






MnasNet: Platform-Aware Neural Architecture Search for Mobile
标题含义:
- Neural Architecture Search:用人工智能来搜索出一个框架(不是靠人力来设计);
- Platform-Aware:用真实移动端平台来衡量效果(准确性、延迟);
建议读MobileNet V3前依次看完MobileNet V1,MobileNet V2和MnasNet;
发表时间:[Submitted on 31 Jul 2018 (v1), last revised 29 May 2019 (this version, v3)]
发表期刊/会议:Computer Vision and Pattern Recognition
论文地址:https://arxiv.org/abs/1807.11626v3
代码地址:https://github.com/tensorflow/tpu/tree/master/models/official/mnasnet
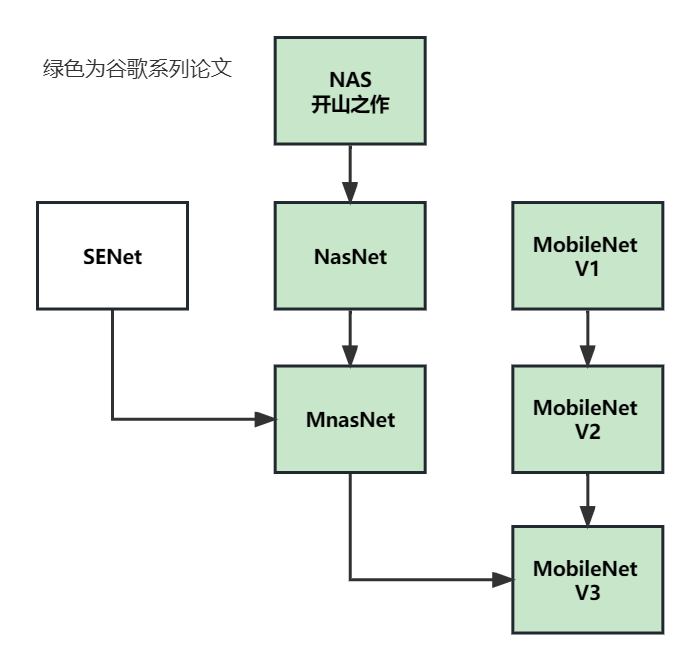
系列论文阅读顺序:
0 摘要
为移动端设计CNN的挑战在于平衡准确性和效率(延迟),手工设计模型非常困难(搜索空间非常大,无法达到全局最优,甚至不能达到局部最优);
本文实现了一种自动移动端CNN搜索方法(automated Mobile Neural Architecture Search,MNAS),并且明确的将设备的运算延迟纳入目标函数,来达到准确性与延迟之间的平衡;不像以前的工作,只是用一些代理的指标来衡量延迟,如FLOPS,本文的方法通过在移动电话上执行模型直接测量现实世界的推理延迟。
为了保持模型的多样性以及压缩搜索空间,本文提出了一种分解分层搜索空间;
实验表明,本文提出的模型有效(分类、目标检测);
亮点:
- 用人工智能来搜索(真炼丹);
- 考虑手机真实的延迟,不用代理指标;
- 分解分层的搜索空间;
1 简介
CNN变得越来越深、越来越大,同时也变得越来越慢,越来越消耗资源。
由于移动设备上可用的计算资源受限,有许多研究都几种在设计和改进CNN上。然而,人工设计一个模型非常具有挑战性,要平衡模型的精度和资源效率,搜索空间非常大。
本文用一种自动神经结构搜索方法(MNAS),来搜索出一个用于移动端的网络;如图1所示:
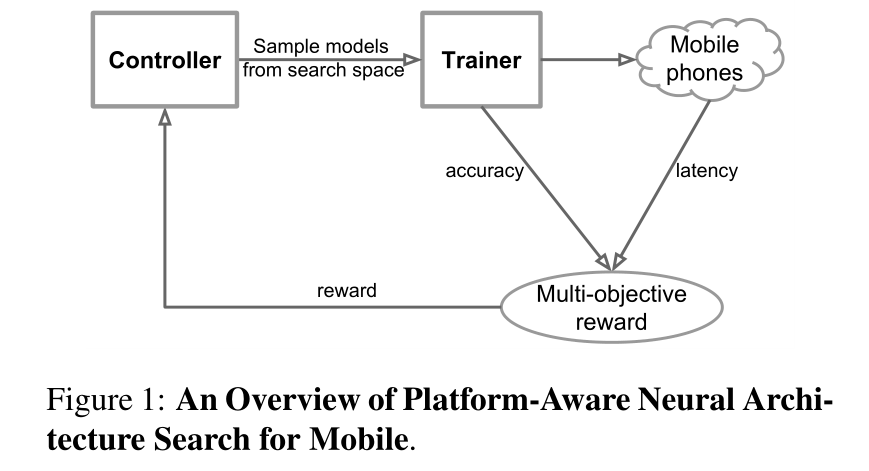
(强化学习内容)Controller从搜索空间中采样,得到模型Trainer,训练模型,一方面从精度(accuracy)评价模型,另一方面,在真实的手机上运行,用真实的延迟(latency)来评价模型。由精度和延迟得到一个目标函数(多目标函数),作为奖励(reward),返回给Controller,如此循环,以求得到最好的模型。
本文的方法基于两个主要思想(三个贡献):
- ①将设计问题表述为一个多目标优化问题,同时考虑CNN模型的准确性和推理延迟;
- ②提出分解分层的搜索空间,搜索空间划分为不同block,不同block中可以有不同的结构,以此来鼓励网络的多样性(之前的工作每个block结构相同);
- ③在不同数据集上证明有效;
2 相关工作
提高CNN资源效率方面的工作;
- 修改以前的模型:量化、剪枝、硬件等;
- 直接训练一个小模型:SENet、MobileNets、ShuffleNets、Condensenet;
- 用人工智能自动搜索模型;
3 问题表述
本文将问题表述成一个多目标搜索问题,旨在找到一个高精度、低延迟的CNN模型。延迟不像之前的模型用FLOPS来间接表示,本文用真实的手机运行延迟来表示。
对于一个给定的模型 m m m, A C C ( m ) ACC(m) ACC(m)表示模型的精度, L A T ( m ) LAT(m) LAT(m)表示模型的延迟,T是目标延迟(常数,比如我想模型的60ms内能得到推理结果)。之前的做法是把T当作一个硬指标,比如在延迟满足T的情况下,使得模型精度最大,如下式-(1)所示:
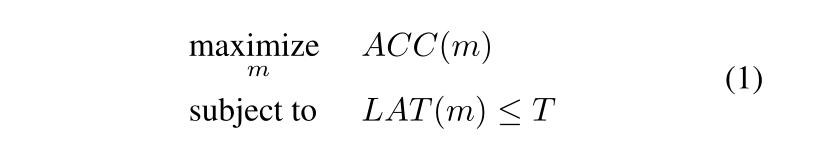
然而,这种方法只能最大化单个指标。现在本文将目标转换为以下表述,使得模型在精度和延迟直接进行博弈:
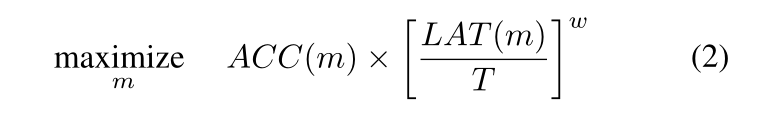
目标函数变成两项相乘,此时T不再是硬指标。精度ACC越大,模型越好,延迟LAT越小,模型越好( w < = 0 w<=0 w<=0);
其中w为权重因子,定义如下:
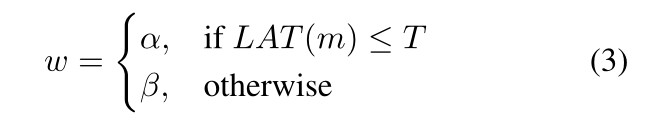
(翻译一下:延迟满足T时, w = α w=α w=α,延迟不满足T时, w = β w=β w=β)
根据帕累托最优解,一个经验值取 α = β = − 0.07 α=β=-0.07 α=β=−0.07;
图3展示了 ( α , β ) (α,β) (α,β)的典型值目标函数。
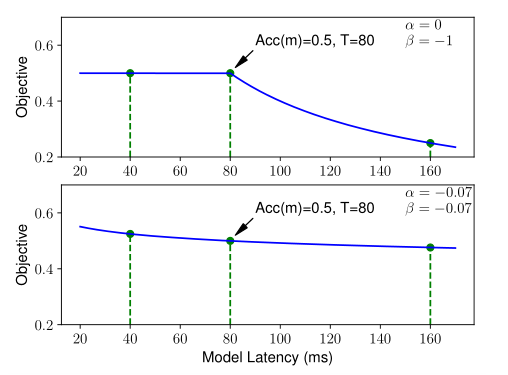
解释一下…
top: α = 0 , β = − 1 α=0,β=-1 α=0,β=−1
- 在满足硬指标T的情况下(80ms之前),此时的目标函数只和精度ACC有关( L A T ( m ) T w , w = α = 0 \frac{LAT(m)}{T}^w,w=α=0 TLAT(m)w,w=α=0时,此项恒为1)。
- 不满足硬指标T的情况下(80ms之后), w = β = − 1 w=β=-1 w=β=−1,会显著的惩罚延迟LAT,延迟LAT越大,目标函数越小。
bottom: α = β = − 0.07 α=β=-0.07 α=β=−0.07,T做为软指标,目标函数较平滑,不会被显著惩罚。
4 搜索
4.1 分解分层的搜索空间
之前的大多数方法只搜索到一个基本的最优单元,然后堆砌这个单元(丢失多样性)。
分解分层的搜索空间:把CNN的搜索空间分成若干个block,分别搜索每个block内的操作和block直接的连接,这样就允许在不同的block内使用不同的架构。
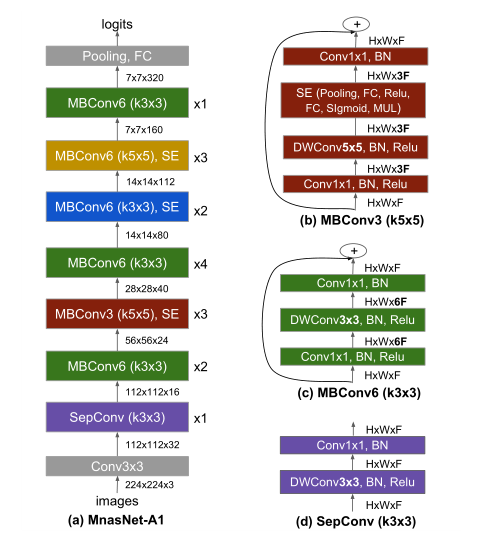
图4展示了搜索的baseline。
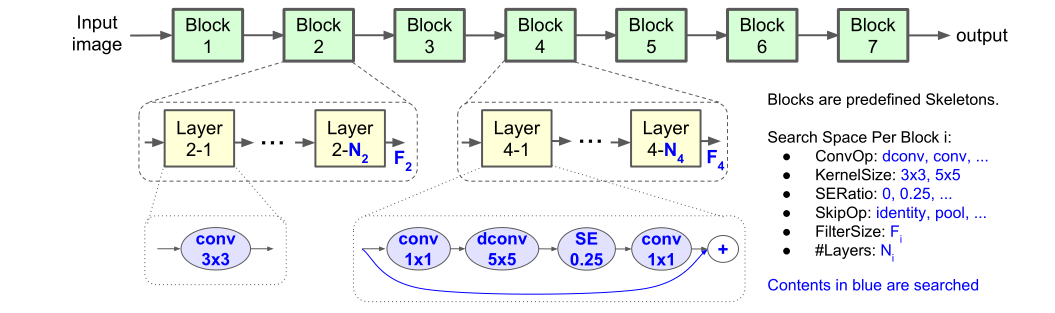
网络层根据输入输出大小被预定义为许多block。其中每个block包含不等数量可重复的相同层,其中只有第一层stride = 2(如果输入输出分辨率不同),其他层stride = 1。对于每个block,搜索单个层的操作和连接,层数为N则代表同一层重复N次。每个block之间可以不同。(图上蓝色部分都可以经过搜索来得到)
搜索的空间包括:
- 卷积操作:
- 常规卷积;
- 深度可分离卷积;
- 逆向残差卷积;
- 卷积核大小:
- 3 × 3;
- 5 × 5;
- SENet注意力机制,SERatio:
- 0
- 0.25
- 跨层连接的方式,skip:
- 池化
- 恒等映射
- 没有跨层连接
- 输出层卷积核的大小 F i F_i Fi;
- 每个block内层数 N i N_i Ni;
可以在MobileNet V2框架的基础上进行搜索,比如 0 , + 1 , − 1 {0,+1,-1} 0,+1,−1代表在MobileNet V2的基础上{不变/多一层/减一层}等;
分解分层搜索的优点,平衡了层的多样性和总搜索空间的大小之间的关系;
假设把网络划分成B个block,每个block的子搜索空间为S,每个block平均有N层,那么总的搜索空间就是 S B S^B SB(之前的是 S B ∗ N S^{B*N} SB∗N,每个层都要分别搜索)。
举个例子:S = 432,B = 5,N = 3;
S B = 1 0 13 S^B=10^{13} SB=1013;
S B ∗ N = 1 0 39 S^{B * N}=10^{39} SB∗N=1039;
4.2 搜索算法
(强化学习知识)
使用强化学习方法来解决多目标搜索问题找到帕累托最优解。
将CNN模型映射到一系列token(向量,就是CNN里结构的参数 a 1 : T a_1:T a1:T),强化学习参数θ,目标是多目标函数期望最大化,如下式定义:
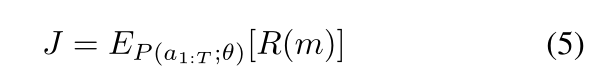
- m:采样出来的模型(由动作 a 1 : T a_1:T a1:T决定的);
- R(m):多目标函数(如式2定义);
- θ:强化学习参数;
- E P E_P EP:期望;
具体过程如图1所示;
5 实验设置
(之前都是在小型数据集训练 不直接在大型数据集训练)
本文直接在大型数据集ImageNet训练,先训练5epoch;
每种架构在64 TPUv2上训练4.5天(烧钱);在训练过程中,通过在Pixel 1手机(google的手机)的单线程CPU核上运行预测来得到真实的延迟。
大约采样了8000个模型,选了15个最优的,其中一个泛化到COCO目标检测上;
RMSProp优化器;
decay…
momentum…
batch norm…
weight decay…
dropout…
learning rate…
! batch size:4K
6 实验
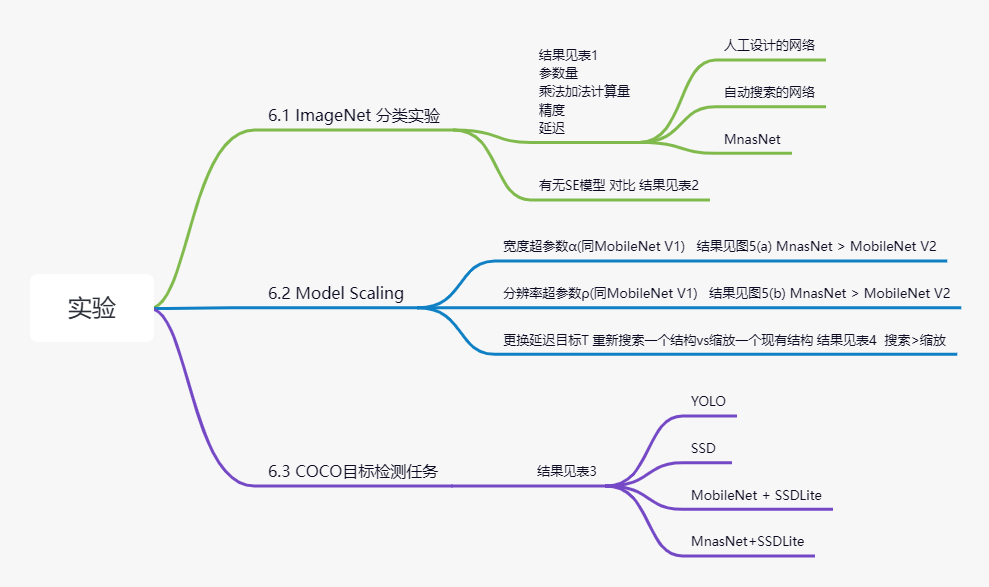
7 消融实验

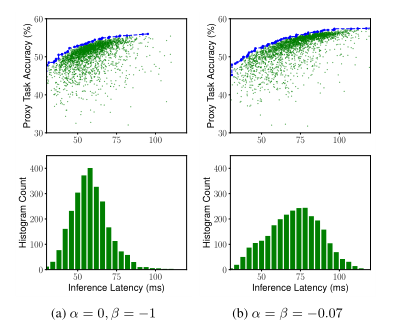
(a)作为硬指标,模型集中在T=75ms之前;
(b)软指标,延迟的搜索范围更宽,能找到更多模型;















 691
691











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









