






- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
代码
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import torchvision
from torchvision import transforms, datasets
import os,PIL,pathlib,warnings
warnings.filterwarnings("ignore") #忽略警告信息
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device
device(type=‘cuda’)
import os,PIL,random,pathlib
data_dir = './data/weather_photos/'
data_dir = pathlib.Path(data_dir)
data_paths = list(data_dir.glob('*'))
classeNames = [str(path).split("\\")[2] for path in data_paths]
classeNames
[‘cloudy’, ‘rain’, ‘shine’, ‘sunrise’]
train_transforms = transforms.Compose([
transforms.Resize([224, 224]), # 将输入图片resize成统一尺寸
# transforms.RandomHorizontalFlip(), # 随机水平翻转
transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间
transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])
test_transform = transforms.Compose([
transforms.Resize([224, 224]), # 将输入图片resize成统一尺寸
transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间
transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])
total_data = datasets.ImageFolder("./data/weather_photos/",transform=train_transforms)
total_data.class_to_idx
{‘cloudy’: 0, ‘rain’: 1, ‘shine’: 2, ‘sunrise’: 3}
train_size = int(0.8 * len(total_data))
test_size = len(total_data) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(total_data, [train_size, test_size])
batch_size = 4
train_dl = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=1)
test_dl = torch.utils.data.DataLoader(test_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=1)
import torch.nn.functional as F
def autopad(k, p=None): # kernel, padding
# Pad to 'same'
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
class Conv(nn.Module):
# Standard convolution
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
return self.act(self.bn(self.conv(x)))
class Bottleneck(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class C3(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # act=FReLU(c2)
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))
class SPPF(nn.Module):
# Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher
def __init__(self, c1, c2, k=5): # equivalent to SPP(k=(5, 9, 13))
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * 4, c2, 1, 1)
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
def forward(self, x):
x = self.cv1(x)
with warnings.catch_warnings():
warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning
y1 = self.m(x)
y2 = self.m(y1)
return self.cv2(torch.cat([x, y1, y2, self.m(y2)], 1))
"""
这个是YOLOv5, 6.0版本的主干网络,这里进行复现
(注:有部分删改,详细讲解将在后续进行展开)
"""
class YOLOv5_backbone(nn.Module):
def __init__(self):
super(YOLOv5_backbone, self).__init__()
self.Conv_1 = Conv(3, 64, 3, 2, 2)
self.Conv_2 = Conv(64, 128, 3, 2)
self.C3_3 = C3(128,128)
self.Conv_4 = Conv(128, 256, 3, 2)
self.C3_5 = C3(256,256)
self.Conv_6 = Conv(256, 512, 3, 2)
self.C3_7 = C3(512,512)
self.Conv_8 = Conv(512, 1024, 3, 2)
self.C3_9 = C3(1024, 1024)
self.SPPF = SPPF(1024, 1024, 5)
# 全连接网络层,用于分类
self.classifier = nn.Sequential(
nn.Linear(in_features=65536, out_features=100),
nn.ReLU(),
nn.Linear(in_features=100, out_features=4)
)
def forward(self, x):
x = self.Conv_1(x)
x = self.Conv_2(x)
x = self.C3_3(x)
x = self.Conv_4(x)
x = self.C3_5(x)
x = self.Conv_6(x)
x = self.C3_7(x)
x = self.Conv_8(x)
x = self.C3_9(x)
x = self.SPPF(x)
x = torch.flatten(x, start_dim=1)
x = self.classifier(x)
return x
device = "cuda" if torch.cuda.is_available() else "cpu"
print("Using {} device".format(device))
model = YOLOv5_backbone().to(device)
# 统计模型参数量以及其他指标
import torchsummary as summary
print(summary.summary(model, (3, 224, 224)))
Using cuda device
==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
├─Conv: 1-1 [-1, 64, 113, 113] --
| └─Conv2d: 2-1 [-1, 64, 113, 113] 1,728
| └─BatchNorm2d: 2-2 [-1, 64, 113, 113] 128
| └─SiLU: 2-3 [-1, 64, 113, 113] --
├─Conv: 1-2 [-1, 128, 57, 57] --
| └─Conv2d: 2-4 [-1, 128, 57, 57] 73,728
| └─BatchNorm2d: 2-5 [-1, 128, 57, 57] 256
| └─SiLU: 2-6 [-1, 128, 57, 57] --
├─C3: 1-3 [-1, 128, 57, 57] --
| └─Conv: 2-7 [-1, 64, 57, 57] --
| | └─Conv2d: 3-1 [-1, 64, 57, 57] 8,192
| | └─BatchNorm2d: 3-2 [-1, 64, 57, 57] 128
| | └─SiLU: 3-3 [-1, 64, 57, 57] --
| └─Sequential: 2-8 [-1, 64, 57, 57] --
| | └─Bottleneck: 3-4 [-1, 64, 57, 57] 41,216
| └─Conv: 2-9 [-1, 64, 57, 57] --
| | └─Conv2d: 3-5 [-1, 64, 57, 57] 8,192
| | └─BatchNorm2d: 3-6 [-1, 64, 57, 57] 128
| | └─SiLU: 3-7 [-1, 64, 57, 57] --
| └─Conv: 2-10 [-1, 128, 57, 57] --
| | └─Conv2d: 3-8 [-1, 128, 57, 57] 16,384
| | └─BatchNorm2d: 3-9 [-1, 128, 57, 57] 256
| | └─SiLU: 3-10 [-1, 128, 57, 57] --
├─Conv: 1-4 [-1, 256, 29, 29] --
| └─Conv2d: 2-11 [-1, 256, 29, 29] 294,912
| └─BatchNorm2d: 2-12 [-1, 256, 29, 29] 512
| └─SiLU: 2-13 [-1, 256, 29, 29] --
├─C3: 1-5 [-1, 256, 29, 29] --
| └─Conv: 2-14 [-1, 128, 29, 29] --
| | └─Conv2d: 3-11 [-1, 128, 29, 29] 32,768
| | └─BatchNorm2d: 3-12 [-1, 128, 29, 29] 256
| | └─SiLU: 3-13 [-1, 128, 29, 29] --
| └─Sequential: 2-15 [-1, 128, 29, 29] --
| | └─Bottleneck: 3-14 [-1, 128, 29, 29] 164,352
| └─Conv: 2-16 [-1, 128, 29, 29] --
| | └─Conv2d: 3-15 [-1, 128, 29, 29] 32,768
| | └─BatchNorm2d: 3-16 [-1, 128, 29, 29] 256
| | └─SiLU: 3-17 [-1, 128, 29, 29] --
| └─Conv: 2-17 [-1, 256, 29, 29] --
| | └─Conv2d: 3-18 [-1, 256, 29, 29] 65,536
| | └─BatchNorm2d: 3-19 [-1, 256, 29, 29] 512
| | └─SiLU: 3-20 [-1, 256, 29, 29] --
├─Conv: 1-6 [-1, 512, 15, 15] --
| └─Conv2d: 2-18 [-1, 512, 15, 15] 1,179,648
| └─BatchNorm2d: 2-19 [-1, 512, 15, 15] 1,024
| └─SiLU: 2-20 [-1, 512, 15, 15] --
├─C3: 1-7 [-1, 512, 15, 15] --
| └─Conv: 2-21 [-1, 256, 15, 15] --
| | └─Conv2d: 3-21 [-1, 256, 15, 15] 131,072
| | └─BatchNorm2d: 3-22 [-1, 256, 15, 15] 512
| | └─SiLU: 3-23 [-1, 256, 15, 15] --
| └─Sequential: 2-22 [-1, 256, 15, 15] --
| | └─Bottleneck: 3-24 [-1, 256, 15, 15] 656,384
| └─Conv: 2-23 [-1, 256, 15, 15] --
| | └─Conv2d: 3-25 [-1, 256, 15, 15] 131,072
| | └─BatchNorm2d: 3-26 [-1, 256, 15, 15] 512
| | └─SiLU: 3-27 [-1, 256, 15, 15] --
| └─Conv: 2-24 [-1, 512, 15, 15] --
| | └─Conv2d: 3-28 [-1, 512, 15, 15] 262,144
| | └─BatchNorm2d: 3-29 [-1, 512, 15, 15] 1,024
| | └─SiLU: 3-30 [-1, 512, 15, 15] --
├─Conv: 1-8 [-1, 1024, 8, 8] --
| └─Conv2d: 2-25 [-1, 1024, 8, 8] 4,718,592
| └─BatchNorm2d: 2-26 [-1, 1024, 8, 8] 2,048
| └─SiLU: 2-27 [-1, 1024, 8, 8] --
├─C3: 1-9 [-1, 1024, 8, 8] --
| └─Conv: 2-28 [-1, 512, 8, 8] --
| | └─Conv2d: 3-31 [-1, 512, 8, 8] 524,288
| | └─BatchNorm2d: 3-32 [-1, 512, 8, 8] 1,024
| | └─SiLU: 3-33 [-1, 512, 8, 8] --
| └─Sequential: 2-29 [-1, 512, 8, 8] --
| | └─Bottleneck: 3-34 [-1, 512, 8, 8] 2,623,488
| └─Conv: 2-30 [-1, 512, 8, 8] --
| | └─Conv2d: 3-35 [-1, 512, 8, 8] 524,288
| | └─BatchNorm2d: 3-36 [-1, 512, 8, 8] 1,024
| | └─SiLU: 3-37 [-1, 512, 8, 8] --
| └─Conv: 2-31 [-1, 1024, 8, 8] --
| | └─Conv2d: 3-38 [-1, 1024, 8, 8] 1,048,576
| | └─BatchNorm2d: 3-39 [-1, 1024, 8, 8] 2,048
| | └─SiLU: 3-40 [-1, 1024, 8, 8] --
├─SPPF: 1-10 [-1, 1024, 8, 8] --
| └─Conv: 2-32 [-1, 512, 8, 8] --
| | └─Conv2d: 3-41 [-1, 512, 8, 8] 524,288
| | └─BatchNorm2d: 3-42 [-1, 512, 8, 8] 1,024
| | └─SiLU: 3-43 [-1, 512, 8, 8] --
| └─MaxPool2d: 2-33 [-1, 512, 8, 8] --
| └─MaxPool2d: 2-34 [-1, 512, 8, 8] --
| └─MaxPool2d: 2-35 [-1, 512, 8, 8] --
| └─Conv: 2-36 [-1, 1024, 8, 8] --
| | └─Conv2d: 3-44 [-1, 1024, 8, 8] 2,097,152
| | └─BatchNorm2d: 3-45 [-1, 1024, 8, 8] 2,048
| | └─SiLU: 3-46 [-1, 1024, 8, 8] --
├─Sequential: 1-11 [-1, 4] --
| └─Linear: 2-37 [-1, 100] 6,553,700
| └─ReLU: 2-38 [-1, 100] --
| └─Linear: 2-39 [-1, 4] 404
==========================================================================================
Total params: 21,729,592
Trainable params: 21,729,592
Non-trainable params: 0
Total mult-adds (G): 1.76
==========================================================================================
Input size (MB): 0.57
Forward/backward pass size (MB): 51.14
Params size (MB): 82.89
Estimated Total Size (MB): 134.60
==========================================================================================
==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
├─Conv: 1-1 [-1, 64, 113, 113] --
| └─Conv2d: 2-1 [-1, 64, 113, 113] 1,728
| └─BatchNorm2d: 2-2 [-1, 64, 113, 113] 128
| └─SiLU: 2-3 [-1, 64, 113, 113] --
├─Conv: 1-2 [-1, 128, 57, 57] --
| └─Conv2d: 2-4 [-1, 128, 57, 57] 73,728
| └─BatchNorm2d: 2-5 [-1, 128, 57, 57] 256
| └─SiLU: 2-6 [-1, 128, 57, 57] --
├─C3: 1-3 [-1, 128, 57, 57] --
| └─Conv: 2-7 [-1, 64, 57, 57] --
| | └─Conv2d: 3-1 [-1, 64, 57, 57] 8,192
| | └─BatchNorm2d: 3-2 [-1, 64, 57, 57] 128
| | └─SiLU: 3-3 [-1, 64, 57, 57] --
| └─Sequential: 2-8 [-1, 64, 57, 57] --
| | └─Bottleneck: 3-4 [-1, 64, 57, 57] 41,216
| └─Conv: 2-9 [-1, 64, 57, 57] --
| | └─Conv2d: 3-5 [-1, 64, 57, 57] 8,192
| | └─BatchNorm2d: 3-6 [-1, 64, 57, 57] 128
| | └─SiLU: 3-7 [-1, 64, 57, 57] --
| └─Conv: 2-10 [-1, 128, 57, 57] --
| | └─Conv2d: 3-8 [-1, 128, 57, 57] 16,384
| | └─BatchNorm2d: 3-9 [-1, 128, 57, 57] 256
| | └─SiLU: 3-10 [-1, 128, 57, 57] --
├─Conv: 1-4 [-1, 256, 29, 29] --
| └─Conv2d: 2-11 [-1, 256, 29, 29] 294,912
| └─BatchNorm2d: 2-12 [-1, 256, 29, 29] 512
| └─SiLU: 2-13 [-1, 256, 29, 29] --
├─C3: 1-5 [-1, 256, 29, 29] --
| └─Conv: 2-14 [-1, 128, 29, 29] --
| | └─Conv2d: 3-11 [-1, 128, 29, 29] 32,768
| | └─BatchNorm2d: 3-12 [-1, 128, 29, 29] 256
| | └─SiLU: 3-13 [-1, 128, 29, 29] --
| └─Sequential: 2-15 [-1, 128, 29, 29] --
| | └─Bottleneck: 3-14 [-1, 128, 29, 29] 164,352
| └─Conv: 2-16 [-1, 128, 29, 29] --
| | └─Conv2d: 3-15 [-1, 128, 29, 29] 32,768
| | └─BatchNorm2d: 3-16 [-1, 128, 29, 29] 256
| | └─SiLU: 3-17 [-1, 128, 29, 29] --
| └─Conv: 2-17 [-1, 256, 29, 29] --
| | └─Conv2d: 3-18 [-1, 256, 29, 29] 65,536
| | └─BatchNorm2d: 3-19 [-1, 256, 29, 29] 512
| | └─SiLU: 3-20 [-1, 256, 29, 29] --
├─Conv: 1-6 [-1, 512, 15, 15] --
| └─Conv2d: 2-18 [-1, 512, 15, 15] 1,179,648
| └─BatchNorm2d: 2-19 [-1, 512, 15, 15] 1,024
| └─SiLU: 2-20 [-1, 512, 15, 15] --
├─C3: 1-7 [-1, 512, 15, 15] --
| └─Conv: 2-21 [-1, 256, 15, 15] --
| | └─Conv2d: 3-21 [-1, 256, 15, 15] 131,072
| | └─BatchNorm2d: 3-22 [-1, 256, 15, 15] 512
| | └─SiLU: 3-23 [-1, 256, 15, 15] --
| └─Sequential: 2-22 [-1, 256, 15, 15] --
| | └─Bottleneck: 3-24 [-1, 256, 15, 15] 656,384
| └─Conv: 2-23 [-1, 256, 15, 15] --
| | └─Conv2d: 3-25 [-1, 256, 15, 15] 131,072
| | └─BatchNorm2d: 3-26 [-1, 256, 15, 15] 512
| | └─SiLU: 3-27 [-1, 256, 15, 15] --
| └─Conv: 2-24 [-1, 512, 15, 15] --
| | └─Conv2d: 3-28 [-1, 512, 15, 15] 262,144
| | └─BatchNorm2d: 3-29 [-1, 512, 15, 15] 1,024
| | └─SiLU: 3-30 [-1, 512, 15, 15] --
├─Conv: 1-8 [-1, 1024, 8, 8] --
| └─Conv2d: 2-25 [-1, 1024, 8, 8] 4,718,592
| └─BatchNorm2d: 2-26 [-1, 1024, 8, 8] 2,048
| └─SiLU: 2-27 [-1, 1024, 8, 8] --
├─C3: 1-9 [-1, 1024, 8, 8] --
| └─Conv: 2-28 [-1, 512, 8, 8] --
| | └─Conv2d: 3-31 [-1, 512, 8, 8] 524,288
| | └─BatchNorm2d: 3-32 [-1, 512, 8, 8] 1,024
| | └─SiLU: 3-33 [-1, 512, 8, 8] --
| └─Sequential: 2-29 [-1, 512, 8, 8] --
| | └─Bottleneck: 3-34 [-1, 512, 8, 8] 2,623,488
| └─Conv: 2-30 [-1, 512, 8, 8] --
| | └─Conv2d: 3-35 [-1, 512, 8, 8] 524,288
| | └─BatchNorm2d: 3-36 [-1, 512, 8, 8] 1,024
| | └─SiLU: 3-37 [-1, 512, 8, 8] --
| └─Conv: 2-31 [-1, 1024, 8, 8] --
| | └─Conv2d: 3-38 [-1, 1024, 8, 8] 1,048,576
| | └─BatchNorm2d: 3-39 [-1, 1024, 8, 8] 2,048
| | └─SiLU: 3-40 [-1, 1024, 8, 8] --
├─SPPF: 1-10 [-1, 1024, 8, 8] --
| └─Conv: 2-32 [-1, 512, 8, 8] --
| | └─Conv2d: 3-41 [-1, 512, 8, 8] 524,288
| | └─BatchNorm2d: 3-42 [-1, 512, 8, 8] 1,024
| | └─SiLU: 3-43 [-1, 512, 8, 8] --
| └─MaxPool2d: 2-33 [-1, 512, 8, 8] --
| └─MaxPool2d: 2-34 [-1, 512, 8, 8] --
| └─MaxPool2d: 2-35 [-1, 512, 8, 8] --
| └─Conv: 2-36 [-1, 1024, 8, 8] --
| | └─Conv2d: 3-44 [-1, 1024, 8, 8] 2,097,152
| | └─BatchNorm2d: 3-45 [-1, 1024, 8, 8] 2,048
| | └─SiLU: 3-46 [-1, 1024, 8, 8] --
├─Sequential: 1-11 [-1, 4] --
| └─Linear: 2-37 [-1, 100] 6,553,700
| └─ReLU: 2-38 [-1, 100] --
| └─Linear: 2-39 [-1, 4] 404
==========================================================================================
Total params: 21,729,592
Trainable params: 21,729,592
Non-trainable params: 0
Total mult-adds (G): 1.76
==========================================================================================
Input size (MB): 0.57
Forward/backward pass size (MB): 51.14
Params size (MB): 82.89
Estimated Total Size (MB): 134.60
==========================================================================================
# 训练循环
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset) # 训练集的大小
num_batches = len(dataloader) # 批次数目, (size/batch_size,向上取整)
train_loss, train_acc = 0, 0 # 初始化训练损失和正确率
for X, y in dataloader: # 获取图片及其标签
X, y = X.to(device), y.to(device)
# 计算预测误差
pred = model(X) # 网络输出
loss = loss_fn(pred, y) # 计算网络输出和真实值之间的差距,targets为真实值,计算二者差值即为损失
# 反向传播
optimizer.zero_grad() # grad属性归零
loss.backward() # 反向传播
optimizer.step() # 每一步自动更新
# 记录acc与loss
train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()
train_loss += loss.item()
train_acc /= size
train_loss /= num_batches
return train_acc, train_loss
def test (dataloader, model, loss_fn):
size = len(dataloader.dataset) # 测试集的大小
num_batches = len(dataloader) # 批次数目, (size/batch_size,向上取整)
test_loss, test_acc = 0, 0
# 当不进行训练时,停止梯度更新,节省计算内存消耗
with torch.no_grad():
for imgs, target in dataloader:
imgs, target = imgs.to(device), target.to(device)
# 计算loss
target_pred = model(imgs)
loss = loss_fn(target_pred, target)
test_loss += loss.item()
test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()
test_acc /= size
test_loss /= num_batches
return test_acc, test_loss
import copy
optimizer = torch.optim.Adam(model.parameters(), lr= 1e-4)
loss_fn = nn.CrossEntropyLoss() # 创建损失函数
epochs = 60
train_loss = []
train_acc = []
test_loss = []
test_acc = []
best_acc = 0 # 设置一个最佳准确率,作为最佳模型的判别指标
for epoch in range(epochs):
model.train()
epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, optimizer)
model.eval()
epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)
# 保存最佳模型到 best_model
if epoch_test_acc > best_acc:
best_acc = epoch_test_acc
best_model = copy.deepcopy(model)
train_acc.append(epoch_train_acc)
train_loss.append(epoch_train_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
# 获取当前的学习率
lr = optimizer.state_dict()['param_groups'][0]['lr']
template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%, Test_loss:{:.3f}, Lr:{:.2E}')
print(template.format(epoch+1, epoch_train_acc*100, epoch_train_loss,
epoch_test_acc*100, epoch_test_loss, lr))
# 保存最佳模型到文件中
PATH = './best_model.pth' # 保存的参数文件名
torch.save(best_model.state_dict(), PATH)
print('Done')
Epoch: 1, Train_acc:53.7%, Train_loss:1.155, Test_acc:76.4%, Test_loss:0.640, Lr:1.00E-04
Epoch: 2, Train_acc:62.7%, Train_loss:0.877, Test_acc:81.3%, Test_loss:0.533, Lr:1.00E-04
Epoch: 3, Train_acc:69.9%, Train_loss:0.722, Test_acc:72.9%, Test_loss:0.552, Lr:1.00E-04
Epoch: 4, Train_acc:71.3%, Train_loss:0.748, Test_acc:71.6%, Test_loss:0.644, Lr:1.00E-04
Epoch: 5, Train_acc:78.4%, Train_loss:0.545, Test_acc:69.3%, Test_loss:1.131, Lr:1.00E-04
Epoch: 6, Train_acc:81.6%, Train_loss:0.497, Test_acc:91.1%, Test_loss:0.328, Lr:1.00E-04
Epoch: 7, Train_acc:82.4%, Train_loss:0.468, Test_acc:87.1%, Test_loss:0.365, Lr:1.00E-04
Epoch: 8, Train_acc:80.2%, Train_loss:0.471, Test_acc:86.7%, Test_loss:0.358, Lr:1.00E-04
Epoch: 9, Train_acc:86.3%, Train_loss:0.363, Test_acc:75.6%, Test_loss:0.678, Lr:1.00E-04
Epoch:10, Train_acc:86.7%, Train_loss:0.335, Test_acc:88.9%, Test_loss:0.372, Lr:1.00E-04
Epoch:11, Train_acc:88.1%, Train_loss:0.332, Test_acc:90.2%, Test_loss:0.288, Lr:1.00E-04
Epoch:12, Train_acc:88.6%, Train_loss:0.336, Test_acc:76.4%, Test_loss:0.742, Lr:1.00E-04
Epoch:13, Train_acc:91.0%, Train_loss:0.261, Test_acc:88.0%, Test_loss:0.379, Lr:1.00E-04
Epoch:14, Train_acc:89.7%, Train_loss:0.306, Test_acc:85.3%, Test_loss:0.393, Lr:1.00E-04
Epoch:15, Train_acc:88.4%, Train_loss:0.324, Test_acc:88.9%, Test_loss:0.333, Lr:1.00E-04
Epoch:16, Train_acc:90.8%, Train_loss:0.243, Test_acc:87.1%, Test_loss:0.418, Lr:1.00E-04
Epoch:17, Train_acc:94.9%, Train_loss:0.156, Test_acc:88.9%, Test_loss:0.400, Lr:1.00E-04
Epoch:18, Train_acc:93.6%, Train_loss:0.171, Test_acc:88.9%, Test_loss:0.354, Lr:1.00E-04
Epoch:19, Train_acc:93.6%, Train_loss:0.153, Test_acc:82.7%, Test_loss:0.450, Lr:1.00E-04
Epoch:20, Train_acc:95.9%, Train_loss:0.128, Test_acc:88.0%, Test_loss:0.432, Lr:1.00E-04
Epoch:21, Train_acc:94.7%, Train_loss:0.145, Test_acc:89.8%, Test_loss:0.269, Lr:1.00E-04
Epoch:22, Train_acc:95.0%, Train_loss:0.122, Test_acc:90.2%, Test_loss:0.318, Lr:1.00E-04
Epoch:23, Train_acc:96.4%, Train_loss:0.100, Test_acc:88.4%, Test_loss:0.384, Lr:1.00E-04
Epoch:24, Train_acc:95.9%, Train_loss:0.122, Test_acc:88.0%, Test_loss:0.368, Lr:1.00E-04
Epoch:25, Train_acc:95.3%, Train_loss:0.121, Test_acc:91.1%, Test_loss:0.286, Lr:1.00E-04
Epoch:26, Train_acc:96.8%, Train_loss:0.100, Test_acc:84.4%, Test_loss:0.476, Lr:1.00E-04
Epoch:27, Train_acc:96.7%, Train_loss:0.071, Test_acc:92.4%, Test_loss:0.277, Lr:1.00E-04
Epoch:28, Train_acc:98.3%, Train_loss:0.055, Test_acc:89.8%, Test_loss:0.350, Lr:1.00E-04
Epoch:29, Train_acc:97.8%, Train_loss:0.071, Test_acc:86.7%, Test_loss:0.476, Lr:1.00E-04
Epoch:30, Train_acc:95.3%, Train_loss:0.113, Test_acc:87.6%, Test_loss:0.406, Lr:1.00E-04
Epoch:31, Train_acc:95.2%, Train_loss:0.121, Test_acc:80.0%, Test_loss:0.721, Lr:1.00E-04
Epoch:32, Train_acc:95.4%, Train_loss:0.147, Test_acc:81.8%, Test_loss:0.671, Lr:1.00E-04
Epoch:33, Train_acc:96.9%, Train_loss:0.076, Test_acc:91.1%, Test_loss:0.358, Lr:1.00E-04
Epoch:34, Train_acc:99.2%, Train_loss:0.033, Test_acc:90.2%, Test_loss:0.328, Lr:1.00E-04
Epoch:35, Train_acc:99.0%, Train_loss:0.028, Test_acc:92.9%, Test_loss:0.248, Lr:1.00E-04
Epoch:36, Train_acc:98.3%, Train_loss:0.057, Test_acc:87.6%, Test_loss:0.359, Lr:1.00E-04
Epoch:37, Train_acc:95.8%, Train_loss:0.137, Test_acc:89.8%, Test_loss:0.334, Lr:1.00E-04
Epoch:38, Train_acc:98.0%, Train_loss:0.058, Test_acc:81.8%, Test_loss:0.517, Lr:1.00E-04
Epoch:39, Train_acc:99.1%, Train_loss:0.025, Test_acc:88.9%, Test_loss:0.404, Lr:1.00E-04
Epoch:40, Train_acc:99.6%, Train_loss:0.012, Test_acc:91.1%, Test_loss:0.324, Lr:1.00E-04
Epoch:41, Train_acc:99.9%, Train_loss:0.007, Test_acc:90.2%, Test_loss:0.387, Lr:1.00E-04
Epoch:42, Train_acc:99.2%, Train_loss:0.028, Test_acc:84.9%, Test_loss:0.506, Lr:1.00E-04
Epoch:43, Train_acc:97.2%, Train_loss:0.079, Test_acc:84.0%, Test_loss:0.626, Lr:1.00E-04
Epoch:44, Train_acc:98.6%, Train_loss:0.046, Test_acc:87.1%, Test_loss:0.426, Lr:1.00E-04
Epoch:45, Train_acc:97.8%, Train_loss:0.059, Test_acc:83.1%, Test_loss:0.637, Lr:1.00E-04
Epoch:46, Train_acc:96.8%, Train_loss:0.097, Test_acc:91.1%, Test_loss:0.369, Lr:1.00E-04
Epoch:47, Train_acc:98.7%, Train_loss:0.040, Test_acc:88.9%, Test_loss:0.404, Lr:1.00E-04
Epoch:48, Train_acc:99.6%, Train_loss:0.019, Test_acc:89.8%, Test_loss:0.470, Lr:1.00E-04
Epoch:49, Train_acc:99.7%, Train_loss:0.012, Test_acc:89.8%, Test_loss:0.413, Lr:1.00E-04
Epoch:50, Train_acc:99.1%, Train_loss:0.028, Test_acc:85.8%, Test_loss:0.717, Lr:1.00E-04
Epoch:51, Train_acc:98.8%, Train_loss:0.045, Test_acc:87.6%, Test_loss:0.452, Lr:1.00E-04
Epoch:52, Train_acc:98.6%, Train_loss:0.047, Test_acc:87.1%, Test_loss:0.484, Lr:1.00E-04
Epoch:53, Train_acc:99.6%, Train_loss:0.015, Test_acc:87.1%, Test_loss:0.518, Lr:1.00E-04
Epoch:54, Train_acc:97.7%, Train_loss:0.070, Test_acc:89.8%, Test_loss:0.545, Lr:1.00E-04
Epoch:55, Train_acc:97.9%, Train_loss:0.053, Test_acc:89.3%, Test_loss:0.437, Lr:1.00E-04
Epoch:56, Train_acc:98.7%, Train_loss:0.029, Test_acc:87.1%, Test_loss:0.457, Lr:1.00E-04
Epoch:57, Train_acc:99.3%, Train_loss:0.020, Test_acc:88.4%, Test_loss:0.449, Lr:1.00E-04
Epoch:58, Train_acc:99.2%, Train_loss:0.024, Test_acc:86.7%, Test_loss:0.522, Lr:1.00E-04
Epoch:59, Train_acc:99.4%, Train_loss:0.028, Test_acc:90.2%, Test_loss:0.420, Lr:1.00E-04
Epoch:60, Train_acc:98.8%, Train_loss:0.032, Test_acc:87.6%, Test_loss:0.495, Lr:1.00E-04
Done
import matplotlib.pyplot as plt
#隐藏警告
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 #分辨率
epochs_range = range(epochs)
plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
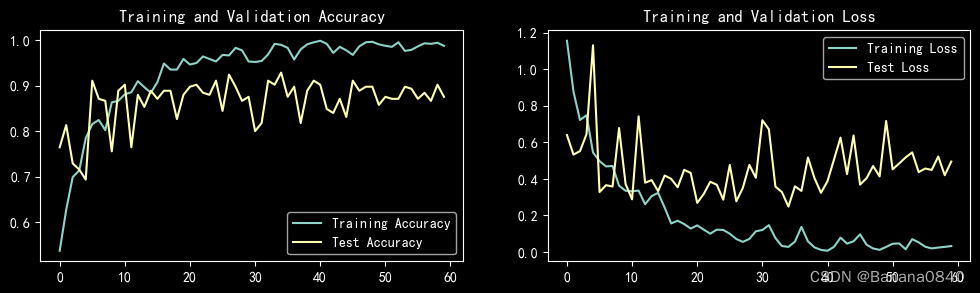
# 将参数加载到model当中
best_model.load_state_dict(torch.load(PATH, map_location=device))
epoch_test_acc, epoch_test_loss = test(test_dl, best_model, loss_fn)
epoch_test_acc, epoch_test_loss
(0.9511111111111111, 0.25679569537080343)
总结
Yolov5结构图
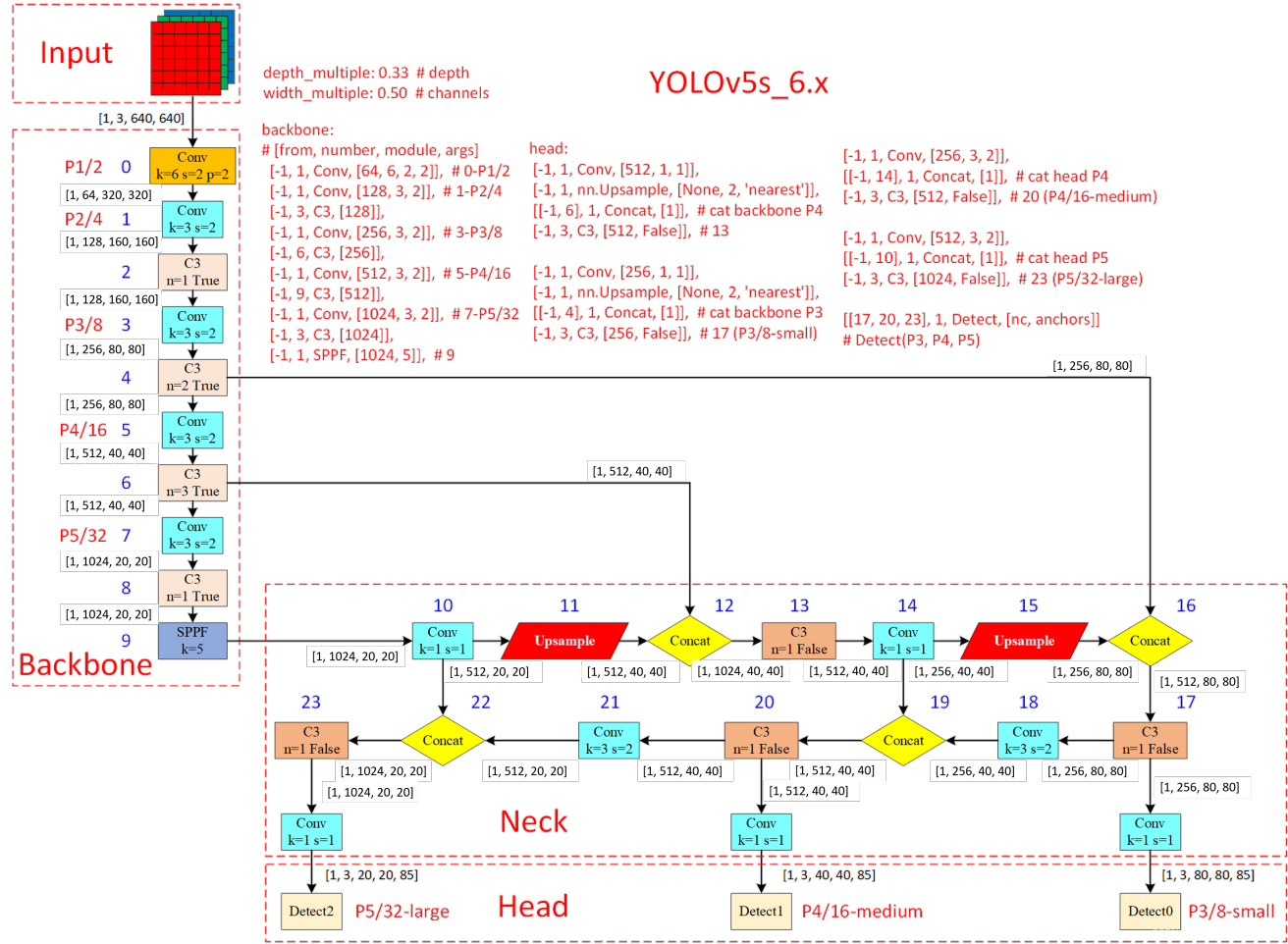
Yolov5中的各个模块
Focus
Focus模块主要作用为切片,意思就是把原图切分为小一点的图片,减小图片尺寸,增加通道数。以yolov5s为例,原始的640 × 640 × 3的图像输入Focus结构,采用切片操作,先变成320 × 320 × 12的特征图,再经过一次卷积操作,最终变成320 × 320 × 32的特征图。
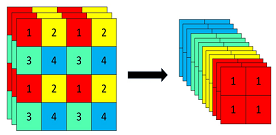
理论:
从高分辨率图像中,周期性的抽出像素点重构到低分辨率图像中,即将图像相邻的四个位置进行堆叠,聚焦wh维度信息到c通道中,增大每个点的感受野,减少原始信息的丢失,该模块的设计主要是减少计算量加快速度 Focus wh information into c-space 把宽度w和高度h的信息整合到c空间中
- 先做4个 slice 再 concat 最后再做 Conv
- slice 后
(b,c1,w,h)-> 分成4个 slice 每个 slice 为(b,c1,w/2,h/2) - concat(dim=1) 后 4个 slice :
(b,c1,w/2,h/2))->(b,4c1,w/2,h/2) - conv 后
(b,4c1,w/2,h/2)->(b,c2,w/2,h/2)
Conv

Conv层是由2D卷积层+BN层+SiLU激活函数组成的,其目的是减少计算量和参数量,达到提速效果。
C3
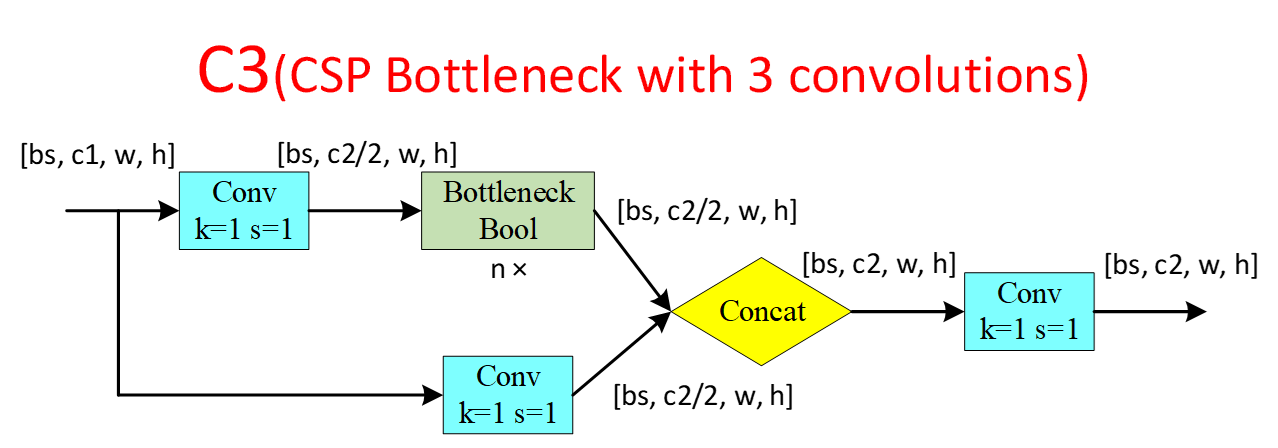
SPPF
先说SPP,Spatial Pyramid Pooling,对每个特征图,使用三种不同尺寸的池化核进行最大池化,分别得到预设的特征图尺寸,最后将所有特征图展开为特征向量并融合。
通常由三个步骤组成:
池化:将输入特征图分别进行不同大小的池化操作,以获得一组不同大小的特征图。
连接:将不同大小的特征图连接在一起。
全连接:通过全连接层将连接后的特征向量降维,得到固定大小的特征向量。
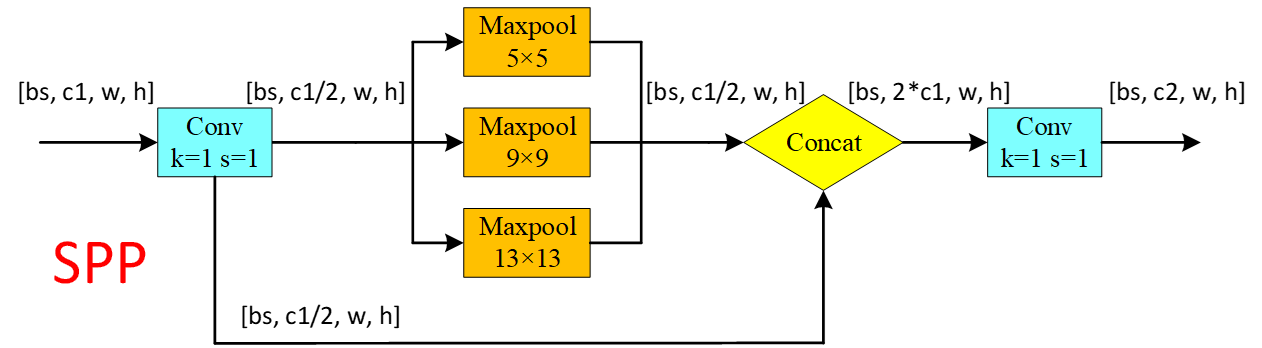
SPPF:

SPPF,Spatial Pyramid Pooling - Fast,用在了Backbone中的最后,保证准确率相似的条件下,减少计算量,以提高速度,使用3个5×5的最大池化,代替原来v6之前的5×5、9×9、13×13最大池化。使用SPPF的目的是为了利用不同的池化核尺寸提取特征的方式可以获得更多的特征信息,提高网络的识别精度。
Upsample
上采样,用来将输入数据的尺寸放大,指将低分辨率的图像或特征图放大到原始分辨率的过程。
例如,将每个数据复制四次,从而使得输出数据的尺寸变为输入数据的两倍。例如shape为(1,512,20,20),经过Upsample之后,变为(1,512,40,40)。
参考:
https://zhuanlan.zhihu.com/p/651170489
https://blog.csdn.net/qq_44878985/article/details/129287587
https://blog.csdn.net/qq_39056987/article/details/112712817
https://blog.csdn.net/weixin_43799388/article/details/123271962
https://www.jianshu.com/p/6156f7865833















 11万+
11万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









