







本文首发于微信公众号 CVHub,不得以任何形式转载到其它平台,仅供学习交流,违者必究!
Title: DAE-Former: Dual Attention-guided Efficient Transformer for Medical Image Segmentation
Author: Reza Azad et al. (亚琛工业大学)
Paper: https://arxiv.org/pdf/2212.13504v1.pdf
Github: https://github.com/mindflow-institue/daeformer
引言
本文旨在针对 Transformer 建模效率进行改进,作者设计了一种基于双重注意力机制引导的新型 Transformer 架构,以捕获整个特征维度的空间和通道关系,同时保持计算效率。此外,通过包含交叉注意力模块来重新设计跳跃连接路径,以确保特征的可复用性并增强模型的定位能力。所提方法可以在无需加载预训练权重的前提下,在多器官心脏和皮肤病变分割数据集上优于最先进的方法。
方法
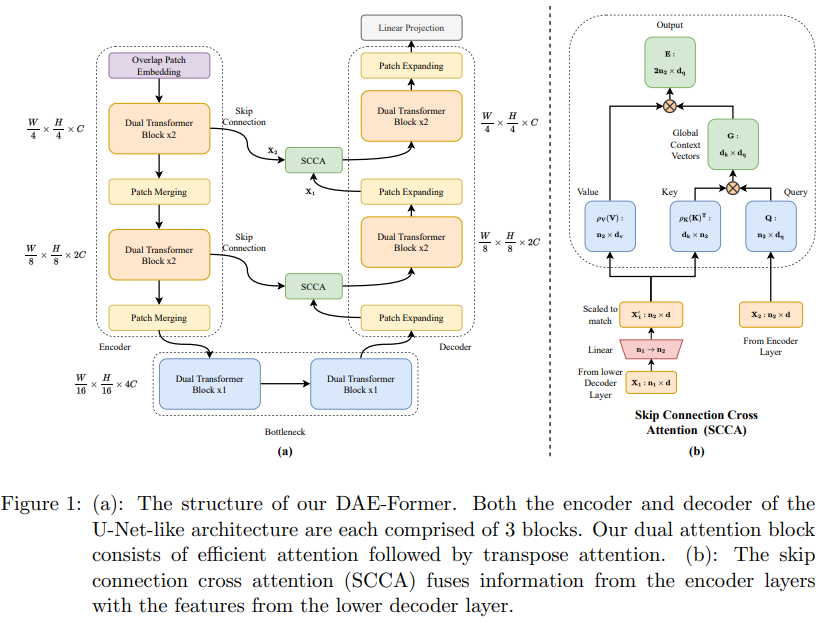
上图为 DAE-Former 的整体架构图,是一种无卷积的类 U-Net 分层纯 Transformer 结构。
给定一张输入图像,DAE-Former 利用补丁嵌入模块获得重叠的补丁标记,将输入图像下采样4倍。标记化输入然后通过编码器模块,其包含 3 个堆叠的编码器块,每个编码器块由两个连续的 Dual Transformer 层和一个 Patch Merging 层组成。 在补丁合并期间,合并 2×2 补丁令牌以减少空间维度,同时将通道维度加倍。这允许网络以分层方式获得多尺度表示。
在解码器中,Token 在每个块中再次扩展为 2 倍。 然后使用 SCCA 将每个补丁扩展层的输出与来自并行编码器层的跳跃连接转发的特征融合。生成的特征被送入两个连续的双 Transformer 层。 最后,线性投影层生成输出分割图。
高效注意力
原始的 Transformer 计算公式如下所示:
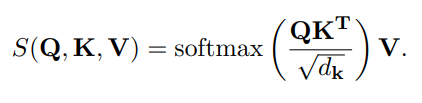
可以看到,计算复杂度是输入 Token 的二次方,这严重限制了该架构对高分辨率图像的适用性。
一种可能的优化方法如下所示:
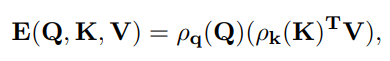
其中 ρq 和 ρk 是查询和键的规范化函数。相关研究表明,当应用 ρq 和 ρk 时,模块会产生等效的点积注意力输出,它们是 softmax 归一化函数。 因此,高效注意力首先对键和查询进行归一化,然后将键和值相乘,最后将生成的全局上下文向量与查询相乘以产生新的表示。
与点积注意力不同,有效注意力不会首先计算点之间的成对相似性。相反,键表示为 $ d_{k} $ 的注意力图 $ k^{T}_{j} $,其中 $ j $ 指的是输入特征中的位置 $ j $。 这些全局注意力图表示整个输入特征的语义方面,而不是与输入位置的相似性。这种方式极大地降低了注意力机制的计算复杂性,同时保持了较高的代表性。在本文中,作者使用等效的注意力来捕捉输入特征图的空间重要性。
转置注意力
交叉协方差注意力,也称为转置注意力,是一种通道注意力机制。 该策略仅使用转置注意力来处理更大的输入尺寸。本文提出了一种新的转置注意机制来有效地捕获完整的通道维度,其公式如下所示:
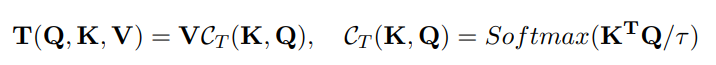
键和查询矩阵被转置,因此,注意力权重基于互协方差矩阵。这里,CT 指的是 transpose attention 的 context vector。 引入温度参数 τ 是为了在计算注意力权重之前使用应用于查询和键的 l2 范数来抵消缩放。这增加了训练期间的稳定性,但消除了一定程度的自由度,从而降低了模块的表示能力。
转置注意力的空间复杂度为 $ O(hN^{2} + Nd) $,自注意力的空间复杂度为 $ O(d^{2}/h + N d) $。Self-attention 与 token 的数量 N N N 成平方关系,而 transpose attention 与嵌入维度 d d d 成平方关系,通常小于 N N N,尤其是对于较大的图像。
高效双重注意力
通常来说,结合空间注意力和通道注意力可以有效增强模型捕获更多上下文特征的能力。因此,本文构建了一个结合转置(通道)注意力和高效(空间)注意力的双 Transformer 块。该高效双注意力模块的结构如下图所示:
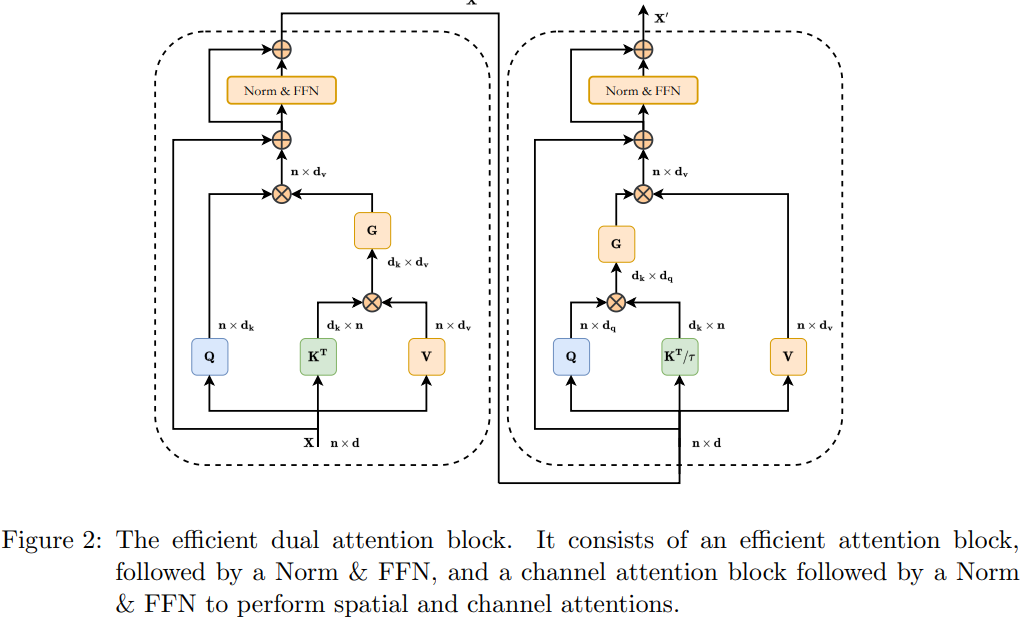
SCCA 模块
SCCA 模块被作用于 Skip Connection,可以有效地为每个解码器提供空间信息,以便它可以在生成输出掩码时恢复细粒度的细节。 SCCA 应用了高效的注意力,但是,不是对键、查询和值使用相同的输入特征,用于查询的输入是由 skip 转发的编码器层的输出连接 X2,因此得名。用于键和值的输入是较低解码器层 X1 的输出。为了融合这两个特征,需要使用线性层将 X1 缩放到与 X2 相同的嵌入维度。使用 X2 作为查询输入的动机是在高效注意力块中对多级表示进行建模。
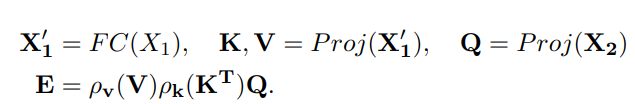
其中, ρ v ρ_{v} ρv、 ρ k ρ_{k} ρk 为归一化函数,$ P_{roj} $ 为投影函数,此处为线性投影。
实验设置
训练参数
本文方法基于 PyTorch 库实现,并在单个 RTX 3090 GPU 上进行训练。训练是在批量大小为 24 和随机梯度下降的情况下完成的,基础学习率为 0.05,动量为 0.9,权重衰减为 0.0001。 该模型使用交叉熵和 Dice 损失(Loss = 0.6 * Dice + 0.4 * BCE)训练 400 个 epochs。
数据集和评价指标
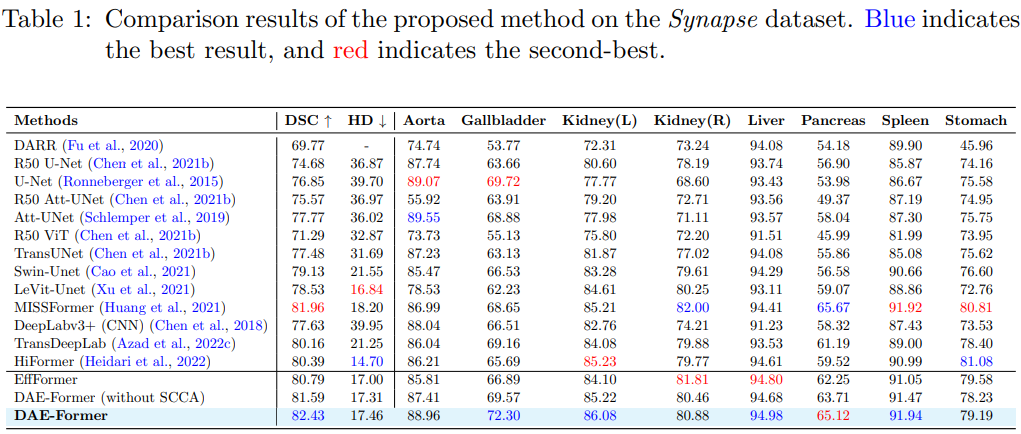
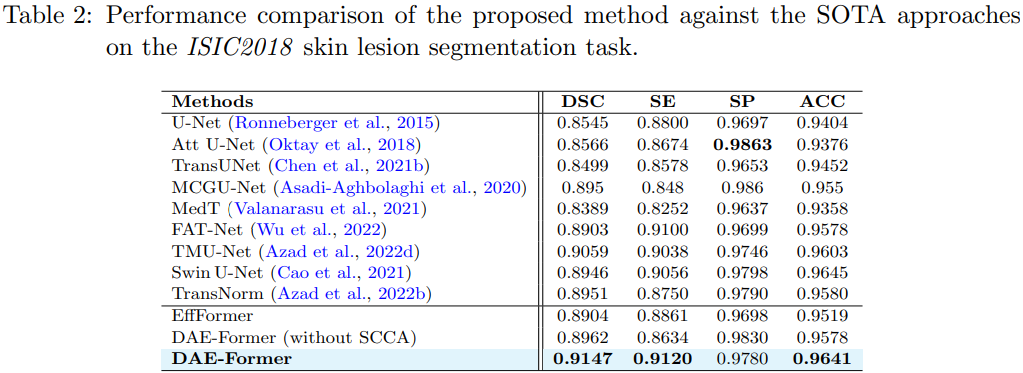
本文采用 Synapse 数据集进行评估,该数据集构成了一个多器官分割数据集,包含 30 个病例和 3779 个轴位腹部临床 CT 图像。此外,作者使用 ISIC 2018 数据集进一步评估我们的皮肤病变分割挑战方法。
定量分析
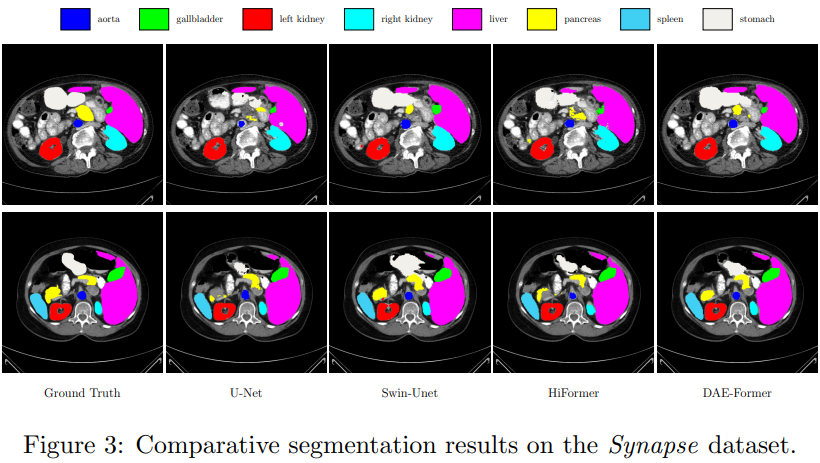
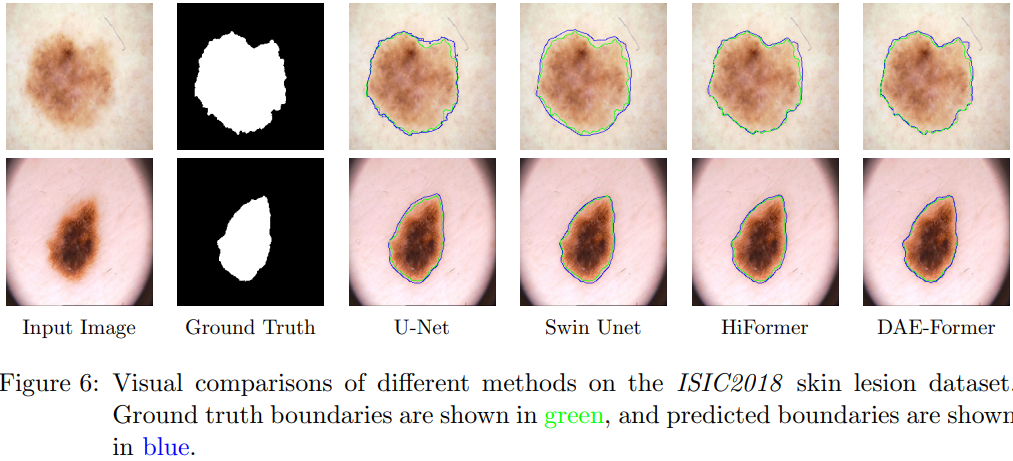
定性分析
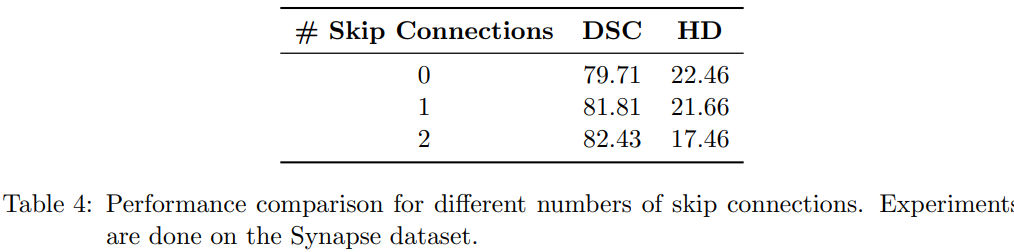
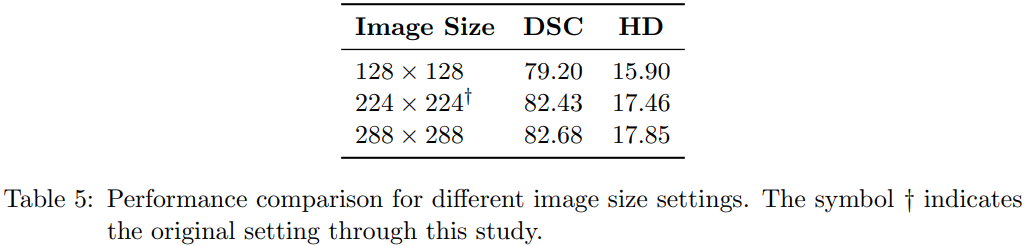
消融实验
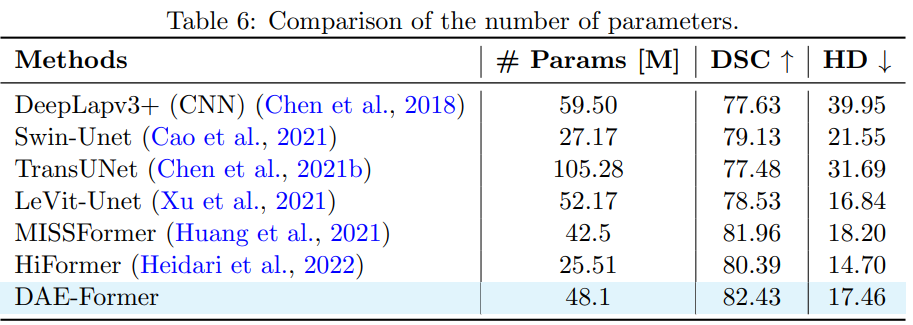
总结
本文提出了一种新颖的类 U-Net 分层纯 Transformer —— DAE-Former,它在全特征维度上同时利用空间和通道注意力。该方法通过包含双重注意力来丰富表示空间,同时与以前的架构相比保留相同数量的参数。此外,DAE-Former 还通过跳过连接交叉注意力来执行多尺度特征的融合。所提方法在突触和皮肤病变分割数据集上均取得了 SOTA 结果,从而大大超越了基于 CNN 的方法。
写在最后
如果您也对人工智能和计算机视觉全栈领域感兴趣,强烈推荐您关注有料、有趣、有爱的公众号『CVHub』,每日为大家带来精品原创、多领域、有深度的前沿科技论文解读及工业成熟解决方案!欢迎添加小编微信号:cv_huber,一起探讨更多有趣的话题!

















 1900
1900











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











