









摘要
视频字幕的自动生成是计算机视觉领域的一个基本挑战。最近的技术通常采用卷积神经网络(cnn)和递归神经网络(RNNs)的组合来进行视频字幕。这些方法主要侧重于通过rnn裁剪序列学习,以更好地生成字幕,而现成的视觉特征则借鉴了cnn。我们认为,为这项任务精心设计视觉特征同样重要,并提出了一种视觉特征编码技术,使用门控循环单元(gru)生成语义丰富的字幕。我们的方法通过分层地将短傅里叶变换应用于整个视频的CNN特征,在视觉特征中嵌入丰富的时间动态。它还从对象检测器中派生出高级语义,以丰富被检测对象的空间动态表示。最终的表示被投射到一个紧凑的空间,并馈送到语言模型中。通过学习包含两个GRU层的相对简单的语言模型,我们在METEOR和ROUGEL指标的MSVD和MSR-VTT数据集上建立了新的最先进的技术。
介绍
用自然语言描述视频对人类来说是微不足道的,但对机器来说是一项非常复杂的任务。为了生成有意义的视频字幕,机器需要理解视频中的对象、它们之间的相互作用、事件的时空顺序以及其他这样的细节;然而,要有能力用语法正确且有意义的自然语言句子表达这些细节[1]。这个问题的双头性最近导致计算机视觉和自然语言处理(NLP)的研究人员共同努力解决其挑战[3,4,5,30]。顺便提一下,视频字幕在新兴技术中的广泛应用,例如从教学视频生成过程[2]、视频索引和re-
Trieval [45,55];最近引起了人们的关注,认为它是计算机视觉中的一项基本任务。早期的视频字幕和描述方法,例如[26,9],主要是为了在标题中生成正确的主语、动词和宾语(也称为SVO-Triplet)。更近期的方法[50,39]依靠深度学习[28]来构建类似于典型神经机器翻译系统的框架,该系统可以生成单句[57,33]或多句[38,43,60]来描述视频。视频字幕的双管齐下问题为深度学习方法提供了一个默认的划分,即使用卷积神经网络(cnn)对视频的视觉内容进行编码[44,48],并使用语言模型将其解码为字幕。循环神经网络(RNNs)[16,14,22]是该问题后一个组成部分的自然选择。由于语义正确的句子生成在NLP领域有着更长的历史,因此基于深度学习的字幕技术主要集中在语言建模上[51,34]。对于视觉编码,这些方法通过预训练的2D CNN向前传递视频帧;或通过3D CNN传递视频片段,并从网络的内层(称为“提取层”)中提取特征。帧/片段的特征通常与均值池化相结合,以计算整个视频的最终表示。这和其他类似的视觉编码技术[33,51,18,34]——由于视频字幕研究的诞生——严重低估了视觉表示在字幕任务中的能力。据我们所知,本文提出了第一个专注于改进字幕任务的视觉编码机制的工作。我们提出了一种视觉编码技术来计算富含场景时空动态的表示,同时也考虑了视频的高级语义属性。我们的视觉编码(图1中的“v”)融合了来自多个来源的信息。我们通过分层地对2D和3D CNN提取层应用短傅里叶变换[31]来处理激活。

图1所示。视频的“c”片段和“f”帧分别用3D和2D cnn进行处理。神经元智能短傅里叶变换分层应用于这些网络的提取层激活(使用整个视频)。这就产生了丰富了时空动态的编码α和β。相关的高级对象语义γ和动作语义η是使用语言模型字典中的词汇与3D CNN和object Detector的标签的交集来导出的。Object Detector的输出特征还用于嵌入场景的空间动态和其中的多个对象。生成的代码用全连接层进行压缩,并用于学习多层GRU作为语言模型。
其中InceptionResNetv2[46]和C3D[48]分别用作2D和3D cnn。所提出的使用整个视频的神经元智能激活变换可以编码场景的精细时间动态。我们通过处理对象的位置及其从对象检测器(YOLO[37])中提取的多重信息来编码空间动态。附加到Object Detector和3D CNN输出层的语义也被用于在我们的视觉代码中嵌入高级语义属性。我们压缩视觉代码,并使用生成的表示来学习语言模型。利用高度丰富的视觉代码,我们提出了一个相对简单的门控循环单元(GRU)网络用于语言建模,该网络由两层组成,与现有的复杂模型[52,54,34,18]相比,在多个评估指标上已经取得了同等或更好的性能。
本文的主要贡献如下。我们提出了一种视觉编码技术,该技术可以有效地封装视频的时空动态,并在视频字幕的视觉编码中嵌入相关的高级语义属性。所提出的视觉特征包含检测到的对象属性、它们出现的频率以及它们的位置随时间的演变。我们通过学习基于gru的语言模型来建立所提出编码的有效性,并在MSVD[11]和MSR-VTT[57]数据集上进行了彻底的实验。对于这些数据集,我们的方法在METEOR和ROUGEmL etrics上实现了最高2.64%和2.44%的增益。
相关工作
视频字幕中的经典方法通常使用基于模板的技术,其中分别检测主语(S),动词(V)和宾语(O),然后在句子中连接在一起。然而,深度学习研究的进步也已经超越到现代视频字幕方法。这一方向的最新方法通常利用深度学习进行视觉特征编码,以及将其解码为有意义的字幕。在基于模板的方法中,第一个成功的视频字幕方法是由Kojima等人[26]提出的,该方法专注于描述一个人只执行一个动作的视频。它们严重依赖于手动创建的活动概念层次结构和状态转移模型的正确性,阻碍了其扩展到更复杂的视频。hankmann等人[21]提出了一种自动描述由一个或多个个体执行的涉及多个动作(平均七个)的事件的方法。虽然之前的大部分工作都局限于约束域[25,9],但Krishnamoorthy等人[27]领导了描述开放域视频的早期工作。[20]提出了语义层次结构来建立演员、动作和对象之间的关系。[40]使用CRF对视觉实体之间的关系进行建模,并将视频描述视为机器翻译问题。然而,上述方法依赖于预定义的句子模板,并通过从经典方法中检测实体来填充模板。这些方法对于语法丰富的句子生成来描述开放域视频来说是不够的。
与上述方法相反,深度模型直接生成给定视觉输入的句子。例如,LSTM- yt[51]通过将所有帧平均池化到LSTM中获得视频的视觉内容,并生成句子。LSTM-E[33]则探讨了视觉语境与句子语义之间的相关性。该框架中的初始视觉特征是使用2D-CNN和3D-CNN获得的,而最终的视频表示是通过平均池化来自帧/剪辑的特征来实现的,忽略了视频的时间动态。TA[59]通过引入一种注意力机制来探索视频的时域,为每一帧的特征分配权重,然后根据注意力权重将它们融合。S2VT[50]则采用光流来迎合视频的时间信息。SCN- LSTM[18]提出了语义组合网络,该网络可以从视频的平均汇集视觉内容中检测语义概念,并将该信息馈送到语言模型中,以生成具有更多相关单词的字幕。LSTM-TSA[34]提出了一种传递单元,它从图像和视频的平均池化视觉内容中提取语义属性,并将其作为补充信息添加到视频表示中,以进一步提高标题生成的质量。M3-VC[54]提出了一种多模型记忆网络,以满足长期的视觉-文本依赖,并引导视觉注意力。
尽管上述方法采用了深度学习,但它们使用了来自cnn的平均混合视觉特征或基于注意力的高级特征。这些特征在语言模型的框架中直接使用,或者通过在标准框架中引入额外的单元来使用。我们认为,这种技术没有充分利用视频字幕框架中最先进的CNN特征。我们提出了视觉内容丰富的特征,并通过经验表明,当与标准和简单的语言模型相结合时,这种视觉特征的丰富性可以胜过现有的最先进的方法。视觉特征是每个视频字幕框架的一部分。因此,与其使用高级或平均池特征,不如在我们的视觉特征之上进行构建,可以进一步增强视频字幕框架的性能。
.建议的方法
设V表示有“f”帧或“c”片段的视频。自动视频字幕的基本任务是生成-
吃了一个文本句子S = {W1, W2,…, Ww}包含与同一视频中人类生成的字幕密切匹配的“W”单词。基于深度学习的视频字幕方法通常为这个任务定义如下形式的能量损失函数:
其中Pr(.)表示概率,v∈Risd 是v的视觉表示。通过最小化定义为能量期望值Ξ(.)的成本,希望推断出的模型M可以为未见过的视频自动生成有意义的字幕。
在这个公式中,“v”被认为是一个训练输入,这使得问题的其余部分成为一个序列学习任务。因此,视频字幕的现有方法主要集中在裁剪rnn[16]或lstm[22]来生成更好的字幕,假设V的有效视觉编码以’ V '的形式可用。cnn的表示能力使其成为现有文献中视觉编码的默认选择。然而,由于视频字幕研究尚处于起步阶段,在文献中只能找到使用CNN特征进行“v”的原始方法。这些方法直接使用2D/3D CNN特征或它们的拼接进行视觉编码,其中视频的时间维度通过均值池化(mean pooling)来解决[33,34,18]。
我们承认apt序列建模对视频描述的作用,然而,我们也认为为字幕设计专门的视觉编码技术同样重要。因此,我们主要关注映射M(Q(V))→S中的算子Q(.),其中Q(V)→V .我们提出了一种视觉编码技术,该技术利用CNN特征的力量,在视觉表示中明确编码场景的时空动态,并在其中嵌入语义属性,以进一步帮助视频描述的序列建模阶段生成语义丰富的文本句子
视觉编码
为了清晰起见,我们将视频V的视觉表示描述为V = [α;β;γ;η],其中α到γ本身是由所提出的技术计算的列向量。我们在下面解释这些计算。
编码时间动态
在视频描述的背景下,从预训练的2d - cnn中提取的特征,如VGG[44]和3d - cnn,如C3D[48],已被证明对视频的视觉编码很有用。标准做法是通过2D CNN转发传递单个视频帧,并存储网络预选提取层的激活值。然后,对所有帧的这些激活值执行均值池化,以计算视觉表示。3D CNN采用了类似的过程,不同之处在于视频片段被用于前向传递而不是帧。
在对视频的细粒度时间动态进行编码时,对激活值进行简单的均值池化操作必然会失败。对于2D和3D cnn来说都是如此,尽管后者对视频片段进行建模。我们通过定义变换Tf (F)→α来解决这个缺点
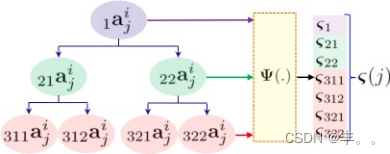
图2。短傅里叶变换Φ(.)分层应用于ivideo提取层的jneuronth 的激活aij的示意图。th

图2说明了这个操作。对提取层的每个神经元单独执行相同的操作。然后我们串联ς(j): j∈{1,2,…, m}得到α∈R(p×7×m)×1,其中m表示提取层中的神经元数量。作为执行Tf (F)→α的结果,我们计算了视频的表示,同时考虑了整个视频帧序列中的精细时间动态。因此,Tf (.)得到的表示比神经元激活的平均池化得到的表示信息丰富得多。
我们以类似的方式为视频剪辑激活集C定义Tc(.)。这种转换的结果β∈R(p×7×k)×1,其中k表示3D CNN提取层中的神经元数量。值得一提的是,3D CNN已经在短视频剪辑上进行了训练。因此,其特征在一定程度上解释了V的时间维度。然而,考虑到整个视频中的精细时间细节会显著增加我们的编码(参见第4.3节)。值得注意的是,在人类动作识别中也考虑了以分层方式利用傅里叶变换来编码时间动态[53,36]。然而,这项工作是第一次将短傅立叶变换分层地应用于视频字幕。
编码语义与空间演化
众所周知,由于在前一层分层应用卷积操作,cnn的后一层能够学习更高抽象层次的特征[28]。通常使用全连接层的激活作为字幕的视觉特征,也是由于这些表示是高级视频特征的判别变换。我们进一步采用这一概念,并认为cnn的输出层本身可以作为视频字幕的最高抽象级别的判别编码。在接下来的段落中,我们描述了有效利用这些特征的技术。在这里,我们简要地强调,网络的输出层包含了用于视频字幕的额外信息,超出了常用的网络提取层所提供的信息,因为:
1.输出标签是提取层特征的另一种转换,由提取层未考虑的网络权重产生。
2.附加到输出层的语义与视频字幕中遇到的抽象级别相同——这是输出层的独特属性。
我们使用对象检测器(即YOLO[37])和3D CNN(即C3D[48])的输出层来提取与视频中记录的对象和动作相关的语义。其核心思想是在视觉编码向量中定量地嵌入对象标签、它们的出现频率以及它们在视频中空间位置的演变。此外,我们还旨在通过视频中执行的动作的语义来丰富我们的视觉编码。将这一概念具体化的细节如下所示。
对象信息:与仅预测输入图像/帧的标签的分类器不同,对象检测器可以在单个帧中定位多个对象,从而为确定单个帧中相同类型的多个对象以及多个帧中对象位置的演变提供线索。将这种高级信息有效地嵌入到向量“v”中,可以明确区分视频中的“人在跑”和“人在走”等描述。
视频字幕系统的序列建模组件通过从中选择单词来生成文本句子
D.对象检测器在其输出端提供一个setTLe of对象标签。我们首先计算L = dl,e 并定义γ =[ζ,1 ζ,2…], ζ|L|],其中|。|表示集合的基数。γ中的向量iζ,∀i在原始视频采样的“q”帧的帮助下进一步定义。我们使用给定视频的采样帧之间的固定时间间隔来执行此采样。样本通过对象检测器,其输出用于计算ζ,i∀i。一个向量ζi 被定义为ζi=[公关(我),Fr(我),ν1,ν2我,……, νi(q−1)],其中’i表示分别计算’i对应的物体出现的概率和iz 频率,ν表示物体在帧z和z +1之间的速度(在采样的q帧中)。我们定义’ q '帧上的γ,而使用的对象检测器处理单个帧,从而得到每个帧的概率和频率值。我们通过使用下列ζ分量的定义来解决这个问题和相关的不匹配。

我们在实验中让q = 5,得到ζi ∈R10,∀i构成γ∈R(10x |L|)×1。γ中系数的指标识别视频中的对象标签(即可能出现在描述中的名词)。除非在视频中检测到对象,否则与之对应的γ的系数保持为零。对于视频描述系统的序列学习模块,提出的在γ中嵌入高级语义的方法以显式的形式包含了关于对象的高度相关信息。动作信息:视频一般记录对象及其交互。后者最好用视频中执行的动作来描述。我们已经使用了一个3D CNN来学习视频的动作描述符。我们利用该网络的输出层进一步将高级动作信息T嵌入到我们的视觉编码中。为此,我们计算A = ADe ,其中A是3DCNN输出的标签集。摘要,然后?求解-细η= ?(ϑ公关(1)]、[ϑ2,公关(2),…, [|A|, Pr(’ |A|)]∈Bel),而φ是一个二元变量,只有当动作被网络预测时,它才为1。
我们将上面描述的向量α、β、γ和η连接起来,形成我们的视觉编码向量v∈Rd,其中d =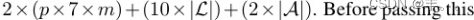
向量到我们方法的序列建模组件,我们使用全连接层执行其压缩,如图1所示。使用tanh激活函数和固定权重,该层将“v”投影到2k维空间。得到的投影“υ”被我们的语言模型所使用。
序列建模
我们遵循视频描述技术的常见管道,将视频的可视化表示提供给序列建模组件,参见图1。我们没有使用复杂的语言模型,而是使用多层门控循环单元(gru)开发了一个相对简单的模型[14]。众所周知,gru对于梯度消失问题(在长标题中遇到的问题)具有更强的鲁棒性,因为它们能够记住相关信息,并随着时间的推移忘记其余信息。
GRU有两个门:resetr Γand updateuΓ,其中更新门决定该单元更新其先前内存的程度,reset门决定如何将新输入与先前内存结合起来。具体地说,我们的语言模型将GRU 的隐藏状态计算为:
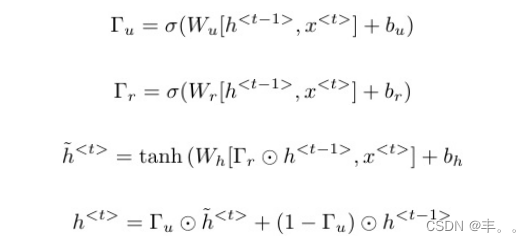
其中,表示hadamard积,σ(.)是sigmoid激活,Wq、∀q是可学习的权重矩阵,bu/r/h 表示各自的偏差。在我们的方法中,对于给定的视频,h<0> = υ,而信号x是词嵌入向量。在第4.3节中,我们报告了使用两层gru的结果,并证明了我们在提议的直接序列建模下的语言模型由于提议的视觉编码已经提供了极具竞争力的性能。
实验评价&数据集
我们使用来自现有视频描述文献的两个流行的基准数据集来评估我们的技术,即微软视频描述(MSVD)数据集[11]和msr -视频到文本(MSR-VTT)数据集[57]。在讨论实验结果之前,我们首先给出了这些数据集及其在这项工作中执行的处理的详细信息。
MSVD数据集[11]:该数据集由1,970个YouTube开放域视频组成,每个视频主要只显示一个活动。一般来说,每个片段的跨度在10到25秒之间。该数据集提供了多语言的人类注释句子作为视频的字幕。我们用英文的字幕进行实验。平均而言,一个视频可以关联41个基本事实说明文字。对于基准测试,我们遵循1200个训练样本的常见数据分割,100个样本用于验证,670个视频用于测试[59,54,18]。MSR-VTT数据集[57]:这个最近引入的开放域视频数据集包含了用于字幕任务的各种视频。它由7,180个视频组成,这些视频被转换成10,000个片段。这些视频被分成20个不同的类别。按照常见的设置[57],我们将10000个片段分为6513个样本用于训练,497个样本用于验证,剩下的2990个片段用于测试。每个视频由亚马逊土耳其机械(AMT)工作人员用20个单句注释来描述。这是视频字幕任务可用的最大的剪辑-句子对数据集之一,这也是我们选择这个数据集来对我们的技术进行基准测试的主要原因。
数据集处理和评估指标
我们将两个数据集中的标题转换为小写,并删除了所有标点符号。然后对所有的句子进行标记化。我们将MSVD的词汇量设置为9450,MSR-VTT的词汇量设置为23500。我们采用了300维的“fasttext”[10]词嵌入向量。MSVD的1,615个词的嵌入向量和MSR-VTT的2,524个词的嵌入向量在预训练集中不存在。我们没有使用随机初始化的向量或在训练集中完全忽略词汇表外的单词,而是使用单词内的字符n-gram为这些单词生成嵌入向量,并将结果向量相加以产生最终向量。我们对预训练的词嵌入进行了特定于数据集的微调。
为了将我们的技术与现有方法进行比较,我们报告了四个最流行的指标的结果,包括;双语评价替代研究(BLEU)[35]、带有显式排序的翻译评价度量(METEOR)[7]、基于共识的图像描述评价(CIDErD)[49]和面向召回的注册评价替代研究(ROUGEL)[29]。这些指标的具体定义,我们参考了原文。CIDEr中的下标“D”表示在人类判断中抑制不适当标题的更高值的度量变体。类似地,下标“L”表示ROUGE的变体,它基于预测和基本事实之间最长公共序列的召回精度分数。我们使用Microsoft COCO服务器[12]来计算我们的结果。
实验
在我们下面1报道的实验中,我们使用Inception- ResnetV2 (IRV2)[46]作为2D CNN,而使用C3D[48]作为3D CNN。前者的最后一个“avg池”层和后者的“fc6”层被认为是提取层。2D CNN在流行的ImageNet数据集[41]上进行预训练,而Sports 1M数据集[24]则用于C3D的预训练。为了处理视频,我们重新调整帧的大小,以匹配这些网络的输入维度。对于3D CNN,我们使用16帧剪辑作为输入,重叠8帧。在我们所有的实验中,YOLO[37]被用作目标检测器。为了训练我们的语言模型,我们在标题中加入了一个开始和结束标记,以处理不同句子的动态长度。对于MSVD数据集的实验,我们将最大句子长度设置为30个单词,对于MSR- VTT数据集,我们将最大句子长度设置为50个单词。这些长度限制是基于数据集中可用的标题。如果句子的长度超过设定的限制,我们将截断句子,如果句子的长度较短,我们将补零。
我们在验证集上调整语言模型的超参数。下面的结果使用了两层gru,它们采用0.5作为dropout值。我们使用学习率为2 × 10−4 的RMSProp算法来训练模型。在我们的实验中,训练使用的批大小为60。我们对我们的模型进行了50个epoch的训练。我们使用稀疏交叉熵损失来训练我们的模型。训练使用NVIDIA Titan XP 1080 GPU进行。我们使用TensorFlow框架进行开发表示“状态”。
MSVD数据集上的结果
我们将我们的方法与当前最先进的视频字幕进行了全面的基准测试。我们在表1中报告了现有方法和我们的方法的结果。对于现有技术,选择最近表现最好的方法,其结果直接取自现有文献(确保相同的评估方案)。表列给出了BLEU-4 (B-4)、METEOR (M)、CIDErD ©和ROUGEL ®指标的得分。
表格的最后七行报告了我们的方法的不同变体的结果,以突出整个技术的各个组成部分的贡献。GRU-MP表明我们使用我们的两层GRU模型,而采用常见的“均值池化(MP)”策略来解决视频的时间维度。括号中的“C3D”和“IRV2”标识了用于计算视觉编码的网络。我们将C3D和IRV2的联合使用缩写为“CI”。我们使用“EVE”来表示我们的丰富视觉编码,该编码应用分层傅立叶变换(由下标“hft”表示)对网络的激活。
表1。在MSVD数据集[11]上对BLEU- 4 (B-4)、METEOR (M)、CIDErD ©和ROUGEL ®进行基准测试。所提方法GRU-EVE的变体描述见文中。
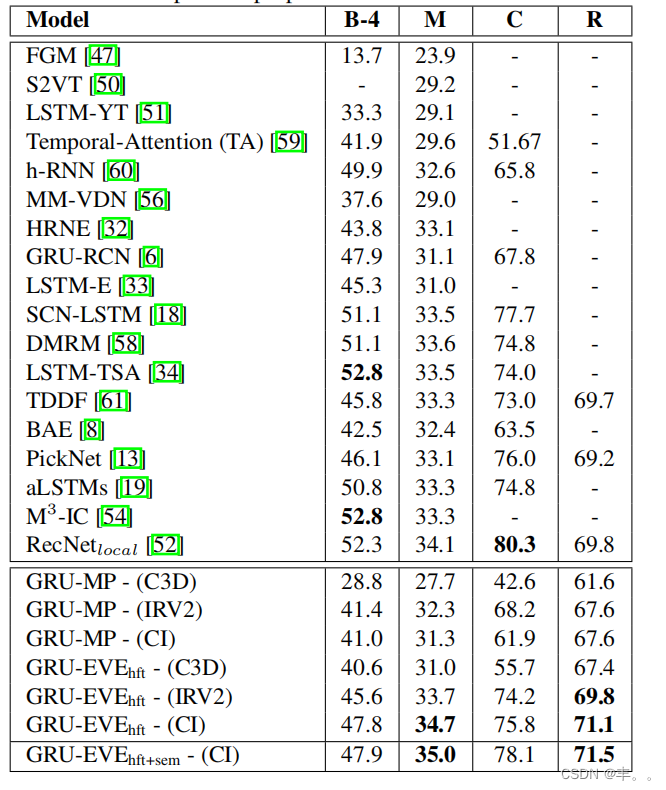
工作提取层。建议的最后一种技术,也包含了高级语义信息-由下标“+sem”表示-在表的最后一行中提到。在其余的表格中,我们也遵循相同的符号约定。
我们的方法实现了METEOR的35强值,与最接近的竞争对手相比,它提供了35.0−34.134.1× 100 = 2.64%的增益。类似地,rougeL es比当前最先进技术的增益为2.44%。对于其他指标,我们的分数与表现最好的方法相比仍然具有竞争力。需要强调的是,我们的方法的主要优势来自于视觉编码部分,而不是复杂的语言模型,这通常是现有方法的情况。当然,复杂的语言模型需要困难和计算昂贵的训练过程,这并不是我们方法的限制。
我们在图3中说明了我们方法的代表性定性结果。为简洁起见,我们在图中将我们的最终方法缩写为“GRU-EVE”。例如,复数、名词和动词的语义细节和准确性在由所提出的方法生成的标题中清晰可见。该图还报告了GRU-MP-(CI)和GRU-EVEhft-(CI)的标题,以显示与均值池化(MP)策略相比,分层傅里叶变换(hft)产生的差异。这些标题证明了值得注意的。
表2。在MSVD数据集上与单一2D-CNN方法的性能比较[11]。
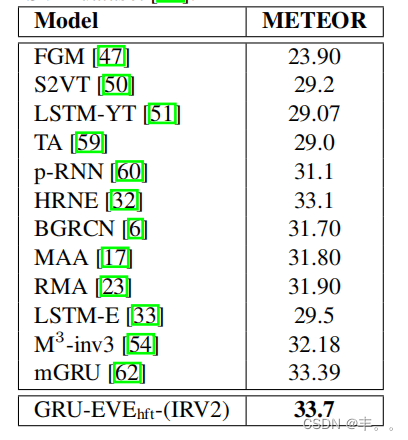
表3。使用多特征的方法在MSVD数据集[11]上的性能比较。现有方法的得分取自[54]。V表示VGG19, C表示C3D, identiv otes Inception-V3, G表示GoogleNet, I表示InceptionResNet-V2
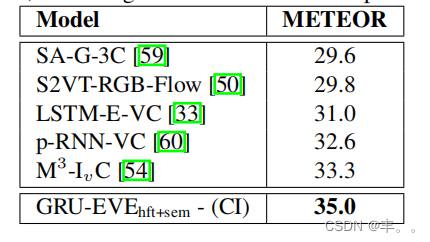
表1所示的hft比传统MP获得的增益。我们还从表中观察到,我们的方法在METEOR、CIDEr和ROUGEL上的分类性能优于基于平均池的方法,即LSTM-YT[51]、LSTM-E[33]、SCN-LSTM[18]和LSTM-TSA[34]。在这些观察结果下,我们安全地推荐所提出的分层傅立叶变换作为视频字幕中的“均值池化”的替代品。
在表2中,我们将基于单个CNN的方法变体与基于现有方法的最佳单个CNN进行了比较。结果直接取自[54]所提供的METEOR指标。可以看出,我们的方法优于所有这些方法。在表3中,我们还将我们在METEOR上的方法与最先进的方法进行了比较,这些方法必须使用多个视觉特征才能获得最佳性能。在这方面,我们的方法比最接近的竞争对手获得了5.1%的显著增益。
MSR-VTT数据集上的结果
MSR-VTT[57]是最近发布的数据集。我们将我们的方法在该数据集上的性能与最新发布的模型(如Alto[42]、RUC- UVA[15]、TDDF[61]、PickNet[13]、M3-VC[54]和RecNet[local 52])进行了比较。结果总结如表4。与MSVD数据集类似,我们的方法显着im-

图3。为MSVD测试集生成的标题示意图:为简洁起见,最终的方法缩写为GRU-EVE。图中显示了一个来自ground truth字幕的句子,以供参考
表4。在MSR-VTT数据集[57]上对BLEU-4 (B-4)、METEOR (M)、CIDErD ©和ROUGEL ®进行基准测试
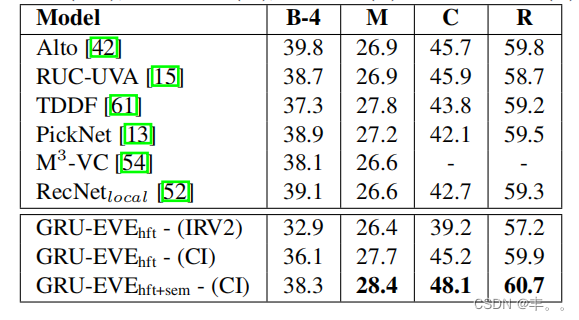 在METEOR和ROUGEmL etrics上证明了该数据集的最先进水平,同时在其余指标上取得了强有力的结果。这些结果确定了所提出的用于视觉字幕的丰富视觉编码的有效性。我们在本文的补充材料中提供了关于该数据集的定性结果的示例。
在METEOR和ROUGEmL etrics上证明了该数据集的最先进水平,同时在其余指标上取得了强有力的结果。这些结果确定了所提出的用于视觉字幕的丰富视觉编码的有效性。我们在本文的补充材料中提供了关于该数据集的定性结果的示例。
讨论
我们对所提出的方法进行了全面的实证评估,以探索其不同方面。下面我们将在文中讨论并强调其中的几个方面。必要时,我们还在论文的补充材料中提供结果来支持讨论。
对于上一节讨论的设置,我们通常观察到由提议的方法生成的语义丰富的标题。特别是,这些字幕很好地捕获了多个对象及其运动/动作。此外,这些字幕一般描述的是整个视频,而不是它的部分片段。除了只有两个,我们还测试了不同数量的GRU层,并观察到GRU层数的增加会使BLEU-4的分数恶化。然而,所有剩余的指标都有所改善。我们只保留了两个GRU层
最后的方法主要用于计算增益。此外,我们还测试了GRU的不同架构,例如状态大小为512、1024、2048和4096。在2048状态之前,我们观察到性能提升的趋势。然而,进一步的州并没有提高性能。因此,在上一节报告的结果中最终使用了2048。
虽然所提出的技术的所有组成部分都有助于整体的最终性能,但我们工作的最大启示是使用分层傅立叶变换来捕捉视频的时间动态。与在现有字幕管道中执行的“近乎标准”的平均池化操作相比,建议使用傅里叶变换可以为任何方法带来显着的性能提升。因此,我们建议在未来的技术中使用我们的变换来取代平均池化操作。
结论
我们提出了一种新的视频视觉编码技术,以生成语义丰富的字幕。除了利用cnn的表示能力外,我们的方法还明确地考虑了场景的时空动态以及视频中遇到的高级语义概念。我们以分层方式将短傅里叶变换应用于视频的2D和3D CNN特征,并通过处理对象检测器和3D CNN的输出层特征来解释高级语义。我们丰富的视觉表示用于学习一个相对简单的基于GRU的语言模型,该模型在流行的MSVD和MSR-VTT数据集上的表现与现有的视频描述方法相当或更好。
















 1366
1366











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











