






作者 | eyesighting 编辑 | 汽车人
原文链接:https://zhuanlan.zhihu.com/p/639306111
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【多传感器融合】技术交流群
题目:K-Radar: 4D Radar Object Detection for Autonomous Driving in Various Weather Conditions
名称:K-Radar:用于各种天气条件下自动驾驶的 4D 雷达目标检测
论文:https://arxiv.org/abs/2206.08171
代码:https://github.com/kaist-avelab/k-radar
0.摘要
不同于使用可见光波段的 RGB 相机(384~769 THz)和使用红外波段的激光雷达(361~331 THz),雷达使用相对较长波长的无线电波段(77~81 GHz),从而在恶劣天气下进行稳健的测量。不幸的是,与现有的相机和激光雷达数据集相比,现有的雷达数据集仅包含相对较少数量的样本。这可能会阻碍基于雷达感知的复杂数据驱动深度学习技术的发展。此外,大多数现有雷达数据集仅提供 3D 雷达张量 (3DRT) 数据,其中包含沿多普勒、距离和方位角维度的功率测量。由于没有高程信息,因此很难从 3DRT 估计对象的 3D 边界框。
在这项工作中,我们介绍了 KAIST-Radar (K-Radar),这是一种新型的大型物体检测数据集和基准,包含 35K 帧的 4D 雷达张量 (4DRT) 数据,以及沿着多普勒、距离、方位角和仰角的功率测量方面,连同仔细注释的道路上物体的 3D 边界框标签。K-Radar 包括具有挑战性的驾驶条件,例如各种道路结构(城市、郊区道路、小巷和高速公路)上的恶劣天气(雾、雨和雪)。除了 4DRT 之外,我们还提供来自经过仔细校准的高分辨率激光雷达、环绕立体相机和 RTK-GPS 的辅助测量。我们还提供基于 4DRT 的对象检测基线神经网络(基线 NN),并表明高度信息对于 3D 对象检测至关重要。通过将基线 NN 与结构相似的基于激光雷达的神经网络进行比较,我们证明 4D 雷达是一种更强大的传感器,可以应对恶劣的天气条件。
1.介绍
自动驾驶系统通常由感知、规划和控制的顺序模块组成。由于规划和控制模块依赖于感知模块的输出,因此即使在不利的驾驶条件下,感知模块的鲁棒性也是至关重要的。最近,各种工作提出了基于深度学习的自动驾驶感知模块,这些模块在车道检测(Paek et al.,2022;刘等人,2021)、物体检测(Wang et al.,2021a;Lang et al.,2019;Major等人,2019)和其他任务(Ranftl et al.,2021;Teed和Deng,2021)中表现出显著的性能。这些工作通常使用RGB图像作为神经网络的输入,因为有许多公共的大规模数据集可用于基于相机的感知。此外,RGB图像具有相对简单的数据结构,其中数据维度相对较低,并且相邻像素通常具有高相关性。这种简单性使深度神经网络能够学习图像的底层表示并识别图像上的对象。
不幸的是,相机容易受到较差的照明,很容易被雨滴和雪花遮挡,并且无法保存深度信息,这对于准确理解环境的3D场景至关重要。另一方面,激光雷达在红外光谱中主动发射测量信号,因此测量几乎不受照明条件的影响。激光雷达还可以提供厘米分辨率内的精确深度测量。然而,激光雷达测量仍然受到不利天气的影响,因为信号的波长(850nm-1550nm)不足以穿过雨滴或雪花(Kurup和Bos,2021)。
与激光雷达类似,雷达传感器主动发射波并测量反射。然而,雷达发射的无线电波(4毫米)可以穿过雨滴和雪花。因此,雷达测量对较差的照明和不利的天气条件都是稳健的。这种鲁棒性在(Abdu et al.,2021)中得到了证明,其中基于调频连续波(FMCW)雷达的感知模块被证明即使在恶劣的天气条件下也是准确的,并且可以很容易地直接在硬件上实现。随着具有密集雷达张量(RT)输出的FMCW雷达变得容易获得,许多工作(Dong等人,2020;Mostajabi等人,2020年;Sheeny等人,2021)提出了具有与基于相机和激光雷达的目标检测网络相当的检测性能的基于RT的目标检测网。然而,这些工作仅限于2D鸟瞰(BEV)对象检测,因为现有工作中使用的FMCW雷达仅提供具有沿多普勒、距离和方位维度的功率测量的3D雷达张量(3DRT)。
在这项工作中,我们介绍了KAIST雷达(K-Radar),一种新的基于4D雷达张量(4DRT)的三维目标检测数据集和基准。与传统的3DRT不同,4DRT包含沿着多普勒、距离、方位角和仰角维度的功率测量,从而可以保留3D空间信息,这可以实现精确的3D感知,例如使用激光雷达的3D对象检测。据我们所知,K-Radar是第一个基于4DRT的大规模数据集和基准,从各种道路结构(如城市、郊区、高速公路)、时间(如白天、晚上)和天气条件(如晴朗、雾、雨、雪)收集了35k帧。除了4DRT,K-Radar还提供高分辨率激光雷达点云(LPC)、四个立体相机的环绕RGB图像以及ego车辆的RTK-GPS和IMU数据。
由于4DRT高维表示对人类来说是不直观的,我们利用了高分辨率LPC,以便注释器可以在可视化的点云中准确地标记道路上物体的3D边界框。3D边界框可以很容易地从激光雷达转换到雷达坐标系,因为我们分别提供了空间和时间校准参数来校正由于传感器和异步测量的分离而产生的偏移。K-Radar还为每个注释对象提供了唯一的跟踪ID,这对于沿着帧序列跟踪对象很有用。有关跟踪的信息示例如附录I.7所示。
为了证明基于4DRT的感知模块的必要性,我们提出了一种直接消耗4DRT作为输入的3D对象检测基线神经网络(baseline NN)。从K-Radar的实验结果中,我们观察到,基于4DRT的基线神经网络在三维目标检测任务中,尤其是在恶劣天气条件下,优于基于激光雷达的网络。我们还表明,利用高度信息的基于4DRT的基线神经网络显著优于仅利用BEV信息的网络。此外,我们还发布了完整的开发工具包(devkit),其中包括:(1) 用于基于4DRT的神经网络的训练/评估代码,(2) 标记/校准工具,以及(3)加速基于4DRT的感知领域研究的可视化工具。
总之,我们的贡献如下:我们提出了一种新的基于4DRT的数据集和基准K-Radar,用于3D目标检测。据我们所知,K-Radar是第一个基于4DRT的大规模数据集和基准,具有多样且具有挑战性的照明、时间和天气条件。凭借精心标注的3D边界框标签和多模式传感器,K-Radar还可以用于其他自动驾驶任务,如物体跟踪和里程计。我们提出了一种直接使用4DRT作为输入的3D对象检测基线NN,并验证了4DRT的高度信息对于3D对象检测是必不可少的。我们还证明了基于4DRT的感知对自动驾驶的稳健性,尤其是在恶劣天气条件下。我们提供的开发工具包包括:(1) 训练/评估,(2) 标记/校准,以及(3) 用于加速自动驾驶研究的基于4DRT的感知的可视化工具。
本文的其余部分组织如下。第2节介绍了与自动驾驶感知相关的现有数据集和基准。第3节解释了K-Radar数据集和基线神经网络。第4节讨论了基线神经网络在K-Radar数据集上的实验结果。第5节总结并讨论了本研究的局限性。
2.相关工作
深度神经网络通常需要从不同的条件下收集大量的训练样本,以便它们能够以优异的泛化能力获得显著的性能。在自动驾驶中,有许多物体检测数据集提供了各种传感器模态的大规模数据,如表1所示。

KITTI(Geiger et al.,2012)是最早且广泛使用的自动驾驶物体检测数据集之一,提供相机和激光雷达测量以及准确的校准参数和3D边界盒标签。然而,数据集的样本数量和多样性相对有限,因为数据集的15K帧主要在白天在城市地区收集。另一方面,Waymo(Sun等人,2020)和NuScenes(Caesar et al.,2020)分别提供了230K和40K帧的大量样本。在这两个数据集中帧都是在白天和夜间收集的,增加了数据集的多样性。此外,NuScenes提供了3D雷达点云(RPC),Nabati和Qi(2021)证明利用雷达作为神经网络的辅助输入可以提高网络的检测性能。然而,RPC由于CFAR阈值操作而丢失了大量信息,并且在用作网络的主要输入时导致较差的检测性能。例如,基于激光雷达的三维物体检测在NuScenes数据集上的最先进性能为69.7%mPA,而基于雷达的仅为4.9%mPA时。
在文献中,有几个基于3DRT的自动驾驶物体检测数据集。CARRADA(Ouaknine et al.,2021)为距离-方位角和距离-多普勒维度的雷达张量提供了受控环境(宽平面)中最多两个物体的标签。Zenar(Mostajabi等人,2020)、RADIATE(Sheeny等人,2021)和RADDet(Zhang et al.,2021)另一方面,提供了在真实道路环境中收集的雷达张量,但由于3DRT中缺乏高度信息,只能提供2D BEV边界框标签。CRUW(Wang et al.,2021b)提供了大量的3DRT,但注释仅提供对象的2D点位置。VoD(Palffy等人,2022)和Asytx(Meyer和Kuschk,2019)提供了具有4DRPC的3D边界盒标签。然而,密集的4DRT不可用,并且数据集中的样本数量相对较少(即8.7K和0.5K帧)。据我们所知,所提出的K-Radar是第一个在不同条件下提供4DRT测量以及3D边界框标签的大规模数据集。
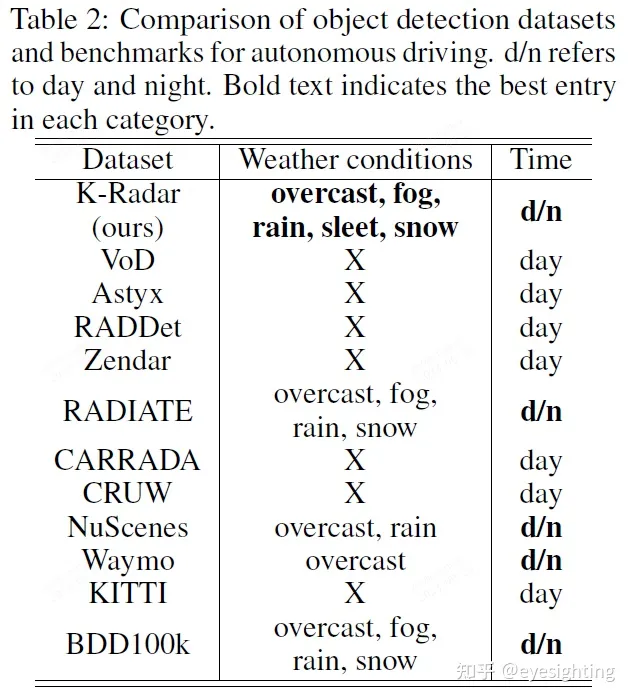
自动驾驶汽车即使在恶劣的天气条件下也应该能够安全运行,因此,自动驾驶数据集中恶劣天气数据的可用性至关重要。在文献中,BDD100K(Yu et al.,2020)和RADIATE数据集包含在不利天气条件下获取的帧,如表2所示。然而,BDD100K仅提供RGB正面图像,而RADIATE仅提供32通道低分辨率LPC。同时,所提出的K-Radar提供了4DRT、64通道和128通道高分辨率LPC以及360度RGB立体图像,这使得能够开发使用雷达、激光雷达和相机的多模态方法,以解决恶劣天气条件下自动驾驶的各种感知问题。
3.K-Radar
在本节中,我们描述了用于构建K-Radar数据集的传感器的配置、数据收集过程以及数据的分布。然后,我们解释了4DRT的数据结构,以及可视化、校准和标记过程。最后,我们提出了可以直接使用4DRT作为输入的3D对象检测基线网络。
3.1 K-雷达传感器规范
为了在恶劣天气下收集数据,我们根据图3所示的配置安装了五种IP66等级的防水传感器(见附录B)。首先,在汽车的前格栅上安装了一个4D雷达,以防止由于发动机罩或天花板造成的多径现象。其次,64通道远程激光雷达和128通道高分辨率激光雷达位于车顶中心,高度不同(图3-(a))。远程LPC用于精确标记各种距离的物体,而高分辨率LPC提供具有宽(即44.5度)垂直视场(FOV)的密集信息。第三,在车辆的前部、后部、左侧和右侧放置了一个立体摄像头,这将产生四个立体RGB图像,从自我车辆的角度覆盖360度视场。最后,在车辆后侧设置了一个RTK-GPS天线和两个IMU传感器,以实现自我车辆的精确定位。

3.2 数据收集和分布
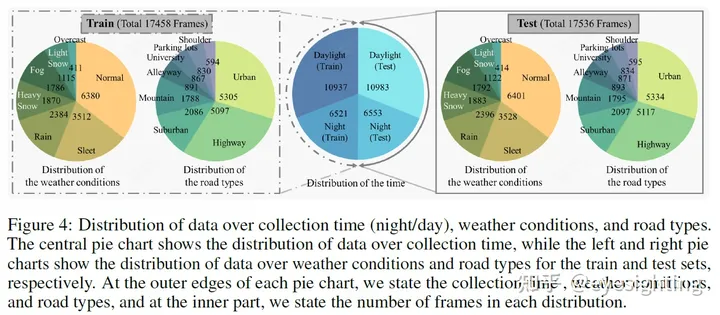
大多数天气条件恶劣的相框都是在大韩民国江原道收集的,该省是全国年降雪量最高的省份。另一方面,具有城市环境的相框大多收集在大韩民国的大田。数据收集过程产生了35K帧的多模态传感器测量,这些测量构成了K-Radar数据集。我们根据附录C中列出的标准将收集的数据分为几个类别。此外,我们将数据集拆分为训练集和测试集,使每个条件以平衡的方式出现在两个集中,如图4所示。
在距离自我车辆120米的纵向半径和80米的横向半径内,道路上的物体(即轿车、公共汽车或卡车、行人、自行车和摩托车)总共有93.3K个3D边界框标签。请注意,我们只注释出现在正纵轴上的对象,即在自我交通工具前面的对象。在图5中,我们显示了K-Radar数据集中对象类别和对象与自车辆的距离的分布。大多数物体位于距离自我车辆60米以内的地方,其中10K-15K个物体分别出现在0米至20米、20米至40米和40米至60米的距离类别中,约7K个物体出现在60米以上的距离类别。因此,K-Radar可以用于评估3D物体检测网络对不同距离物体的性能。

3.3 数据可视化、校准和标注过程、
与缺乏高度信息的3D雷达张量(3DRT)相反,4D雷达张量(4DRT)是一个密集的数据张量,充满了四个维度的功率测量:多普勒、距离、方位和仰角。然而,密集数据的额外维度给将4DRT可视化为稀疏数据(如点云)带来了挑战(图2)。为了解决这个问题,我们通过启发式处理将4DRT可视化为笛卡尔坐标系中的二维热图,如图6-(a)所示,这导致了鸟瞰图(BEV-2D)、前视图(FV-2D)和侧视图(SV-2D)中的二维热图可视化。我们将这些2D热图统称为BFS-2D。

通过BEV-2D,我们可以直观地验证4D雷达对恶劣天气条件的稳健性,如图2所示。如前所述,在下雨、雨夹雪和下雪等不利天气条件下,相机和激光雷达测量可能会恶化。在图2-(e,f)中,我们显示了在大雪条件下,长距离物体的激光雷达测量值丢失。然而,4DRT的BEV-2D清楚地指示了在对象的边界框边缘上具有高功率测量的对象。
我们还提出了一种用于BEV-2D和LPC逐帧校准的工具,以将3D边界框标签从激光雷达坐标系转换为4D雷达坐标系。校准工具支持每像素1厘米的分辨率,最大误差为0.5厘米。4D雷达和激光雷达之间的校准细节见附录D.2。此外,我们通过附录D.3中详细介绍的一系列过程,精确地获得了激光雷达和相机之间的校准参数。激光雷达和相机之间的校准过程使3D边界盒和LPC能够准确地投影到相机图像上,这对多模态传感器融合研究至关重要,并可用于生成用于单目深度估计研究的密集深度图。
3.4 K-Radar的基线神经网络
我们提供了两个基线神经网络来证明高度信息对3D物体检测的重要性:(1) 具有高度的雷达张量网络(RTNH),通过3D稀疏CNN从RT中提取特征图(FM),从而利用高度信息,以及(2) 无高度雷达张量网络(RTN),其利用不利用高度信息的2D CNN从RT中提取FM。如图7所示,RTNH和RTN都由预处理、主干、颈部和头部组成。预处理将4DRT从极坐标系转换为笛卡尔坐标系,并提取感兴趣区域(RoI)内的3DRT-XYZ。请注意,我们通过沿着维度取平均值来减小多普勒维度。主干然后提取包含用于边界框预测的重要特征的FM。头部根据颈部产生的串联FM预测3D边界框。

附录E中详细描述了RTNH和RTN的网络结构,除了主干之外,其他结构相似。我们分别用3D-SCB和2D-DCB构建了RTNH和RTN的主干。3D-SCB利用3D稀疏卷积(Liu et al.,2015),从而可以将三维空间信息(X,Y,Z)编码到最终FM中。我们选择在稀疏RT上使用稀疏卷积(RT中的前10%功率测量),因为原始RT上的密集卷积需要大量的内存和计算,不适合实时自动驾驶应用。与3D-SCB不同,2D-DCB使用2D卷积,因此只有二维空间信息(X,Y)被编码到最终FM中。结果,3D-SCB产生的最终FM包含3D信息(具有高度),而2D-DCB产生的最后FM仅包含2D信息(没有高度)。
4.Experiment
在本节中,我们展示了基于4DRT的感知在各种天气下对自动驾驶的鲁棒性,以找到基线神经网络和类似结构的基于激光雷达的神经网络PointPillars之间的3D物体检测性能比较(Lang et al.,2019)。我们还通过比较基线NN与3D-SCB主干(RTNH)和基线NN与2D-DCB主干(RTN)之间的3D对象检测性能,讨论了高度信息的重要性。
4.1 实验设置和度量
实现细节我们使用PyTorch 1.11.0在带有RTX3090 GPU的Ubuntu机器上实现了基线NN和PointPillars。我们将批量大小设置为4,并使用Adam优化器以0.001的学习率训练11个时期的网络。请注意,我们将检测目标设置为轿车类,该类在K-Radar数据集中具有最多的样本。
定量在实验中,我们利用广泛使用的基于联合交集(IOU)的平均精度(AP)度量来评估3D对象检测性能。我们提供了用于BEV(APBEV)和3D(AP3D)边界盒预测的AP,如(Geiger et al.,2012)中所述,其中如果IoU超过0.3,则预测被认为是真正的。
4.2 RTN与RTNH的比较
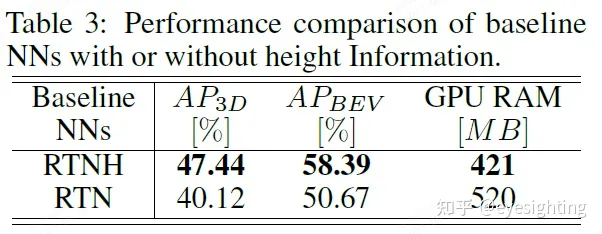
我们在表3中显示了RTNH和RTN之间的检测性能比较。我们可以观察到,与RTN相比,RTNH在AP3D和APBEV中的性能分别高出7.32%和7.72%。在AP3D和APBEV方面,RTNH显著超过RTN,这表明4DRT中可用的高度信息对于3D对象检测的重要性。此外,与RTN相比,RTNH需要更少的GPU内存,因为它利用了第3.4节中提到的内存高效稀疏卷积。
4.3 RTNH与PointPillars的比较
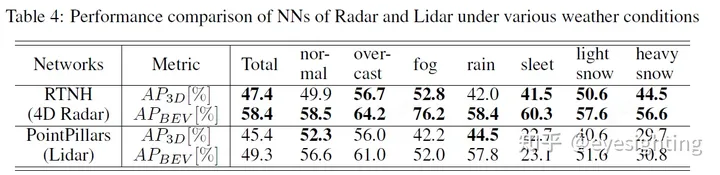
我们在表4中显示了RTNH和类似结构的基于激光雷达的检测网络PointPillars之间的检测性能比较。与正常情况相比,在雨夹雪或大雪条件下,基于激光雷达的网络的BEV和3D检测性能分别显著下降33.5%和29.6%或25.8%和22.6%。相比之下,基于4D雷达的RTNH探测性能几乎不受不利天气的影响,在雨夹雪或大雪条件下,BEV和3D物体探测性能比正常条件更好或相似。结果证明了基于4D雷达的感知在恶劣天气下的鲁棒性。我们在附录F中提供了其他天气条件的定性结果和额外讨论。
5.局限性和结论
在本节中,我们讨论了K-Radar的局限性,并对这项工作进行了总结,并对未来的研究方向提出了建议。
5.1 4DRT FOV覆盖范围的限制
如第3.1节所述,K-Radar在前向方向提供4D雷达测量,视场为107度。与激光雷达和相机的360度视场相比,测量覆盖范围更为有限。这种限制源于具有四维密集测量的4DRT的大小,与具有二维的相机图像或具有三维的LPC相比,4DRT需要更大的存储器来存储数据。具体而言,K-Radar中的4DRT数据的大小大约为12TB,而环绕相机图像数据的大小约为0.4TB,LPC数据的大小为0.6TB。由于提供360度4DRT测量需要大量的内存,我们选择仅在正向记录4DRT数据,这可以为自动驾驶提供最相关的信息。
5.2 结论
在本文中,我们介绍了一个基于4DRT的三维目标检测数据集和基准K-Radar。K-Radar数据集由35K帧组成,其中包含4DRT、LPC、环绕摄像头图像和RTKIMU数据,所有这些数据都是在不同的时间和天气条件下收集的。K-Radar为距离达120m的五类93.3K个物体提供3D边界框标签和跟踪ID。
为了验证基于4D雷达的目标检测的稳健性,我们引入了使用4DRT作为输入的基线神经网络。从实验结果中,我们证明了传统3DRT中无法获得的高度信息的重要性,以及4D雷达在恶劣天气下的稳健性。虽然这项工作中的实验集中在基于4DRT的3D物体检测上,但K-Radar可用于基于4DRT的物体跟踪、SLAM和各种其他感知任务。因此,我们希望K-Radar能够加速基于4DRT的自动驾驶感知工作。
① 全网独家视频课程
BEV感知、毫米波雷达视觉融合、多传感器标定、多传感器融合、3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、协同感知、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码免费学习)
 视频官网:www.zdjszx.com
视频官网:www.zdjszx.com
② 国内首个自动驾驶学习社区
近2000人的交流社区,涉及30+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(2D检测、分割、2D/3D车道线、BEV感知、3D目标检测、Occupancy、多传感器融合、多传感器标定、目标跟踪、光流估计)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、Occupancy、多传感器融合、大模型、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向。扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)
















 503
503











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









