







题目:DFP-Net: An unsupervised dual-branch frequency-domain processing framework for single image dehazing
DFP-Net:一种用于单图像去雾的无监督双分支频域处理框架
作者:Jianlei Liu, Shilong Wang, Chen Chen, Qianwen Hou
源码:https://github.com/wsl666/DFP-Net.git
论文创新点
-
融合先验与深度学习优势:论文提出的DFP-Net将暗通道先验(DCP)算法嵌入深度学习网络。利用DCP算法在恢复图像可见性方面的优势,结合深度学习方法的强大学习能力,克服了以往方法仅依赖单一技术的局限,有效恢复图像细节和颜色,实现更稳定的去雾效果。
-
双分支频域与空间协同处理:设计了双分支频域处理网络和空间感知融合网络。双分支频域处理网络依据雾气主要存在于低频分量、高频分量包含更多结构信息的特点,分别处理图像的高频和低频信息;空间感知融合网络则进一步融合处理后的频域分量,在空间域增强去雾效果,生成更清晰、自然的去雾图像。
-
解决配对数据稀缺问题:通过结合生成对抗网络(GANs)和对比学习,使用未配对的训练样本对DFP-Net进行训练。这种方式避免了监督学习方法对配对数据的依赖,有效缓解了因缺乏配对样本导致的去雾性能受限问题,提高了模型的适应性和泛化能力。
摘要
无雾图像是许多计算机视觉任务的前提条件,因此单图像去雾在该领域尤为重要。然而,现有的深度学习去雾方法面临以下问题:(1)先前去雾方法在恢复图像可见性方面的巨大潜力被忽视;(2)大多数深度学习去雾方法主要利用空间信息,却忽略了图像不同频域中的信息;(3)由于缺乏成对的有雾和清晰图像,这些方法的去雾能力有限。因此,作者提出了一种新颖的无监督去雾网络DFP-Net,以解决上述三个问题。具体而言,作者将暗通道先验算法嵌入到网络中,结合了先验方法和深度学习方法的优势。精心设计了双分支频域处理网络和空间感知融合网络,共同探索图像不同频域和空间域中的信息。此外,作者结合对比学习和对抗训练,利用未配对的训练样本缓解缺乏配对训练样本的问题。大量实验结果表明,DFP-Net在合成数据集和真实数据集上均优于其他最先进的方法,峰值信噪比(PSNR)提高了约2.8dB,生成的结果在视觉上令人满意,有助于在有雾天气条件下提高图像的可见性。
3. 提出的方法
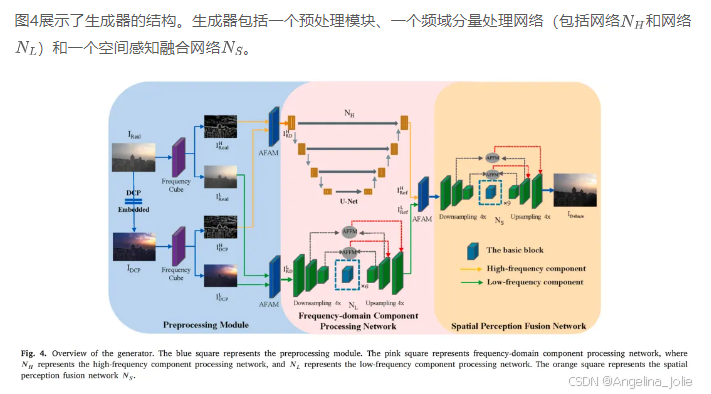
鉴于先验方法和深度学习方法各自的独特优势和局限性,作者提出了一种新颖的图像去雾网络,结合了两者的优点。根据库马尔等人(2022)、朱等人(2020)的研究以及实验分析,雾气通常存在于低频分量中,而高频分量包含更多的结构信息。因此,作者采用双分支结构分别处理图像的不同频域分量。此外,作者设计了一个空间感知融合网络,在空间域进一步恢复无雾图像。尽管配对的清晰和有雾图像稀缺给监督学习方法带来了挑战,但作者利用无监督GAN来克服这一问题。此外,对比学习(陈等人,2022b,2020;金等人,2020;德尼兹等人,2023;王等人,2022a)通过最大化和最小化样本之间的相似性,以无监督的方式提高模型的性能。因此,作者将对比学习融入去雾框架。
3.1 网络架构
去雾网络DFP-Net的完整架构如图3所示。DFP-Net可分为三个部分:生成器、多尺度PatchGAN判别器和像素级对比学习。具体细节将在后续章节讨论。
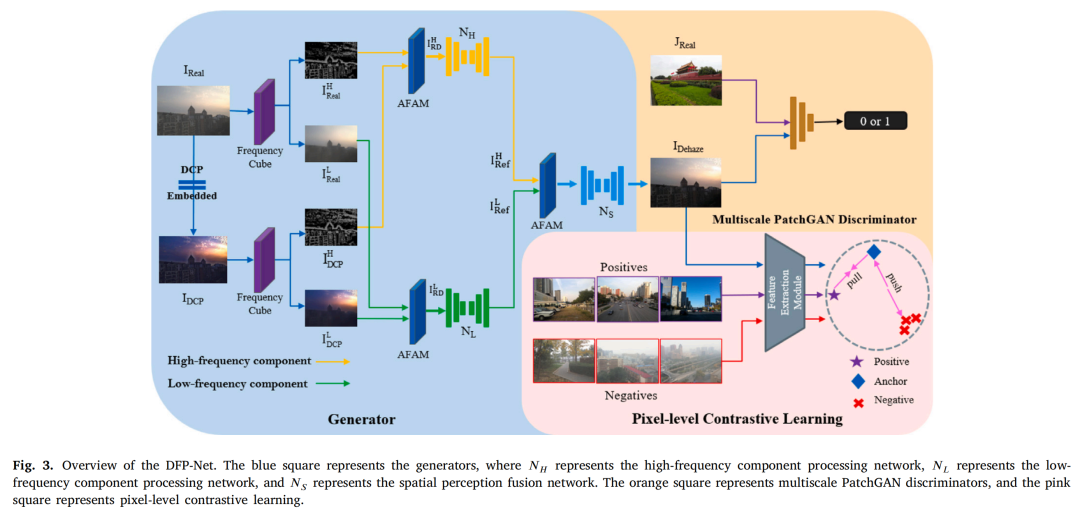
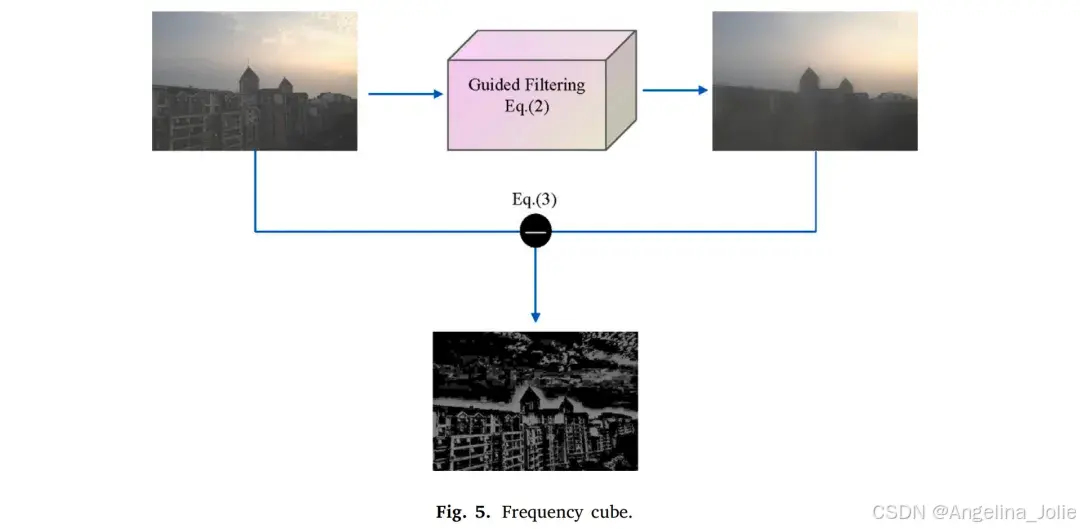
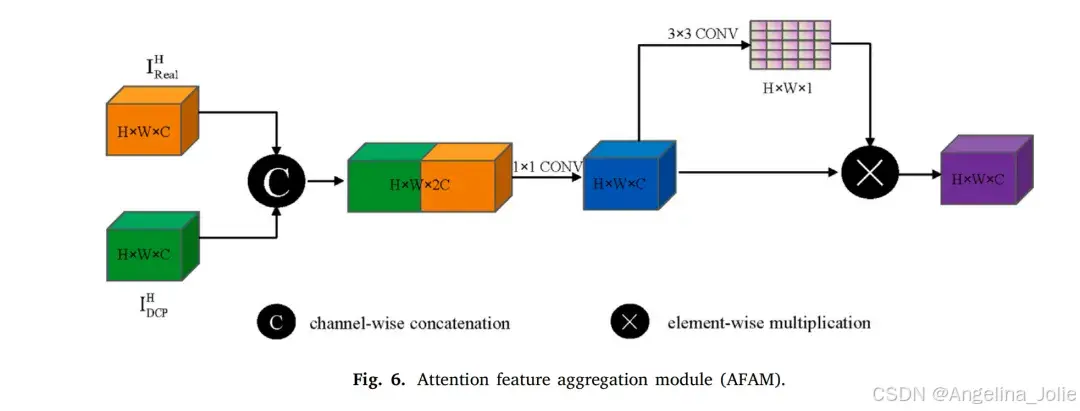
3.1.1 生成器



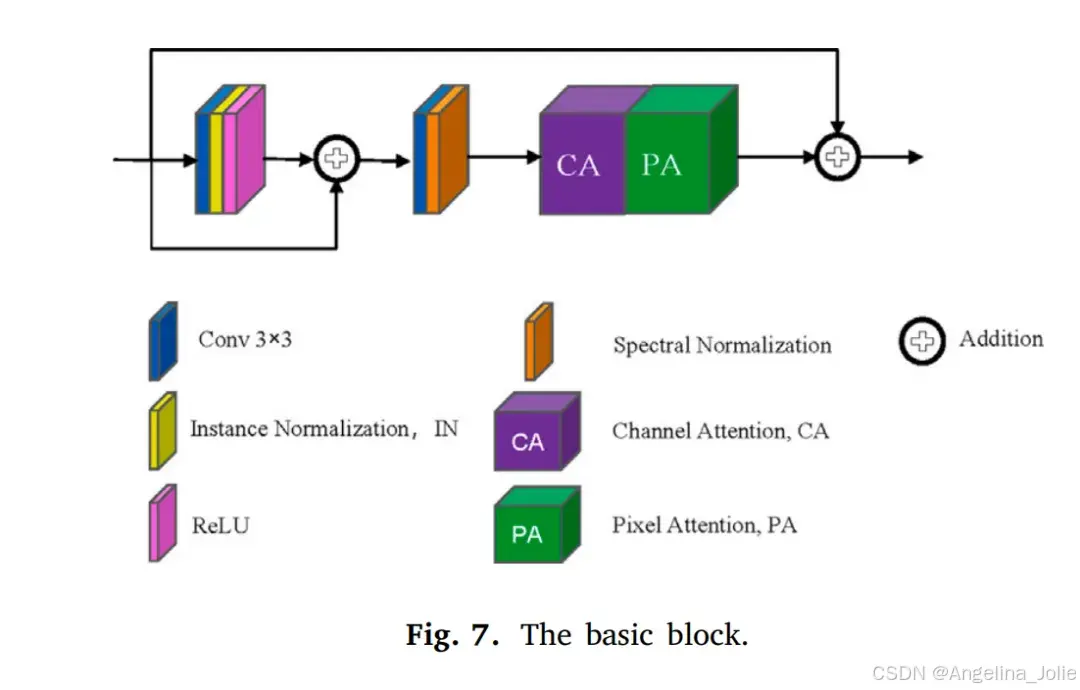

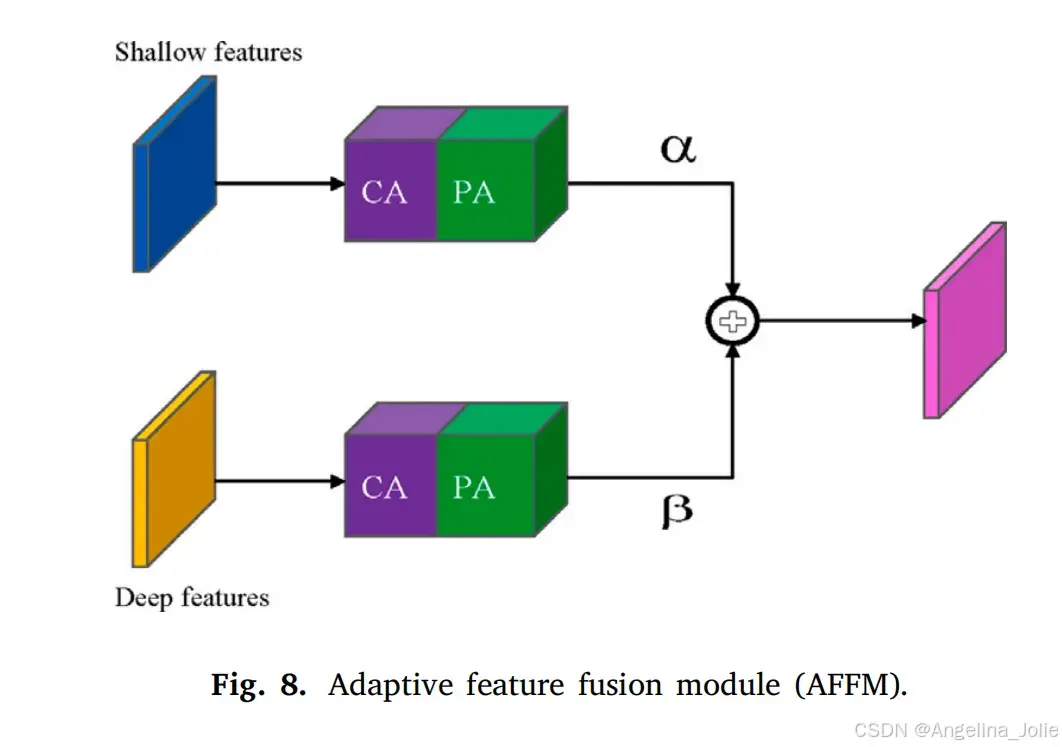

3.1.2 多尺度PatchGAN判别器
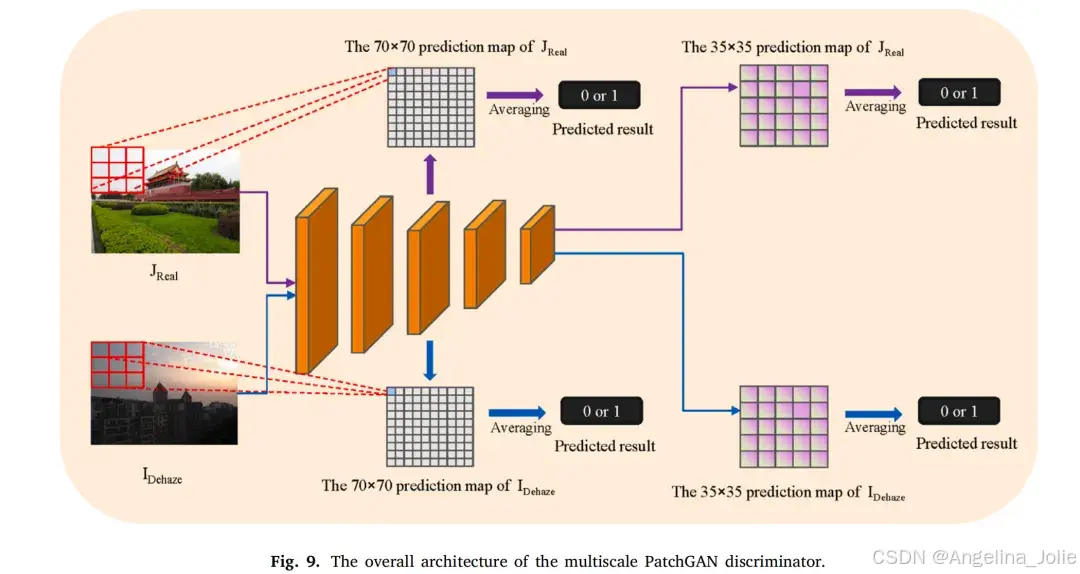
在对抗训练中,作者采用广泛应用的PatchGAN(朱等人,2017;伊索拉等人,2017)作为判别器。它能有效捕捉图像中的详细信息,且比其他传统判别器运算速度更快。相比之下,为从生成器获得更逼真的图像,判别器需要较大的感受野,从全局视角区分生成器生成的图像与真实(GT)图像,这需要深度网络或大卷积核;而为在去雾图像中保留更多细节信息,判别器又需要较小的感受野,从局部视角聚焦于图像的局部边缘和纹理信息。此外,单个判别器难以同时对全局和局部特征提供准确反馈,这可能导致生成器生成的图像质量较低,比如建筑物墙壁纹理失真(常等人,2023;陈等人,2022a)。因此,为解决这两个问题,作者提出了多尺度PatchGAN判别器,如图9所示。较大尺度的判别器感受野大、参数少,负责捕捉全局视角;较小尺度的判别器感受野小、参数多,用于学习图像细节。判别器输入生成器得到的图像,并从数据集中随机选择未配对的GT图像。此外,作者添加谱归一化(宫谷等人,2018)以使训练更稳定。
3.1.3 像素级对比学习
对比学习(吴等人,2021)通过比较不同样本之间的异同来学习特征表示。利用对比学习,模型在嵌入空间中将正样本拉近,将负样本推远,以此学习到一组有意义的特征表示。在该方法中,作者将初步恢复的图像Dehaze作为锚点,从数据集中随机选择一张真实的清晰图像作为正样本,同样从同一数据集中随机选择一张有雾图像作为负样本。该方法使用的正样本和负样本均从数据集中随机选取,彼此不配对。目标是将恢复的图像(锚点)向清晰图像(正样本)拉近,同时远离有雾图像(负样本),如图1所示。作者采用王等人(2022b)提出的一种新颖的逐像素对比感知损失来实现像素级对比学习。

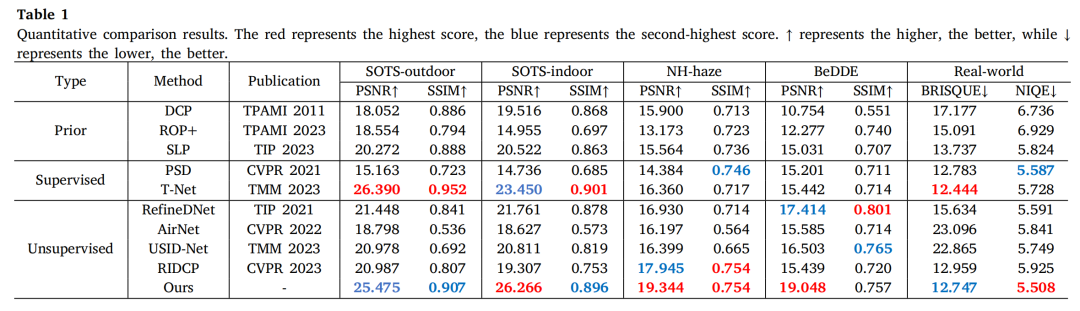
4. 实验
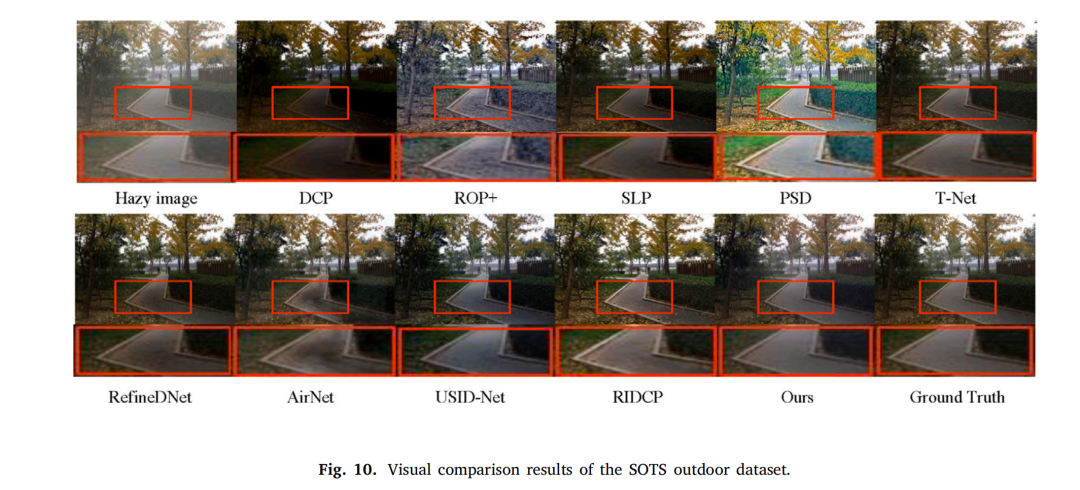
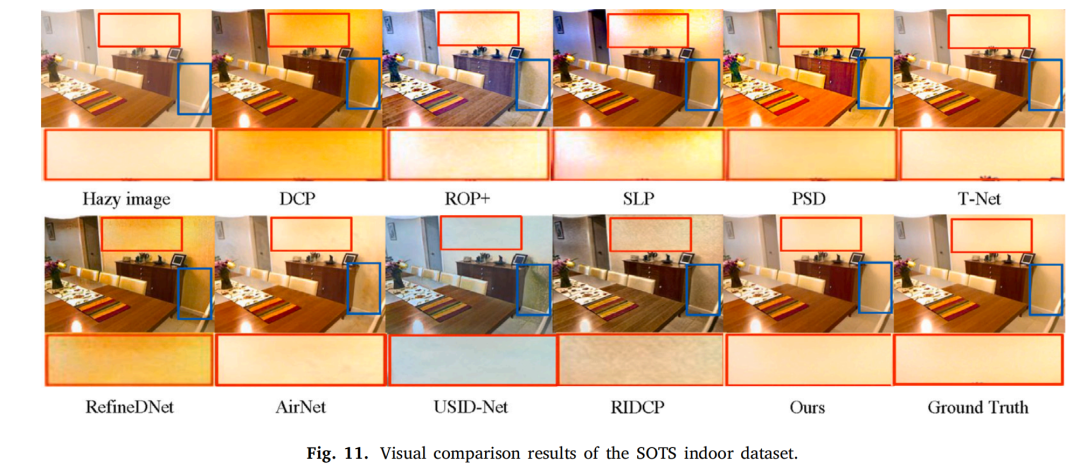



















 1849
1849

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









