






https://www.cnblogs.com/pinard/p/6093948.html 绿颜色的图都来自这篇博客,因为我编辑了一会公式,实在编辑不下去了。。。
该博主写了很多文章,大家可以去看看,反正我是经常是看的。
什么是熵
熵度量了事物的不确定性,越不确定的事物,它的熵就越大。具体的,随机变量X的熵的表达式如下:
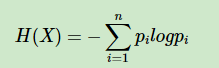
其中n代表X的n种不同的离散取值。而pi代表了X取值为i的概率,log为以2或者e为底的对数。(一般是以e为底的对数)
最大熵模型认为,学习概率模型时,熵最大的模型是最好的模型。
当我们想找一个合适的模型:
1、通过一些约束条件来确定一个模型集合
2、找到集合中熵最大的模型
2. 最大熵模型的定义

f(x,y) 中的x,y满足某个关系定义很广,可以被根据实际需要定义成各式各样,模型可以被多个约束特征函数所约束,而且每个函数x和y满足的关系都可能是不同的。随便举几个例子:
1、x有a1,a2,a3 三种取值,y有 1,2 两种取值。 f(x,y)可以定义成 x=a1,y=2时,f(x,y)=1,那当 x不等于a1,或者y不等于2时,这个函数就为0 ,即f(a1,2)=1 ,f(a1,3)=0
2、x是一个20维的向量,每一维的取值都是0或1,y有1,2两种取值,f(x,y)可以定义成x第一维向量为0,y=1时,值为1。
现在我们需要具体的定义约束条件:

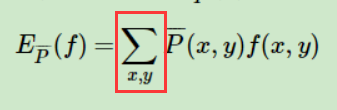 x有5种,y有6种,则这里是30种。 但如果训练集x其实有一种根本没有,只有4种,那么这个地方就是只有20种。没有的那种因为经验概率必为0,所以不算在内,所以
x有5种,y有6种,则这里是30种。 但如果训练集x其实有一种根本没有,只有4种,那么这个地方就是只有20种。没有的那种因为经验概率必为0,所以不算在内,所以 >0
>0
3 . 最大熵模型损失函数的优化

下面证明是凸函数
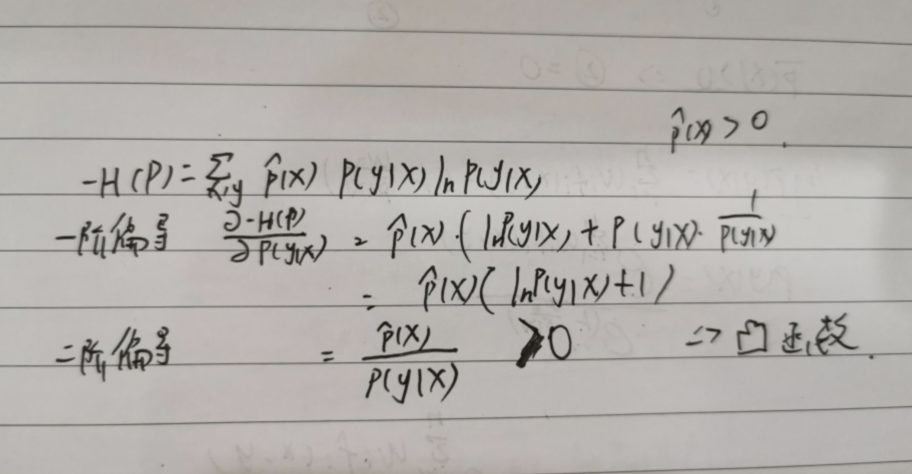
两个约束条件也是仿射函数,
那么根据拉格朗日对偶性的定理,原始问题和对偶问题的解是一样的。这样我们的损失函数的优化变成了拉格朗日对偶问题的优化。
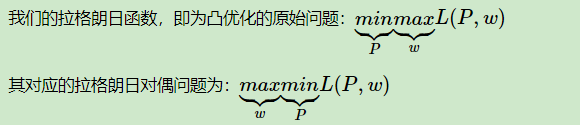

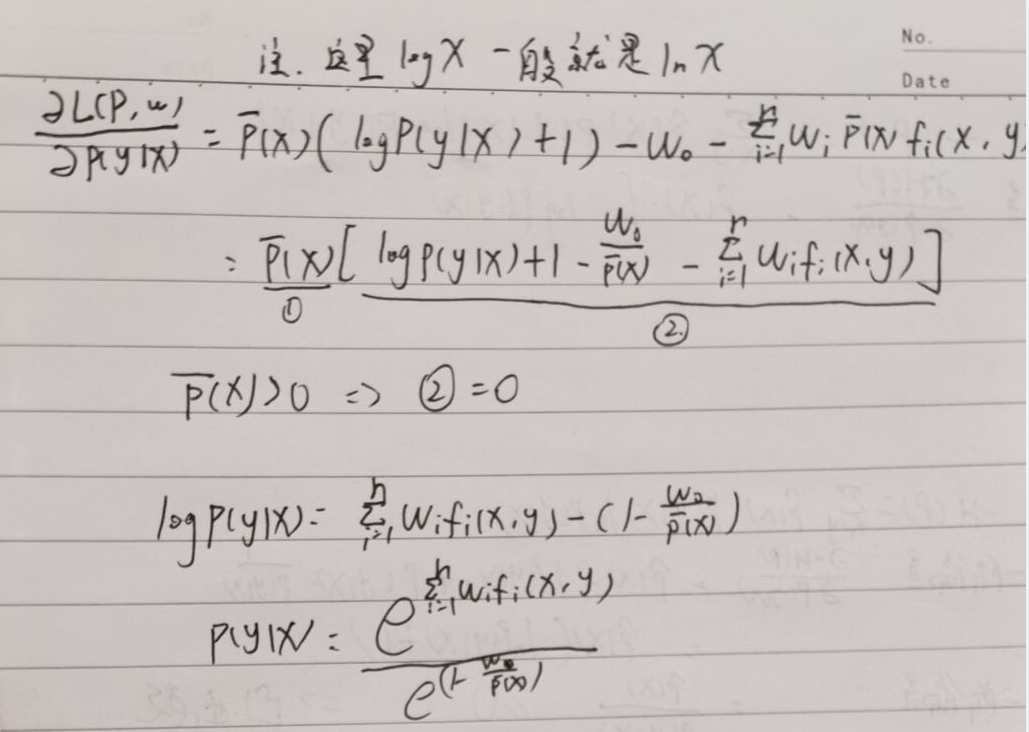
以我的理解
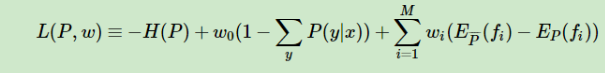 这个时候的
这个时候的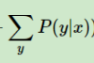 是不为1的,这时候P(y|x)是可以取任何值的。
是不为1的,这时候P(y|x)是可以取任何值的。
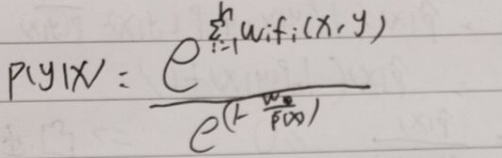 这个时候P已经是最大熵模型里面的P了,所以是为1的 (准确说这时候是Pw(y|x) 写错了不想改了)
这个时候P已经是最大熵模型里面的P了,所以是为1的 (准确说这时候是Pw(y|x) 写错了不想改了)
再后面求maxW,只是去具体调整这个模型
所以
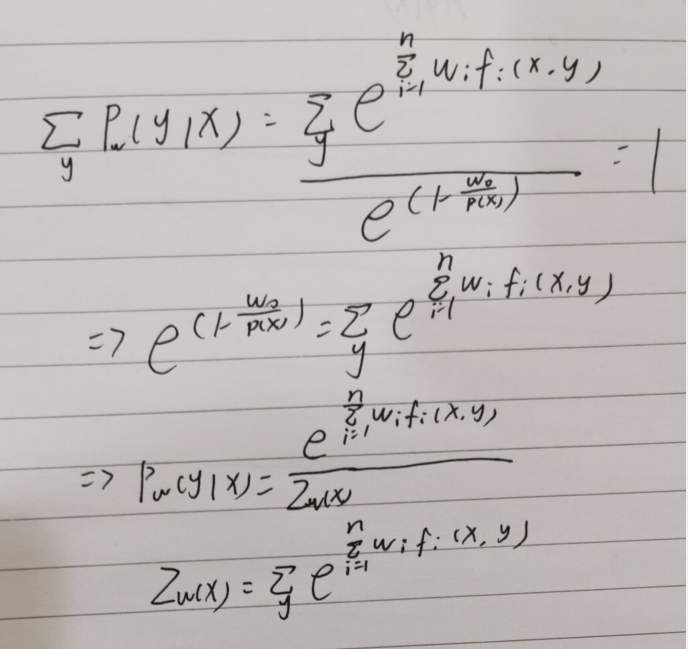

一个地方的解释:

这个地方的写法意思是对于任意的x,都满足固定x后对所有的P(y|x)和为1成立。
其实是可以直接写成多项x一个个表示出来的,因为后面为用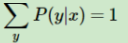 把换成Zw,是不影响的。我自己算了一次,但不想重写了。将就看看
把换成Zw,是不影响的。我自己算了一次,但不想重写了。将就看看
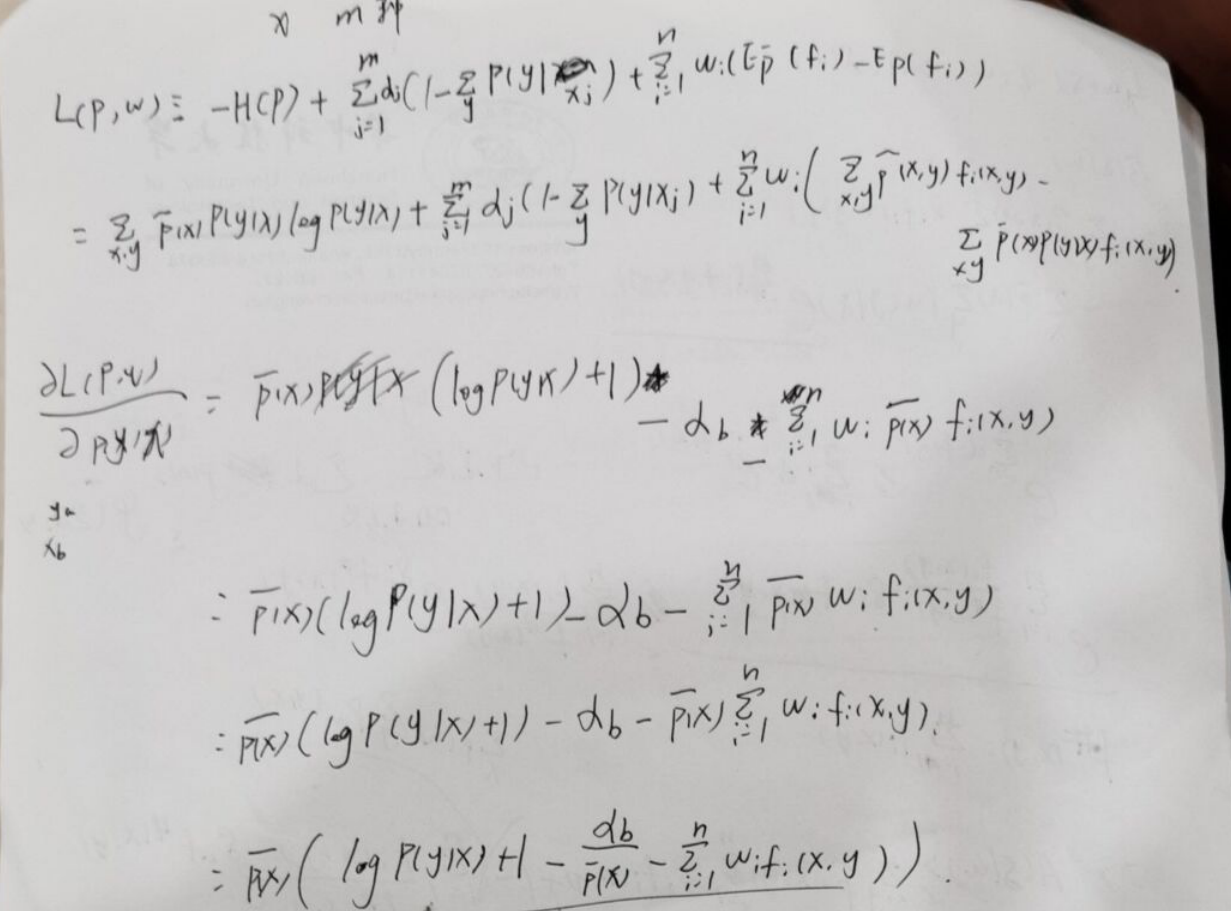

改进的迭代尺度法 IIS
先写出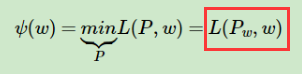 ,然后做出一些变形
,然后做出一些变形

下面就是一个迭代的方法,先给个初始值,然后每次希望加上一个值,使得到的值更小。
基本就是jensen不等式的使用,没有什么计算复杂的地方。。。我就不写了
用jensen不等式的时候记得判断凹凸性,大于和小于方向不一样。
可以去这里看http://www.pkudodo.com/2018/12/05/1-7/
这个大佬还把除了CRF的代码全写了,很强,github也放在最下面了。
我就贴个结论了。。

关于github的代码:
作者的注释已经很详细了,我说说自己的看法,并加一些注释
1、我理解的和作者不太一样,但写出来是一样的效果。。。 我理解的是minst输入的x 28*28就是X。 即使训练集没有,也可以通过
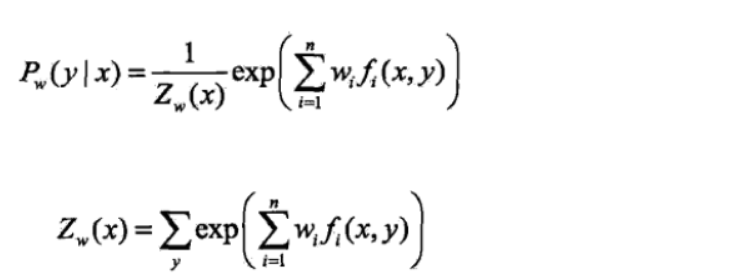
这个公式算出来。因为我的特征函数,可以设置成X的第一维为0,y为1的概率,不一定要是X是28*28的一个向量,y=0的概率
2、
根据这个公式,我们看出,只要特征函数选的好,是可以大大简化算法过程的。
那要对训练集中所有的(x,y)的f#(x,y)都相等,要怎么选特征函数呢。
首先minst数据集是28*28,Y是0-9
作者把简化了,X只有0,1 Y也只有0,1
那么如果我们把特征函数设为
f(x,y) x的第一维为0时,y为0时 为1
x第一维为0时,y为1时 为1
,x = 1,y=0 , x=1,y=1同理,加上有28*28维,相当一共有28*28*4个特征函数。
但我们训练集是有限的,可能一些是没有的。如x200维是1,y=1 。 就没有这个样例。我们就要把这个特征函数给去了。
这个相当于作者的self.fixy = self.calc_fixy() #所有(x, y)对出现的次数 这个函数。
这个时候特征函数选好了,我们会发现,对于所有的(x,y) 他们的 f#(x,y)都是28*28。。。 因为总有对应的fi(x,y)为真。 比如x是28*28个1,y是0 那么 x一维是1,y=0的特征函数为1 , x一维是2,y=0的特征函数为1 一直到 x最后一维是1,y=0的特征函数为1 。 其他所有的都为0,加起来和就是28*28
3、
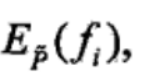 是可以直接先算好的。它不会变。因为p(x,y)的经验概率一开始就是固定的。作者的代码一开始直接算了self.Ep_xy = self.calcEp_xy() #Ep_xy期望值,就表明了这一点
是可以直接先算好的。它不会变。因为p(x,y)的经验概率一开始就是固定的。作者的代码一开始直接算了self.Ep_xy = self.calcEp_xy() #Ep_xy期望值,就表明了这一点
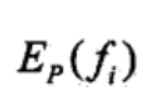 每轮都要变,里面的p(y|x)是跟着w改变而改变的。 而且这个算的方法特别有技巧性。。。
每轮都要变,里面的p(y|x)是跟着w改变而改变的。 而且这个算的方法特别有技巧性。。。
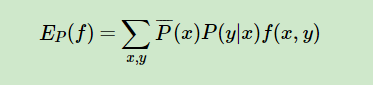
一共可能有2000多个特征函数。(为什么是2000多个,28*28*4,再减一些训练集不存在的)
我刚开始想直接2000个,一个一个算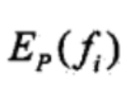 。。。然后看了一眼作者的代码。
。。。然后看了一眼作者的代码。
直接对训练集遍历,有N个,每个都分别算p(y=0|x),p(y=0|x),y=0和y=1都要算,因为前面只是对p(x)的经验概率,如果有对y的,就只要算存在的y,然后对28*28个维度开始循环。
看它能为哪个fi()做贡献,就加到哪个fi()的和里面。。。这个有点绕
所有公式都是自己推的,可能存在错误。。如果有疑问,欢迎讨论。
参考资料
1、李航老师的统计学习方法
2、https://www.cnblogs.com/pinard/p/6093948.html //刘建平老师写了很多的博客,基本包含了初学者所有要学的内容,大家可以去看看,我也看了很多。
3、http://www.pkudodo.com/2018/12/05/1-7/
4、https://github.com/handsomeWaterMelon/Statistical-Learning-Method_Code //除了CRF代码都有,主要用于分类minst数据集,很不错,很多算法实现起来也用了很多技巧,建议照着手打一遍,收获很大。















 479
479











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









