







LlamaIndex VS LangChain,全方位比较这两个框架
大语言模型(LLMs)是当今时代最顶尖的AI技术之一。早在2022年11月,OpenAI发布了自己的生成式AI聊天机器人,这在当时引起了极大的轰动,大家纷纷讨论这种尖端技术的应用。在见识到ChatGPT的奇迹之后,企业、开发者和个人都想要拥有自己的定制版ChatGPT。这导致了对开发、集成和管理生成式AI模型的工具/框架需求激增。
由于市场上存在这样的缺口,有两个突出的框架正引领潮流:LlamaIndex和LangChain。然而,这两个框架的目标都是帮助开发者创建自己的定制大语言模型(LLM)应用程序。每个框架都有其自身的优点和缺点。本文的目的是揭示LlamaIndex和LangChain之间的关键区别,以帮助你为你的具体使用场景选择合适的框架。
LlamaIndex简介
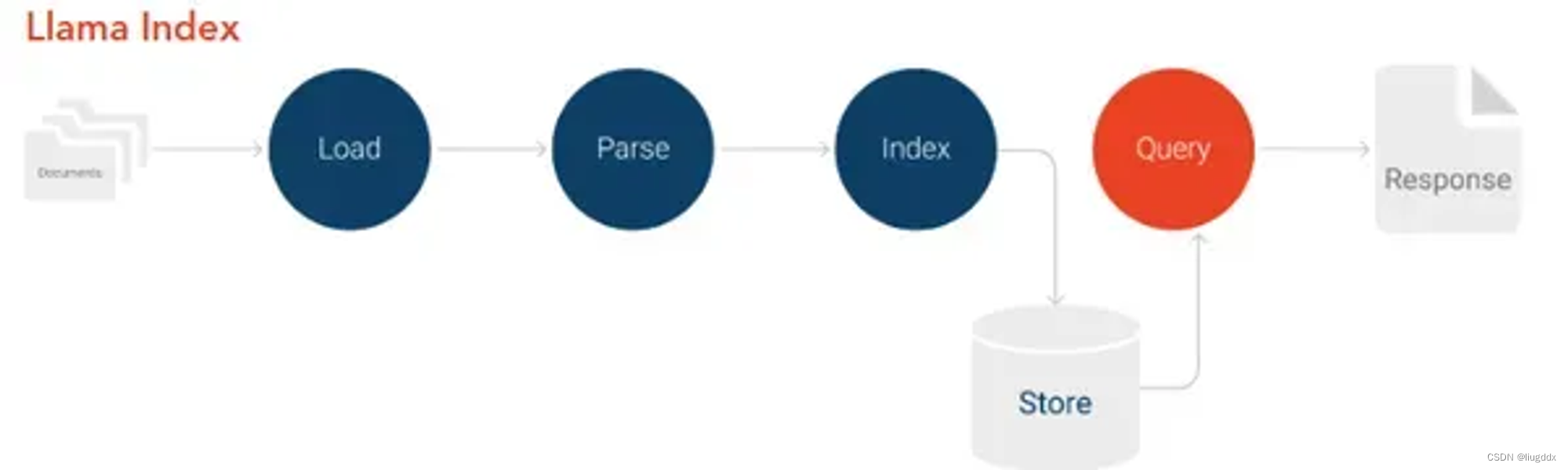
LlamaIndex 是一个框架,旨在基于自定义数据对大语言模型(LLMs)进行索引和查询。它能够通过多种数据源连接数据,如结构化数据(例如关系数据库)、非结构化数据(例如NoSQL数据库)和半结构化数据(例如Elasticsearch数据库)。
虽然你的数据是专有的,但可以将其索引为嵌入向量,这些向量在大规模上对最先进的LLMs而言是可以理解的,从而消除了重新训练模型的需求。
LlamaIndex 工作原理
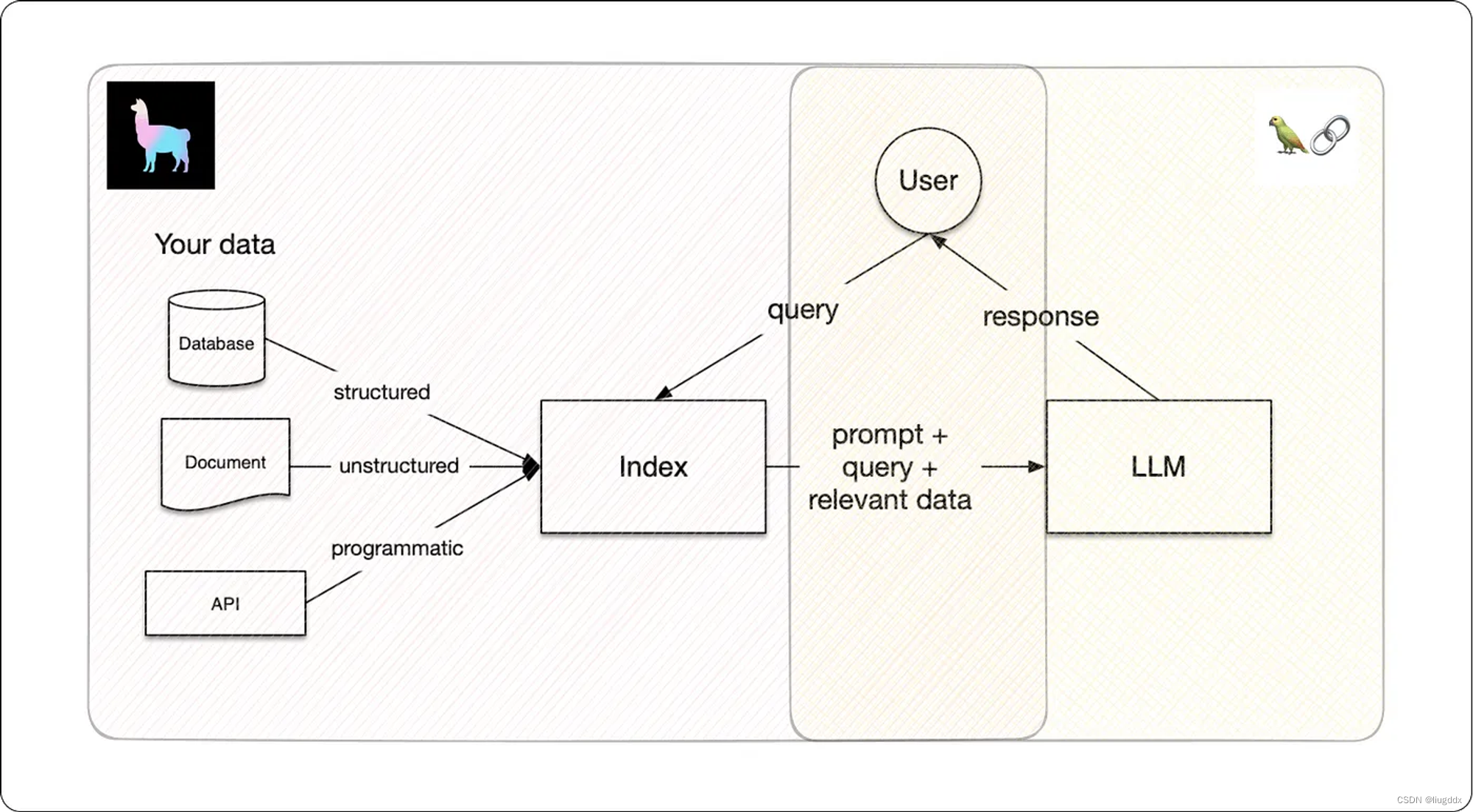
LlamaIndex 促进了LLMs的下一级定制化。它将你的专有数据嵌入到内存中,使模型在给出基于上下文的响应时逐渐变得更好。LlamaIndex 将大语言模型转变为领域知识专家;它可以作为AI助手或对话机器人,基于一个真实来源(例如包含业务特定信息的PDF文档)回答你的查询。
为了基于专有数据定制LLMs,LlamaIndex 使用了一种称为检索增强生成(RAG)的技术。RAG主要包括两个关键阶段:
- 索引阶段:专有数据被有效地转换为向量索引。在索引阶段,数据被转换为具有语义意义的向量嵌入或数值表示。
- 查询阶段:在这个阶段,每当系统被查询时,语义相似度最高的查询将以信息块的形式返回。这些信息块与原始查询提示一起被发送到LLM以获得最终响应。借助这种机制,RAG可以生成高度准确且相关的输出,而这些输出是LLMs的基础知识无法实现的。
LlamaIndex 入门
首先,开始安装 llama-index:
pip install llama-index
设置openai的密钥:
import os
os.environ["OPENAI_API_KEY"] = "your_api_key_here"
请查看
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6756
6756

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











