







本文首发至微信公众号:CVHub,不得以任何形式转载或售卖,仅供学习,违者必究!

Title: Synthetic Data from Diffusion Models Improves ImageNet Classification
Paper: https://arxiv.org/pdf/2304.08466.pdf
导读
深度生成模型正变得越来越强大,现在可以根据文本提示生成多样且高保真度的逼真图像样本。它们**是否已经达到了可以用于生成数据增强的自然图像的程度,从而有助于改善具有挑战性的分类任务?**论文展示了大规模的文本到图像扩散模型可以进行微调,以产生具有 SOTA FID(256×256 分辨率下为 1.76)和 Inception 分数(256×256 为 239)的条件分类模型。该模型还在分类准确度分数方面产生了新的 SOTA(256×256 生成样本为 64.96,对于 1024×1024 样本改进为 69.24)。使用所得模型的样本增强 ImageNet 训练集,在强 ResNet 和 Vision Transformer baseline上显著提高了 ImageNet 分类准确度。
贡献

**扩散模型能否产生足够质量和多样性的图像样本,以提高像ImageNet分类这样的经典基准任务的性能?由于现有的架构、数据增强策略和训练方法已经得到充分调整,这样的任务设定了很高的门槛。一个密切相关的问题是,大规模文本到图像模型在下游任务中能否作为良好的表示学习器或基础模型?论文探讨了这个问题在生成数据增强的背景下,表明这些模型可以被微调,以在ImageNet上产生最先进的类条件生成模型。**论文的主要贡献如下:
- 论文展示了对 ImageNet 训练数据进行微调后的 Imagen 模型在多个分辨率上达到了SOTA,在 256×256 的图像样本上获得了 FID 1.76 和 IS 239。
- 论文进一步证实,从这样微调的类别条件模型中获取的数据也提供了新的**SOTA的分类精度分数 (CAS),**通过在合成数据上训练 ResNet-50 模型,然后在真实的 ImageNet 验证集上对其进行评估来计算 (如图1上半部分所示)。
- 最后,在卷积和基于 Transformer 的多种架构下,使用生成数据训练的模型性能进一步提高,特别是将合成数据与真实数据相结合,使用更多合成数据,以及更长时间的训练时长 (如图1下半部分所示)。
方法
在接下来的研究中,论文探讨了两个主要问题:大规模的文本到图像模型是否能够被微调为类别条件的ImageNet模型,以及这样的模型在生成数据增强方面的用途。

由于ImageNet-1K数据集的图像在尺寸和分辨率上有所不同,平均图像分辨率为469×387,论文在不同的分辨率下检查合成数据生成,包括64×64、256×256和1024×1024。与直接在ImageNet数据上训练扩散模型的以前工作不同,这里论文利用一个大规模的文本到图像扩散模型作为基础,部分原因是探索在更大的通用语料库上进行预训练的潜在好处。这样做的一个关键挑战涉及文本到图像模型与ImageNet类别的对齐,如上图所示,以前的方法给定的文本标签可能与野外中的多个视觉概念相关联,或者与ImageNet有系统性差异的视觉概念相关联。
Imagen Fine-tuning
论文利用大规模文本到图像模型Imagen作为backbone文本到图像生成器,使用ImageNet训练集进行微调。该模型包括一个预训练的文本编码器,将文本映射到上下文嵌入,并包括一系列的有条件扩散模型,将这些嵌入映射到分辨率逐渐增加的图像中。
考虑到ImageNet中高分辨率图像的相对匮乏,作者仅在ImageNet-1K训练集上微调64×64基础模型和64×64→256×256超分辨率模型,保持最终的超分辨率模块和文本编码器不变。64×64基础模型进行210K步微调,64×64→256×256超分辨率模型进行490K步微调。在整个微调实验中,论文根据默认的Imagen采样器和ImageNet-1K验证集中计算超过10K样本的FID评分来选择模型。
Sampling Parameters
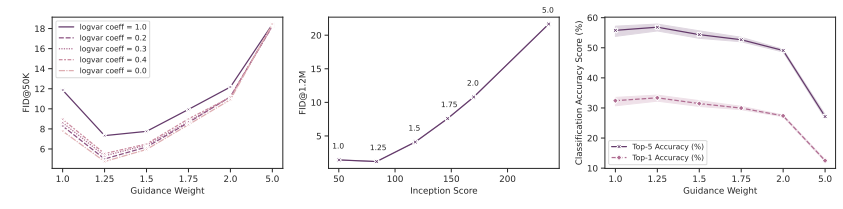
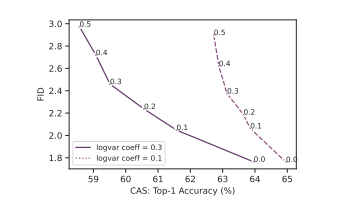
总的来说,作者通过对超参数进行扫描和分析,发现指导权重、噪声条件增强和对数方差对超分辨率模型的采样参数都对模型的表现有影响。在选择超参数时,作者通过平衡FID和CAS等评价指标的表现,选择了指导值为1.25,在其他分辨率下为1.0,使用DDPM采样器的对数方差混合系数分别为0.0和0.1的64×64和256×256样本,并进行了1000步的去噪。在1024×1024的分辨率下,使用DDIM采样器,步数为32,并不使用噪声条件增强进行采样。
Generation Protocol
作者使用经过微调的Imagen模型和优化后的采样超参数来生成类似于ImageNet数据集训练集的合成数据。这意味着作者旨在产生与真实ImageNet数据集中每个类别相同数量的图像,同时保持与原始数据集相同的类别平衡。然后,作者构建了大规模的训练数据集,从1.2M到12M张图像不等,即原始ImageNet训练集大小的1倍到10倍之间。
实验
Sample Quality: FID and IS
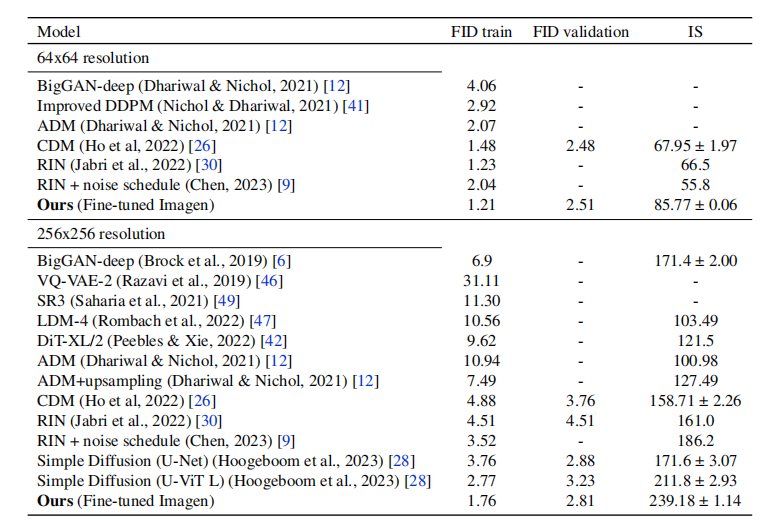
FID和Inception Score仍然是评估生成模型的标准指标。表1报告了论文的方法和现有的类别条件和指导式方法的FID和IS。论文的微调模型优于所有现有方法,包括仅在ImageNet数据上训练的使用U-Net和更大的U-ViT模型的最新方法。这表明,**大规模预训练后在特定领域的目标数据上进行微调是实现更好的视觉质量的有效策略。**也表明,在资源有限的情况下,可以通过微调模型权重和调整采样参数来改善扩散模型的性能。
Classification Accuracy Score
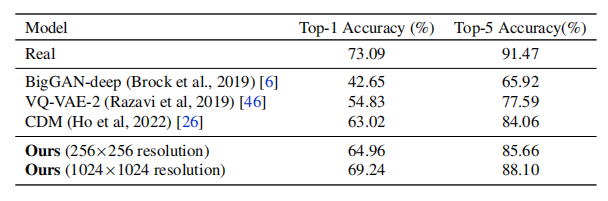
分类准确度分数(CAS)是评估生成模型下游训练性能的更好代理,**CAS衡量了仅在合成样本上训练的模型在真实测试数据上的ImageNet分类准确度。**表2报告了论文微调模型的样本在256×256和1024×1024分辨率下的CAS。结果表明,论文微调的类别条件模型在256×256分辨率下的表现优于先前的方法,无论是Top-1还是Top-5准确度都很好。如表2所述,论文方法在1024×1024分辨率下实现了69.24%的SOTA Top-1分类准确度分数。这大大缩小了与在真实数据上训练的ResNet-50模型之间的差距。
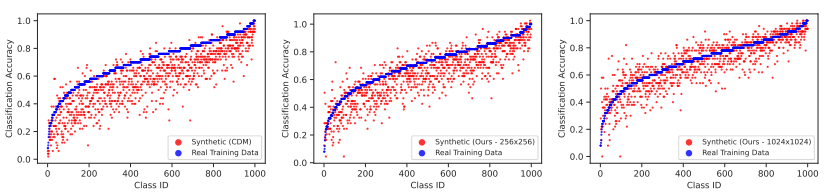
图5展示了使用生成数据(红色)和真实数据(蓝色)训练的模型在ImageNet的1000个类别上的分类精度。从图中可以看出,在256×256分辨率下,使用CDM样本训练的ResNet-50模型的精度普遍低于使用真实数据训练的模型。而对于论文微调的Imagen模型,在256×256分辨率下的表现则更好一些,有一些类别上的模型在生成数据上训练的精度优于在真实数据上训练的模型。
特别是在1024×1024分辨率下,论文微调的Imagen模型在大多数类别上都优于使用真实数据训练的模型。这表明论文的生成模型能够生成高质量的图像,使得用于下游任务的合成数据可以替代真实数据。
Classification Accuracy with Different Models
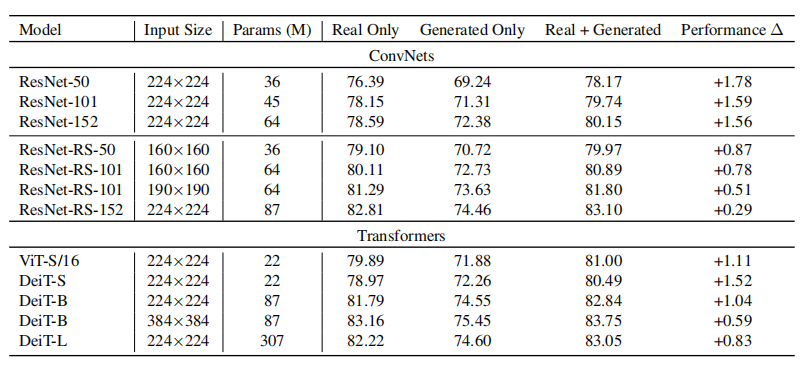
作者进一步评估了生成数据与真实ImageNet数据的区分能力,并分析了使用不同架构、输入分辨率和模型容量的模型的分类准确率。作者考虑了多个基于ResNet和Vision Transformer (ViT) 的分类器,包括 ResNet-50、ResNet-RS-50、ResNet-RS-152x2、ResNet-RS-350x2、ViT-S/16 和 DeiT-B。如上表所示,作者发现,使用扩散模型生成的图像将真实数据扩充后,所有分类器的性能都有了显著提高。
Merging Real and Synthetic Data at Scale
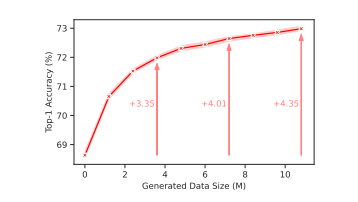
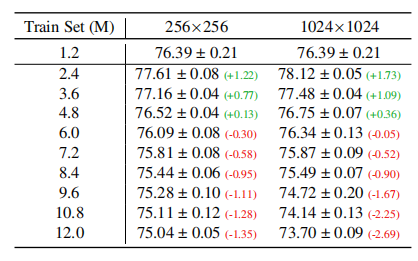
本节讨论了在ResNet-50分类器中使用生成数据来增强真实数据的效果。如图5所示,在几乎所有测试的模型中,将生成样本与真实数据混合会降低Top-5分类器的准确度。但在低分辨率下(64×64),如图6所示,将生成数据量增加到真实数据量的九倍可以显著提高性能。然而,在更高分辨率下(256×256和1024×1024),如表4所示,即使增加九倍的生成数据,性能提升仍然有限。使用微调的扩散模型生成的数据可以显著提高性能,最多可以将生成数据的大小增加到真实数据的4到5倍。这比之前的研究结果有所提升。
总结
本文提出了当前使用基于扩散模型的生成数据来进行数据增强在多大程度上是有效的。在ImageNet分类任务中,本文表明可以利用大规模的文本生成模型fine-tuning得到SOTA FID(256×256分辨率下为1.76)和Inception Score(256×256分辨率下为239),此外还证明了这种生成模型的新CAS SOTA(256×256模型为64.96,增强到1024×1024生成样本时为69.24)也有助于提高ResNet和Transformer等多种模型的ImageNet分类准确性。虽然这些结果很有潜力,但仍有许多问题需要解决,例如为什么1024×1024的分辨率的图像可以提高CAS,以及为什么64×64的分辨率在大量扩增生成数据时可以保持分类准确性的提升,但高分辨率图像的分类性能会随着生成数据集的增大而下降等等。这些问题仍需进一步研究。
CVHub是一家专注于计算机视觉领域的高质量知识分享平台,全站技术文章原创率常年高达99%,每日为您呈献全方位、多领域、有深度的前沿AI论文解决及配套的行业级应用解决方案,提供科研 | 技术 | 就业一站式服务,涵盖有监督/半监督/无监督/自监督的各类2D/3D的检测/分类/分割/跟踪/姿态/超分/重建等全栈领域以及最新的AIGC等生成式模型。欢迎关注微信公众号CVHub或添加小编好友:cv_huber,备注“知乎”,参与实时的学术&技术互动交流,领取CV学习大礼包,及时订阅最新的国内外大厂校招&社招资讯!



















 1760
1760

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











