







Large Language Model Cascades with Mixture of Thoughts Representations for Cost-efficient Reasoning 采用混合思维表征的LLMs级联,实现低成本高效率推理
Abstract
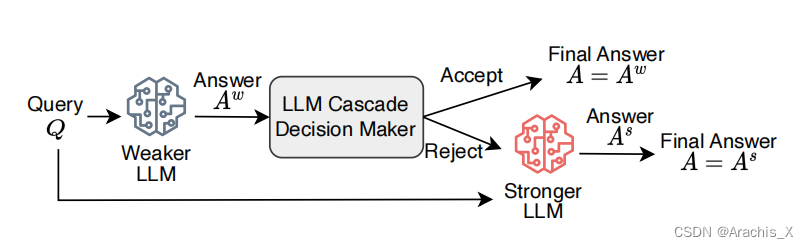
Large language models (LLMs) such as GPT-4 have exhibited remarkable performance in a variety of tasks, but this strong performance often comes with the high expense of using paid API services. In this paper, we are motivated to study building an LLM cascade to save the cost of using LLMs, particularly for performing reasoning (e.g., mathematical, causal) tasks. Our cascade pipeline follows the intuition that simpler questions can be addressed by a weaker but more affordable LLM, whereas only the challenging questions necessitate the stronger and more expensive LLM. To realize this decision-making, we consider the “answer consistency” of the weaker LLM as a signal of the question difficulty and propose several methods for the answer sampling and consistency checking, including one leveraging a mixture of two thought representations (i.e., Chain-of-Thought and Program-of-Thought). Through experiments on six reasoning benchmark datasets, with GPT-3.5-turbo and GPT-4 being the weaker and stronger LLMs, respectively, we demonstrate that our proposed LLM cascades can achieve performance comparable to using solely the stronger LLM but require only 40% of its cost.
GPT-4 等大型语言模型(LLM)在各种任务中表现出了卓越的性能,但这种强大的性能往往伴随着使用付费 API 服务的高昂费用。
在本文中,我们的动机是研究建立一个 LLM 级联,以节省使用 LLM 的成本,尤其是在执行推理(如数学、因果关系)任务时。
我们的级联管道遵循的直觉是,较简单的问题可以用较弱但更经济的 LLM 来解决,而只有具有挑战性的问题才需要较强和较昂贵的 LLM。
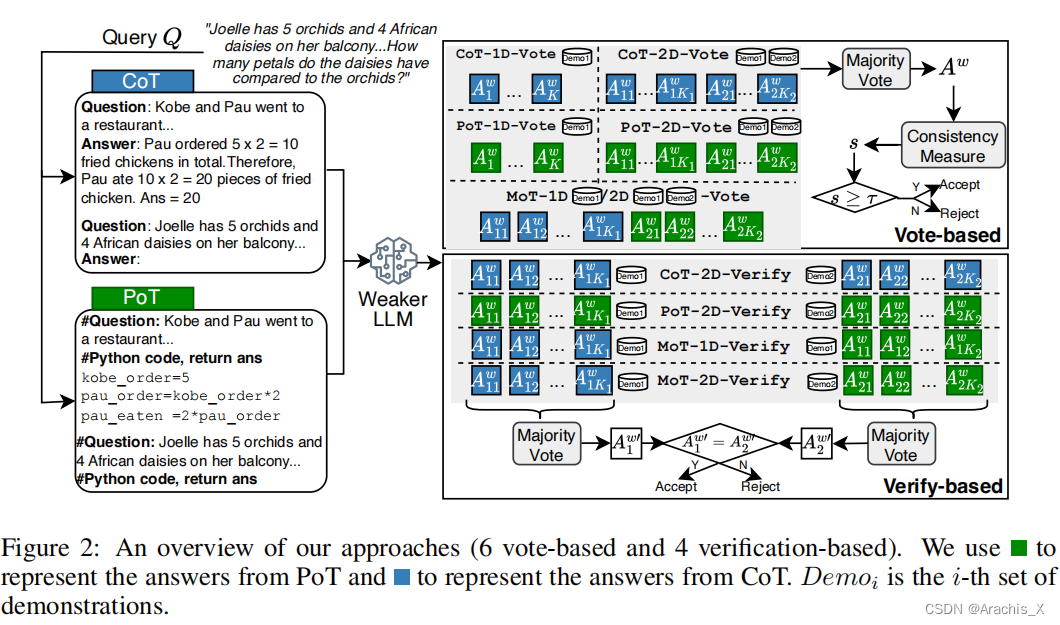
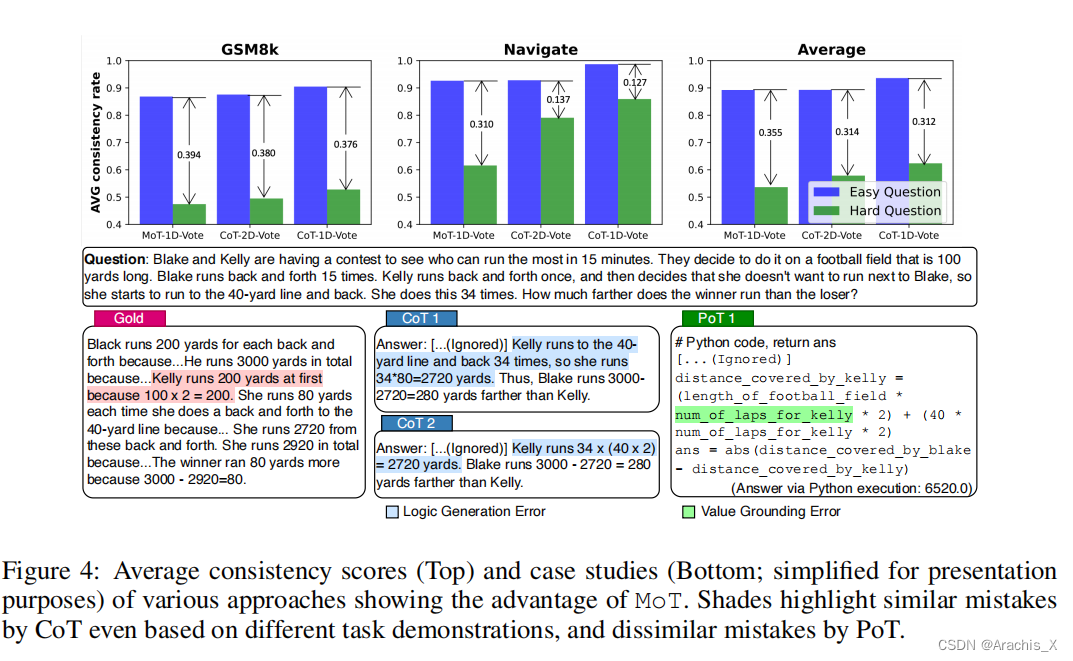
为了实现这一决策,我们将较弱 LLM 的 "答案一致性 "视为问题难度的信号,并提出了几种答案抽样和一致性检查方法,其中包括一种利用两种思维表征(即思维链和思维程序)混合的方法。
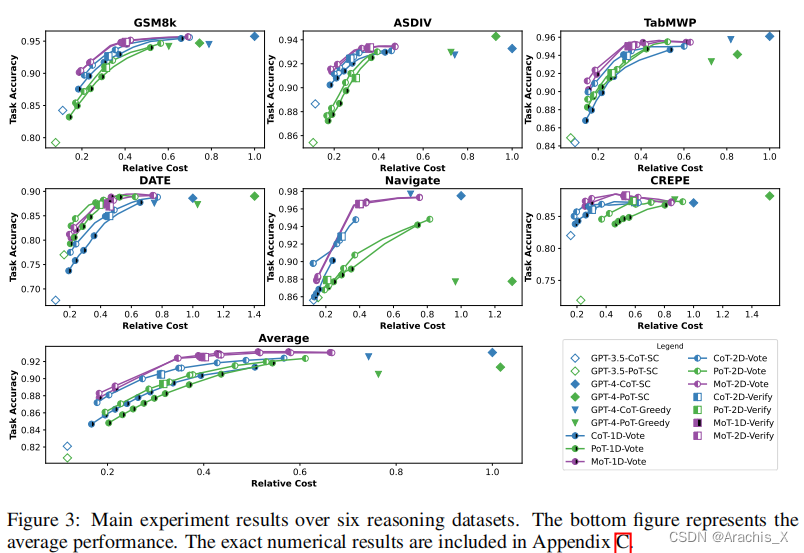
通过在六个推理基准数据集(GPT-3.5-turbo 和 GPT-4 分别为较弱和较强的 LLM)上进行实验,我们证明了我们提出的 LLM 级联可以实现与仅使用较强 LLM 相当的性能,但所需成本仅为其 40%。














 1341
1341











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









