






目录
动态规划算法简介
动态规划( D y n a m i c   P r o g r a m m i n g \mathbf{Dynamic\,Programming} DynamicProgramming)算法是用于求解决策过程最优化问题( o p t i m i z a t i o n   p r o b l e m \mathbf{optimization \,problem} optimizationproblem)的数学方法. 与分治算法相似,也是通过组合子问题的解来求解原问题. 但是动态规划算法对每个子问题只求解一次,避免了不必要的重复工作. 如果随后再次出现需要此子问题的解,只需查找保存的结果,而不必重新计算. 实际上动态规划最核心的思想就是: 付出额外的内存空间以节省计算时间(是典型的时空权衡( t i m e \mathbf{time} time − m e m o r y   t r a d e \mathbf{-memory \,trade} −memorytrade − o f f \mathbf{-off} −off)的例子),而节省的时间可能是非常巨大的.
- 动态规划英文中的Programming并不是编程的意思,而是指一种表格法规划的意思.
与分治算法的异同
下面再对分治算法和动态规划算法的异同做出更为详细的讨论:
首先,二者都是分治思想的体现: 即将复杂的原问题分而治之. 先将原问题不断分解成若干较小规模的子问题(小到可以直接求解),然后进行递归地求解,再通过合并子问题的解,产生最终原问题的解.
但对于要使用分治思想的问题中有一类问题,非常不适合使用分治算法直接求解. 即最优化问题(这类问题拥有多个可能的解,而我们希望从中找到一个最满意的解). 因为最优化问题具有重叠子问题( o v e r l a p p i n g   s u b p r o b l e m s \mathbf{overlapping\, subproblems} overlappingsubproblems)的性质(后文会再做详细介绍,简单来说就是存在子问题共享了相同的子子问题),所以如果具有重叠子问题性质的问题使用分治算法,在递归求解过程中对于不同的子问题,就会大量重复计算相同的子子问题,产生非常高的代价.
而动态规划算法正是专门解决此类问题的. 它在求解过程中,对每一个不同的子问题只求解一次. 若之后出现相同的子问题,只需查找保存的结果, 避免了不必要的重复工作.
总之,分治算法用于解决子问题不相交的情况,动态规划算法用于解决子问题重叠的情况.
从具体实现的角度来看,分治算法通常只能利用递归求解问题. 而动态规划方法使用的是一种带备忘功能的递归过程来求解问题. 除此以外,动态规划还有一种非常高效的非递归实现方法——自底向上(后文会详细介绍).
动态规划问题的两大性质
一个可使用动态规划算法求解的最优化问题,应该具备下面两个关键要素: 最优子结构( o p t i m a l   s u b s t r u c t u r e \mathbf{optimal\,substructure} optimalsubstructure)和子问题重叠( o v e r l a p p i n g   s u b p r o b l e m s \mathbf{overlapping\,subproblems} overlappingsubproblems).
最优子结构
一个问题满足最优子结构的性质,当且仅当该问题的最优解由相关子问题的最优解组合而成,而且这些子问题可以独立求解.
- 最优子结构并不是动态规划的特有性质,贪心算法也具有最优子结构.
寻找最优子结构的通用模式
- 你发现得到这个问题的一个解需要至少做出一个选择. 而做出这样的选择会产生一个或多个待解决的子问题.
- 对于一个给定的问题,你假定你已经知道做出哪一步选择会产生最优解(现在你不需要关心这种选择是怎么确定出来的,就假定它已经提供给你了).
- 做出这步选择后,你要确定会产生哪些子问题,以及如何最好地刻画产生的子问题空间.
- 利用"剪切-粘贴"( c u t \mathbf{cut} cut- a n d \mathbf{and} and- p a s t e \mathbf{paste} paste)的方法证明: 这些构成原问题最优解的子问题的解,就是这些子问题的最优解.
- “剪切-粘贴"方法(实际上就是一种反证法): 假定每个子问题的解不是子问题的最优解,然后通过从原问题中“剪切”掉这些"非最优解”,然后“粘贴”新的“最优解”后,得到了原问题一个更优的解. 这就与“用于求解原问题最优解的子问题,它们自身的解就是它们自身的最优解. ”的前提产生矛盾.
以上这个通用模式可能让人难以理解,后文还会通过实例分析比较形象地展现这一过程.
对于不同问题的领域,最优子结构的不同体现在两个方面:
- 原问题的最优解涉及多少个子问题
- 确定最优解使用哪些子问题时,我们要考虑多少种选择.
重叠子问题
适合使用动态规划求解的最优化问题还应该具备第二个性质是子问题空间必须足够“小” (问题的递归算法会反复求解相同的子问题,而不是一直产生新的问题). 如果递归算法反复地求解相同的子问题,我们就称最优化子问题具有 重叠子问题 的性质(与之相对的是,如果递归算法一直产生全新的子问题,那么就适合使用分治方法来求解).
动态规划通常这样利用重叠子问题的性质: 对于每个子问题只求解一次,然后将解存入一个表中. 当再次需要这个子问题时,直接查表得解(每次查表的代价为常量时间).
如何设计一个动态规划算法
设计步骤
下面给出设计一个动态规划算法遵循的步骤:
- 描述一个最优解( a n   o p t i m a l   s o l u t i o n \mathbf{an\,optimal\,solution} anoptimalsolution)的结构.
- 递归地定义出这个最优解的值( t h e   v a l u e   o f   a n   o p t i m a l   s o l u t i o n \mathbf{the\,value\,of\,an\, optimal\,solution} thevalueofanoptimalsolution).
- 计算一个最优解的值,通常采用自底向上( b u t t o m \mathbf{buttom} buttom − u p \mathbf{-up} −up)的方法.
- 利用计算出的信息构造一个最优解.
几点说明:
- 之所以强调是一个最优解,是因为问题的最优解可能不止一个.
- 注意区分最优解和最优解的值两个概念. 最优解指的是能产生最大效益的一组具体方案. 而产生的最大效益本身是最优解的值.
- 第二步实际上就是写出一个得出最优解的值的递归表达式.
- 步骤中的1~3步是动态规划算法求解问题的基础. 如果只需要得到最优解的值,做完前三步即可. 但如果要得到一个最优解的解本身,就需要在执行第3步的过程中维护一些额外的信息,然后利用这些信息,再通过第4步构造出最优解(集).
重构最优解 (Reconstructing an optimal solution)
求得最优解的值后,可能还需要得到解本身(比如对于一个钢条切割问题,通过动态规划算法求得最优解的收益值以后,并没有得到真正的解本身,即给出切割方案的一个长度列表). 这时候就需要扩展动态规划算法. 使之对每个子问题,不仅保存最优的收益值,还保存对应的切割方案. 利用这些信息即可输出最优解.
从实际考虑,我们通常在过程中直接将每个子问题所做的选择存放在一个表中. 这样就不必根据最后得到一个代价值倒回去重构这些信息,产生没必要的代价.
动态规划的两种实现方法
动态规划有两种等价的实现方法.
带备忘的自顶向下法 (Top-down with memoization)
备忘 (Memoization)
我们可以保持自然递归的自顶向下的策略求解动态规划问题(和分治方法一致),但为了避免反复求解重复的子问题,我们在自然低效的递归算法中加入备忘机制. 通过维护一个记录子问题解的表项,随后每次遇到同一子问题时,只需简单查表返回其解即可.
此方法仍按照最自然的递归形式编写过程,但过程中会保存每一个子问题的解(保存在数组或散列表中). 递归过程会首先检查是否已经保存过这个子问题的解,如果保存过,直接返回这个解,否则计算出这个解后保存. 我们就称这样的递归过程为带备忘的(memoized).
自底向上法 (Button-up method)
这种方法不使用递归编写. 而是先将子问题按照规模排序,由小到大地进行求解并逐一保存. 因此和带备忘的自顶向下法一样,自底向上地求解方法也能保证每个子问题只会求解一次. 当求解某个子问题时,它所依赖的子子问题必然已经求解完毕.
两种方法的运行时间比较
上面提到的两种方法拥有相同的渐近运行时间,仅有的差异是: 自顶向下方法并没有真正递归地求得所有可能的子问题(而只是求解了问题需要的子问题). 而自底向上法由于没有频繁调用递归函数的开销,通常时间复杂度具有更小的系数.
实例分析 (钢条切割问题)
本文将通过钢条切割问题( r o d \mathbf{rod} rod − c u t t i n g   p r o b l e m \mathbf{-cutting\,problem} −cuttingproblem)的典型模型来详细分析以上使用动态规划算法步骤中的每一步,以加深对算法的理解:
问题描述
钢条切割问题: 给定一段长度为
 
n
 
\,n\,
n英寸的钢条和一个价格表
 
p
i
 
\,p_i\,
pi(
i
=
1
,
2
,
.
.
.
i = 1, 2,...
i=1,2,...
;
 
;\,
;单位美元),求切割钢条的方案,使销售的收益
 
r
n
 
\,r_n\,
rn最大. (如果待切割钢条的价格
 
p
n
 
\,p_n\,
pn足够大,最优解可能不需要切割.)
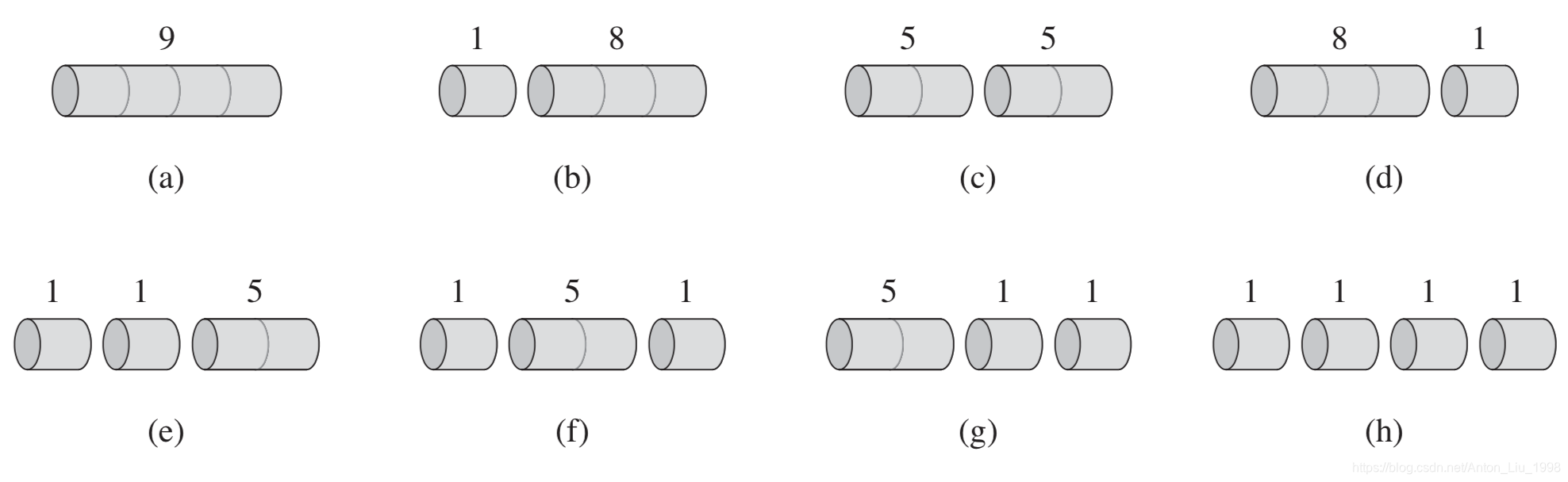
我们首先通过一个例子来认识这个问题: 考虑
 
n
=
4
 
\,n=4\,
n=4的情况(即钢条长度为4),总共有
(
a
)
(a)
(a) ~
(
h
)
(h)
(h) 8种切割方案. 可以发现将钢条切割成两段2英寸的小钢条时,将产生10美元的最大收益(
 
p
2
+
p
2
=
5
+
5
=
10
\,p_2+p_2=5+5=10
p2+p2=5+5=10).
step 1 描述一个最优解的结构
我们不妨用加法符号来表示一个最优解(一个最优的切割方案):
若一个最优解是将钢条切割为
 
k
 
\,k\,
k段长度为
 
i
 
\,i\,
i的小钢条,那么最优切割方案可表示为:
n
=
i
1
+
i
2
+
.
.
.
+
i
k
n=i_1+i_2+...+i_k
n=i1+i2+...+ik
其对应的最大收益表示为:
r
n
=
p
i
1
+
p
i
2
+
.
.
.
+
p
i
k
r_n=p_{i_1}+p_{i_2}+...+p_{i_k}
rn=pi1+pi2+...+pik
如此,我们就通过等式充分地描述了一个最优解的结构.
step 2 递归地定义最优解的值
下面是用表格列举出的长度为 1 ~ 7 1~7 1~7英寸钢条切割问题的最优解的值和对应的最优解:
| 最大收益 r n r_n rn | 最优解 |
|---|---|
| r 1 = 1 r_1 = 1 r1=1 | 1 = 1 1 = 1 1=1 |
| r 2 = 5 r_2 = 5 r2=5 | 2 = 2 2 = 2 2=2 |
| r 3 = 8 r_3 = 8 r3=8 | 3 = 3 3 = 3 3=3 |
| r 4 = 10 r_4 = 10 r4=10 | 4 = 2 + 2 4 = 2 + 2 4=2+2 |
| r 5 = 13 r_5 = 13 r5=13 | 5 = 2 + 3 5 = 2 + 3 5=2+3 |
| r 6 = 17 r_6 = 17 r6=17 | 6 = 6 6 = 6 6=6 |
| r 7 = 18 r_7 = 18 r7=18 | 7 = 1 + 6 7 =1 + 6 7=1+6 或 7 = 2 + 2 + 3 7 = 2 + 2 + 3 7=2+2+3 |
下面我们做一个简单思考: 一根 5 5 5英寸的钢条是如何切割产生最优解的值呢? 对于这条钢条的处理,首先我们可以选择不切割( 5 = 5 5=5 5=5). 如果切割,那么进行第一次切割可以产生   5 = 1 + 4 、 5 = 2 + 3   \,5 = 1+4、5=2+3\, 5=1+4、5=2+3两种结果. 显然最优的切割方案必然产生于以上三种情形之一.
-   5 = 5 \,5 = 5 5=5: 不切割的收益查表可得是 10 10 10美元.
-   5 = 1 + 4 \,5 = 1+4 5=1+4: 产生了两个长度分别为 1 1 1和 4 4 4的小钢条. 为得到最大收益,我们可能需要对两段小钢条再进行切割或者根本不需要切割. 不难想到,这个方案的最优解,一定是由两段小钢条的最优切割方案组成的. 长度为 4 4 4的这段钢条最优切割方案产生的最大收益为 10 10 10. 长度为 1 1 1的这段钢条最优切割方案产生的最大收益为 1 1 1. 二者加起来即为这个方案的最大收益 11 11 11.
-   5 = 2 + 3 \,5 = 2+3 5=2+3: 我们用与   5 = 1 + 4   \,5 = 1+4\, 5=1+4这个情况相同分析的方法得出这个方案的最优解,一定是由长度为 2 2 2和 3 3 3的两段小钢条的最优切割方案组成的. 求得最大收益为 13 13 13.
综合上面三种情形, 5 5 5英寸的钢条切割的最优解的值,即为三者中最大的 13 13 13. 思考过程中对于“这个方案的最优解,一定是由两段小钢条的最优切割方案组成的”这一结论的产生,是十分自然的. 后文还会给出一种反证法证明其正确性.
通过上面的思考,我们就可以用一个递归表达式来定义最优解的值了:
一般地,对于
 
r
n
(
n
⩾
1
)
\,r_n(n\geqslant 1)
rn(n⩾1),我们就可以用更短的钢条的最优切割收益来表示:
r
n
=
m
a
x
(
p
n
,
r
1
+
r
n
−
1
,
r
2
+
r
n
−
2
,
.
.
.
,
r
n
−
1
+
r
1
)
r_n=max(p_n, r_1+r_{n-1}, r_2+r_{n-2},...,r_{n-1}+r_1)
rn=max(pn,r1+rn−1,r2+rn−2,...,rn−1+r1)
- 第一个参数   p n   \,p_n\, pn对应不切割直接售出的方案. 后面的   n − 1   \,n-1\, n−1个参数对应另外的   n − 1   \,n-1\, n−1种切割方案(将钢条切割为   i   \,i\, i和   n − i   \,n-i\, n−i两段. 接着求解这两段的最优切割收益   r i   \,r_i\, ri和   r n − i \,r_{n-i} rn−i).
为了便于后续递归处理,我们还可以用下面这种相似但更为简单的表示方法来定义最优解的值. 是将钢条切割问题分解为: 从左边开始割下长度为
 
i
 
\,i\,
i的一段,然后继续切割右边剩余长度为
 
n
−
i
 
\,n-i\,
n−i的一段(递归求解). 对于不做任何切割的方案可描述为: 第一段长度为
 
n
 
\,n\,
n,收益为
 
p
n
 
\,p_n\,
pn(对应收益为
 
r
0
=
0
 
\,r_0=0\,
r0=0. 于是得到前面方法公式的简化版本:
r
n
=
max
1
⩽
i
⩽
n
(
p
i
+
r
n
−
i
)
r_n=\max \limits_{1 \leqslant i \leqslant n}(p_i + r_{n-i})
rn=1⩽i⩽nmax(pi+rn−i)
这个公式原问题的最优解只包含一个相关子问题的解(前面的方法的子问题基本包含了两个).
step 3 计算最优解的值
下面我们就可以利用定义好的递归表达式进行对最优解的值的求解了.
这里我们先说服自己,使用一般的递归方法求解钢条切割问题会产生很高的代价(因而要采取更高效的动态规划算法),下面给出伪代码:
// 自顶向下的递归实现
CUT-ROD(p, n)
if n == 0
return 0;
q = -∞
for i = 1 to n
q = max(q, p[i] + CUT-ROD(n - i))
return q;
运行后会发现,对于稍大一点的输入规模   n   \,n\, n,运行时间就会变得相当长. 分析可知, C U T CUT CUT- R O D ( p , n ) ROD(p, n) ROD(p,n)显然要考虑所有   2 n − 1   \,2^{n-1}\, 2n−1种可能的切割方案. 其运行时间为指数时间. 可通过证明得到运行时间   T ( n ) = 2 n \,T(n) = 2^n T(n)=2n.
下面我们用两种动态规划的实现方法来求解钢条切割问题:
- 带备忘的自顶向下:
// 带备忘的自顶向下方法实现
MEMOIZED-CUT-ROD(p, n)
let r[0...n] be a new array
for i = 0 to n
r[i] = -∞
return MEMOIZED-CUT-ROD-AUX(p, n, r)
MEMOIZED-CUT-ROD-AUX(p, n, r)
if r[n] >= 0
return r[n]
if n == 0
q = 0
else q = -∞
for i = 1 to n
q = max(q, p[i] + MEMOIZED-CUT-ROD-AUX(p, n - i, r))
r[n] = q
return q
过程MEMOIZED-CUT-ROD将辅助数组   r [ 0.. n ]   \,r[0..n]\, r[0..n]的元素初始化为 − ∞ -\infty −∞,然后调用MEMOIZED-CUT-ROD-AUX过程. MEMOIZED-CUT-ROD-AUX过程就是前面CUT-ROD过程的引入备忘机制后的版本(首先检查所需的值是否已知,如果是,直接返回   r [ n ]   \,r[n]\, r[n],否则计算所需值   q   \,q\, q,再将求得的   q   \,q\, q保存入   r [ n ] \,r[n] r[n]并返回).
- 自底而上
step 4 利用信息构造最优解
由此我们发现,钢条切割问题满足最优子结构的性质:
求解一个规模为
 
n
 
\,n\,
n的原问题,我们需要先求解更小规模,但求解形式完全一样的子问题. 一旦我们完成一次切割,我们就可以把切割后的两段看成独立的两个钢条切割问题的实例. 通过组合两个相关子问题的最优解,并在所有可能的两段切割方案中选择收益最大者,构成原问题的最优解.














 1037
1037











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









