






作者 | 鱼肖浓 编辑 | 汽车人
原文链接:https://zhuanlan.zhihu.com/p/587010197
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【SLAM】技术交流群
后台回复【SLAM综述】获取视觉SLAM、激光SLAM、RGBD-SLAM等多篇综述!
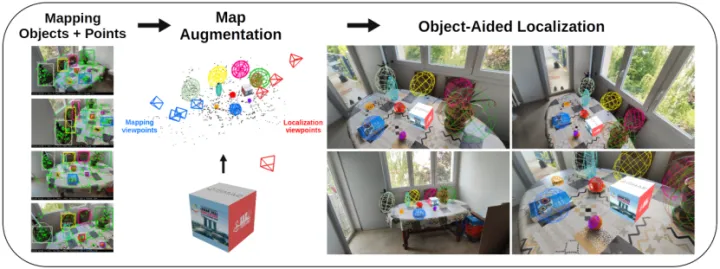
Motivations:
用粗略模型(长方体或椭球体)表示的对象可能不够精确,无法改善相机的位姿跟踪。
目前SOTA目标检测器对视角和光照变化具有很强的鲁棒性,这对于从大量不同视角恢复相机姿态非常有利。
缺乏用于构建面向对象地图的全自动系统,都有着一定的假设。
Contributions:
结合对象和点的优点,提出了一种改进的重定位方法,能够从大量不同的视角中估计相机位姿。
提出了一种全自动的SLAM系统,能够在飞行中识别、跟踪和重建对象。
Background and Related Works:
1. 对象建图
Crocco使用简化相机模型,提出了一种封闭形式的公式来估计来自多视图目标检测的对偶二次曲面。Rubino将其拓展到针孔相机模型。Chen等人解决了前向移动中初始化对象估计问题。
2. 基于对象的定位
Weinzaepfel等人利用查询图像中出现的对象与参考图像中出现的对象之间的稠密2D-3D对应关系来计算相机的位姿,但该方法仅限于平面对象。
一些工作使用了更通用的对象,用椭球表示。然而这些方法仅从对象估计相机姿态,并假设一个预构建的对象地图。[11]只估计相机的位置,假设方向已知。[38]专注于3D感知椭圆对象检测。
3. 基于对象的SLAM
Bao等人在定位和建图中引入了对象,在一个SfM框架中识别和定位对象。McCormac等人和Sünderhauf等人将RGB-D SLAM和语义分割和对象检测相融合,获得具有语义注释的稠密点云。
QuadricSLAM使用对偶二次曲面作为3D地标,共同估计相机位姿和对偶二次曲面参数。EAO-SLAM在半稠密的SLAM中集成对象,利用不同的统计信息来提高数据关联的鲁棒性。Hosseinzadeh将点、平面和二次曲面联合为基于因子图的SLAM。SO-SLAM中,Liao等人使用手工提取的平面为对象添加支撑约束,以及语义尺度先验和对象约束。ROSHAN利用边界框检测、图像纹理、语义知识和对象形状先验来推断椭球模型,并解决前向平移车辆运动下的可观察性问题。CubeSLAM使用长方体来表示对象,使用2D边界框和消失点采样从单图中生成对象候选。Frost等人用球体建模对象,并使用它们解决SLAM中的尺度不确定和漂移问题。
4. 基于对象的SLAM重定位
只有Dudek等人利用SLAM中的语义地图进行重定位。Mahattansin等人利用对象检测改进了视觉SLAM的重定位,但对象检测知识用来更好地筛选候选关键帧,相机位姿仍使用与最相似的关键帧的点匹配估计得到。
Methodology:
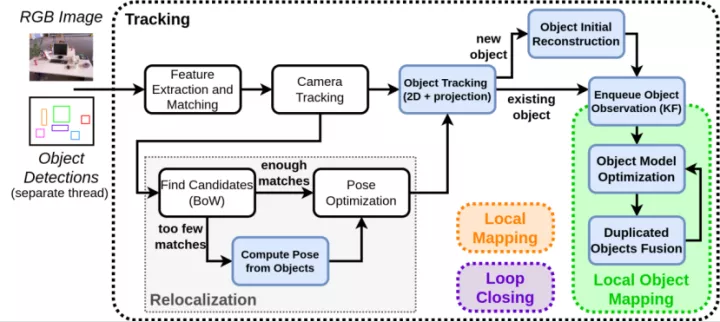
1. 椭球体对象表示
9DoF表示,3DoF表示轴长,3DoF表示方向,3DoF表示位置。其方程可以用对偶空间的封闭形式表示。椭球体定义为4×4矩阵Q*,椭圆定义为3×3矩阵C*。
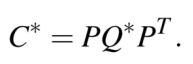
2. 目标检测与关联
目标检测器:YOLO (只考虑评分高于0.5的检测)
2.1 基于box的对象追踪
在重建之前,基于边界框重叠和标签一致性在2D帧中跟踪对象在两帧之间的运动相对较小和平滑时短期有效。
考虑3D重建来获得长期的跟踪,将其椭球模型投影到当前帧中,并利用该帧中与目标检测的重叠来寻找关联。
结合以上两种情况,使用匈牙利算法找到最优关联,该最大化匹配总分,以便在N次检测和M个对象之间找到最佳的可能分配。
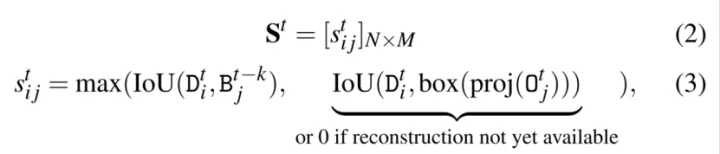
2.2 基于点的对象追踪
在相机位姿估计过程中,将图像关键点与地图地标进行鲁棒匹配,这些匹配可以用于链接检测框和对象椭球:
1)在图像中,如果一个关键点位于边界框内,它就与一个检测相链接
2)在地图中,如果一个点地标位于椭球体内,则与该对象相链接
如果检测和地图对象之间至少存在τ个基于点的匹配,则关联。
3. 初始对象重建
当通过相机中心的光线与对象检测中心的光线之间的角度变化为10°以上时,创建其3D椭球的初始估计。为了尽快地获得对象的3D估计,对象最初被重建为球体,然后随着视角的增加,细化为椭球体的形式。
球体的位置是从边界框的中心进行三角测量,半径被确定为边界框的平均大小。
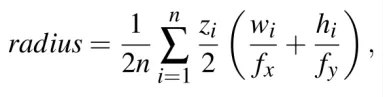
其中,为在第i个相机坐标系中的对象中心z坐标,和为第i帧检测框的宽度和高度,和为相机内参,n为对象被追踪到的帧数。
然后将该球体细化为椭球体,更新其轴长和位姿,以最小化重投影误差的形式进行改进。当经过足够帧数(通常为40帧)重构和细化对象,3D IoU超过阈值时,将对象集成到地图中。
4. 局部对象建图
4.1 对象优化
与ORB-SLAM2的局部束调节类似,对象模型也会定期进行优化,每当一个新的关键帧观察到地图中存在的对象时,就会通过最小化重投影误差来优化对象。
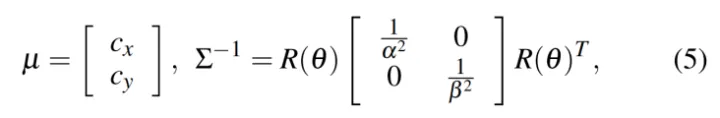
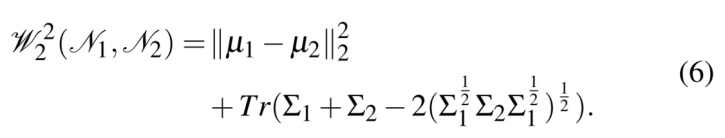
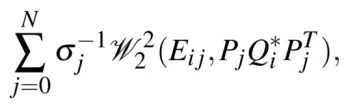
其中,为第j次检测框的内切椭圆, 为第i个对象的对偶矩阵,为第j个关键帧的投影矩阵,为第j个关键帧的目标检测评分,N为对象观测数量。
4.2 对象合并
系统定期检查重复的对象,如果它们的3D IoU超过0.2,并且一个椭球体的中心位于另一个椭球体的内部或者共享超过 个3D点,则合并这两个对象。
对关键帧中的两个对象跟踪的检测框进行组合,并初始化一个新的椭球。
5. 使用对象重定位
当重构地图上的点与关键帧显著不同时,基于BoW的方法经常失败。因此采用基于对象的方法增强重定位,对视角改变更加鲁棒。
由于PnP计算出的位姿比从对象对应关系中得到的位姿更准确,主要思想是引导点与从对象对应关系中计算出的姿态进行匹配。然后采用点对应关系使用PnP进行定位。
基于对象的方法:根据椭圆-椭球的类别建立了椭圆-椭球对,每次迭代至少选择三对组合,在中心使用P3P算法计算相机位姿。对于P3P解出的四种解,椭球体被投影并且基于重叠关联检测,代价计算为每个关联对的(1-IoU)之和,选择四种解中代价最小的相机位姿。
然后将基于对象方法得到的位姿通过ORB-SLAM2的局部匹配步骤来识别关键点-地标对应关系,选择最小代价且超过30个关键点-地标匹配的位姿,在点上进行优化。
Experiments:
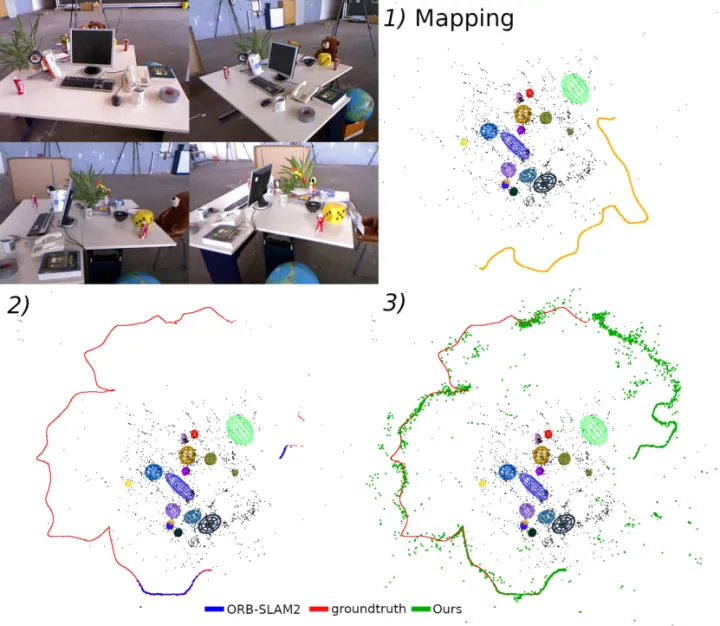
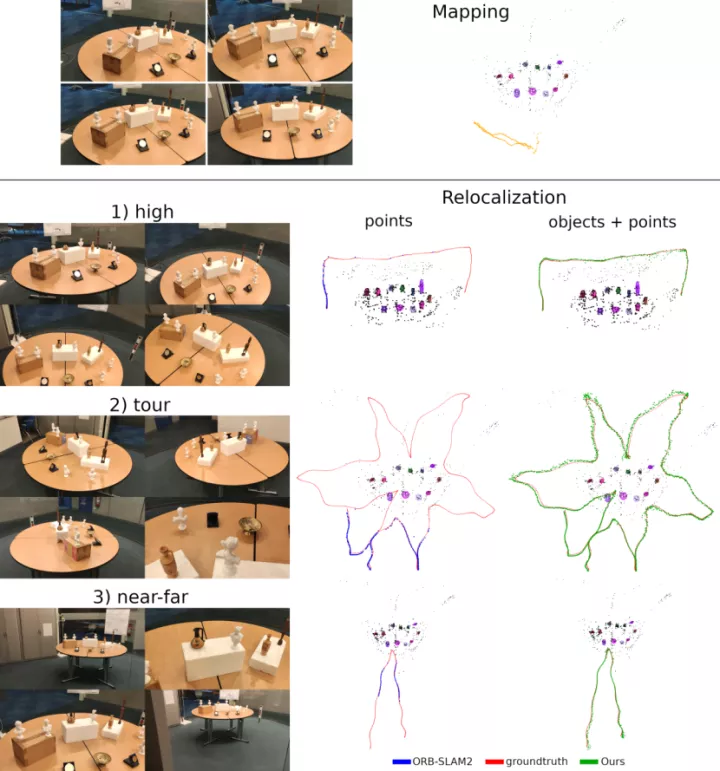
1. 对象建图


与EAO-SLAM的对比

2. 对象vs点
2.1 重定位
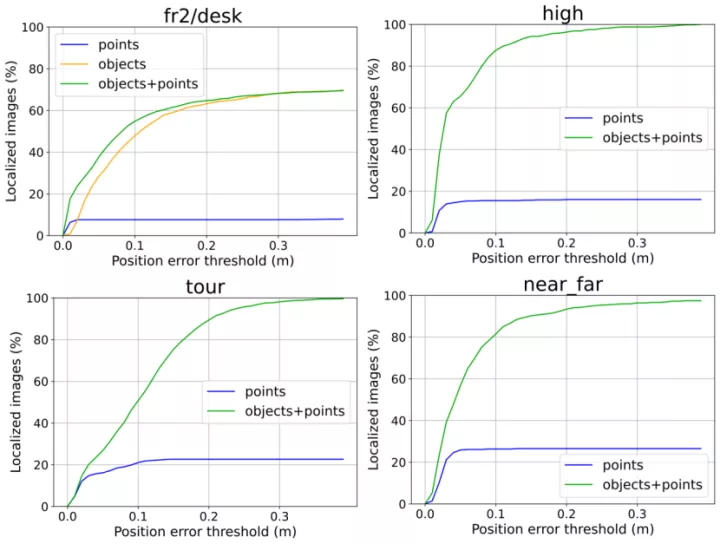
2.2 在束调整中集成对象
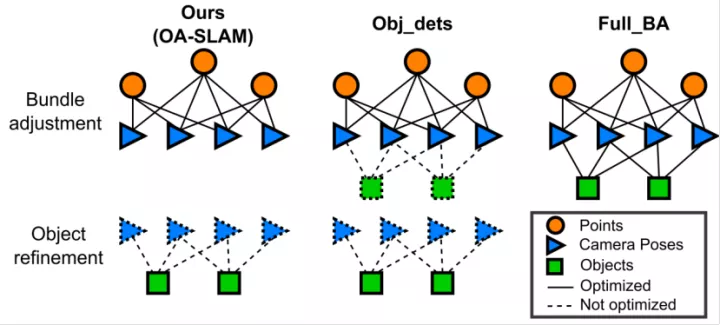
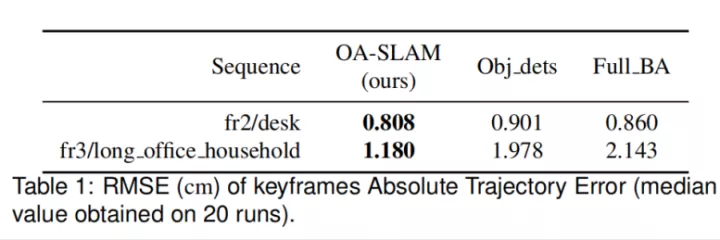
3. AR应用
3.1 重新初始化3D追踪

3.2 SLAM恢复
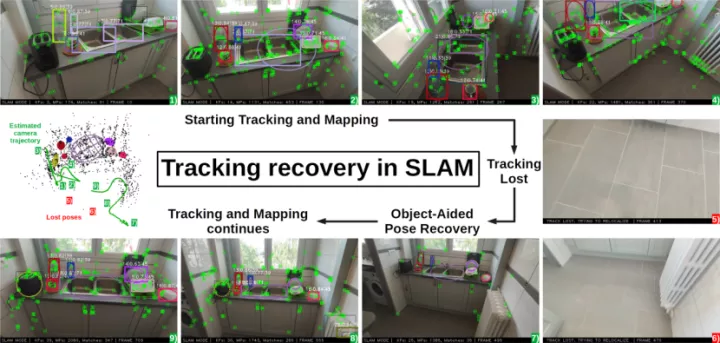
1-4)在3D中跟踪相机,并建立点和对象的地图
5-6)由于相机的突然运动,跟踪丢失了
7-9)当重构的场景再次可见时,重定位模块从对象中估计相机姿态,建立点匹配,并使跟踪和建图继续进行。
4. 按部分建模

相机重定位需要足够数量的对象(3),当相机靠近时,可能只有一到两个对象可见。解决方法:微调检测器网络,以检测对象的可区分部分。
近距离情况下,雕像的部分(头、肩膀和底部)被用于重新定位,当远距离情况下,只使用完整的对象检测。
Discussion and Future work:
考虑将基于对象的推理与静态/动态识别相结合。
往期回顾
视觉和Lidar里程计SOTA方法一览!(Camera/激光雷达/多模态)

【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、规划控制、模型部署落地、自动驾驶仿真测试、硬件配置、AI求职交流等方向;

添加汽车人助理微信邀请入群
备注:学校/公司+方向+昵称
自动驾驶之心【知识星球】
想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球(三天内无条件退款),日常分享论文+代码,这里汇聚行业和学术界大佬,前沿技术方向尽在掌握中,期待交流!
















 382
382











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









