






arXiv 202503
摘要
-假新闻,特别是deepfakes(生成的非真实图像或视频内容)在过去几年中已经成为一个严肃的话题。随着机器学习算法的出现,现在比以往任何时候都更容易生成这种虚假内容,即使是对私人来说。生成的虚假图像的问题在政治和公众人物的背景下尤其重要。
我们希望通过构建基于卷积神经网络的模型来解决这一冲突,以便检测此类显示人类肖像的生成和伪造图像。作为基础,我们使用预训练的ResNet-50模型,因为它在分类图像方面很有效。然后,我们采用基本模型来将单个图像分类为真实图像。通过添加一个包含单个神经元的全连接输出层来识别真实的或虚假的图像。我们应用微调和迁移学习来开发模型并改进其参数。在训练过程中,我们收集了图像数据集“多样化的人脸伪造数据集”。包含各种不同的图像处理方法,以及图像上可见人脸的多样性。最终模型达到了以下出色的性能指标:精确度= 0.98,召回率0.96,F1-Score = 0.97和曲线下面积= 0.99。
索引术语- ResNet-50,迁移学习,二进制分类,多样化的人脸假数据集,概率密度函数
一、引言
假新闻--世界范围内最流行、最受欢迎、但也是最具问题的话题之一。假新闻可能已经存在了数千年,但近年来变得越来越重要。特别是由于互联网,假新闻的使用和传播最近呈指数级增长。特别是年轻人使用互联网上的社交媒体平台来了解自己并保持最新。
这在政治和公众人物的背景下变得尤为重要
假新闻过去只以假文本的形式出现,但现在已不再局限于这种单一格式:一个名为deepfake的新范围也可以算作假新闻。这个术语是“深度学习”和“假”的组合。因此,Deepfake指的是使用生成机器学习算法伪造内容,通常是图像和视频。由于这些算法不断变得更好,更便宜,私人对这种媒体的创造和使用也在稳步增加。使用Deepfake技术,可以像以前一样更快地创建和分发包含全新和非真实的内容的图像和视频形式的假新闻。
虽然机器学习工具通常被开发用于在机器人、自主系统或语音模型领域创建创新解决方案,但它们也可以用于创建深度伪造,使其变得越来越真实和真实的。例如,在图像中,人们的某些特征或面部表情可以被改变,甚至整个面部可以被另一个人的面部取代。通过这样做,deepfake具有误导性,并极大地影响了当前的公共业务,如全球选举。因此,可靠地检测此类deepfake内容变得越来越重要,但同时也越来越复杂。
随着机器学习算法(尤其是神经网络)被用于生成此类图像,类似的技术似乎也可以用于识别深度假货。为了应对深度假货的滥用,正在开发基于机器学习的工具来可靠地检测生成的图像。然而,由于快速改进的生成工具和有限的训练数据等原因,这些技术也存在局限性。
尽管如此,许多商业机器学习工具在deepfake检测方面非常有前途。
目前的研究项目集中在Deepfake检测领域,提供了有希望的结果。例如,Rossler等人在[5]中介绍了一种用于检测被操纵的面部图像和视频的高级基准数据集。该数据集支持四种操纵方法,如DeepFakes(目标人脸替换的具体方法),Face 2Face(表情转移,同时保持人的身份),FaceSwap(将面部区域或完整面部转移到目标人物)和NeuralTextures(基于机器学习优化的面部重现)。基于这个基准,他们比较了不同的知名网络架构,将deepfake分类为真实/真实的或伪造。最好的训练模型,XceptionNet架构(即,所有通道的深度可分离卷积,包括ResNet中的快捷方式),实现了高达99.26%的二进制检测精度[5]。然而,XceptionNet架构通常不理想,尤其是对于较小的数据集,因为它们是计算密集型的,并且存在过拟合的风险[6]。
不像传统的方法使用整个脸在 Deepfake检测任务,Tolosana等人在[7]中探索了一种使用部分面部线索的方法。这种方法使用特定的面部部位,如眼睛,鼻子或嘴巴来区分真假。对于传统方法,同样,Xception模型表现最好,曲线下面积(AUC)得分高达100%。相反,对于第二种方法,基于人脸眼睛区域的胶囊网络(即动态路由以捕获数据中的空间层次和关系)也实现了100%的最高AUC分数[7]。然而,这些类型的网络是计算密集型的,并且具有复杂的模型结构[8].
本文旨在通过一种简单而准确的机器学习算法,在将deepfake图像分类为真实或虚假的领域做出贡献。
我们使用ResNet-50模型[9]作为我们模型的基础。这个神经网络由50个参数可采用的卷积层组成,每三层配对一个剩余连接。网络的顶层用于拟合输入图像,而最后一个全连接层则由两个特定于此任务的层取代:一层为扁平层,一层为1-d完全连接的密集层。最后一层由具有S形激活函数的单个输出神经元组成。因此,输出显示真实图像被呈现的单个概率,因此用作分类器。基于Diverse Fake Face Dataset(DFFD)[10],训练模型的AUC评分为0.9931,F1评分为0.9715
II.方法
我们使用ResNet-50模型[9]作为基线构建我们的模型,并将其应用于我们的任务。为了训练,我们使用DFFD数据集应用迁移学习。这些方面将在下面的章节中详细解释。
A model
ResNet-50模型[9]是一种残差卷积神经网络模型,它使用先进的模型架构来解决训练深度神经网络时出现的退化问题。在神经网络中添加更多层来构建深度网络,会导致准确性饱和,并在某些时候迅速退化。这种影响不是过拟合的结果,而是由训练深度神经网络的困难引起的。
为了抵消这种退化问题,剩余网络使用身份捷径[9] [11]。
这些快捷方式通过将跳过连接应用到网络的特定部分(如图1所示的剩余块),允许信息直接通过网络流动。通过将构建块的输入添加到其输出,快捷方式跳过了包含在这样一个块中的层。这确保了来自输入图像或来自先前层的重要信息被原封不动地转发到网络中的更深层。
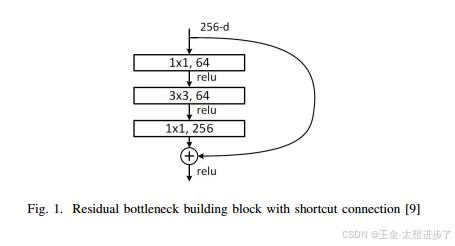
用于特征提取的卷积层与快捷连接的组合允许ResNet-50解决退化和消失梯度问题,并在图像分类任务中实现高精度。[9] [11]图1.具有快捷连接的剩余瓶颈构建块[9]总的来说,ResNet-50模型由50个参数可训练层组成,这些层以特定的方式构造。三个卷积层总是组合在一起形成所谓的“瓶颈”构建块,图1所示。1x 1卷积层减少并随后增加,以恢复维度,而中间的3x 3层负责特征提取。多个块堆叠在一起形成整个网络。
表I在左边显示了ResNet-50模型的架构,在右边显示了我们采用的模型。图1中显示的一个构建块在表中的括号中显示,右侧显示了堆叠块的数量。堆叠的构建块按输出大小分组,并从'conv 1'命名为'conv 5 x'。在这里,“x”表示每组中堆叠的积木块的递增数量。所有堆叠的积木块一起形成整个模型。
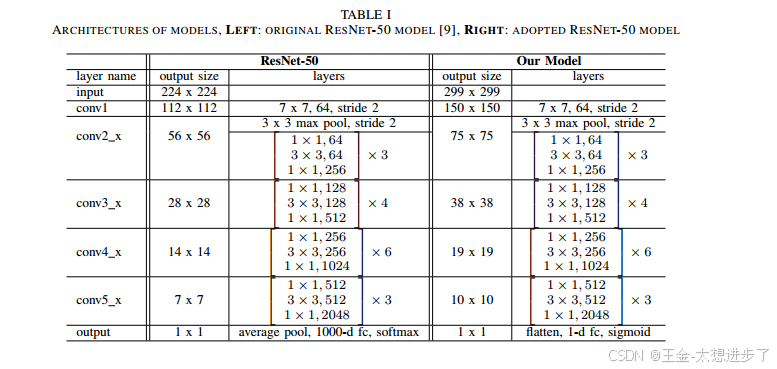
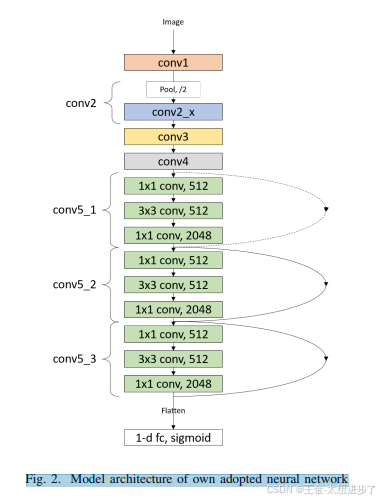
图2显示了我们采用的模型的架构。为了清晰起见,“conv 1”到“conv 4 x”的堆叠块仍然被分组在一起。作为示例,包含单个卷积层的“conv 5”块以及跳过每个构建块的快捷连接被展开以显示更多细节。每组块之间因此,受影响的快捷方式(虚线)需要采用先前输出的大小,以通过应用附加滤波器来与下一个块的输入大小匹配

















 2040
2040

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









