张量维度操作(拼接、维度扩展、压缩、转置、重复……)_Ma Sizhou-CSDN博客_pytorch张量扩张
图像边界 padding
pytorch必须掌握的4种边界Padding方法 - 知乎
PyTorch碎片:F.pad的图文透彻理解_面壁者-CSDN博客_f.pad
将装有 tensor 的 list 转为装有 tensor 的 tensor
可用 torch.stack(),第二个参数为 dim,按行拼接。
result = torch.stack(result, 0)torch.detach() 和 torch.data()
如果是用 torch.data(),可以得到 tensor 数据的 requires grad = False 的版本。而且二者共享储存空间,也就是如果修改其中一个,另一个也会变。因为 PyTorch 的自动求导系统不会追踪tensor.data() 的变化,所以使用它的话可能会导致求导结果出错。官方建议使用tensor.detach() 来替代它,二者作用相似,但是 detach 会被自动求导系统追踪。
a = torch.tensor([7., 0, 0], requires_grad=True)
b = a + 2
print(b)
# tensor([9., 2., 2.], grad_fn=<AddBackward0>)
loss = torch.mean(b * b)
b_ = b.detach()
b_.zero_()
print(b)
# tensor([0., 0., 0.], grad_fn=<AddBackward0>)
# 储存空间共享,修改 b_ , b 的值也变了
loss.backward() '报错'
# RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation但是使用 tensor.data(),就不会报错,给调试带来困难。
a = torch.tensor([7., 0, 0], requires_grad=True)
b = a + 2
print(b)
# tensor([9., 2., 2.], grad_fn=<AddBackward0>)
loss = torch.mean(b * b)
b_ = b.data
b_.zero_()
print(b)
# tensor([0., 0., 0.], grad_fn=<AddBackward0>)
loss.backward() '没有报错,但是结果是错误的'
print(a.grad)
# tensor([0., 0., 0.])
# 其实正确的结果应该是:
# tensor([6.0000, 1.3333, 1.3333])Rearrange() 函数
是 einops 包中的一个函数调用方法。
from einops import rearrange 把张量的维度操作具象化,想出即写出。
output_tensor = rearrange(input_tensor, 'h w c -> c h w')
a = torch.randn(3, 9, 9) # [3, 9, 9]
output = rearrange(a, 'c (r p) w -> c r p w', p=3)
print(output.shape) # [3, 3, 3, 9]Open CV
可视化 anchor 时,cv2.rectangle 报错。
cv2.rectangle(img, (x1,y1), (x2,y2), color, thickness=1, lineType=cv2.LINE_AA)
TypeError: Expected Ptr<cv::UMat> for argument 'img'
是因为 img 处理后在内存中存储不连续所导致的问题,可能是之前对 img 的某些操作引起的,所以加入下面的命令使之连续,问题得到解决。
img = np.ascontiguousarray(img)Numpy
np.maximum() 函数
逐元素求最大值和最小值,broadcasting。
pred_bboxes = np.array([[15, 18, 47, 60],
[50, 50, 90, 100],
[70, 80, 120, 145],
[130, 160, 250, 280],
[25.6, 66.1, 113.3, 147.8]])
gt_bbox = np.array([70, 80, 120, 150])
ixmin = np.maximum(pred_box[:, 0], gt_box[0]) # 结果是 [70, 70 ,70 ,130 ,70]
ixmax = np.minimum(pred_box[:, 2], gt_box[2]) # 结果是 [47, 90 ,120 ,120, 113.3]
inters_w = np.maximum(ixmax - ixmin + 1., 0) # 结果是 [0, 21, 51, 0, 44.3]np.maximum(np.eye(2), [0.5, 2]) # broadcasting,结果是 array([[1. , 2. ], [0.5, 2. ]])np.expand_dims() / np.newaxis() 函数和 np.squeeze() 函数
增加一个维度,也可以用 np.newaxis() 函数:
import numpy as np
arr = np.array([[1, 2, 3], [2, 3, 4]])
print(arr.shape) # (2, 3)
# 很好理解
print(np.expand_dims(arr, 0).shape) # (1, 2, 3)
print(np.expand_dims(arr, 1).shape) # (2, 1, 3)
print(np.expand_dims(arr, 2).shape) # (2, 3, 1)
arr = np.array([1, 2, 3])
print(np.expand_dims(arr, 0))
"""
[[1 2 3]]
"""
print(np.expand_dims(arr, 1))
"""
[[1]
[2]
[3]]
"""np.newaxis() 的作用就是选取部分的数据增加一个维度。
a=np.array([1,2,3,4,5])
print(a.shape)
print (a)
输出:
(5,)
[1 2 3 4 5]
a=np.array([1,2,3,4,5])
aa=a[:,np.newaxis]
print(aa.shape)
print (aa)
输出:(5, 1)
[[1]
[2]
[3]
[4]
[5]]
a=np.array([1,2,3,4,5])
aa=a[np.newaxis,:]
print(aa.shape)
print (aa)
输出
(1, 5)
[[1 2 3 4 5]]np.newaxis 的作用是增加一个维度。对于 [: , np.newaxis] 和 [np.newaxis,:],是在 np.newaxis 这里增加1维。删除一个维度:
import numpy as np
arr = np.array([[[1, 2, 3], [2, 3, 4]]])
print(arr)
"""
[[[1 2 3]
[2 3 4]]]
"""
print(arr.shape) # (1, 2, 3)
# 事实上第一个维度我们是不需要的,因为在该维度上数组的长度是1
# 删除第1个维度,我们看到已经改变了
# 这个操作不会改变原来的数据
print(np.squeeze(arr, 0))
"""
[[1 2 3]
[2 3 4]]
"""但是注意:只有数组长度在该维度上为1,那么该维度才可以被删除。如果不是1,那么删除的话会报错。
这 numpy 中的三个函数可以应对大部分的维度操作。
Numpy 与 Tensor
两者转换
改变一方就会影响另一方。
n = np.ones(5)
t = torch.from_numpy(n)
np.add(n, 1, out=n)
print(f"t: {t}")
print(f"n: {n}")结果是:
t: tensor([2., 2., 2., 2., 2.], dtype=torch.float64)
n: [2. 2. 2. 2. 2.]使用 tensor.numpy() 也一样。
改变数据类型
Torch:
torch 中的数据类型

import torch
my_tensor = torch.randn(2, 4) # 默认为float32类型
my_tensor.type(torch.float16)Numpy:
import numpy as np
my_numpy = np.random.randint(1, 10, (3, 4)) # 默认为int32
my_numpy.astype(np.float32)np.repeat() 和 torch.repeat() 函数
print("复制之前:", img_Y_blur.shape)
img_Y_blur = np.repeat(img_Y_blur, 3, 2)
print("复制之后:", img_Y_blur.shape)结果是:
复制之前: (368, 496, 1)
复制之后: (368, 496, 3)numpy.repeat(a, repeats, axis=None),参数的意思顾名思义。例如 ff 是(280,304,1)的数组,此时执行:
ff = np.repeat(ff, 3, 2)
ff.shape() # 结果是[280, 304, 3]查看数组的值发现完成复制:

numpy() 文档中的示例:

而 torch 中的 torch.repeat() 函数:当参数只有两个时,第一个参数表示的是复制后的行数,第二个参数表示复制后的列数。当参数有三个时,第一个参数表示的是复制后的通道数,第二个参数表示的是复制后的列数,第三个参数表示复制后的行数,以此类推。
>>> import torch
>>> # 定义一个 33x55 张量
>>> a = torch.randn(33, 55)
>>> a.size()
torch.Size([33, 55])
>>>
>>> # 下面开始尝试 repeat 函数在不同参数情况下的效果
>>> a.repeat(1,1).size() # 原始值:torch.Size([33, 55])
torch.Size([33, 55])
>>>
>>> a.repeat(2,1).size() # 原始值:torch.Size([33, 55])
torch.Size([66, 55])
>>>
>>> a.repeat(1,2).size() # 原始值:torch.Size([33, 55])
torch.Size([33, 110])
>>>
>>> a.repeat(1,1,1).size() # 原始值:torch.Size([33, 55])
torch.Size([1, 33, 55])
>>>
>>> a.repeat(2,1,1).size() # 原始值:torch.Size([33, 55])
torch.Size([2, 33, 55])
>>>
>>> a.repeat(1,2,1).size() # 原始值:torch.Size([33, 55])
torch.Size([1, 66, 55])
>>>
>>> a.repeat(1,1,2).size() # 原始值:torch.Size([33, 55])
torch.Size([1, 33, 110])
>>>
>>> a.repeat(1,1,1,1).size() # 原始值:torch.Size([33, 55])
torch.Size([1, 1, 33, 55])Python
切片操作
tensor = torch.rand(4, 4)
print(tensor)
print('First row: ',tensor[0])
print('First column: ', tensor[:, 0])
print('Last column:', tensor[..., -1])
tensor[:,1] = 0
print(tensor)结果是:
tensor([[0.2512, 0.0451, 0.0583, 0.1652],
[0.2723, 0.8213, 0.0976, 0.3671],
[0.2543, 0.6730, 0.5836, 0.8554],
[0.2277, 0.9309, 0.5631, 0.1803]])
First row: tensor([0.2512, 0.0451, 0.0583, 0.1652])
First column: tensor([0.2512, 0.2723, 0.2543, 0.2277])
Last column: tensor([0.1652, 0.3671, 0.8554, 0.1803])
tensor([[0.2512, 0.0000, 0.0583, 0.1652],
[0.2723, 0.0000, 0.0976, 0.3671],
[0.2543, 0.0000, 0.5836, 0.8554],
[0.2277, 0.0000, 0.5631, 0.1803]])- list = [1,2,3,4,5,6,7,7,8] 我想访问从倒数第一位到倒数第三位怎么做到,我想要的输出效果应该是 [8,7,7]?
list[::-1][:3]
或者
list[-3:][::-1]list[::-1] 是将列表反过来,一种是先反过来,然后取前三位;一种是先取后三位,再反过来。















 8959
8959











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









