







GoogLeNet各种版本
参考资料:https://blog.csdn.net/qq_39297053/article/details/130667442?spm=1001.2014.3001.5502
GoogLeNet往宽度发展,而VGG是往深度发展
背景

V1

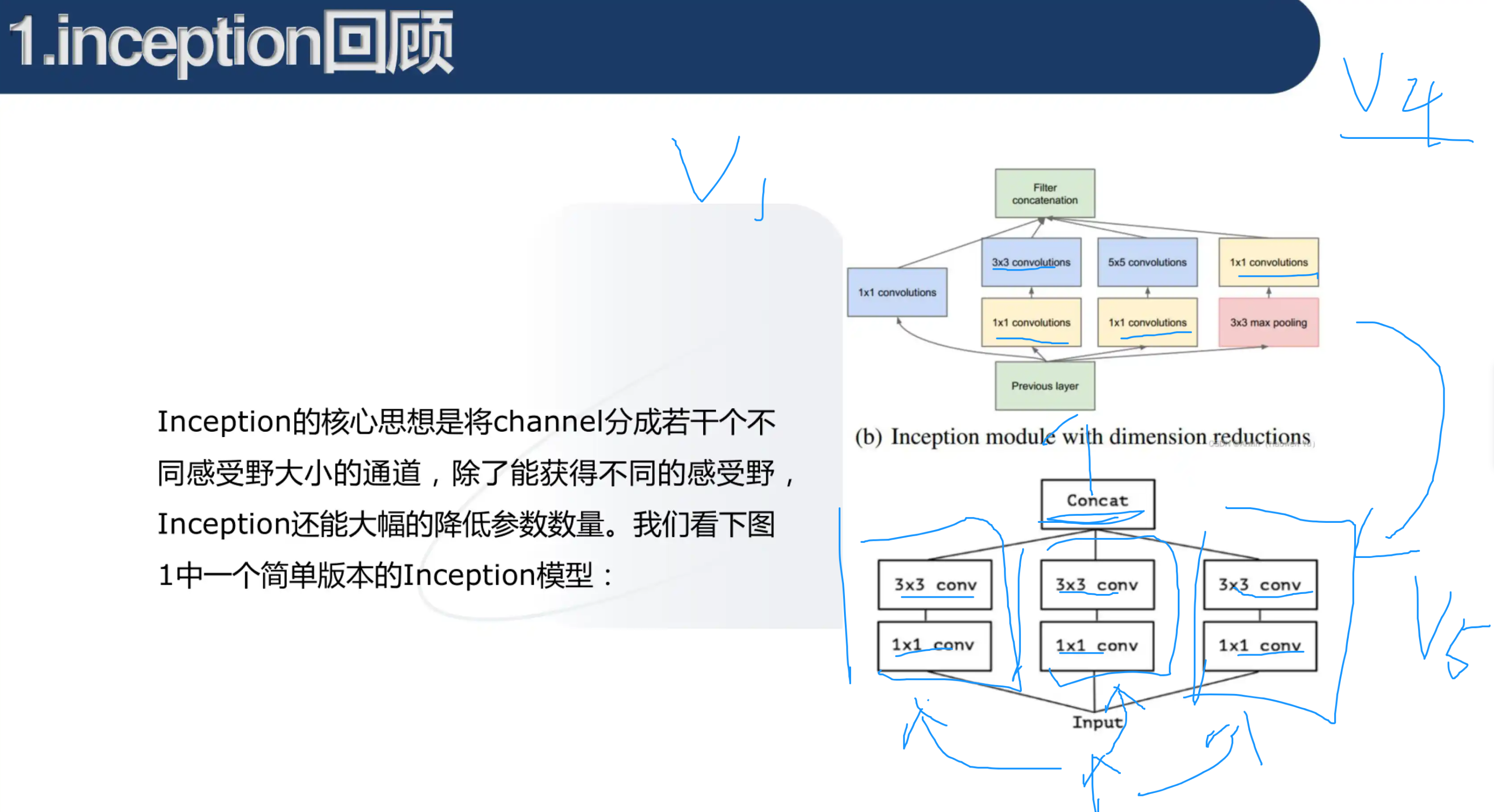
模块化 就是分成好多个stage
辅助分类器 总的损失=loss3+0.3 * (loss2+loss1)
用于向前传导梯度 这个目前没看懂????????????????之后得去看一下梯度下降算法
网络最后采用了average pooling来代替全连接层 ,事实证明可以将TOP1 accuracy提高百分之0.6,而且,average pooling允许网络接收不同大小的图片输入了,在最后还是加了一个全连接层,主要是为了方便以后finetune(微调);

为什么要保证每个stage内部的feature map不变呢??????
这样可以保证可以多次堆叠,就是说我可以一直扩充inception模块
那什么时候会改变feature map的尺寸呢??? 在每个stage之间会有最大池化操作,就可以改变feature map的尺寸
V2

最大贡献:Batch Normalization(BN)
Batch Normalization(BN)。BN在之后的网络模型中频繁出现,成为神经网络中必不可少的一环

减去均值再除以方差
因为初始化的参数一般都是0,所以开始拟合的直线基本过原点附近。
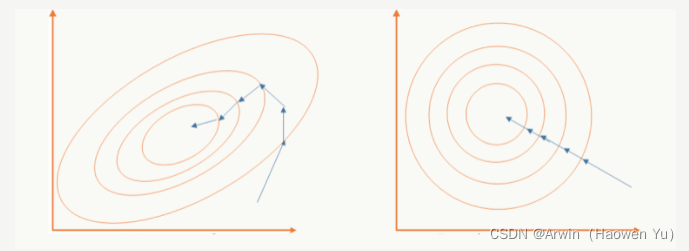
再举一个可视化的解释:BN就是对神经网络每层输入数据的数据分布,做了下面左图不规律的数据分布到右图规则的数据分布的归一化操作。箭头表示模型寻找最优解的过程,显然右图的方式更方便,更容易。
V3
GoogLeNet Inception V3在《Rethinking the Inception Architecture for Computer Vision》中提出,该论文的亮点在于:
-
提出四个通用的网络结构设计准则
-
引入卷积分解提高效率(空间可分离卷积)
-
引入高效的feature map降维方法
-
平滑样本标签
准则1:模型设计者应避免在神经网络的前若干层产生特征表示的瓶颈。
神经网络的特征提取过程包括多层卷积。一个直观且符合常识的理解是:如果网络前面的特征提取过程过于粗糙,那么就可能会丢失细节信息,即使后面的结构再精细也无法有效地进行特征表示和组合。
例如,如果一开始就直接从35×35×320被抽样降维到了17×17×320,那么特征的细节就会大量丢失,即使后续使用Inception结构进行各种特征提取和组合也无济于事。因此,在对特征图进行降维的同时,一般会对channel通道进行升维。
因此,随着层数的加深,特征图的大小应该逐渐变小,但为了保证特征能得到有效表示和组合,其通道数量会逐渐增加。一个简单的理解是:卷积操作就可以在图像的空间维度上进行特征提取,并把提取到的特征转移到channel维度上。

举个例子,stage1是H,W,128,经过最大池化后的stage2会变成H/2,W/2,256,即不想丢失空间上的信息,而是转移到通道维度上
准则2:在模型中增加卷积次数可以解耦更多特征,帮助网络的收敛。
当输出特征相互独立时,输入信息就能被更彻底地分解,而子特征内部相关性就会更高。将相关性强的特征聚集在了一起会更容易收敛。简单点说就是:提取到的特征越多,对下游任务的帮助就越大。
对于神经网络的某一层,通过更多的输出分支,可以产生互相解耦的特征表示,从而产生更多高阶稀疏特征,而加速收敛,具体方法如下。
首先,一个前置小知识:5×5大小的卷积核可以使用两个3×3的小卷积核代替。因为5×5大小的卷积核感受野是5×5=25,而两个3×3的卷积核堆叠在一起时,第一层的感受野是9,第二层的感受野是25,两者感受野相同。同理,3×3 kernel大小的卷积核可以使用一个3×1和一个1×3的小卷积核代替。

所以,为了在网络中增加更多的卷积次数,GoogLeNetV3对inception做了如下改进:首先将inception中的5X5卷积使用两个3X3卷积进行替代,再组合使用1X3和3X1的卷积来替代3X3的卷积。

值得一提的是:一个n×n卷积核可以分解为通过顺序相连的两个1×n和n×1的卷积,这种操作也称空间可分离卷积(有点像矩阵分解),如果n=3,计算性能可以提升1-(3+3)/9=33%。当然,它的缺点也很明显,并不是所有的卷积核都可以拆成两个1×n和n×1卷积核相乘的形式。实际上,作者发现在网络的前期使用这种分解效果并不好,只有在中度大小的feature map上使用效果才会更好。(对于mxm大小的feature map,建议m在12到20之间)。
至于Figure7中的1 x n和 n x 1 的卷积组合方式是并联,是因为作者希望模型变得更宽而不是更深,以解决表征性瓶颈。如果该模块没有被拓展宽度,而是变得更深,那么维度会过多减少,造成信息损失。在General Design Principles的1和2中也有解释。
准则3:对模型的特征维度进行合理的压缩,可以减少计算量

可能前10个feature map很像很像,存在信息冗余
准则4:模型网络结构的深度和宽度(特征维度数)要做到平衡
优化采样操作

优化辅助分类器
GoogLeNetV1中的辅助分类器可以帮助网络训练时回传梯度,并在一定程度上能够起到正则的作用。不过GoogLeNetV3在训练时发现,GoogLeNetV1中的辅助分类器存在问题:辅助分类器在训练初期的时候并不能加速收敛,只有当训练快结束时它才会略微提高网络精度。因此,在GoogLeNetV3版本中,第一个辅助分类器被去掉了。
优化标签
深度学习中通常使用One Hot向量作为分类标签,用于指示分类器的唯一结果。这种标签类似于信号与系统中的脉冲函数,也被称为“Dirac delta”,即只在某个位置上取1,其它位置上都是0。这种方式会鼓励模型对不同类别的输出差异较大的分数,或者说,模型过分相信它的判断。然而,对于一个由多人标注的数据集中,不同人标注的规则可能不同,每个人的标注也可能会有一些错误。模型对标签的过分信任会导致过拟合。
** 标签平滑(Label-Smoothing Regularization, LSR)**是应对该问题的有效方法之一,它的具体思想是降低我们对于标签的信任,例如我们可以将目标标签从1稍微降到0.9,或者将从0稍微升到0.1。

New_labels = (1.0 - label_smoothing) * one_hot_labels + label_smoothing / num_classes
V5
深度可分离卷积(Depthwise Separable Convolution)最初由Laurent Sifre在其博士论文Rigid-Motion Scattering For Image Classification中提出。
这篇文章主要从Inception模块的角度出发,探讨了Inception和深度可分离卷积的关系,以一个全新的角度解释深度可分离卷积。再结合经典的残差网络(详见ResNet),一个新的架构Xception应运而生。Xception取义自Extreme Inception,即Xception是一种极端的Inception模型。
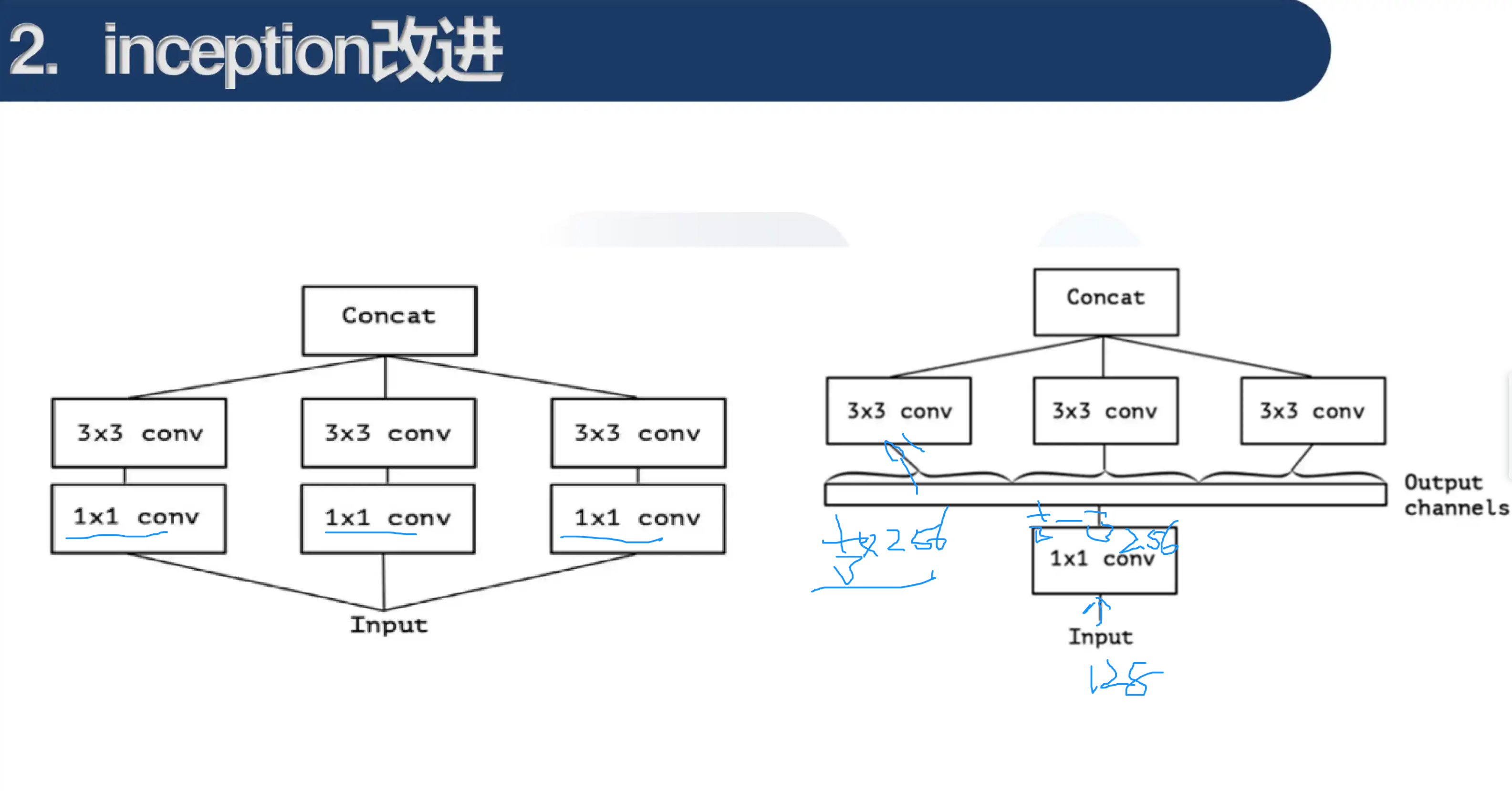
把1 * 1的卷积进行合并。假设得到结果的通道数有256个,则把前三分之一送到第一个3 * 3卷积,三分之一到三分之二的送到第二个,依此类推。
对于一个输入的Feature Map,首先通过三组 1X1 卷积得到三组Feature Map,它和先使用一组 1X1 卷积得到Feature Map,再将这组Feature Map分成三组是完全等价的。
假设图中 1X1 卷积核的个数都是 K1 ,3X3 的卷积核的个数都是 K2,输入Feature Map的通道数为 m ,那么这个简单版本的参数个数为:
m
∗
k
1
+
3
∗
3
∗
3
∗
k
1
/
3
∗
k
2
/
3
=
m
∗
k
1
+
3
∗
k
1
∗
k
2
m*k_1+3*3*3*k_1/3*k_2/3=m*k_1+3*k_1*k_2
m∗k1+3∗3∗3∗k1/3∗k2/3=m∗k1+3∗k1∗k2 (1 * 1卷积后得到
k
1
k_1
k1个通道,分成3份,所以每一个3 *3 卷积核处理的通道数是
k
1
/
3
k_1/3
k1/3,但是此时并不是只有3个3 * 3卷积核,所以每一份3 * 3卷积核处理其中三分之一的通道,总共有
k
2
/
3
k_2/3
k2/3份,所以就是
3
∗
3
∗
3
∗
k
1
/
3
∗
k
2
/
3
3 * 3 *3 * k_1/3 *k_2/3
3∗3∗3∗k1/3∗k2/3)
对比相同通道数,但是没有分组的普通卷积,普通卷积的参数数量为:
m ∗ k 1 + 3 ∗ 3 ∗ k 1 ∗ k 2 m*k_1+3*3*k_1*k_2 m∗k1+3∗3∗k1∗k2(首先是 1 ∗ 1 ∗ m ∗ k 1 1 * 1 * m * k_1 1∗1∗m∗k1 ,然后得到的通道数是 k 1 k_1 k1, 3 ∗ 3 ∗ k 1 ∗ k 2 3 * 3 * k_1 * k_2 3∗3∗k1∗k2)
即普通卷积的参数数量约为Inception的三倍。
Xception

每个卷积核只处理一个feature map,所以假设output的channels为256,那么就需要256个3 * 3的卷积核。即Xception
如果Inception是将 3x3 卷积分成3组,那么考虑一种极端的情况,我们如果将Inception的 1x1 得到的 k1 个通道的Feature Map完全分开呢?也就是使用 k1 个不同的 3x3 卷积分别在每个通道上进行卷积,它的参数数量是
m ∗ k 1 + k 1 ∗ 3 ∗ 3 m*k_1+k_1*3*3 m∗k1+k1∗3∗3( 1 ∗ 1 ∗ m ∗ k 1 1 * 1 * m * k_1 1∗1∗m∗k1,得到 k 1 k_1 k1个通道,每个通道一个3*3卷积, 3 ∗ 3 ∗ 1 ∗ k 1 3 * 3 * 1 * k_1 3∗3∗1∗k1)
这个的参数数量是普通卷积的 1/k,和上面对比可知,k代表3 * 3卷积核的数量。

假设我的图像是5 * 5 * 3,卷积核的尺寸为3 * 3,那么此时我的卷积核的大小应该是3 * 3 * 3(即卷积核的通道数要和输入图像的通道数相同),然后对应通道的进行相乘求和,最后在把每个通道求得的结果求和,得到一张feature map。
总结
作为GoogLeNet系列文章的终章,GoogLeNetV5 模型以实验结果为导向,放弃了GoogLeNetV1-V4中将1×1、3×3、5×5卷积核并列的结构。与GoogLeNetV4中复杂的模型结构相比,Xception这种简单的模型结构反而取得了更好的性能。
代码实现

import torch.nn as nn
class SeperableConv2d(nn.Module):
def __init__(self, input_channels, output_channels, kernel_size, **kwargs):
super().__init__()
## 3*3卷积
self.depthwise = nn.Conv2d(
input_channels,
input_channels,
kernel_size,
groups=input_channels, ##一个3*3卷积核只处理一个通道,所以输入是多少就有多少个3*3卷积核
bias=False,
**kwargs
)
## 1*1卷积
self.pointwise = nn.Conv2d(input_channels, output_channels, 1, bias=False)
## 先经过3*3卷积,再经过1*1卷积?????论文中不是先经过1*1再3*3吗
## 解释:差距其实不大,因为网络是层级结构
## 每一层是堆叠上去的 1*1 3*3 1*1 3*3 1*1 3*3 他可能就是先框中了第2个和第3个,即先3*3再1*1了????
## 可分离卷积:1*1主要用于处理channel通道上的信息,3*3主要用于处理空间上的信息
def forward(self, x):
x = self.depthwise(x)
x = self.pointwise(x)
return x
class EntryFlow(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3, 32, 3, padding=1,stride=2, bias=False),
nn.BatchNorm2d(32),
nn.ReLU(inplace=True)
)
self.conv2 = nn.Sequential(
nn.Conv2d(32, 64, 3, padding=1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True)
)
self.conv3_residual = nn.Sequential(
SeperableConv2d(64, 128, 3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
SeperableConv2d(128, 128, 3, padding=1),
nn.BatchNorm2d(128),
nn.MaxPool2d(3, stride=2, padding=1),
)
## 残差连接,就是论文图片中的那个分支
self.conv3_shortcut = nn.Sequential(
nn.Conv2d(64, 128, 1, stride=2),
nn.BatchNorm2d(128),
)
self.conv4_residual = nn.Sequential(
nn.ReLU(inplace=True),
SeperableConv2d(128, 256, 3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
SeperableConv2d(256, 256, 3, padding=1),
nn.BatchNorm2d(256),
nn.MaxPool2d(3, stride=2, padding=1)
)
self.conv4_shortcut = nn.Sequential(
nn.Conv2d(128, 256, 1, stride=2),
nn.BatchNorm2d(256),
)
#no downsampling
self.conv5_residual = nn.Sequential(
nn.ReLU(inplace=True),
SeperableConv2d(256, 728, 3, padding=1),
nn.BatchNorm2d(728),
nn.ReLU(inplace=True),
SeperableConv2d(728, 728, 3, padding=1),
nn.BatchNorm2d(728),
nn.MaxPool2d(3, 1, padding=1)
)
#no downsampling
self.conv5_shortcut = nn.Sequential(
nn.Conv2d(256, 728, 1),
nn.BatchNorm2d(728)
)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
residual = self.conv3_residual(x)
shortcut = self.conv3_shortcut(x)
x = residual + shortcut ##两个结果 拼接
residual = self.conv4_residual(x)
shortcut = self.conv4_shortcut(x)
x = residual + shortcut
residual = self.conv5_residual(x)
shortcut = self.conv5_shortcut(x)
x = residual + shortcut
return x
class MiddleFLowBlock(nn.Module):
def __init__(self):
super().__init__()
self.shortcut = nn.Sequential()
self.conv1 = nn.Sequential(
nn.ReLU(inplace=True),
SeperableConv2d(728, 728, 3, padding=1),
nn.BatchNorm2d(728)
)
self.conv2 = nn.Sequential(
nn.ReLU(inplace=True),
SeperableConv2d(728, 728, 3, padding=1),
nn.BatchNorm2d(728)
)
self.conv3 = nn.Sequential(
nn.ReLU(inplace=True),
SeperableConv2d(728, 728, 3, padding=1),
nn.BatchNorm2d(728)
)
def forward(self, x):
residual = self.conv1(x)
residual = self.conv2(residual)
residual = self.conv3(residual)
shortcut = self.shortcut(x)
return shortcut + residual
class MiddleFlow(nn.Module):
def __init__(self, block):
super().__init__()
self.middel_block = self._make_flow(block, 8) ##重复8次
def forward(self, x):
x = self.middel_block(x)
return x
def _make_flow(self, block, times):
flows = []
for i in range(times):
flows.append(block())
return nn.Sequential(*flows)
class ExitFLow(nn.Module):
def __init__(self):
super().__init__()
self.residual = nn.Sequential(
nn.ReLU(),
SeperableConv2d(728, 728, 3, padding=1),
nn.BatchNorm2d(728),
nn.ReLU(),
SeperableConv2d(728, 1024, 3, padding=1),
nn.BatchNorm2d(1024),
nn.MaxPool2d(3, stride=2, padding=1)
)
self.shortcut = nn.Sequential(
nn.Conv2d(728, 1024, 1, stride=2),
nn.BatchNorm2d(1024)
)
self.conv = nn.Sequential(
SeperableConv2d(1024, 1536, 3, padding=1),
nn.BatchNorm2d(1536),
nn.ReLU(inplace=True),
SeperableConv2d(1536, 2048, 3, padding=1),
nn.BatchNorm2d(2048),
nn.ReLU(inplace=True)
)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
def forward(self, x):
shortcut = self.shortcut(x)
residual = self.residual(x)
output = shortcut + residual
output = self.conv(output)
output = self.avgpool(output)
return output
class Xception(nn.Module):
def __init__(self, block, num_classes=100):
super().__init__()
self.entry_flow = EntryFlow()
self.middel_flow = MiddleFlow(block)
self.exit_flow = ExitFLow()
self.fc = nn.Linear(2048, num_classes)
def forward(self, x):
x = self.entry_flow(x)
x = self.middel_flow(x)
x = self.exit_flow(x)
x = x.view(x.size(0), -1) ##把[[........]] 调整成 [..........]
x = self.fc(x) ##最后还有一个全连接层
return x
def xception(num_classes):
return Xception(MiddleFLowBlock, num_classes=num_classes)















 145
145











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









