






万字综述:全面梳理 FP8 训练和推理技术 -- 附录
原创 AI闲谈 AI闲谈 2024年07月21日 20:02 北京
一、背景
在上一篇文章(万字综述:全面梳理 FP8 训练和推理技术)中我们通过几篇论文具体介绍了 FP8 的发展历程以及在 AI 模型训练和推理中的应用。然而由于篇幅的原因,部分内容并没有具体展开,这篇文章中我们对其补充,并结合代码来介绍。
二、FP8-LM:FP8 梯度和 AllReduce 通信
我们在介绍 [2310.18313] FP8-LM: Training FP8 Large Language Models 时提到其有 FP8 通信,FP8 优化器,以及 FP8 分布式并行训练 3 个方面的优化,但没有具体介绍 FP8 通信是怎么实现的(这个部分比较晦涩),这里进行补充。
如果有 N 个 GPU 要进行梯度聚合,直接使用 FP8 梯度进行梯度聚合会导致精度降低。
如下图所示为 pre-scaling 方案,在求和之前先分别除以 N,此时容易出现 Underflow 的问题:
![]()
如下图所示为 post-scaling,其主要区别是在求和之后再除以 N,此时容易出现 Overflow 的问题:
![]()
作者提出了相应的优化方案,假设有 4 个 GPU 要进行梯度的聚合,分别有 FP16 的梯度:
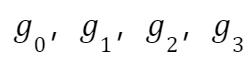
假设最终聚合后的 FP16 梯度为:
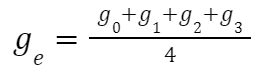
每一个 FP16 的 Tensor 要转换为 FP8,都是由(FP8 的 Tensor,Scale 值)共同表示。上述 FP16 的 Tensor 对应的 FP8 表示为:

如果想要直接使用 FP8 进行 AllReduce,则需要有一个全局的 Scale 值,否则 Reduce 就不等价了。对应的全局 scale 变量如下所示,其中使用 min 可以避免 Overflow:
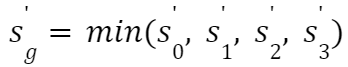
复原后的 FP8 梯度如下所示(等价于 FP16 梯度使用相同的 Scale):
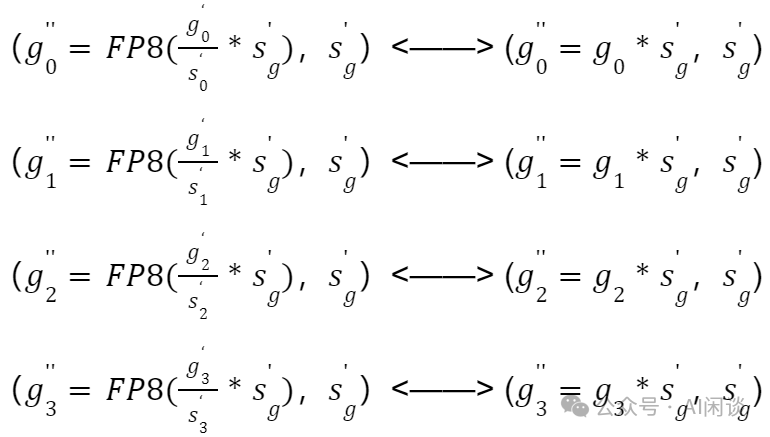
通过 AllReduce 聚合后的 FP8 梯度可以表示为:
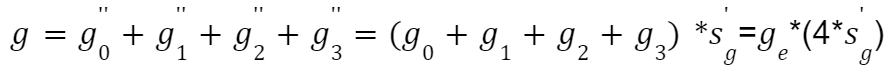
所以,相当于 ge 的 FP8 表示如下所示,这里有个 Trick,聚合后的梯度并没有除以 N,而是让 Scale 值乘以 N:
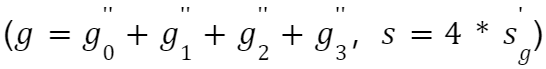
作者论文中为什么会介绍 μ 值(Auto Scaling)呢?应该是想要控制
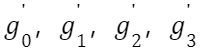
都尽量在 FP8 的范围内(PS:开源代码里并未实现),比如:
-
如果发现
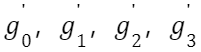
中有超过 0.001% 超过了 FP8 表示的最大值(PS:这里是因为 Delayed Scaling 导致?如果每个 Tensor 都使用 Just-in-time Scaling 是不是就都不会超过?),则下一次迭代的时候让
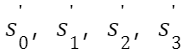
都变为原来的 1/2,降低 Overflow 的风险。
-
如果在接下来的 1000 次迭代中都没有出现超过 0.001% 的情况,则让
的指数增加 2,降低 Underflow 的风险。
三、FP8 梯度聚合代码实现
上述对应的代码位于 :msamp/nn/distributed.py#L124-L193。如下图所示:
第一步:collect 相应的 Gradient,并初始化 Meta(维护 Scale,amax 相关信息):

第二步:分别求每个 Gradient 的 amax(绝对值的最大值),然后 AllReuce 操作获得全局的最大值,这里求 max 是因为 Scale 一般为 FP8 可表示的最大值 / amax,也就等价于求 Scale 的 min:

第三步:根据全局最大 amax,FP8 可表示的最大值等计算全局 Scale 值,其中的 world_size 也就是 N:
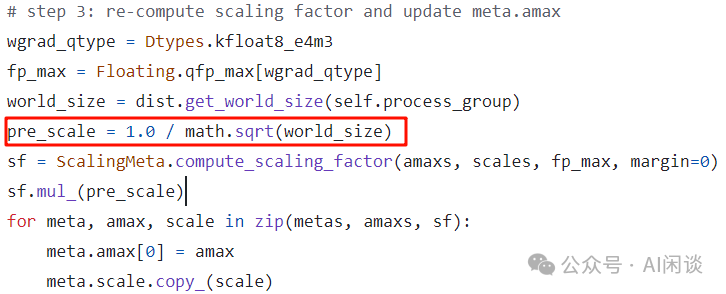
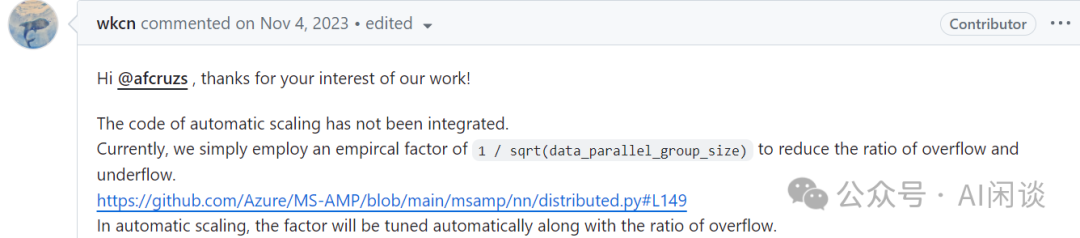
需要说明的是,这里本来应该是 Auto Scaling,也就是对应上述 μ 值的部分,然而作者实际上并没有集成 Auto Scaling,而是使用了经验值 1/sqrt(N),以缓解 Underflow 和 Overflow。可以参考:https://github.com/Azure/MS-AMP/issues/117:
第四步:将 FP16 的 Tensor 转换为 FP8 的 Tensor:
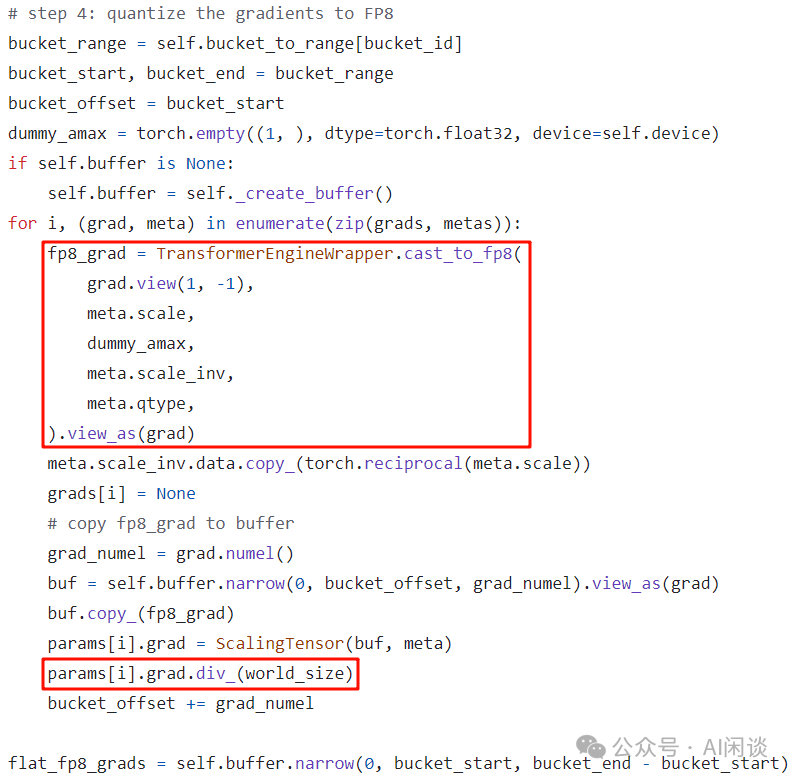
如上图所示存在 Gradient 除以 N 的操作,然而,因为 Gradient 为 ScalingTensor,所以实际除的时候是操作的 Scale 值,如下图所示:
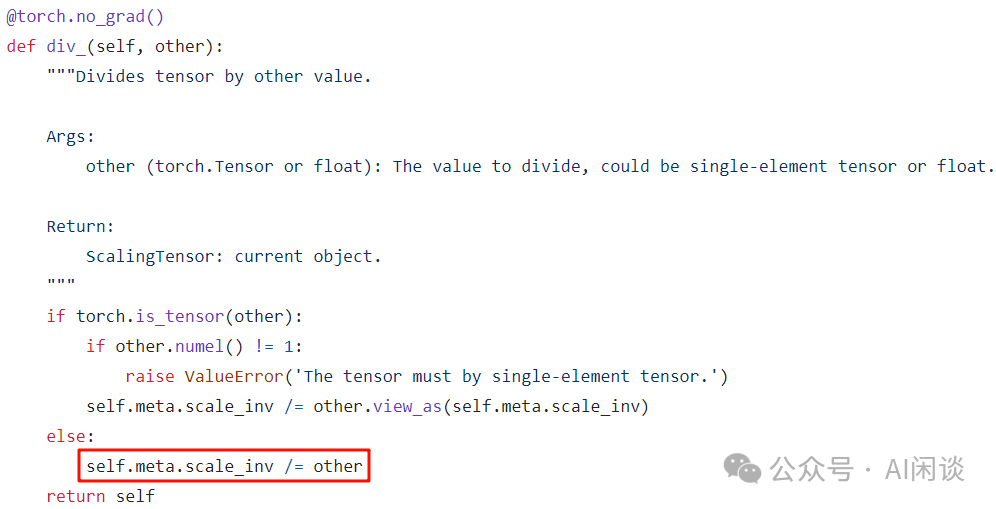
第五步:对 FP8 Gradient 进行 AllReduce 操作:

四、FP8 训练和推理过程
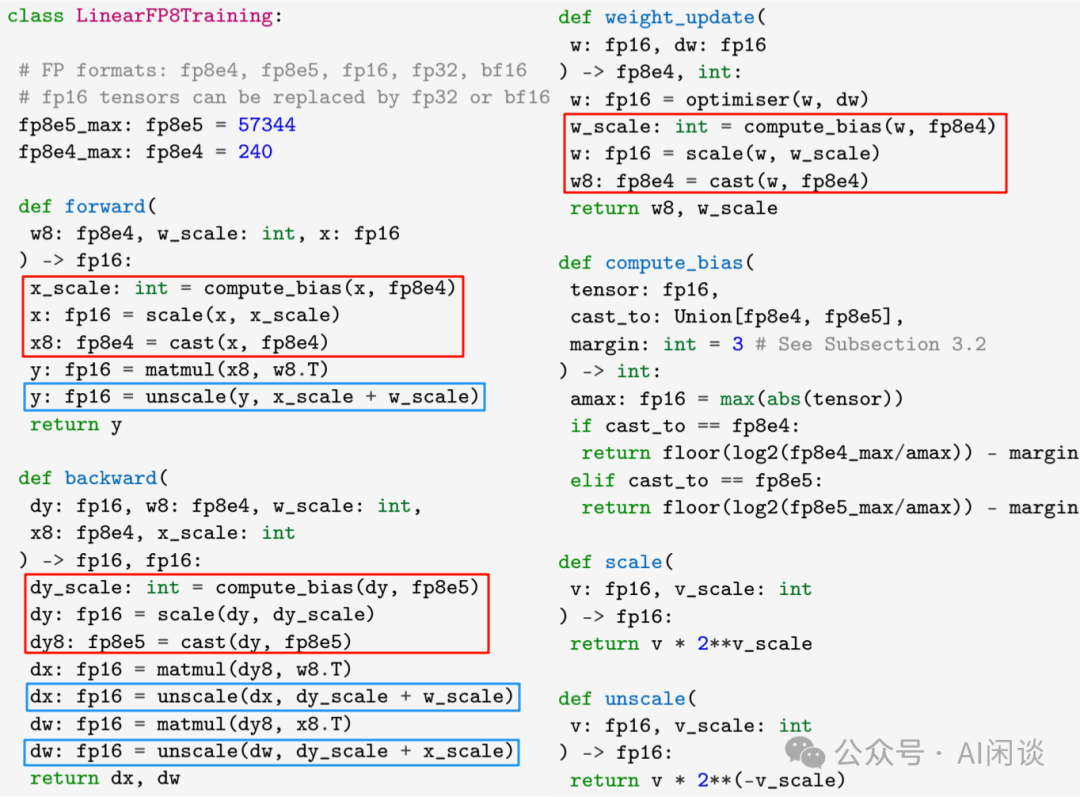
Transformer 模型中最主要的操作就是矩阵乘,也就是 Linear Layer,如下图所示(来自 [2309.17224] Training and inference of large language models using 8-bit floating point)为一个 Linear 操作的伪代码,其核心思路就是在 FP8 矩阵乘之前需要转换的 Tensor 转换为 FP8 类型,如下图红框所示;然后在矩阵乘之后 Unscale 回 FP16,如下图蓝框所示:
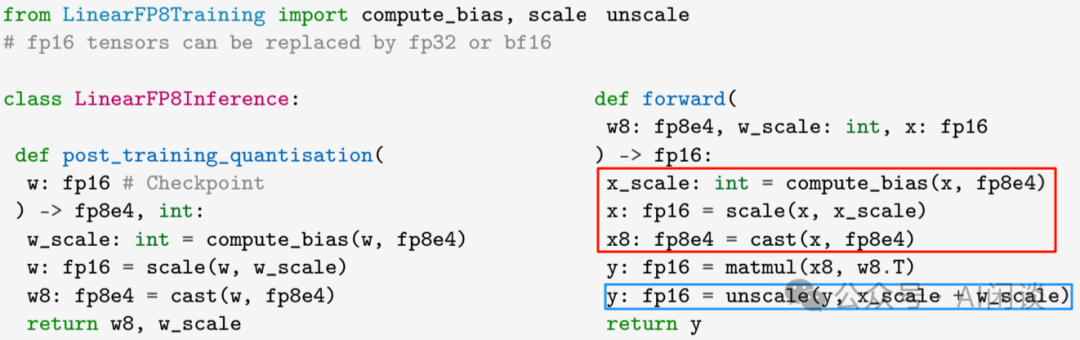
而在推理阶段只用离线的的对 Weight 转换一次,Forward 的时候只需对 x 进行相应的 Scale 操作:
五、Scaling 实现方式
在之前的文章中我们介绍过 Scaling 的实现方式,这里在简单概括一下:
-
Static Scaling:提前离线计算好每个 Tensor 的 Scale,然后一直不变。为了保证精度,这种方式通常用于推理阶段的 Weight,如下图所示:

-
Dynamic Scaling:每次都实时计算每个 Tensor 的 Scale,好处是比较精确,不足是这些计算全部是同步的,如下图所示:

-
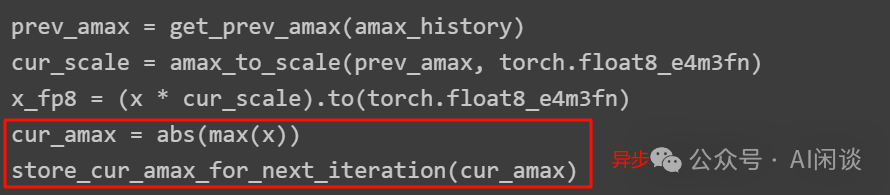
Delayed Scaling:会保存一些之前的多个 Scale 值,计算当前 Tensor 时根据以前的多个 Scale 预估当前 Scale,然后进行 Scaling 操作,同时异步的计算当前的 Scale 值,但是其实现也比较复杂,无状态变为有状态,如下图所示:
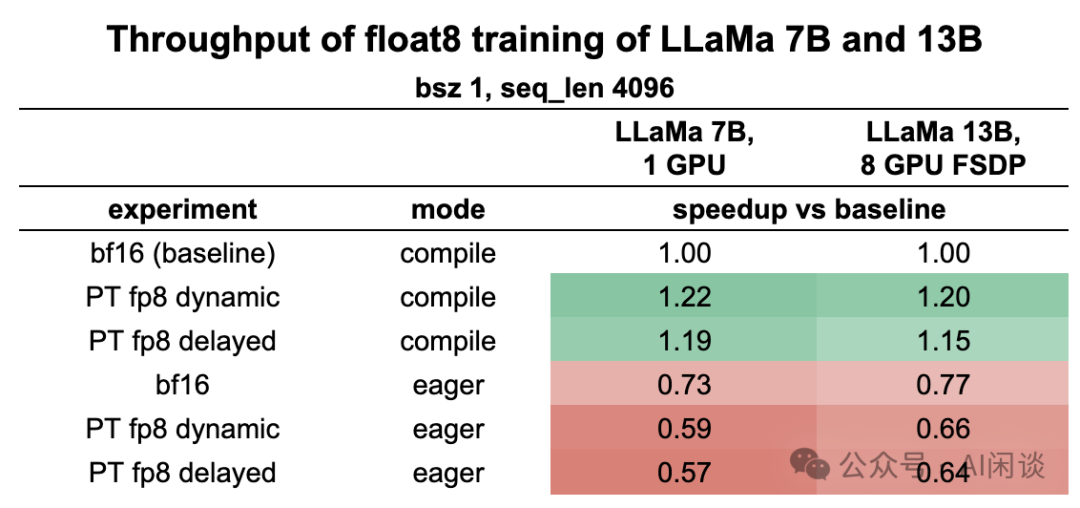
在 Pytorch 的 FP8 实现中(https://github.com/pytorch-labs/float8_experimental/tree/main),早期的测试表明 Delayed Scaling 反而比 Dynamic Scaling 慢,当然也非常接近:
六、参考链接
-
https://arxiv.org/abs/2310.18313
-
https://github.com/Azure/MS-AMP/blob/main/msamp/nn/distributed.py#L124-L193
-
https://github.com/Azure/MS-AMP/issues/117
-
https://arxiv.org/abs/2309.17224
-
https://github.com/pytorch-labs/float8_experimental/tree/main
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











