






DWA(Dynamic Window Approach)算法是一种用于机器人路径规划的算法,它由Andrew Kelly和Lydia E. Kavraki于1996年提出。DWA算法特别适用于在动态环境中进行机器人的实时路径规划,如无人驾驶汽车、无人机(UAV)和移动机器人等。以下是DWA算法的详细解释:
1. 算法原理
DWA算法的核心思想是在机器人的控制空间中搜索一个可行的控制序列,使得机器人能够在避免碰撞的同时,尽可能快速地达到目标位置。
2. 算法步骤
DWA算法通常包括以下步骤:
2.1 初始化
- 确定机器人的初始位置和目标位置。
- 定义机器人的动力学模型和运动学约束。
2.2 控制空间采样
- 在给定的时间间隔内,从控制空间中随机采样一系列的控制输入(如速度、加速度、转向角等)。
2.3 预测模型
- 对于每个采样的控制输入,使用机器人的动力学模型预测未来一段时间内机器人的位置和姿态。
2.4 碰撞检测
- 对于每个预测的未来状态,检查是否存在碰撞风险。这通常涉及到与环境障碍物的几何关系检查。
2.5 评估和打分
- 对于每个未发生碰撞的预测状态,使用一个代价函数进行评估。代价函数通常考虑以下因素:
- 距离目标的接近程度
- 路径的平滑性
- 控制输入的大小(以减少能耗或避免剧烈动作)
2.6 选择最佳控制
- 从所有未发生碰撞的预测状态中,选择具有最低代价的控制输入作为当前步的最佳控制。
2.7 执行控制
- 将选择的最佳控制输入应用于机器人,使其向目标方向移动。
2.8 更新状态
- 根据机器人的实际运动更新其位置和姿态。
3. 算法特点
- 实时性:DWA算法能够快速响应环境变化,适合实时路径规划。
- 动态性:可以处理动态环境中的障碍物。
- 简单性:算法实现相对简单,易于理解和实现。
- 灵活性:可以通过调整代价函数来适应不同的应用场景。
4. 局限性
- 采样密度:控制空间的采样密度影响算法的性能。过高的采样密度会增加计算负担,而过低则可能导致局部最优解。
- 预测时间:预测的时间窗口也会影响算法的效率和准确性。
- 代价函数设计:代价函数的设计对于算法的性能至关重要,需要根据具体应用进行调整。
DWA算法是一种在机器人路径规划领域广泛使用的算法,它通过在控制空间中搜索最优解,能够在复杂环境中实现有效的路径规划。然而,它也有一些局限性,如对采样密度和预测时间的敏感性,以及对代价函数设计的依赖性。在实际应用中,需要根据具体情况对算法进行调整和优化。
二维DWA代码可以参考B站https://b23.tv/rGKUTW;
这里主要展示三维的DWA代码。
DWA_3D.m(主函数)
clear;
clc;
%句柄函数,求距离需要使用
calcuDis = @(x,y) sqrt((x(1)-y(1))^2+(x(2)-y(2))^2+(x(3)-y(3))^2);
%%定义无人机初始状态
startPoint = [0 0 0];
endPoint=[100 100 100];
v0=[0 0 0];
% v0=[3 4 3];
%定义初始状态
x = [startPoint v0];
%%定义障碍物
%静态障碍物
sphereInfo.exist = 0;
sphereInfo = creatSphereObject(sphereInfo);
%边界限制,防止无人机调整时跑出边界
axisStart = [0 0 0];
axisLWH = [105 105 105];
% global dt;
dt = 0.1;%时间,每条路径由多个值构成,dt为每个点之间的时间间隔
paraT=3;%前向模拟的时间
%%无人机运动学参数
vMax = [5,5,5];%各轴最大速度
acc = [2,2,2];%各轴加速度
VResolution = 0.05;%速度分辨率,用于轨迹推算
model = [vMax acc VResolution];
%评价函数参数[heading,dist,velocity,predictDT]
%航向得分比重,距离得分比重,速度得分比重,向前模拟轨迹的时间
evalParam = [0.1,0.1,0.1,3.0];
%模拟实验的结果
result.x=[];
result.x=[result.x;x];
k3=0;
colorMatSphere = [0 0 1];%颜色
pellucidity = 0.6; %透明度
%主循环
for k2=1:2000
xt=x;
[u,trajDB] = dynamicWindowApproach(x,model,dt,paraT,endPoint,sphereInfo,evalParam);
%无人机移动到下一时刻的状态量,包括速度和加速度
x(1)=x(1)+u(1)*dt;
x(2)=x(2)+u(2)*dt;
x(3)=x(3)+u(3)*dt;
x(4)=u(1);
x(5)=u(2);
x(6)=u(3);
% x
k3=k3+1;
%记录结果
result.x=[result.x;x];
%判断是否到达了终点
distToGoal = calcuDis(x(:,1:3),endPoint);
if distToGoal <=3
disp('==========Arrive Goal!!==========');
break;
end
%%画图显示效果
plot3([result.x(k2,1) result.x(k2+1,1)],[result.x(k2,2) result.x(k2+1,2)],[result.x(k2,3) result.x(k2+1,3)],'*R');
hold on;
%画出起点和终点
scatter3(startPoint(1),startPoint(1),startPoint(1),'MarkerEdgeColor','k','MarkerFaceColor',[1 0 0]);
scatter3(endPoint(1),endPoint(2),endPoint(3),'MarkerEdgeColor','k','MarkerFaceColor','b');
text(startPoint(1),startPoint(1),startPoint(1),'起点');
text(endPoint(1),endPoint(2),endPoint(3),'终点');
%画出所有的障碍物
drawSphereObject(sphereInfo,colorMatSphere,pellucidity);
grid on;
axis equal;
axis([0 105 0 105 0 105]);
xlabel('x')
ylabel('y')
zlabel('z')
drawnow limitrate;
disp(k3);
end
creatSphereObject.m (创建障碍物,该部分代码与RRT中定义障碍物的代码相同)
function sphereInfo = creatSphereObject(sphereInfo)
sphereInfo.centerX = [70 80 10];
sphereInfo.centerY = [70 80 10];
sphereInfo.centerZ = [70 80 10];
sphereInfo.radius = [5 8 5];
sphereInfo.exist = 1;
end
dynamicWindowApproach.m(动态窗口计算)
function [u,trajDB] = dynamicWindowApproach(x,model,dt,paraT,endPiont,sphereInfo,evalParam)
%%DWA算法实现
%输入
%输出
%速度采样
%根据当前状态和运动模型计算当前参数允许的范围
%计算动态窗口
vs = calcDynamicWindow(x,model,dt);
%评价函数计算,推算可用的轨迹
[evalDB,trajDB] = Evaluation(vs,model,paraT,x,endPiont,sphereInfo,dt);
% trajDB
% evalDB
if isempty(evalDB)
disp('no path to goal!!');
u=[0 0 0];return;
end
%各评价函数归一化处理
if sum(evalDB(:,4)) ~= 0
sum(evalDB(:,4));
evalDB(:,4) =evalDB(:,4)/sum(evalDB(:,4));
end
if sum(evalDB(:,5)) ~= 0
evalDB(:,5) =evalDB(:,5)/sum(evalDB(:,5));
end
if sum(evalDB(:,6)) ~= 0
evalDB(:,6) =evalDB(:,6)/sum(evalDB(:,6));
end
%最终评价函数计算,从所有的轨迹中找出性能最优的一组
feval=[];
for k1 = 1:length(evalDB(:,1))
feval = [feval;evalParam(1:3)*evalDB(k1,4:6)'];
end
evalDB=[evalDB feval];%纪录每一组轨迹的得分
[mav,ind] =max(feval);
u=evalDB(ind,1:3)%返回最优的速度值
end
Evaluation.m(评价函数)
function [evalDB,trajDB] = Evaluation(vs,model,paraT,x,endPiont,sphereInfo,dt)
%评价函数计算
%评价函数参数存储、轨迹点位置状态存储
evalDB = [];
trajDB = [];
calcuDis = @(x,y) sqrt((x(1)-y(1))^2+(x(2)-y(2))^2+(x(3)-y(3))^2);
for vtx =vs(1):model(7):vs(4)
for vty=vs(2):model(7):vs(5)
for vtz=vs(3):model(7):vs(6)
%轨迹推算
[xTemp,traj] = generateTrajectory(vtx,vty,vtz,paraT,x,dt);
%各评价函数的计算
%航向评价指标
heading = calcHeadingEval(xTemp,endPiont);
%距离评价指标
[dist,flag] = calcDisEval(xTemp,sphereInfo);
%速度得分指标
vel = calcuDis(xTemp(:,4:6),[0 0 0]);
%计算制动距离(速度采样第三部分,保证不发生碰撞)
stopDist = calcBreakingDist(xTemp,model,dt);
%当障碍物距离大于制动距离且终点不发生碰撞时
if dist >stopDist && flag ==0
evalDB=[evalDB;[vtx vty vtz heading dist vel]];
trajDB=[trajDB;traj];
end
end
end
end
end
%%轨迹推算
function [xTemp,traj] = generateTrajectory(vtx,vty,vtz,paraT,x,dt)
t1 = 0;
traj = [];
xTemp = x;
while t1 <= paraT
%更新时间
t1 = t1+dt;
%更新状态,假设前向模拟的速度值为恒定值
xTemp = [xTemp(1)+dt*vtx xTemp(2)+dt*vty xTemp(3)+dt*vtz vtx vty vtz];
%将轨迹和状态保存在traj中
traj = [traj;xTemp];
end
end
%%航向评价指标
function [heading] = calcHeadingEval(x,endPiont)
%以运动方向向量和当前位置与终点连线的向量的夹角(单位为°)
theta = 180-acosd(dot([endPiont(1)-x(1),endPiont(2)-x(2),endPiont(3)-x(3)], ...
[x(4),x(5),x(6)])/(norm([endPiont(1)-x(1),endPiont(2)-x(2),endPiont(3)-x(3)]) ...
*norm([x(4),x(5),x(6)])));
if theta <= 0
heading = -theta;
else
heading = theta;
end
% if max(x) ==0
% heading =0;
% end
if isnan(heading)
heading =0;
end
end
%%障碍物距离指标
function [dist,flag] = calcDisEval(x,sphereInfo)
calcuDis = @(x,y) sqrt((x(1)-y(1))^2+(x(2)-y(2))^2+(x(3)-y(3))^2);
dist = 100; %没有障碍物时的默认值
flag =0;%碰到障碍物则置为1;
for n1 = 1:size(sphereInfo.centerX,2)
center =[sphereInfo.centerX(n1),sphereInfo.centerY(n1),sphereInfo.centerZ(n1)];
disttemp = calcuDis(x(:,1:3),center)-sphereInfo.radius(n1);
if(disttemp < 0)
flag =1;
break;
else
%选取所有障碍物中距离最小值
if dist > disttemp
dist =disttemp;
end
end
end
%%%需要根据实际更改
%限定障碍物距离最大值,如果不限定,则其占比会非常大 20效果较好
if dist >= 20
dist = 20;
end
end
%%计算制动距离
function stopDist = calcBreakingDist(x,model,dt)
calcuDis = @(x,y) sqrt((x(1)-y(1))^2+(x(2)-y(2))^2+(x(3)-y(3))^2);
%将曲线的距离转换为一小段一小段直线
stopDist = 0;
vx=x(4);
vy=x(5);
vz=x(6);
while vx>0 || vy > 0 || vz >0
stopDist = stopDist+calcuDis([vx*dt vy*dt vz*dt],[0 0 0]);
if vx>0
vx=vx-model(4)*dt;
end
if vy>0
vy=vy-model(5)*dt;
end
if vz>0
vz=vz-model(6)*dt;
end
end
end
drawSphereObject.m(画障碍物,与RRT中代码相同)
function drawSphereObject(sphereInfo,colorMatSphere,pellucidity)
if sphereInfo.exist
for k1 = 1:size(sphereInfo.centerX,2)
xCoor = sphereInfo.centerX(k1);
yCoor = sphereInfo.centerY(k1);
zCoor = sphereInfo.centerZ(k1);
radius = sphereInfo.radius(k1);
[x,y,z] = sphere(50);
mesh(x*radius+xCoor,y*radius+yCoor,z*radius+zCoor,'FaceColor',colorMatSphere,'EdgeColor','none','FaceAlpha',pellucidity);
end
end
end
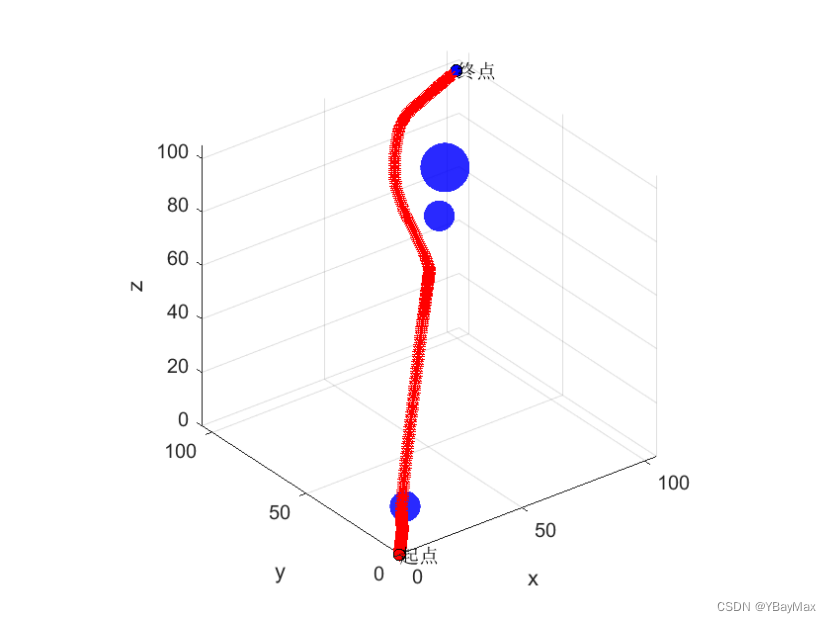
规划的结果:
代码地址:https://blog.csdn.net/BBeymax?type=download
代码中都有详细注释,跑不通可以私聊。
















 2436
2436

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











