






前言
本文为8月28日计算机视觉理论学习笔记——图像生成,分为三个章节:
- 判别式模型与生成式模型;
- VAE 自编码机;
- GAN。
一、判别式模型与生成式模型
1、判别式模型
已知观察变量 X X X 和隐含变量 z z z,对 p ( z ∣ X ) p(z|X) p(z∣X),根据输入的观察变量 x x x 得到隐含变量 z z z 出现的可能性。
2、生成式模型
对 p ( X ∣ z ) p(X|z) p(X∣z) 建模,输入是隐含变量,输出是观察变量的概率。
- 模型目标:
- 训练数据集的模型: x ∼ p t r a i n ( x ) x\sim p_{train}(x) x∼ptrain(x);
- 生成样本的模型: x ∼ p m o d e l ( x ) x\sim p_{model}(x) x∼pmodel(x);
- 令 p m o d e l ( x ) = p t r a i n ( x ) p_{model}(x) = p_{train}(x) pmodel(x)=ptrain(x).
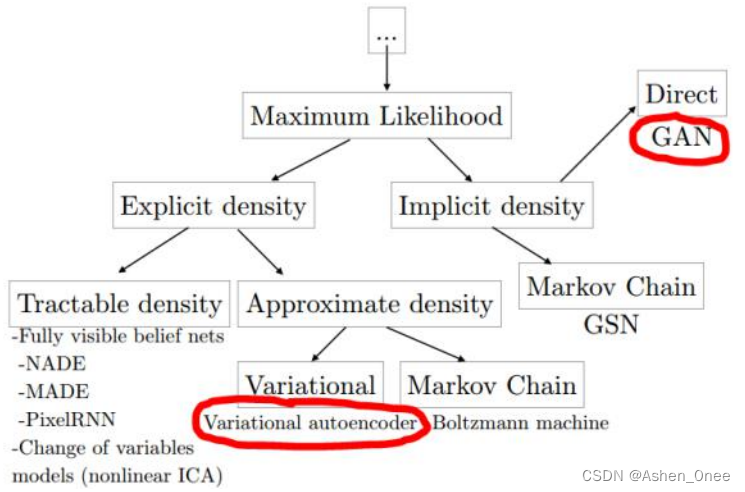
二、VAE 自编码机
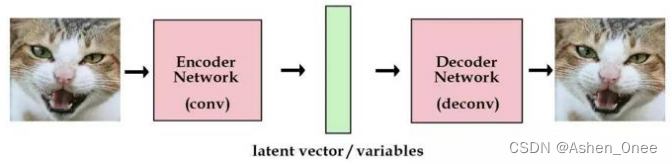
如图所示,左侧把原始图像卷积成向量;解卷积层则把这些向量解码回原始图像。
- 误差包括:
- 生成误差:衡量网络重构图像精确度的均方误差;
- 潜在误差:衡量潜在变量在单位高斯分布上的契合程度;
- 总的目标函数:
L ( x , x ^ ) + ∑ j K L ( q j ( z ∣ x ) ∣ ∣ p ( z ) ) \mathcal{L} (x, \hat{x}) + \sum_{j}\ KL(q_j (z|x)||p(z)) L(x,x^)+j∑ KL(qj(z∣x)∣∣p(z))
三、GAN
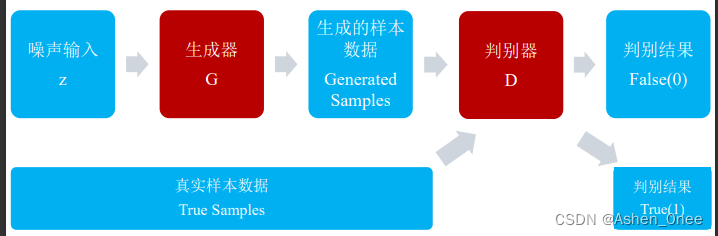
-
Generator: 生成样本数据。
- 输入:高斯白噪声向量 z;
- 输出:样本数据向量 x。
-
Discriminator: 检测样本数据真假。
- 输入:真实或生成的样本数据;
- 输出:真/假标签。
1、CGAN
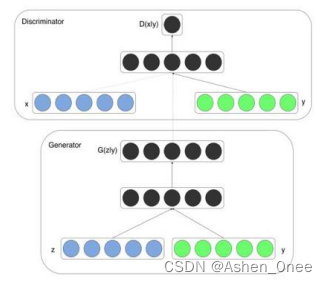
实现方式:
- 在 G 的输入在 z 的基础上连接一个输入 y;
- 然后在 D 的输入 x 基础上也连接一个 y。
2、Wasserstein GAN
相比原始 GAN 改进了:
- D 最后一层去掉 sigmoid;
- Loss 不取 log;
- 每次更新 D 的参数后,把它们的绝对值截断到不超过一个固定常数 c;
- RMSProp / SGD。
3、Super-Resolution GAN
- Generator: 应用分布相同的 B 残差块,每个残差块有两个卷积层。
- 卷积层后加上 Batch-Normalization,用 PReLu 作为激活函数;
- 卷积核 3×3,64 个feature maps;
- 跃层连接。
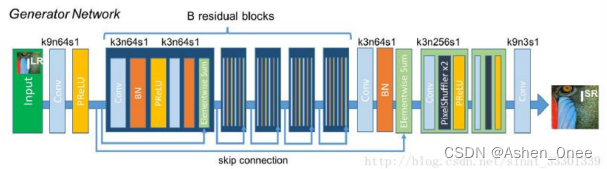
- Discriminator: 由连续的卷积块组成,包括:卷积层、Leaky ReLU层和 BN 层。
- 卷积核 3×3;
- 最后是两个 dense 层,通过 sigmoid 鉴别判断。
















 580
580











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









