







MTUNet:混合Transformer模型用于医学图像分割
from ICASSP2022
Abstract
虽然UNet在医学图像分割领域取得了巨大的成功,但是缺少建立长程依赖关系的能力。而ViT则在这一方面有优异性能,但却需要依赖大规模的预训练,并且拥有很高的计算复杂度。同时SA只能在单个样本中建模关系,而没有办法计算整个数据集的潜在关联性。
为了解决上述问题,本文提出一种新的混合Transformer模块-MTM(Mixed Transformer Module)同时学习样本内和样本间的关系。
MTM首先使用本文精心设计的局部-全局高斯权重自注意力模块来计算注意力,然后会通过外部注意力模块学习样本间关系。基于MTM模块本文构建了一个名为MT-UNet的U型网路,用于精确的医学图像分割。在两个公开数据集上的结果显示超过了其他SOTA。
Section I Introduction
医学图像分割被证明对当今的疾病诊断至关重要。UNet这种U型的编解码结构已被证明对许多不同的分割任务都是有效的,虽然UNet及其变体目前是医学图像分割的主流框架,但是它也面临CNN的通用问题:无法建模长程依赖关系。主要是由于卷积操作本身的局部性导致的。
近期许多工作尝试通过Transformer解决上述问题,Transformer基于注意力模型最开始最要做序列预测,其中SA是Transformer的关键部分,可以建模所有输入token之间的相关性,从而使得能够处理长程依赖关系。虽然已有一些工作取得了令人满意的结果,但是它们通常严重依赖于预训练,给算法的进一步应用带来了不便;此外SA的二次复杂度也会降低像医学图像这种高维数据的处理速度。最后,SA也忽略了样本间的关联,这一部分还有很大的优化空间。
为了解决上述问题,本文重新设计了SA模块可以以更低的计算成本学习局部表征,然后在EA模块同时聚合样本内和样本间的关联。由于在绝大多数视觉任务中,附近区域的局部依赖往往比远处区域之间的依赖性增强,因此本文在细粒度的局部上下文执行局部SA,在粗粒度全局上下文执行全局SA。
在计算全局的注意力图时则使用轴向注意力来减少计算量,并进一步使用一个科可学习的高斯矩阵来增强附近区域的权重。
由于Transformer往往需要大规模预训练,因为没有办法借助先验知识,因此在设计MT-UNet时本文使用卷积作为浅层的特征提取器,这样为分割任务引入先验知识。实验结果表明MT-UNet可以超过其他最先进的方法且不需要预训练。
本文的贡献总结如下:
(1)提出MTM模块可以同时学习样本内和样本间的关系
;
(2)提出LGG-SA可以在细粒度局部和粗粒度全局上下文依次执行SA,还引入一个可学习的高斯矩阵来强调每次查询的附近区域;
(3)提出的MT-UNet是用于医学图像的分割框架,在两个数据集验证了其有效性。
Section II Methods
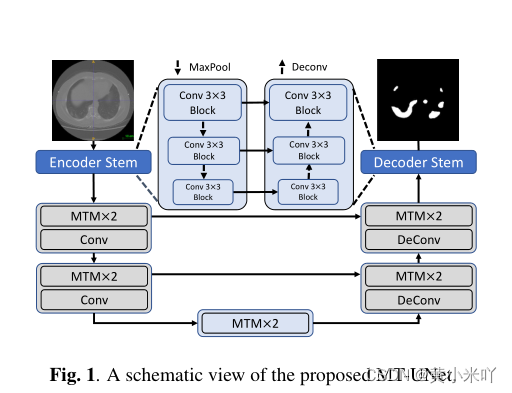
Part 1 Overall Structure Design
Fig 1展示了网络的整体结构,主要网络还是编解码结构,使用skip-connection来保持地尺度特征。可以看到只有在较深层次使用MTM模块,此时空间分辨率比较小计算成本也比较低。因为本文希望最开始的几层更关注局部关系,它们也包含更多的高分辨率细节信息;通过卷积还可以在建模全局关系之前引入一些结构信息,这些信息对小规模的医学图像数据集很有帮助。
需要注意的是,是由的MTM模块都使用步长为2的步长卷积实现下采样和通道扩展,使用反卷积实现上采样/通道压缩。
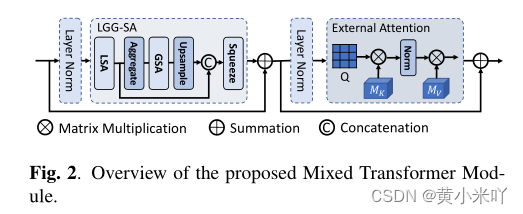
Part 2 Mixed Transformer Module
Fig 2展示了MTM模块的内部结构,可以看到包含LGG-SA和EA两部分。
LGG-SA用于建模不同粒度的依赖关系,包括局部和全局的;EA则计算样本之间的相关性。
这一模块用于替代原始Transformer的SA模块,用来实现更好的性能、更低的时间复杂度。
Part 3 Local-Global Gaussian-Weight Self-Attention
LGG-SA核心思想是局部计算,不像SA会计算所有位置,本文使用了local-global策略和高斯mask,使得LGG-SA会更多关注局部信息,实验结果表明LGG-SA可以节省计算资源提高模型性能,具体结构参见Fig 3.
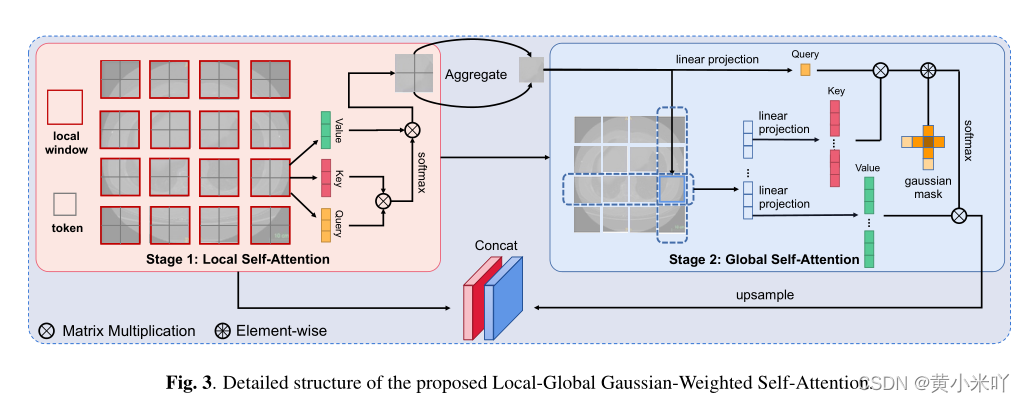
Local-Global Self-Attention
SA为了捕获所有像素之间的关系会计算Q,K,V,这三个矩阵都是X的线性变换,但是在计算机视觉中往往附近区域的相关性比远处的更重要,因此在计算时就没有必要为远处的区域花费这么多计算成本。因此Local SA只计算窗口内的依赖,然后将每个窗口的token聚合为一个全局token表示该窗口的主要信息。
聚合函数使用了步长卷积、最大池化等,其中LDConv(动态卷积)的效果是最好的。
对整个特征图降采样后可以以更少的成本计算全局SA。整个计算流程表述为:
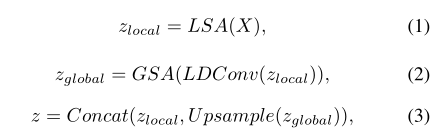
可以看到局部和全局表述级联后作为最终的输出。
Gaussian-weighted Axial Attention
与原始SA中局部注意力不同之处在于,本文使用了高斯加权的轴向注意力。主要受Gaussian Transformer的启发GWAA会使用一个可学习的高斯矩阵来加权token,同时由于使用的是轴向注意力计算复杂度比较低。可以看到最终某位置的输出,是q-k相似性并且进行高斯加权后的结果:
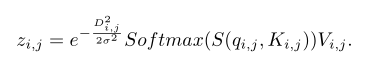
因为方差是可学习的,因此上式也可以写成:
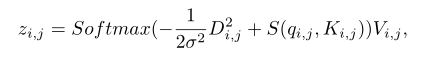
并且本文使用了相对位置信息嵌入,效果比绝对位置要好。 LSA计算复杂度是O(n),轴向注意力的时间复杂度为O(n^3/2).
Part 4 External Attention
External Attention最初是为了解决原始SA无法建模样本之间的关系这一问题的,原始SA是在每个样本内通过线性变换计算注意力,而EA是所有样本共享两个记忆单元(Mk和Mv),这两个记忆单元记录了整个数据集的基本信息。
在本文的设计中Q使用了一个额外的线性硬着来扩充其通道维度,主要为了提升模块的学习能力。
EA的时间复杂度为O(n),因此MT-UNet的总体时间复杂度为O(n^3/2).
Section III Experiments
数据集:
Synapse——多器官分割,
ACDC——心室MRI分割
实验细节:
单张RTX 1080Ti(算量控制的也太好了吧)
输入图像 224 * 224
Adam Optimizer
Part 1 Ablation Study
消融实验主要将本文的注意力模块与原始注意力、只是用Local或只是用Global进行比较。实验结果参见Table 1.
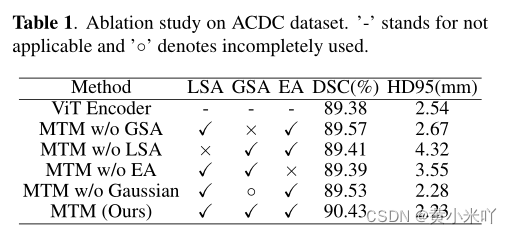
可以看到Local和Global对模型都是不可或缺的,删除任意一个都会导致模型性能的下降。
高斯掩膜也证明了可以帮助网络更关注局部信息;添加EA后DSC和HD95两个指标分别提升了1.04%和1.32mm。因此MTM一方面可以提升性能,一方面计算复杂度也更低。
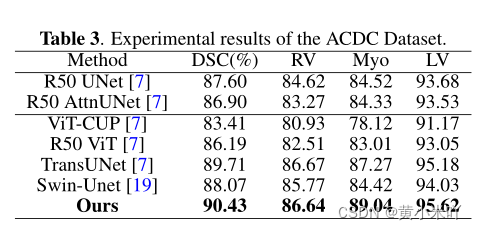
Part 2 Experimental Results
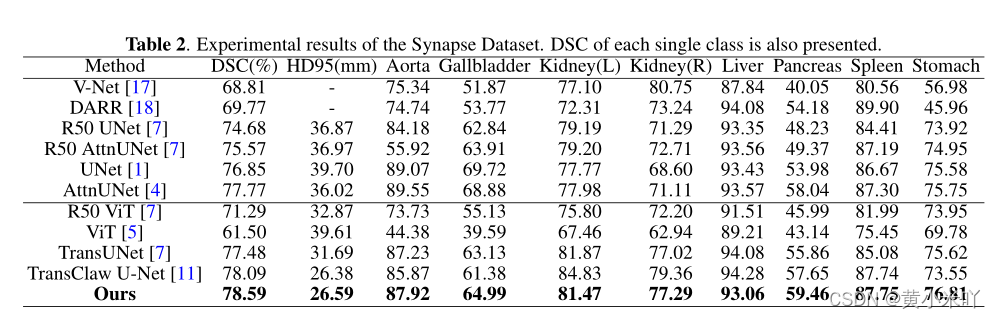
对比实验结果参见Table 2和Table 3。可以看到在两个数据集上MTUNet的效果均超过了CNN,还超过了一大截,并且也优于其他基于Transformer的模型,比如Trans-UNet等。
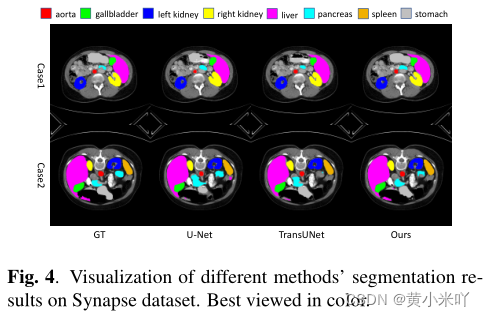
Fig 4可视化了一些多器官分割结果,在CASE 1中可以看到本文在分割主动脉、胃部等具有压倒性优势,与表中的对比结果一致;从CASE2可以看出MT-UNet对于一些复杂器官的分割(肝脏、左肾)也超过了其他Transformer模型,主要得益于其对局部和全局上下文的均衡感知。
Section IV Conclusion
本文提出一种高效的视觉Transformer模型:MT-UNet,通过设计的LGG-SA和EA模块可以同时学习局部和全局信息。可以在更低的时间复杂度上超过其他ViT的性能。
Reference:
External Attention
Gaussian Transformer

















 1049
1049

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









