







 该专栏为热销专栏榜 第42名
该专栏为热销专栏榜 第42名 本专栏深入探讨YOLO的改进技术,包括C2f、主干网络、检测头和注意力机制,同时提供入门基础知识及实战项目案例。
本专栏深入探讨YOLO的改进技术,包括C2f、主干网络、检测头和注意力机制,同时提供入门基础知识及实战项目案例。
1️⃣ 什么⁉️你还不知道怎么改进YOLOv8模型?那你一定不能错过这个宝藏专栏‼️
模型改进看似高深,其实也可以很“接地气”~🎯作为一名疯狂踩坑后终于豁然开朗的AI实践者,我必须强推这个专栏!
2️⃣ 150+种模型改进方法,全都能跑!性价比爆炸🔥
模块结构分析、核心原理讲解、作者的深入总结,还有适配多种场景的改法合集,让人一看就懂,一试就通!
✅ 无废话的讲解
✅ 全流程代码,改完能直接上GPU跑
✅ 初学者也能轻松理解,不再怕模型崩溃😩
3️⃣ 全是近三年顶会/顶刊的先进模块,创新度拉满💡
你以为只是简单“套模板”?NONONO~作者专门筛选了来自CVPR、ICCV、NeurIPS等顶会的最新高性能模块,然后手把手教你怎么融入YOLOv8并优化重构!
💡 注意力机制 | 卷积变体 | 解码器改进 | 特征增强……
全都是经过二次创新、适配YOLOv8任务的版本,真正做到融合 + 创新 + 实用!
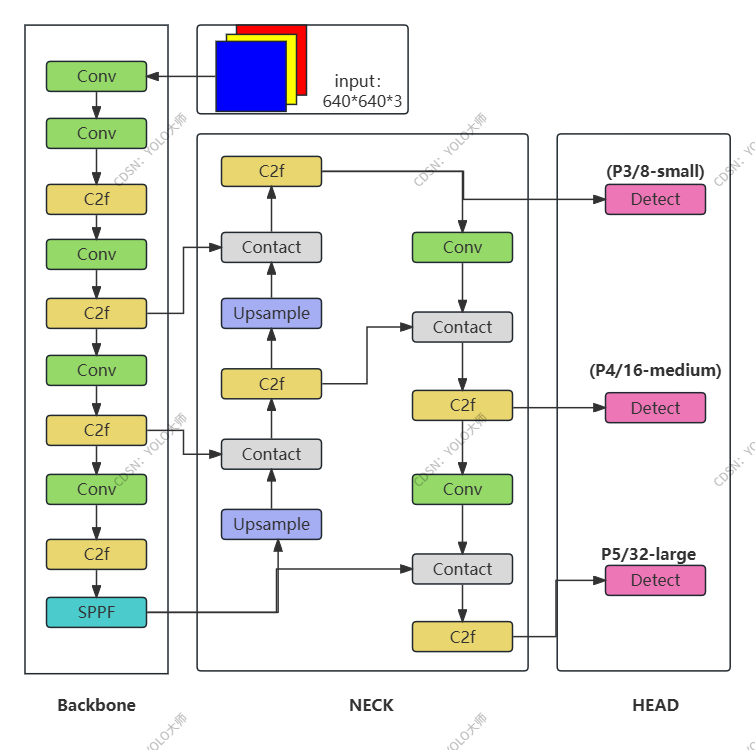
YOLOv8模型结构
YOLOv8创新改进目录(持续更新中)
购买专栏后,即可获取所有程序文件,下方仅为部分文件截图。获得文件后,只需将程序放入个人项目中即可直接运行和训练。 你可以根据自己的需求,自由组合不同模块,针对数据集进行有效优化提升。
入门必会知识点
实战小项目
| 序号 | 标题 | 链接 |
|---|---|---|
| 1 | 写给初学者的YOLO目标检测 概述 | https://blog.csdn.net/shangyanaf/article/details/130399439 |
| 1 | 如何使用 YOLOv9 进行对象检测 | https://blog.csdn.net/shangyanaf/article/details/136757338 |
| 2 | YOLOv9教程:如何在自定义数据上进行YOLOv9的分割训练 | https://blog.csdn.net/shangyanaf/article/details/138284645 |
| 3 | 使用Yolov8和OpenCV计算视频中手扶梯上的人数 | https://blog.csdn.net/shangyanaf/article/details/134430259 |
| 4 | 使用YOLOV5实现视频中的车辆计数 | https://blog.csdn.net/shangyanaf/article/details/134877969 |
| 5 | YOLO结合PySimpleGUI 构建实时目标检测软件!SoEasy! | https://blog.csdn.net/shangyanaf/article/details/135285799 |
注意力机制
| 序号 | 标题 | 链接 |
|---|---|---|
| 1 | 【YOLOv8改进-注意力机制】STA(Super Token Attention) 超级令牌注意力机制 | https://blog.csdn.net/shangyanaf/article/details/139113660 |
| 2 | 【YOLOv8改进-注意力机制】Polarized Self-Attention: 极化自注意力 ,更精细的双重注意力建模结构 | https://blog.csdn.net/shangyanaf/article/details/137295765 |
| 3 | 【YOLOv8改进-注意力机制】Non-Local:基于非局部均值去噪滤波的自注意力模型 | https://blog.csdn.net/shangyanaf/article/details/139105131 |
| 4 | 【YOLOv8改进-注意力机制】MLCA(Mixed local channel attention):混合局部通道注意力 | https://blog.csdn.net/shangyanaf/article/details/139279527 |
| 5 | 【YOLOv8改进-注意力机制】LSKNet(Large Selective Kernel Network ):空间选择注意力 | https://blog.csdn.net/shangyanaf/article/details/137614259 |
| 6 | 【YOLOv8改进-注意力机制】LSKA(Large Separable Kernel Attention):大核分离卷积注意力模块 | https://blog.csdn.net/shangyanaf/article/details/139249202 |
| 7 | 【YOLOv8改进-注意力机制】iRMB: 倒置残差移动块,即插即用的轻量注意力 | https://blog.csdn.net/shangyanaf/article/details/136658166 |
| 8 | 【YOLOv8改进-注意力机制】HAT(Hybrid Attention Transformer): 混合注意力机制 | https://blog.csdn.net/shangyanaf/article/details/139142532 |
| 9 | 【YOLOv8改进-注意力机制】EMA(Efficient Multi-Scale Attention):基于跨空间学习的高效多尺度注意力 | https://blog.csdn.net/shangyanaf/article/details/139160226 |
| 10 | 【YOLOv8改进-注意力机制】DAT(Deformable Attention):可变性注意力 | https://blog.csdn.net/shangyanaf/article/details/139193465 |
| 11 | 【YOLOv8改进-注意力机制】D-LKA Attention:可变形大核注意力 | https://blog.csdn.net/shangyanaf/article/details/146242317 |
| 12 | 【YOLOv8改进-注意力机制】CPCA(Channel prior convolutional attention)中的通道注意力,增强特征表征能力 | https://blog.csdn.net/shangyanaf/article/details/139186904 |
| 13 | 【YOLOv8改进-注意力机制】CoTAttention:上下文转换器注意力 ,增强视觉表示并提高计算机视觉任务的性能 | https://blog.csdn.net/shangyanaf/article/details/139261641 |
| 14 | 【YOLOv8改进-注意力机制】CoordAttention: 用于移动端的高效坐标注意力机制 | https://blog.csdn.net/shangyanaf/article/details/136824282 |
| 15 | 【YOLOv8改进-注意力机制】BRA(bi-level routing attention ):双层路由注意力 | https://blog.csdn.net/shangyanaf/article/details/139307690 |
| 16 | 【YOLOv8改进 -注意力机制】SGE(Spatial Group-wise Enhance):轻量级空间分组增强模块 | https://blog.csdn.net/shangyanaf/article/details/140565720 |
| 17 | 【YOLOv8改进 -注意力机制】Mamba之MLLAttention :基于Mamba和线性注意力Transformer的模型 | https://blog.csdn.net/shangyanaf/article/details/140406244 |
| 18 | 【YOLOv8改进 - 注意力机制】Triplet Attention:轻量有效的三元注意力 | https://blog.csdn.net/shangyanaf/article/details/139999693 |
| 19 | 【YOLOv8改进 - 注意力机制】SKAttention:聚合分支信息,实现自适应调整感受野大小 | https://blog.csdn.net/shangyanaf/article/details/140078451 |
| 20 | 【YOLOv8改进 - 注意力机制】SimAM:轻量级注意力机制,解锁卷积神经网络新潜力 | https://blog.csdn.net/shangyanaf/article/details/140083301 |
| 21 | 【YOLOv8改进 - 注意力机制】SENetV2: 用于通道和全局表示的聚合稠密层,结合SE模块和密集层来增强特征表示 | https://blog.csdn.net/shangyanaf/article/details/139610187 |
| 22 | 【YOLOv8改进 - 注意力机制】Sea_Attention: Squeeze-enhanced Axial Attention,结合全局语义提取和局部细节增强 | https://blog.csdn.net/shangyanaf/article/details/139652325 |
| 23 | 【YOLOv8改进 - 注意力机制】S2Attention : 整合空间位移和分割注意力 | https://blog.csdn.net/shangyanaf/article/details/140472196 |
| 24 | 【YOLOv8改进 - 注意力机制】RCS-OSA :减少通道的空间对象注意力,高效且涨点 | https://blog.csdn.net/shangyanaf/article/details/140457853 |
| 25 | 【YOLOv8改进 - 注意力机制】NAM:基于归一化的注意力模块,将权重稀疏惩罚应用于注意力机制中,提高效率性能 | https://blog.csdn.net/shangyanaf/article/details/140083725 |
| 26 | 【YOLOv8改进 - 注意力机制】LS-YOLO MSFE:新颖的多尺度特征提取模块 | 小目标/遥感 | https://blog.csdn.net/shangyanaf/article/details/140092794 |
| 27 | 【YOLOv8改进 - 注意力机制】HCF-Net 之 PPA:并行化注意力设计 | 小目标 | https://blog.csdn.net/shangyanaf/article/details/140111479 |
| 28 | 【YOLOv8改进 - 注意力机制】HCF-Net 之 MDCR:多稀释通道细化器模块 ,以不同的稀释率捕捉各种感受野大小的空间特征 | 小目标 | https://blog.csdn.net/shangyanaf/article/details/140104977 |
| 29 | 【YOLOv8改进 - 注意力机制】HCF-Net 之 DASI: 维度感知选择性整合模块 | 小目标 | https://blog.csdn.net/shangyanaf/article/details/140117642 |
| 30 | 【YOLOv8改进 - 注意力机制】GC Block (GlobalContext): 全局上下文块,高效捕获特征图中的全局依赖关系 | https://blog.csdn.net/shangyanaf/article/details/140528152 |
| 31 | 【YOLOv8改进 - 注意力机制】Gather-Excite Attention: 提高了网络捕获长距离特征交互的能力 | https://blog.csdn.net/shangyanaf/article/details/140637601 |
| 32 | 【YOLOv8改进 - 注意力机制】GAM(Global Attention Mechanism):全局注意力机制,减少信息损失并放大全局维度交互特征 | https://blog.csdn.net/shangyanaf/article/details/140336852 |
| 33 | 【YOLOv8改进 - 注意力机制】Focused Linear Attention :全新的聚焦线性注意力模块 | https://blog.csdn.net/shangyanaf/article/details/140457255 |
| 34 | 【YOLOv8改进 - 注意力机制】EffectiveSE : 改进的通道注意力模块,减少计算复杂性和信息丢失 | https://blog.csdn.net/shangyanaf/article/details/140635865 |
| 35 | 【YOLOv8改进 - 注意力机制】ECA(Efficient Channel Attention):高效通道注意 模块,降低参数量 | https://blog.csdn.net/shangyanaf/article/details/140336733 |
| 36 | 【YOLOv8改进 - 注意力机制】DoubleAttention: 双重注意力机制,全局特征聚合和分配 | https://blog.csdn.net/shangyanaf/article/details/140478959 |
| 37 | 【YOLOv8改进 - 注意力机制】ContextAggregation : 上下文聚合模块,捕捉局部和全局上下文,增强特征表示 | https://blog.csdn.net/shangyanaf/article/details/140664662 |
| 38 | 【YOLOv8改进 - 注意力机制】c2f结合CBAM:针对卷积神经网络(CNN)设计的新型注意力机制 | https://blog.csdn.net/shangyanaf/article/details/139950898 |
| 39 | 【YOLOv8改进 - 注意力机制】 MHSA:多头自注意力(Multi-Head Self-Attention) | https://blog.csdn.net/shangyanaf/article/details/140110995 |
| 40 | 【YOLOv8改进 - 注意力机制】 CascadedGroupAttention:级联组注意力,增强视觉Transformer中多头自注意力机制的效率和有效性 | https://blog.csdn.net/shangyanaf/article/details/140138885 |
| 41 | 【YOLOv8改进 - 注意力机制】 Agent Attention :代理注意力, softmax注意力与线性注意力的优雅融合 | https://blog.csdn.net/shangyanaf/article/details/140921422 |
| 42 | 【YOLOv8改进 - 注意力机制】 CAA: 上下文锚点注意力模块,处理尺度变化大或长形目标 | https://blog.csdn.net/shangyanaf/article/details/141121752 |
| 43 | 【YOLOv8改进 - 注意力机制】MSCA: 多尺度卷积注意力,即插即用,助力小目标检测 | https://blog.csdn.net/shangyanaf/article/details/136057088 |
| 44 | 【YOLOv8改进 - 注意力机制】MCA:用于图像识别的深度卷积神经网络中的多维协作注意力 (论文笔记+引入代码) | https://blog.csdn.net/shangyanaf/article/details/136205065 |
| 45 | 【YOLOv8改进 - 注意力机制】 MSDA:多尺度空洞注意力 (论文笔记+引入代码) | https://blog.csdn.net/shangyanaf/article/details/136215149 |
| 46 | 【YOLOv8改进 - 注意力机制】HaloNet通过局部自注意力机制(Local Self-Attention)来捕捉空间交互 | https://blog.csdn.net/shangyanaf/article/details/145801601 |
| 47 | 【YOLOv8改进 - 注意力机制】Axial Attention:轴向注意力,提高计算效率和内存使用 | https://blog.csdn.net/shangyanaf/article/details/145839350 |
| 48 | 【YOLOv8改进 - 注意力机制】 SCSA通过结合空间注意力和通道注意力,提高各种下游视觉任务的性能。 | https://blog.csdn.net/shangyanaf/article/details/145864131 |
| 49 | 【YOLOv8改进 - 注意力机制】SOCA:可训练的二阶通道注意力,自适应地重新缩放通道特征,以获得更具辨别性的表示 | https://blog.csdn.net/shangyanaf/article/details/145914187 |
| 50 | 【YOLOv8改进 - 注意力机制】CGAFusion(Content-Guided Attention): 内容引导注意力特征融合 | https://blog.csdn.net/shangyanaf/article/details/145999917 |
| 51 | 【YOLOv8改进 - 注意力机制】GCT(Gaussian Context Transformer):高斯上下文变换器 | https://blog.csdn.net/shangyanaf/article/details/146000370 |
| 52 | 【YOLOv8改进 - 注意力机制】ELA(Efficient Local Attention):深度卷积神经网络的高效局部注意力机制 | https://blog.csdn.net/shangyanaf/article/details/146000582 |
| 53 | 【YOLOv8改进 - 注意力机制】 ParNet :并行子网络结构实现低深度但高性能的神经网络架构 | https://blog.csdn.net/shangyanaf/article/details/146027243/ |
| 54 | 【YOLOv8改进 - 注意力机制】TripletAttention:轻量有效的三元注意力 | https://blog.csdn.net/shangyanaf/article/details/146027039 |
卷积-Conv
主干- Backbone
| 序号 | 标题 | 链接 |
|---|---|---|
| 1 | 【YOLOv8改进】MobileViT 更换主干网络: 轻量级、通用且适合移动设备的视觉变压器 | https://blog.csdn.net/shangyanaf/article/details/136962297 |
| 2 | 【YOLOv8改进】MobileNetV3替换Backbone (论文笔记+引入代码) | https://blog.csdn.net/shangyanaf/article/details/136891204 |
| 3 | 【YOLOv8改进】骨干网络: SwinTransformer (基于位移窗口的层次化视觉变换器)(论文笔记+引入代码) | https://blog.csdn.net/shangyanaf/article/details/135867187 |
| 4 | 【YOLOv8改进】 YOLOv8 更换骨干网络之GhostNetV2 长距离注意力机制增强廉价操作,构建更强端侧轻量型骨干 (论文笔记+引入代码) | https://blog.csdn.net/shangyanaf/article/details/136170972 |
| 5 | 【YOLOv8改进】 YOLOv8 更换骨干网络之 GhostNet :通过低成本操作获得更多特征 (论文笔记+引入代码).md | https://blog.csdn.net/shangyanaf/article/details/136151800 |
| 6 | 【YOLOv8改进- Backbone主干】YOLOv8更换主干网络之ConvNexts,纯卷积神经网络,更快更准,,降低参数量! | https://blog.csdn.net/shangyanaf/article/details/140451741 |
| 7 | 【YOLOv8改进- Backbone主干】YOLOv8 更换主干网络之EfficientNet,高效的卷积神经网络,降低参数量 | https://blog.csdn.net/shangyanaf/article/details/140451442 |
| 8 | 【YOLOv8改进- Backbone主干】YOLOv8 更换主干网络之 PP-LCNet,轻量级CPU卷积神经网络,降低参数量 | https://blog.csdn.net/shangyanaf/article/details/140450841 |
| 9 | 【YOLOv8改进- Backbone主干】2024最新轻量化网络MobileNetV4替换YoloV8的BackBone | https://blog.csdn.net/shangyanaf/article/details/140364353 |
| 10 | 【YOLOv8改进 - Backbone主干】VanillaNet:极简的神经网络,利用VanillaNet替换YOLOV8主干 | https://blog.csdn.net/shangyanaf/article/details/139665923 |
| 11 | 【YOLOv8改进 - Backbone主干】VanillaNet:极简的神经网络,利用VanillaBlock降低YOLOV8参数 | https://blog.csdn.net/shangyanaf/article/details/139664922 |
| 12 | 【YOLOv8改进 - Backbone主干】ShuffleNet V2:卷积神经网络(CNN)架构 | https://blog.csdn.net/shangyanaf/article/details/139655578 |
| 13 | 【YOLOv8改进 - Backbone主干】FasterNet:基于PConv(部分卷积)的神经网络,提升精度与速度,降低参数量。 | https://blog.csdn.net/shangyanaf/article/details/139639091 |
| 14 | 【YOLOv8改进 - Backbone主干】清华大学CloFormer AttnConv :利用共享权重和上下文感知权重增强局部感知,注意力机制与卷积的完美融合 | https://blog.csdn.net/shangyanaf/article/details/139824105 |
| 15 | 【YOLOv8改进 - Backbone主干】EfficientRep:一种旨在提高硬件效率的RepVGG风格卷积神经网络架构 | https://blog.csdn.net/shangyanaf/article/details/139558834 |
| 16 | 【YOLOv10改进- Backbone主干】BiFormer: 通过双向路由注意力构建高效金字塔网络架构 | 小目标 | |
| 17 | 【YOLOv8改进- Backbone主干】BoTNet:基于Transformer,结合自注意力机制和卷积神经网络的骨干网络 | https://blog.csdn.net/shangyanaf/article/details/140653663 |
特征融合
| 序号 | 标题 | 链接 |
|---|---|---|
| 1 | 【YOLOv8改进 - 特征融合NECK】Slim-neck:目标检测新范式,既轻量又涨点 | https://blog.csdn.net/shangyanaf/article/details/139878671 |
| 2 | 【YOLOv8改进 - 特征融合NECK】SDI:多层次特征融合模块,替换contact操作 | https://blog.csdn.net/shangyanaf/article/details/140498153 |
| 3 | 【YOLOv8改进 - 特征融合NECK】ASF-YOLO:SSFF融合+TPE编码+CPAM注意力,提高检测和分割能力 | https://blog.csdn.net/shangyanaf/article/details/140042501 |
| 4 | 【YOLOv8改进 - 特征融合NECK】 HS-FPN :用于处理多尺度特征融合的网络结构,降低参数 | https://blog.csdn.net/shangyanaf/article/details/139877859 |
| 5 | 【YOLOv8改进 - 特征融合NECK】 GIRAFFEDET之GFPN :广义特征金字塔网络,高效地融合多尺度特征 | https://blog.csdn.net/shangyanaf/article/details/140459446 |
| 6 | 【YOLOv8改进 - 特征融合NECK】 DAMO-YOLO之RepGFPN :实时目标检测的创新型特征金字塔网络 | https://blog.csdn.net/shangyanaf/article/details/139863259 |
| 7 | 【YOLOv8改进】EVC(Explicit Visual Center): 中心化特征金字塔模块(论文笔记+引入代码) | https://blog.csdn.net/shangyanaf/article/details/137645622 |
| 8 | 【YOLOv8改进 - 特征融合NECK】CARAFE:轻量级新型上采样算子,助力细节提升 | https://blog.csdn.net/shangyanaf/article/details/139886624 |
| 9 | 【YOLOv8改进 - 特征融合】DySample :超轻量级且高效的动态上采样器 | https://blog.csdn.net/shangyanaf/article/details/139990001 |
| 10 | 【YOLOv8改进 - 特征融合NECK】BiFPN:加权双向特征金字塔网络 (论文笔记+引入代码) | https://blog.csdn.net/shangyanaf/article/details/136021981 |
| 11 | 【YOLOv8改进 - 特征融合NECK】 AFPN :渐进特征金字塔网络 (论文笔记+引入代码).md | https://blog.csdn.net/shangyanaf/article/details/136025499 |
| 12 | 【YOLOv8改进 - 特征融合】FFCA-YOLO: 提升遥感图像中小目标检测的精度和鲁棒性 | https://blog.csdn.net/shangyanaf/article/details/140621023 |
| 13 | 【YOLOv8改进 - 特征融合】 YOGA iAFF :注意力机制在颈部的多尺度特征融合 | https://blog.csdn.net/shangyanaf/article/details/139826529 |
| 14 | 【YOLOv8改进 - 特征融合】 GELAN:YOLOV9 通用高效层聚合网络,高效且涨点 | https://blog.csdn.net/shangyanaf/article/details/140460307 |
损失函数
| 序号 | 标题 | 链接 |
|---|---|---|
| 1 | 【YOLOv8改进】Shape-IoU:考虑边框形状与尺度的指标(论文笔记+引入代码) | https://blog.csdn.net/shangyanaf/article/details/135927712 |
| 2 | 【YOLOv8改进】MPDIoU:有效和准确的边界框损失回归函数 (论文笔记+引入代码) | https://blog.csdn.net/shangyanaf/article/details/135948703 |
| 3 | 【YOLOv8改进】Inner-IoU: 基于辅助边框的IoU损失(论文笔记+引入代码) | https://blog.csdn.net/shangyanaf/article/details/135904930 |
| 4 | 【YOLOv8改进-损失函数】YOLOv8 更换损失函数之 SIoU EIoU WIoU _ Focal_*IoU CIoU DIoU ShapeIoU MPDIou | https://blog.csdn.net/shangyanaf/article/details/139512620 |
| 5 | 【YOLOv8改进-损失函数】SlideLoss损失函数,解决样本不平衡问题 | https://blog.csdn.net/shangyanaf/article/details/139483941 |
| 6 | 【YOLOv8改进-损失函数】 YOLOv8自带损失函数CIoU / DIoU / GIoU 详解,以及如何切换损失函数 | https://blog.csdn.net/shangyanaf/article/details/139509783 |
| 7 | 【YOLOv8改进- 损失函数】 NWD(Normalized Wasserstein Distance:归一化 Wasserstein 距离),助力微小目标检测。 | https://blog.csdn.net/shangyanaf/article/details/141729325 |
| 8 | 【YOLOv8改进-损失函数】PIoU(Powerful-IoU):使用非单调聚焦机制更直接、更快的边界框回归损失 | |
多模块融合改进
| 序号 | 标题 | 链接 |
|---|---|---|
| 1 | 【YOLOv8改进- 多模块融合改进】RFAConv+ TripletAttention: 基于感受野注意力卷积与三元注意力的四头小目标检测头,,提高特证提取的效率以及准确率。 | https://blog.csdn.net/shangyanaf/article/details/141125292 |
| 2 | 【YOLOv8改进- 多模块融合改进】ResBlock + GAM: 基于ResBlock的全局注意力机制ResBlock_ GAM,增强特证提取 | https://blog.csdn.net/shangyanaf/article/details/141136299 |
| 3 | 【YOLOv8改进- 多模块融合改进】ResBlock + CBAM: 基于ResBlock的通道+空间注意力,增强特证提取 | https://blog.csdn.net/shangyanaf/article/details/141135233 |
| 4 | 【YOLOv8改进- 多模块融合改进】Non-Local+ LSKNet : 自注意力模型与空间选择注意力的融合改进,助力小目标检测高效涨点 | https://blog.csdn.net/shangyanaf/article/details/141067397 |
| 5 | 【YOLOv8改进- 多模块融合改进】GhostConv + ContextAggregation 幽灵卷积与上下文聚合模块融合改进,助力小目标高效涨点 | https://blog.csdn.net/shangyanaf/article/details/140665117 |
| 6 | 【YOLOv8改进- 多模块融合改进】CPCA + CARAFE : 通道先验卷积注意力与上采样算子的融合改进,助力细节提升! | https://blog.csdn.net/shangyanaf/article/details/141065415 |
| 7 | 【YOLOv8改进- 多模块融合改进】BoTNet + EMA 骨干网络与多尺度注意力的融合改进,小目标高效涨点 | https://blog.csdn.net/shangyanaf/article/details/140654746 |
| 8 | 【YOLOv8改进- 多模块融合改进】BoTNet + CoordAttention 骨干网络与高效坐标注意力机制融合改进,助力小目标高效涨点 | https://blog.csdn.net/shangyanaf/article/details/140675321 |
| 9 | 【YOLOv8改进- 多模块融合改进】发论文神器SPPF_LSKA,结合各种创新改进,以融合SimAM注意力机制为例! | https://blog.csdn.net/shangyanaf/article/details/140691622 |
C2f融合改进
| 序号 | 标题 | 链接 |
|---|---|---|
| 1 | 【YOLOv8改进 - C2f融合】C2f融合MLCA(Mixed local channel attention):混合局部通道注意力 | https://blog.csdn.net/shangyanaf/article/details/146115789 |
| 2 | 【YOLOv8改进 - C2f融合】C2f融合iRMB: 倒置残差移动块,即插即用的轻量注意力 | https://blog.csdn.net/shangyanaf/article/details/146123278 |
| 3 | 【YOLOv8改进 - C2f融合】C2f融合deformable_LKA_Attention:可变形大核注意力 | https://blog.csdn.net/shangyanaf/article/details/139212227 |
| 4 | 【YOLOv8改进 - C2f融合】C2f融合CoTAttention_上下文转换器注意力,增强视觉表示并提高计算机视觉任务的性能 | https://blog.csdn.net/shangyanaf/article/details/146243249 |
| 5 | 【YOLOv8改进 - C2f融合】C2f融合DWRSeg二次创新C2f_DWR:扩张式残差分割网络,提高特征提取效率和多尺度信息获取能力,助力小目标检测 | https://blog.csdn.net/shangyanaf/article/details/146286798 |
| 6 | 【YOLOv8改进 - C2f融合】C2f融合DWRSeg二次创新C2f_DWRSeg:扩张式残差分割网络,提高特征提取效率和多尺度信息获取能力,助力小目标检测 | https://blog.csdn.net/shangyanaf/article/details/140336972 |
| 7 | 【YOLOv8改进 - C2f融合】C2f融合SCConv :即插即用的空间和通道重建卷积 | https://blog.csdn.net/shangyanaf/article/details/146408427 |
SPPF改进
| 序号 | 标题 | 链接 |
|---|---|---|
| 1 | 【YOLOv8改进-SPPF】 Focal Modulation :使用焦点调制模块替代SPPF | https://blog.csdn.net/shangyanaf/article/details/140456375 |
| 2 | 【YOLOv8改进-SPPF】 AIFI : 基于注意力的尺度内特征交互,保持高准确度的同时减少计算成本 | https://blog.csdn.net/shangyanaf/article/details/140500654 |
| 3 | 【YOLOv8改进 - SPPF】发论文神器!LSKA注意力改进SPPF,增强多尺度特征提取能力,高效涨点!!! | https://blog.csdn.net/shangyanaf/article/details/140685113 |


















 2069
2069

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











