







- 1.SPPF介绍
SPPF是YOLOV8的空间金字塔池化层,用于在多个尺度上聚合特征。其简单的模块结构图如下: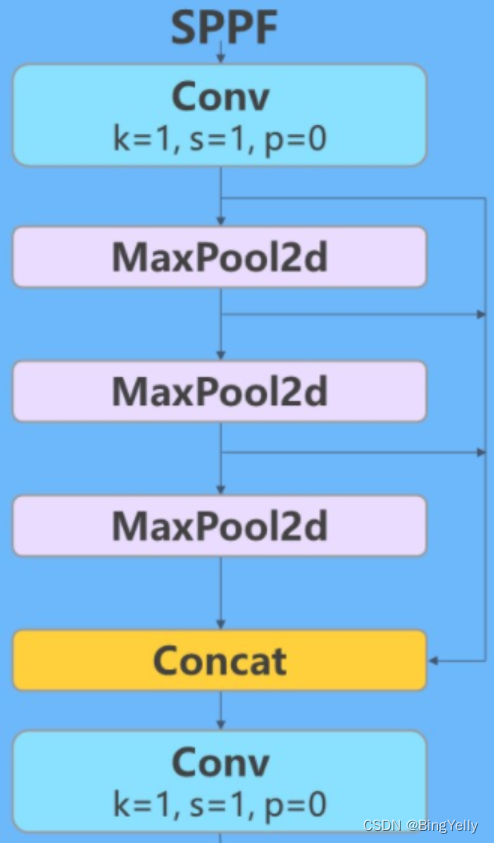
- 快速空间金字塔池化层(SPPF)。1024代表输出通道数,5代表池化核大小k。结合模块结构图和代码可以看出,最后concat得到的特征图尺寸是20*20*(512*4),经过一次Conv得到20*20*1024。在V8中的实现如下
class SPPF(nn.Module):
# Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher
def __init__(self, c1, c2, k=5): # equivalent to SPP(k=(5, 9, 13))
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * 4, c2, 1, 1)
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
def forward(self, x):
x = self.cv1(x)
y1 = self.m(x)
y2 = self.m(y1)
return self.cv2(torch.cat((x, y1, y2, self.m(y2)), 1))
2.LSKA注意力机制介绍
LSKA将深度卷积层的二维卷积核分解为级联的水平和垂直一维卷积核。与标准的LKA设计相比,所提出的分解使得可以在注意力模块中直接使用具有大卷积核的深度卷积层,无需额外的块。
视觉注意力网络(VAN)具有大卷积核注意力(LKA)模块已经在一系列基于视觉的任务上表现出卓越的性能,超越了视觉Transformer。然而,这些LKA模块中的深度卷积层随着卷积核大小的增加而导致计算和内存占用呈二次增加。
为了缓解这些问题,并实现在VAN的注意力模块中使用极大的卷积核,作者提出了一系列Large Separable Kernel Attention模块,称为LSKA。LSKA将深度卷积层的二维卷积核分解为级联的水平和垂直一维卷积核。与标准的LKA设计相比,所提出的分解使得可以在注意力模块中直接使用具有大卷积核的深度卷积层,无需额外的块。作者证明了VAN中所提出的LSKA模块可以实现与标准LKA模块相当的性能,并且计算复杂性和内存占用更低。作者还发现,随着卷积核大小的增加,所提出的LSKA设计更倾向于将VAN偏向物体的形状而不是纹理。
LSKA的结构和作用可以分为以下几个步骤:
-
初始化卷积层(conv0h和conv0v):这两个卷积层分别负责提取输入特征图的水平和垂直方向的特征。这一步是为了生成初步的注意力图,帮助模型集中注意力于图像中的重要部分。
-
空间扩张卷积层(conv_spatial_h和conv_spatial_v):在获得初步的注意力图后,LSKA使用具有不同扩张率的空间扩张卷积来进一步提取特征。这些卷积层能够在不增加计算成本的情况下,覆盖更大的感受野,捕捉更广泛的上下文信息。通过分别沿水平和垂直方向进行操作,它们可以更细致地处理图像特征,并增强模型对于图像中空间关系的理解。
-
融合和应用注意力:在经过一系列的卷积操作后,LSKA通过最后一个卷积层(conv1)融合得到的特征,生成最终的注意力图。这个注意力图会与原始输入特征图(u)进行元素级别的乘法操作,即应用注意力机制。这样,原始特征图中的每个元素都会根据注意力图的值进行加权,突出重要的特征,抑制不重要的特征。
总的来说,LSKA注意力机制通过利用大且可分离的卷积核以及空间扩张卷积来捕捉图像的广泛上下文信息,生成注意力图,并通过这个注意力图加权原始特征,以此增强网络对于重要特征的关注度,提高模型的性能。
这是LSKA原论文的翻译链接:LSKA~_lska注意力机制-CSDN博客
3.基于YOLOV8的改进
根据我的改进,在SPPF(Spatial Pyramid Pooling - Fast)的结构中,LSKA(Large-Separable-Kernel-Attention)模块被添加在了所有最大池化层(MaxPool2d)操作完成后和第二个卷积层(Conv)之前。在代码的forward方法中,输入x首先通过一个卷积层cv1,然后连续通过三个最大池化层m。这些层的输出被连接(Concat)在一起,然后整个连接后的输出被送入LSKA模块。LSKA模块处理完毕后,输出被送入另一个卷积层cv2。
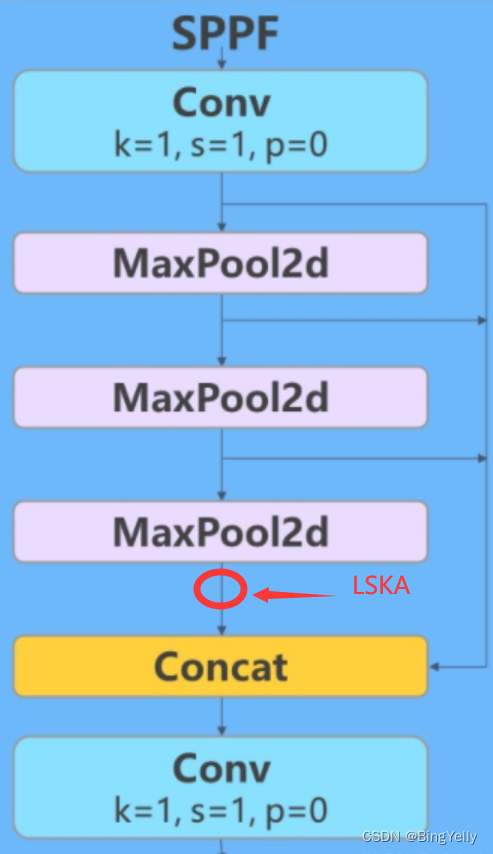
LSKA注意力机制极大的提高了SPPF模块在多个尺度上聚合特征的能力。
大概就是这个意思,如果各位有意购买改进的源码,请移步YOLOV8改进:LSKA注意力机制改进SPPF模块
代码中我已经做好了完整的修改,只需要添加数据源和自己的路径,即可训练。即买即用,对于组会忙着拼凑组会汇报的进度,忙着寻找创新点的炼丹师们极为友好,本科生直接拿来做毕业设计也是极好的,一顿饭钱就解决了本科毕业的问题。

















 1311
1311

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









