






前言
本文通过在本地部署的Dify平台上结合最新的Qwen3模型构建本地化AI医疗问诊初筛系统,从模型特性、本地部署步骤到实际应用案例,为您提供全面的技术指南。

你是否曾经为挂不到专家号而苦恼?或者在医院排长队只为了一个简单的问题咨询?甚至因为自己不懂医学知识,不知道该挂什么科室而浪费时间?😓
随着人工智能技术的飞速发展,大模型在医疗领域的应用正成为解决上述痛点的有力武器。今天,我要向大家介绍如何利用通义千问最新推出的Qwen3模型,结合Dify平台,打造一个本地部署的医疗问诊初筛系统。这套系统不仅能帮助医院提高分诊效率,还能为患者提供初步的医疗咨询服务。💪
Qwen3模型
Qwen3是2025年4月29日阿里巴巴集团旗下最新发布的超大规模语言模型系列,相比前代产品,Qwen3在多个维度都有显著提升。🚀
Qwen3系列的核心特点
多种思考模式:在医学知识理解和医疗对话方面表现出色,能够准确理解患者描述的症状,并给出专业的初步建议
- \1. 思考模式:在这种模式下,模型会逐步推理,经过深思熟虑后给出最终答案。这种方法非常适合需要深入思考的复杂问题。
- \2. 非思考模式:在此模式下,模型提供快速、近乎即时的响应,适用于那些对速度要求高于深度的简单问题。
多语言支持:Qwen3 模型支持119 种语言和方言。这一广泛的多语言能力为国际应用开辟了新的可能性,让全球用户都能受益于这些模型的强大功能。
增强的 Agent 能力:优化了 Qwen3 模型的 Agent 和 代码能力,同时也加强了对 MCP 的支持。
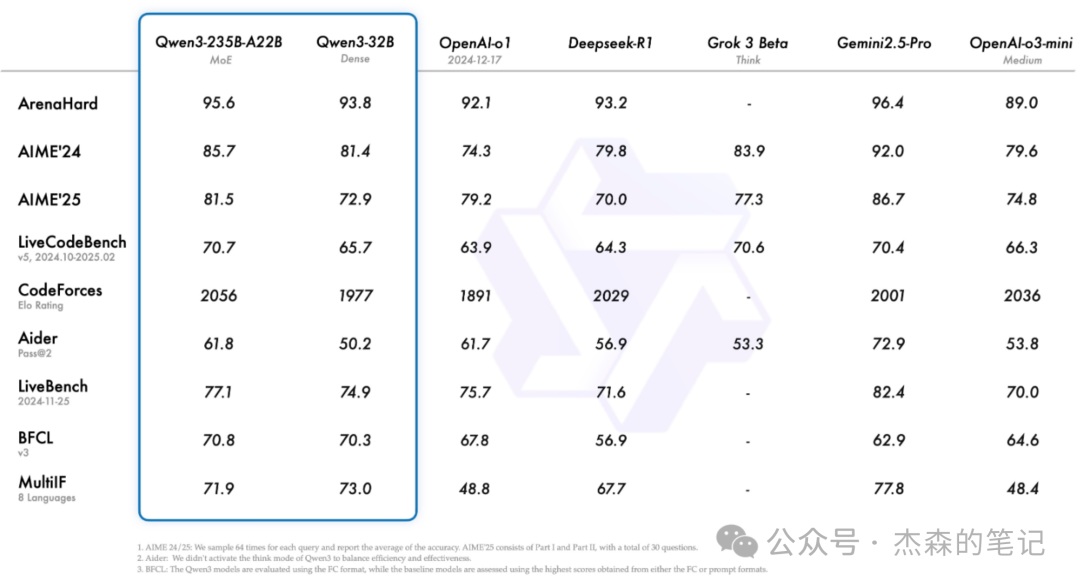
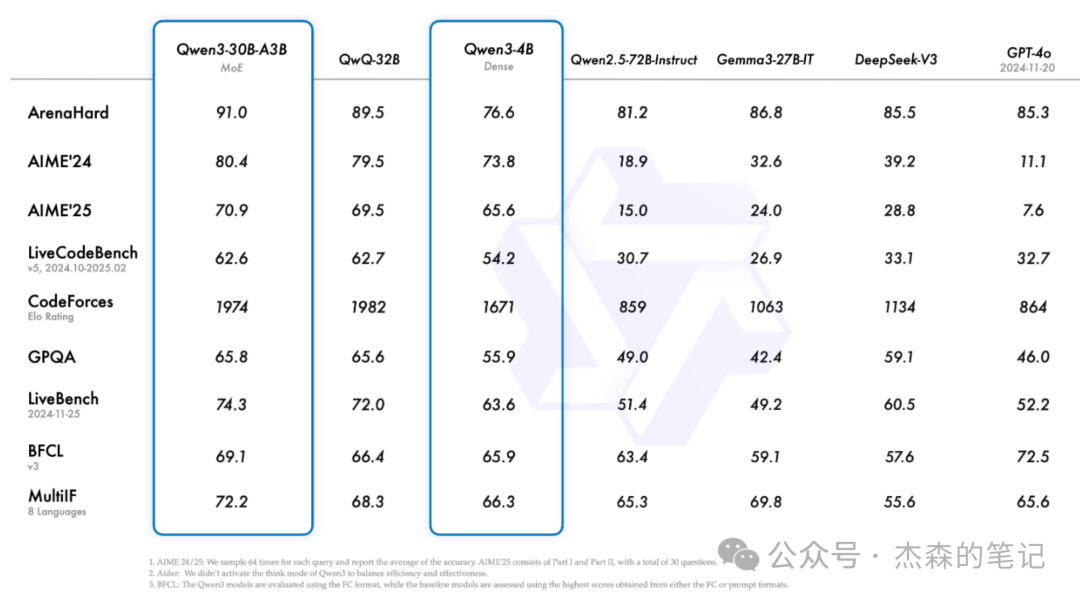
本地部署的优势
在医疗场景中,患者数据的隐私保护至关重要。通过本地部署Qwen3模型,可以确保敏感医疗数据不会离开医院内网,同时也能减少网络延迟,提供更快速的响应体验。👨⚕️
本地部署的核心优势:
- • 数据隐私保护:患者数据完全在本地处理,不需要上传到云端
- • 低延迟响应:本地推理无需网络传输,响应速度更快
- • 灵活定制:可根据医院具体需求对模型进行微调和优化
- • 降低成本:无需持续支付API调用费用,长期使用更经济
实战:部署Qwen3模型的AI医疗问诊初筛系统
接下来,我将详细介绍如何通过以下步骤,构建一个基于Qwen3的本地AI医疗问诊初筛系统:
第一步:安装Ollama管理工具
Ollama 是一个优秀的开源大模型管理工具,可以帮助我们轻松部署和管理Qwen3模型。
这里以Windows操作系统为例:
- \1. 访问Ollama官网
https://ollama.com/下载Windows安装包 - \2. 双击安装包,按照提示完成安装
- \3. 安装完成后,Ollama会在系统托盘中运行
安装结束后,可以用以下命令来查看是否安装成功:
ollama -v
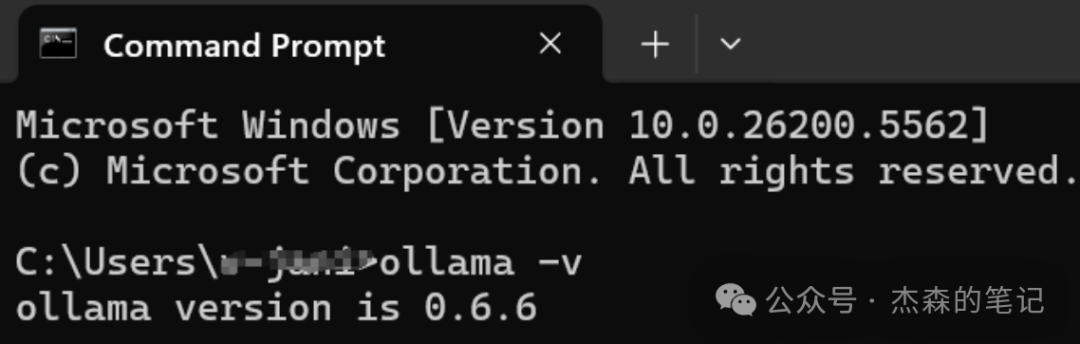
如果显示ollama version说明安装成功🌟
通过以下命令在Dify容器内部测试 Ollama 接口:
docker exec -it docker-api-1 curl host.docker.internal:11434/api/tags

如果显示模型信息说明从容器可以访问 Ollama🌟
注意:ollama 默认是安装到C盘,所以默认模型也会下载到C盘,如果需要指定安装路径,可以使用以下命令进行安装:
.\OllamaSetup.exe /DIR="D:\ollama"
修改模型的下载位置可以添加系统环境变量:OLLAMA_MODELS=D:\ollama\models,请提前创建文件夹
ollama 默认只能通过本机访问 http://localhost:11434/ 或 http://127.0.0.1:11434/。如果需要让局域网内其他人也能访问,可以添加系统环境变量:OLLAMA_HOST=0.0.0.0
ollama 的默认访问端口是11434,如果需要修改默认端口,可以添加系统环境变量:OLLAMA_PORT=8090
ollama 常用命令:
ollama run <model>:<tag> - 运行一个指定标签的模型版本并启动交互式会话
ollama stop <model> - 停止一个正在运行的模型
ollama pull <model> - 下载一个模型
ollama push <model> - 上传一个模型
ollama list - 列出本地已下载的模型
ollama rm <model> - 删除一个模型
ollama ps - 显示当前运行的 Ollama 模型实例
ollama serve - 启动 Ollama 服务器
ollama create <model> - 使用 Modelfile 创建一个自定义模型
ollama cp <model> <new model name> - 创建一个模型副本
ollama show <model> - 显示模型的信息
ollama -h 或 ollama --help - 显示帮助信息
ollama -v 或 ollama --version - 显示当前 Ollama 版本信息
第二步:本地部署Qwen3模型
安装完Ollama后,我们需要拉取并部署Qwen3模型。根据您的设备配置,可以选择不同规格的Qwen3模型:
显存:
- • ≤8GB VRAM:仅可选择 qwen3:0.6b(最低约4GB)
- • 8-16GB VRAM:支持 qwen3:1.7b/4b(约8-12GB)
- • ≥24GB VRAM:可运行 qwen3:8b/14b(需预留缓存空间)
- • 多卡分布式:才考虑 qwen3:32b 及以上
CPU加速:若无GPU,建议选择 MoE 模型(如 qwen3:30b-a3b)通过 CPU 卸载
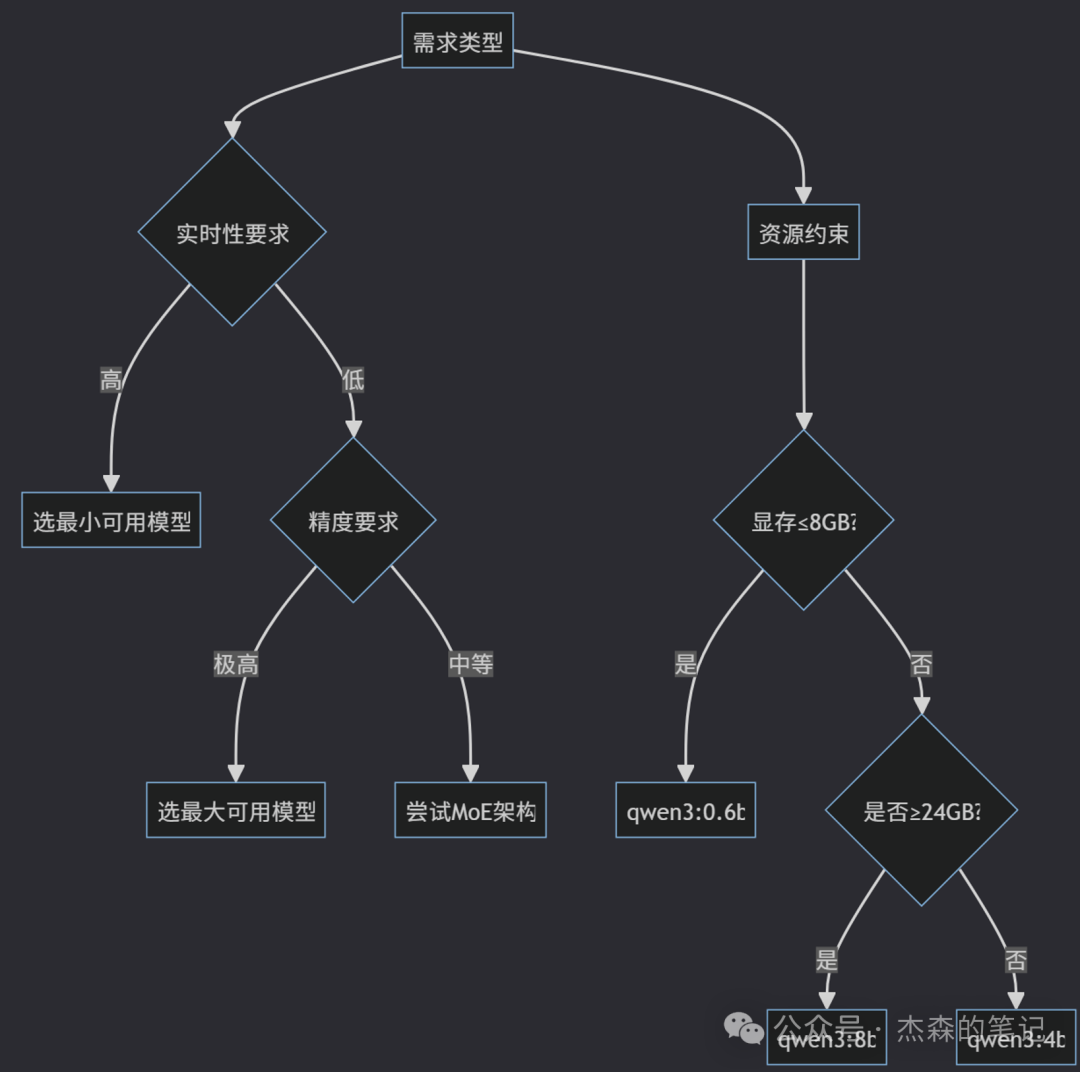
我这里选择的是4B版本的模型,通过以下命令下载并运行模型,大概需要等待几分钟完成下载:
# 拉取并运行Qwen3 4B模型
ollama run qwen3:4b

当模型运行之后,我们可以输入测试: “请简单描述一下感冒的症状”
<think>
嗯,用户让我简单描述感冒的症状。首先,我需要确定用户的需求是什么。他们可能是在自己或家人感冒时,想了解常见症状,以便
判断是否需要就医或者采取什么措施。也有可能是在学习医学知识,或者只是好奇。
接下来,我要回忆感冒的主要症状。感冒通常是由病毒感染引起的,症状包括鼻塞、流鼻涕、打喷嚏、喉咙痛、咳嗽、发烧、乏力、
头痛等。但需要区分普通感冒和流感,因为流感症状更严重,但用户可能只是问普通感冒。
然后,我需要考虑是否要提到不同症状的持续时间,比如感冒通常持续几天到一周,而流感可能更剧烈且持续时间更长。不过用户可
能只需要基本症状,不需要分类型。
还要注意避免使用专业术语,保持语言通俗易懂。比如“鼻塞”而不是“鼻黏膜充血”,或者“喉咙痛”而不是“咽痛”。同时,可
能需要提醒用户如果症状严重或持续时间长,应该就医,但用户可能只需要症状描述,所以这部分可能需要简要提及。
另外,用户可能没有说出来的深层需求是,他们可能想了解如何缓解这些症状,或者是否需要吃药。但根据问题,只需要描述症状,
所以可能不需要扩展。不过可能需要提到常见的治疗方式,比如多喝水、休息、用药等,但不确定是否有必要,可能保持回答简洁。
还要检查是否有遗漏的症状,比如是否提到身体疼痛、肌肉酸痛,或者可能的其他症状如恶心、呕吐,但这些可能更常见于流感或其
它疾病,所以可能不纳入普通感冒的描述。
最后,确保信息准确,没有错误。比如,感冒通常不会引起高烧,但可能有低烧,而流感可能有高烧。但用户可能只需要普通感冒,
所以需要明确说明。或者,可能需要说明感冒通常不会高烧,而流感可能有高烧,但用户的问题可能不需要区分,所以可能只需要提
到发烧作为可能症状。
总结:需要列出常见的感冒症状,包括鼻塞、流鼻涕、打喷嚏、喉咙痛、咳嗽、低烧、乏力、头痛、身体疼痛等,可能还有轻微的恶
心或呕吐,但可能不常见。同时,提醒如果症状严重或持续,应就医。但用户可能只需要症状描述,所以保持简洁。
</think>
感冒(普通感冒)的常见症状包括:
1. **鼻部症状**:鼻塞、流清鼻涕,可能伴随打喷嚏。
2. **咽喉不适**:喉咙痛或干痒。
3. **咳嗽**:干咳或伴有痰。
4. **全身症状**:轻微发热(通常为低烧),乏力、肌肉酸痛、头痛。
5. **其他**:偶尔伴有恶心、呕吐或轻微的全身不适。
症状通常较轻,持续1-10天,多数人可自行恢复。若出现高烧、持续咳嗽、呼吸困难或症状加重,建议及时就医。
如果能看到模型返回关于感冒症状的描述,说明模型已成功部署。🎉默认开启了思考模式,回复的也很不错。
第三步:安装和配置Dify平台
Dify 是一个强大的AI应用开发平台,我们将使用它来构建我们的AI医疗问诊初筛系统。
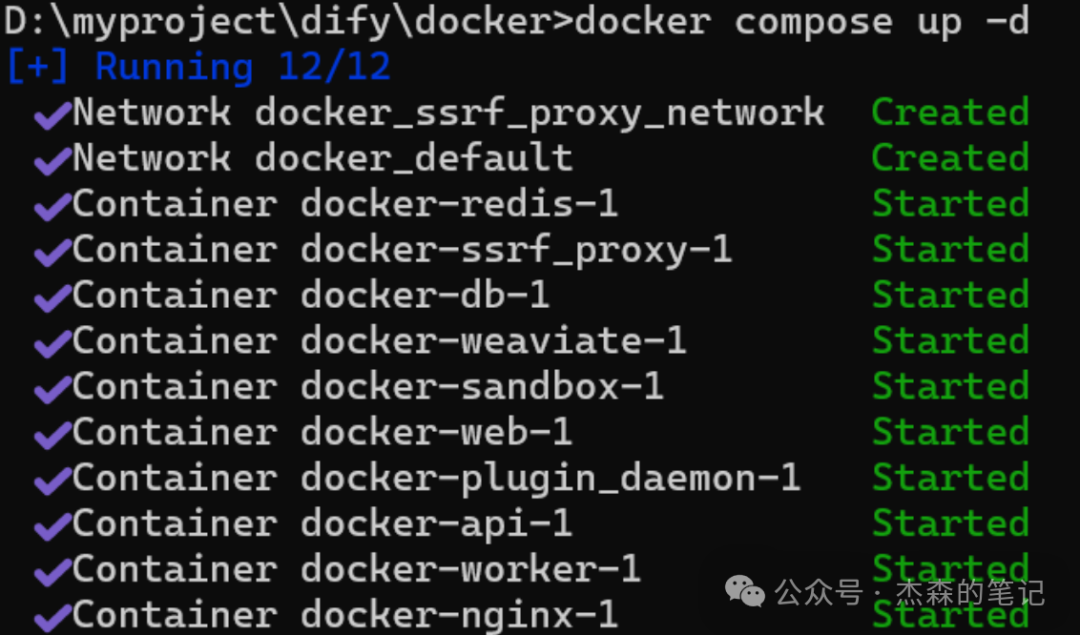
通过以下命令来运行Docker容器启动Dify服务:
docker compose up -d
第四步:在Dify中接入本地Qwen3模型
在浏览器输入地址 http://localhost(如果你配置了自定义端口,记得要加上端口号)打开Dify。
点击右上角 -> 设置 -> 模型供应商,选择Ollama进行安装
安装成功之后,Ollama会出现在“待配置”区域

下面我们来配置Ollama
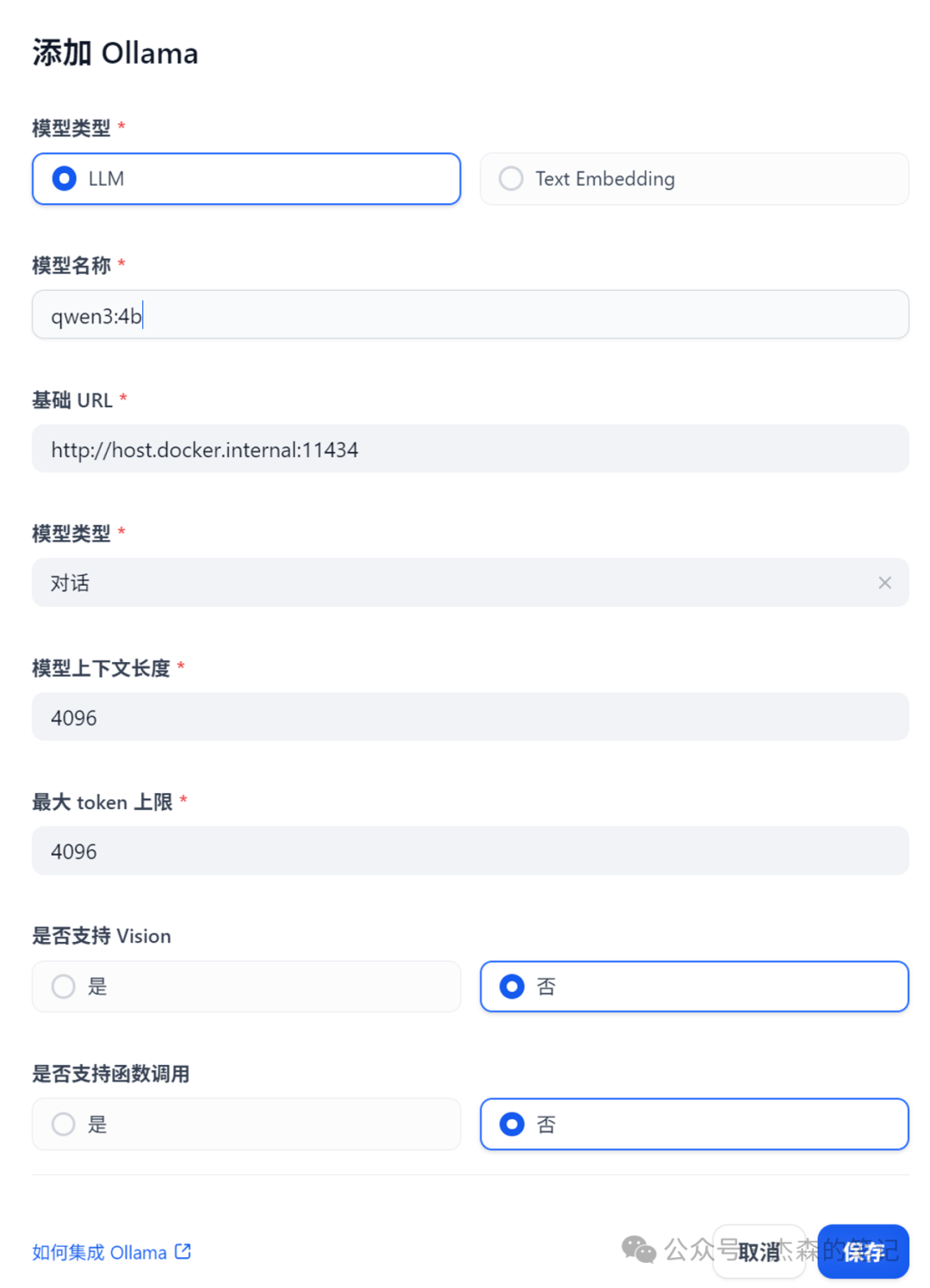
- • 模型名称:qwen3:4b
- • 基础 URL:http://host.docker.internal:11434
- • 模型类型:对话
- • 模型上下文长度:4096
- • 最大 token 上限:4096
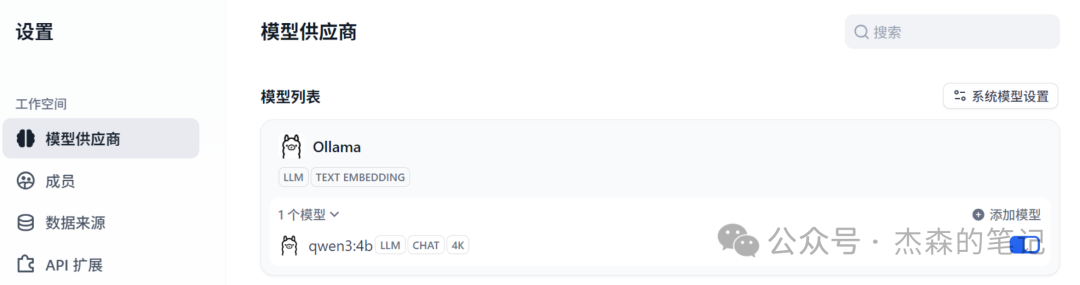
如果遇到添加模型不成功的情况,可以多试几次,或者重启Docker服务
上下文长度选择建议
上下文长度决定了模型能"记住"的对话历史长度:
| 使用场景 | 推荐上下文长度 | 说明 |
|---|---|---|
| 简单问答 | 2k-4k tokens | 适合基础问答,内存占用小 |
| 一般对话 | 8k tokens | 平衡性能与记忆力的良好选择 |
| 文档分析 | 16k-32k tokens | 适合处理长文本、代码分析等 |
| 复杂任务 | 32k-128k tokens | 适用于多文档总结、长文本生成等高级任务 |
最大token上限建议
最大token上限控制模型一次生成的回复长度:
| 使用场景 | 推荐最大tokens | 说明 |
|---|---|---|
| 简短回复 | 256-512 | 适合简单问答,响应快速 |
| 标准回复 | 1024-2048 | 适合一般对话,平衡详细度与速度 |
| 详细解释 | 4096 | 适合复杂问题详细解答 |
| 长文生成 | 8192+ | 适合内容创作、文档生成等 |
第五步:构建医疗问诊初筛系统
接下来,我们在Dify平台中创建医疗问诊应用:
在Dify工作室页面,选择"创建空白应用"
我们选择“聊天助手”并输入应用名称
提示词:
你是一个专业的医疗问诊初筛助手,基于用户的症状描述提供以下服务:
1. **收集结构化症状信息**(按“一般项目→主诉→现病史”顺序)。
2. **初步分析病情**(结合症状特征、持续时间、诱因等)。
3. **提供科室推荐与健康建议**。
#### **交互规则**
- **语言风格**:
- 使用自然口语化中文,避免专业术语堆砌(如“发热”代替“体温升高”)。
- 关键信息加粗显示(如**高烧**、**呼吸困难**)。
- **安全要求**:
- 若症状涉及危急情况(如胸痛、意识模糊),立即触发**红色警示**并推荐急诊科。
- 所有建议标注**免责声明**(模板见下方)。
- **流程逻辑**:
- **首次交互**:引导用户补充必要信息(如年龄、职业)。
- **多轮交互**:根据用户输入动态追问细节(如“能否描述疼痛的具体位置?”)。
#### **用户输入示例**
"我最近三天喉咙痛得厉害,吞咽困难,伴有38℃左右的发热,没有咳嗽。"
#### **模型输出格式**
---
### 🩺 **症状分析**
- **关键词提取**:喉咙痛、吞咽困难、发热(38℃)、无咳嗽
- **初步推测**:
可能为**急性咽炎**或**扁桃体炎**,需进一步检查是否由细菌感染(如链球菌)引起。
- **关联风险**:
若发热持续超过72小时或症状加重,可能引发中耳炎、风湿热等并发症。
---
### 🏥 **科室推荐**
- **主推荐科室**:
🦻 **耳鼻喉科**(最直接匹配)
- **备选科室**:
⚕️ **内科**(病因不明时)|🦠 **感染科**(怀疑传染性疾病)
---
### 💡 **健康建议**
1. **临时措施**:
- 🚰 多喝温水,保持喉咙湿润
- 🥣 避免辛辣刺激食物,可尝试温凉流食(如粥)
- 💊 含服润喉片或淡盐水漱口缓解不适
2. **注意事项**:
- 📉 **监测体温**:若持续高烧或体温超过39℃,需立即就诊
- 🧾 **观察症状变化**:注意是否有皮疹、颈部肿胀或呼吸困难
3. **紧急提示**:
⚠️ **若出现以下情况,请立即前往急诊科**:
- 呼吸困难或吞咽极度困难
- 意识模糊、持续高烧不退
---
### ⚖️ **免责声明**
以上建议仅供参考,具体诊断需由专业医生完成。本系统无法替代面对面医疗检查,如有疑虑请尽快联系医疗机构。
---
#### **进阶功能:多轮交互细化**
若用户描述模糊(如“肚子疼”),主动追问细节:
```text
您能补充疼痛的具体位置(上腹部/下腹部)、持续时间(几小时/天/周)以及伴随症状(如恶心、腹泻)吗?
实际应用效果
部署完成后,我们来测试一下医疗问诊初筛系统:
输入描述:“我最近总是感到头痛,特别是在早上起床后,有时候还伴随着恶心。”
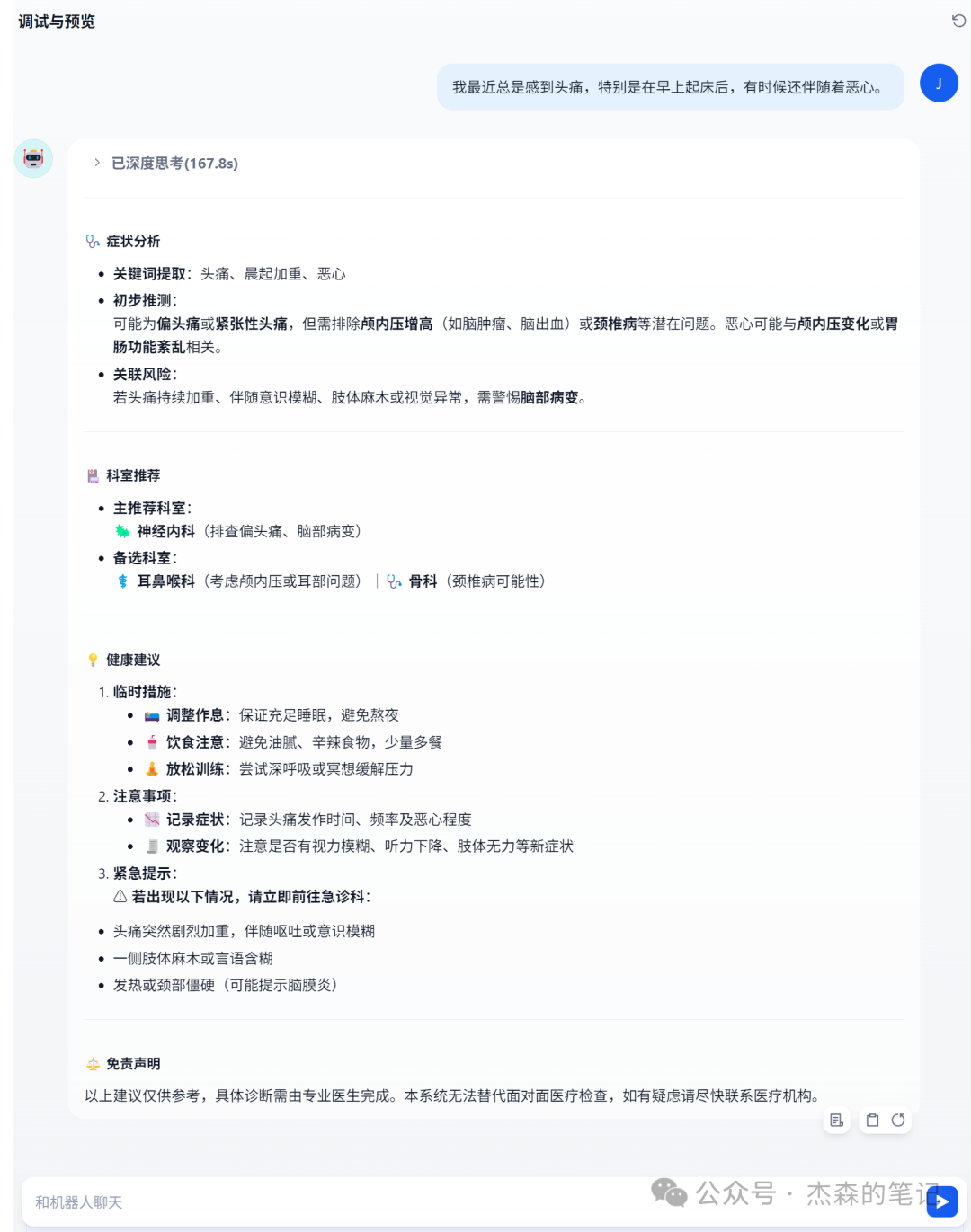
结语
通过本文的学习,我们已经掌握了本地部署Qwen3模型并结合Dify平台,成功构建了一个AI医疗问诊初筛系统。🌟
最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 4744
4744

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









