









 本文介绍了如何通过引入EMA注意力机制改进YOLOv8,分析了不同网络结构下EMA的应用,探讨了创新点在数据集上的表现,并提供了实验结果和数据集验证计划。
本文介绍了如何通过引入EMA注意力机制改进YOLOv8,分析了不同网络结构下EMA的应用,探讨了创新点在数据集上的表现,并提供了实验结果和数据集验证计划。
问题点:创新点为什么在自己数据集不涨点,甚至出现降点的现象
🚀🚀🚀本文解决对策:拿EMA注意力作为案例进行展开,将创新点放入不同网络位置,总有一种能够高效涨点
🚀🚀🚀YOLOv8改进专栏:http://t.csdnimg.cn/hGhVK
学姐带你学习YOLOv8,从入门到创新,轻轻松松搞定科研;
1.EMA注意力介绍

论文:https://arxiv.org/abs/2305.13563v1
录用:ICASSP2023
通过通道降维来建模跨通道关系可能会给提取深度视觉表示带来副作用。本文提出了一种新的高效的多尺度注意力(EMA)模块。以保留每个通道上的信息和降低计算开销为目标,将部分通道重塑为批量维度,并将通道维度分组为多个子特征,使空间语义特征在每个特征组中均匀分布。
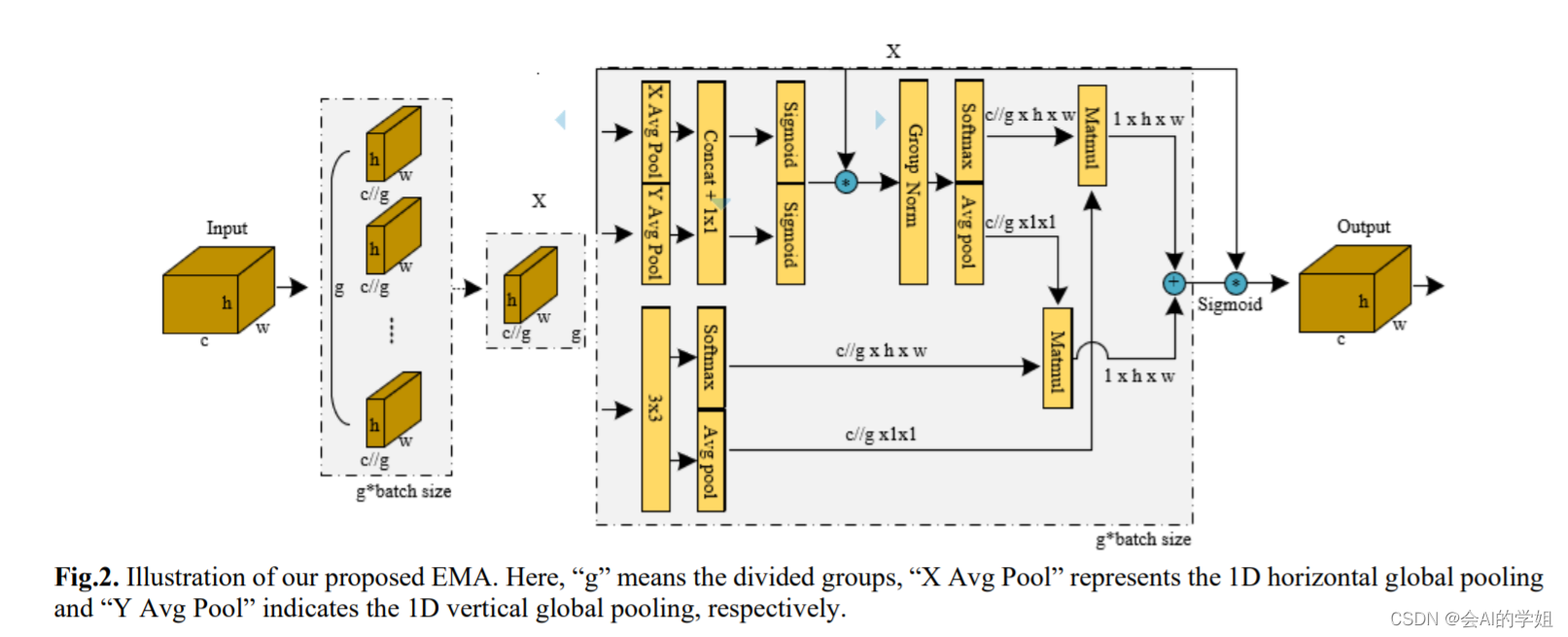
本文提出了一种新的跨空间学习方法,并设计了一个多尺度并行子网络来建立短和长依赖关系。
1)我们考虑一种通用方法,将部分通道维度重塑为批量维度,以避免通过通用卷积进行某种形式的降维。
2)除了在不进行通道降维的情况下在每个并行子网络中构建局部的跨通道交互外,我们还通过跨空间学习方法融合两个并行子网络的输出特征图。
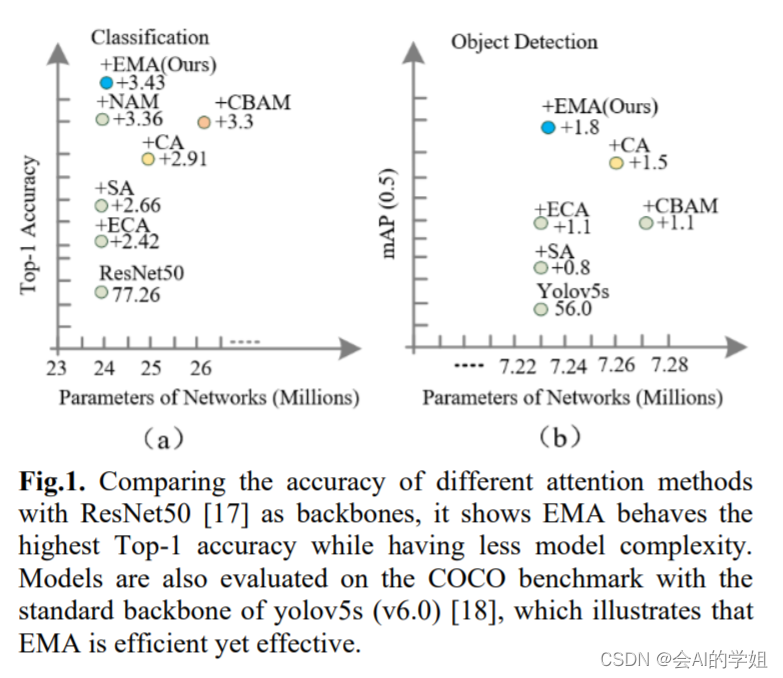
3)与CBAM、NAM[16]、SA、ECA和CA相比,EMA不仅取得了更好的结果,而且在所需参数方面效率更高。
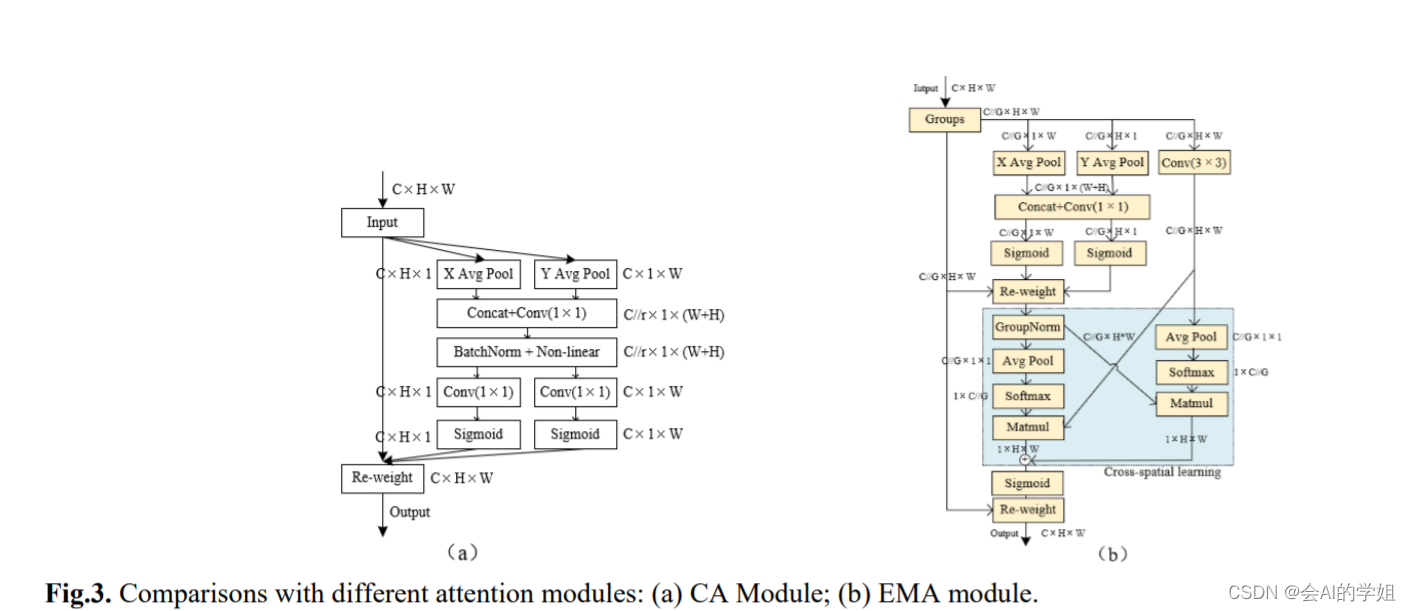
CA块首先可以被视为与SE注意力模块类似的方法,其中利用全局平均池化操作对跨通道信息进行建模。通常,可以通过使用全局平均池化来生成信道统计信息,其中全局空间位置信息被压缩到信道描述符中。与SE微妙不同的是,CA将空间位置信息嵌入通道注意图以增强特征聚合。
并行子结构帮助网络避免更多的顺序处理和大深度。给定上述并行处理策略,我们在EMA模块中采用它。EMA的整体结构如图3 (b)所示。在本节中,我们将讨论EMA如何在卷积操作中不进行通道降维的情况下学习有效的通道描述,并为高级特征图产生更好的像素级注意力。具体来说,我们只从CA模块中挑选出1x1卷积的共享组件,在我们的EMA中将其命名为1x1分支。为了聚合多尺度空间结构信息,将3x3内核与1x1分支并行放置以实现快速响应,我们将其命名为3x3分支。考虑到特征分组和多尺度结构,有效地建立短期和长程依赖有利于获得更好的性能。
1.1 代码详见:
YOLOv8改进:注意力系列篇 | 高效多尺度注意力 EMA | ICASSP2023_会AI的学姐的博客-CSDN博客
2.不同网络结构分析
2.1 原始YOLOv8网络
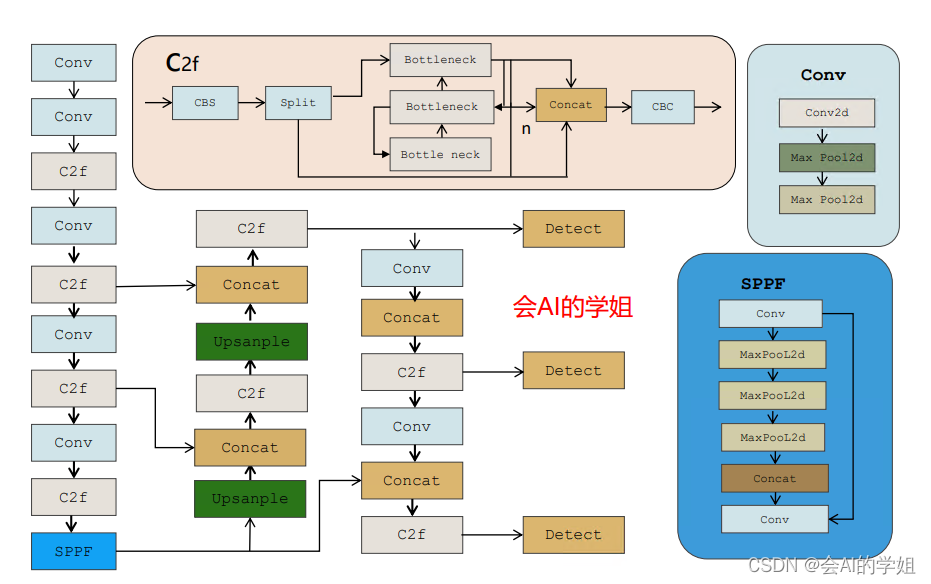
2.1 yolov8_EMA_attention1.yaml
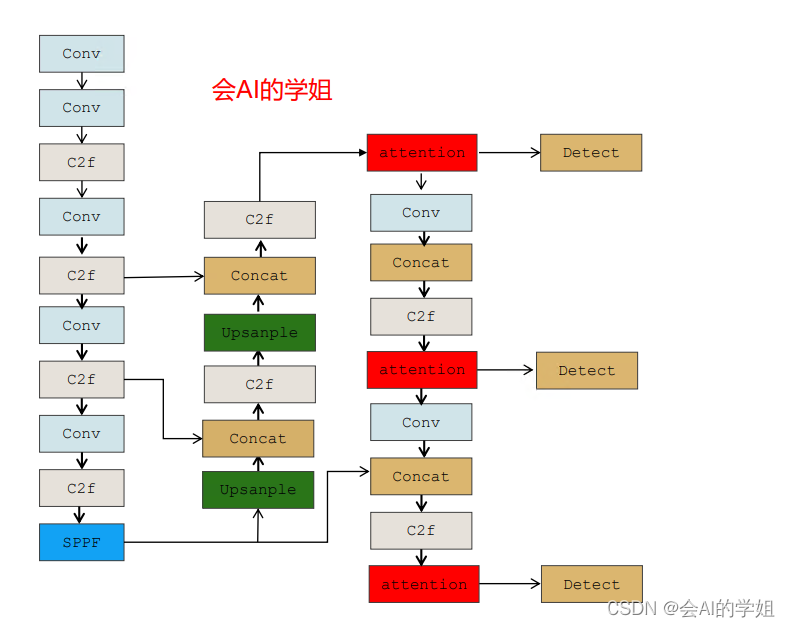
将EMA和neck里的连接Detect的3个C2f结合
# Ultralytics YOLO 🚀, GPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 1 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, EMA_attention, [256]] # 16 (P5/32-large)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 19 (P4/16-medium)
- [-1, 1, EMA_attention, [512]] # 20 (P5/32-large)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 23 (P5/32-large)
- [-1, 1, EMA_attention, [1024]] # 24 (P5/32-large)
- [[16, 20, 24], 1, Detect, [nc]] # Detect(P3, P4, P5)
2.2 yolov8_EMA_attention2.yaml
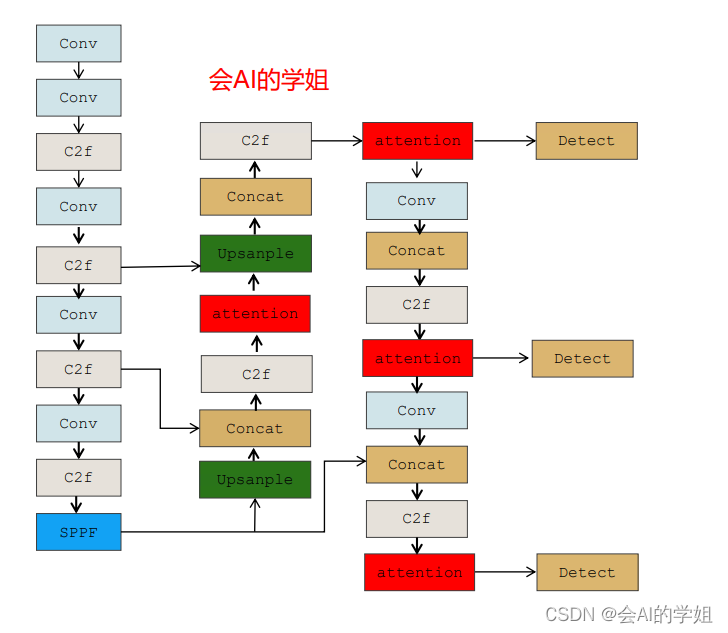
将EMA和neck里的C2f结合
# Ultralytics YOLO 🚀, GPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 1 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, EMA_attention, [512]] # 13
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 16 (P3/8-small)
- [-1, 1, EMA_attention, [256]] # 17 (P5/32-large)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 20 (P4/16-medium)
- [-1, 1, EMA_attention, [512]] # 21 (P5/32-large)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 24 (P5/32-large)
- [-1, 1, EMA_attention, [1024]] # 25 (P5/32-large)
- [[17, 21, 25], 1, Detect, [nc]] # Detect(P3, P4, P5)
2.3 yolov8_EMA_attention3.yaml
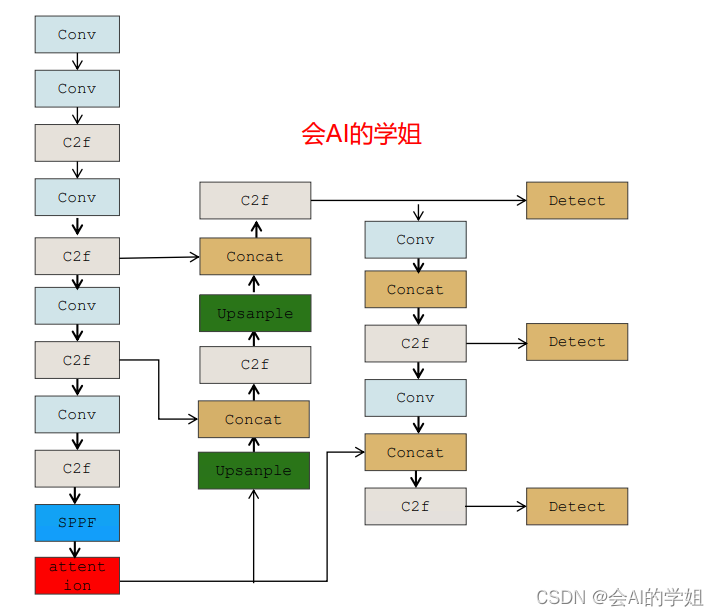
将EMA放在backbone SPPF后面
# Ultralytics YOLO 🚀, GPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 1 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 1, EMA_attention, [1024]] # 10
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 13
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 19 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 22 (P5/32-large)
- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)
2.4 yolov8_EMA_attention4.yaml
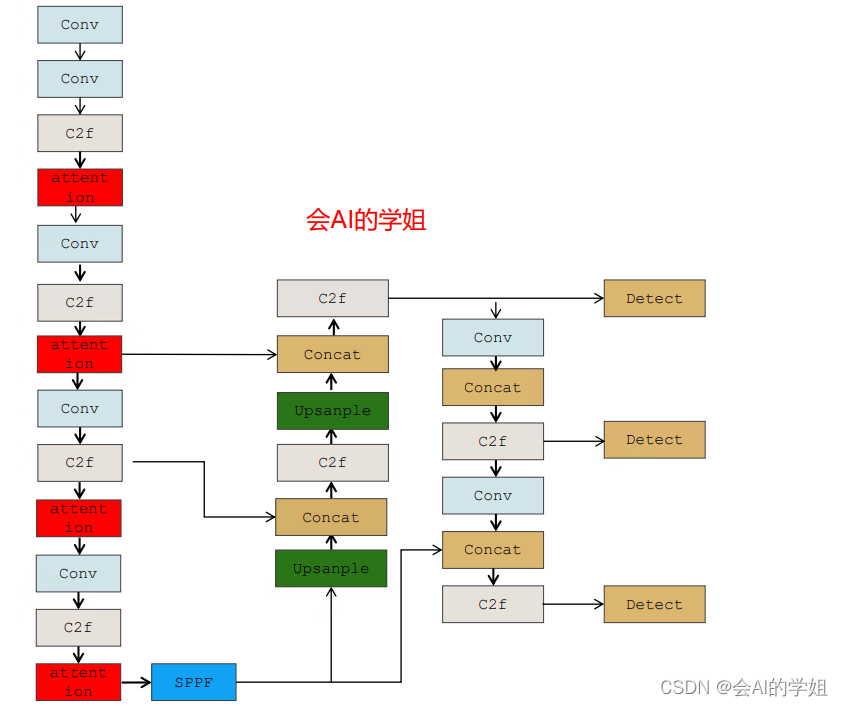
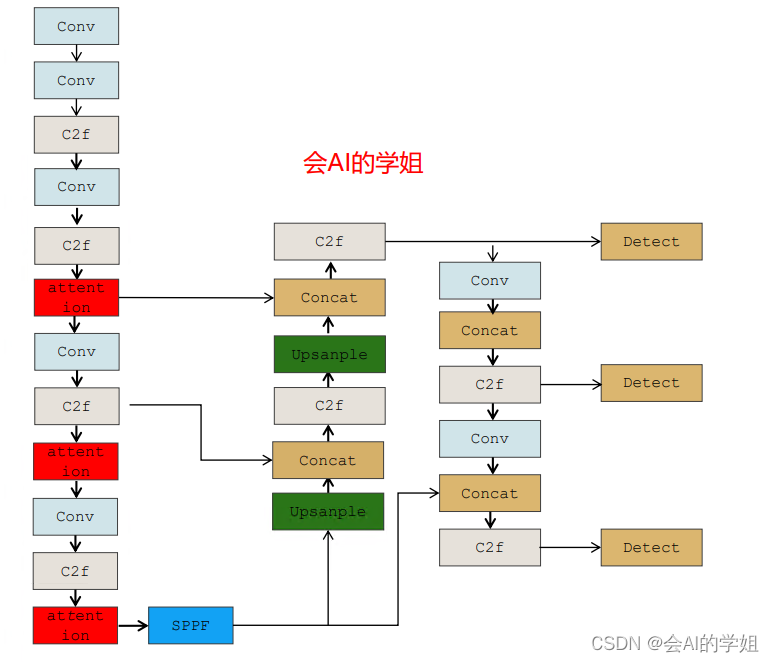
将EMA放在backbone的C2f后面
# Ultralytics YOLO 🚀, GPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 1 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, EMA_attention, [128]] # 3
- [-1, 1, Conv, [256, 3, 2]] # 4-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, EMA_attention, [256]] # 6
- [-1, 1, Conv, [512, 3, 2]] # 7-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, EMA_attention, [512]] # 9
- [-1, 1, Conv, [1024, 3, 2]] # 10-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, EMA_attention, [1024]] # 12
- [-1, 1, SPPF, [1024, 5]] # 13
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 9], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 16
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 5], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 19 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 16], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 22 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 25 (P5/32-large)
- [[19, 22, 25], 1, Detect, [nc]] # Detect(P3, P4, P5)
2.5 yolov8_EMA_attention5.yaml
将EMA放在backbone的P3、P4、P5 C2f后面
# Ultralytics YOLO 🚀, GPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 1 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, EMA_attention, [256]] # 5
- [-1, 1, Conv, [512, 3, 2]] # 6-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, EMA_attention, [512]] # 8
- [-1, 1, Conv, [1024, 3, 2]] # 9-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, EMA_attention, [1024]] # 11
- [-1, 1, SPPF, [1024, 5]] # 12
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 8], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 15
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 18 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 15], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 21 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 24 (P5/32-large)
- [[18, 21, 24], 1, Detect, [nc]] # Detect(P3, P4, P5)
3.数据集验证
下一步工作,将在不同数据集下验证可行性。
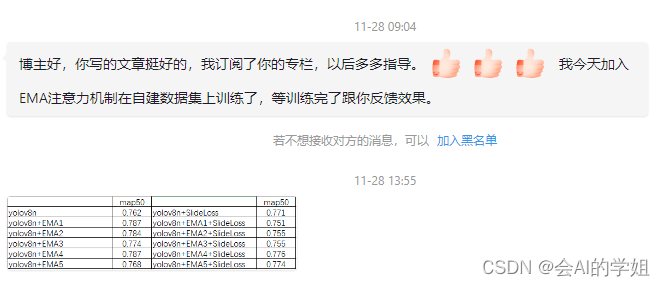
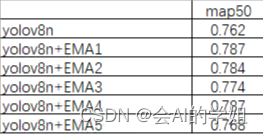
4.订阅者对比实验结果分享
感谢分享,能够涨点替你开心


















 4086
4086

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











