






点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
今天自动驾驶之心很荣幸邀请到Runwei Guan来分享ITSC 2023最新中稿的单目&4D毫米波雷达融合算法—Achelous,如果您有相关工作需要分享,请在文末联系我们!
论文作者 | Runwei Guan
编辑 | 自动驾驶之心
作者单位:利物浦大学,西交利物浦大学,江苏省产业技术研究院深度感知技术研究所
论文地址:https://arxiv.org/abs/2307.07102
论文代码:https://github.com/GuanRunwei/Achelous

很开心受邀来分享我们ITSC 2023最新中稿的Achelous。
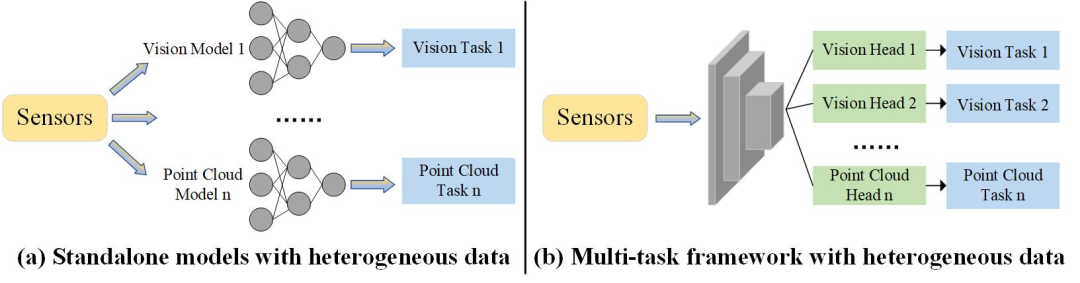
目前水面无人艇(Unmanned Surface vehicle, USV)上针对不同任务的感知模型通常以模块化形式存在,在边缘设备上并行推理速度极慢,导致感知结果与USV位置不同步甚至自主导航决策的错误。与无人车(UGVs)相比,USVs的鲁棒感知发展相对缓慢。此外,目前大多数多任务感知模型参数庞大、推理速度慢且不可扩展。基于此,本文提出一种基于单目相机和4D毫米波雷达融合的低成本、快速的统一水面全景感知框架Achelous。Achelous可以同时执行视觉目标检测与分割、可行驶区域分割、水岸线分割和雷达点云分割5项任务。此外,Achelous家族的模型,参数少于500万,在NVIDIA Jetson AGX Xavier上实现了约18 FPS,比HybridNets快11 FPS,并在我们收集的约5 mAP50-95和0.7 mIoU的数据集上超过了YOLOX-Tiny和Segformer-B0,特别是在恶劣天气、黑暗环境和相机故障的情况下。据我们所知,Achelous是第一个结合视觉级和点云级任务的水面感知综合全景感知框架。
Introduction
随着深度学习的快速发展,自动驾驶已经变得高度智能化。感知作为自动驾驶的一个重要模块,包含了目标检测、可驾驶区域分割、车道线分割、占用预测等环境感知任务。相应地, 多传感器融合技术目前已被用于提高感知系统的精度和鲁棒性 [1]。在深度学习的帮助下,无人地面车辆(UGVs)取得了显著的发展。然而,水面感知能力相较于道路感知发展较为缓慢。USVs在水处理中发挥着重要作用,如水上救援 [2]、水质监测 [3]、垃圾回收 [4]、地质勘查 [5]等。通过大量调研发现: 首先,大多数水面感知模型只能执行单一任务,难以帮助无人艇完成自主导航; 此外,有研究表明多任务之间可以相互提升 [9][10]。其次,目前已有的一些无人船系统倾向于并行多个单任务模型,这可能导致异步感知结果 。此外,感知系统的整体速度取决于推理速度最慢的模型(图1)。再者,许多模型从未考虑过边缘设备上的实时推理问题。它们只能运行在远程服务器的高性能GPU设备上 [9][11],过度依赖网络通信能力。然而,在海洋航行过程中,网络通信能力急剧减弱,一旦网络中断,将给USVs执行某些危险任务带来灾难。最后,纯视觉模型 [12][13] 在面对黑暗环境、浓雾或镜头失灵时是不可靠的。目前,4D毫米波雷达被认为是一种很有前途的不利环境下相机的互补感知传感器,但如何有效地提取不规则雷达特征是一个挑战。
基于以上,
我们提出了一种基于单目相机和4D雷达融合的低成本、快速的统一水面全景感知框架Achelous。Achelous将5个感知任务集成在一个端到端框架中,包括目标检测、目标语义分割、水线分割、可驾驶区域分割与雷达点云语义分割。Achelous在NVIDIA Jetson AGX Xavier上获得了约18 FPS,并在感知任务上与单任务模型和其他多任务模型相比实现了有竞争力的性能。
我们提出一种简单有效的卷积算子RadarConv (Radar conv)。与普通卷积相比,RadarConv对雷达点云的不规则性友好,能够精细化有效提取不规则点云特征。
为了促进基于多传感器的水面全景感知的发展,我们的Achelous家族具有可扩展性和开源性。
Achelous
A. Overview
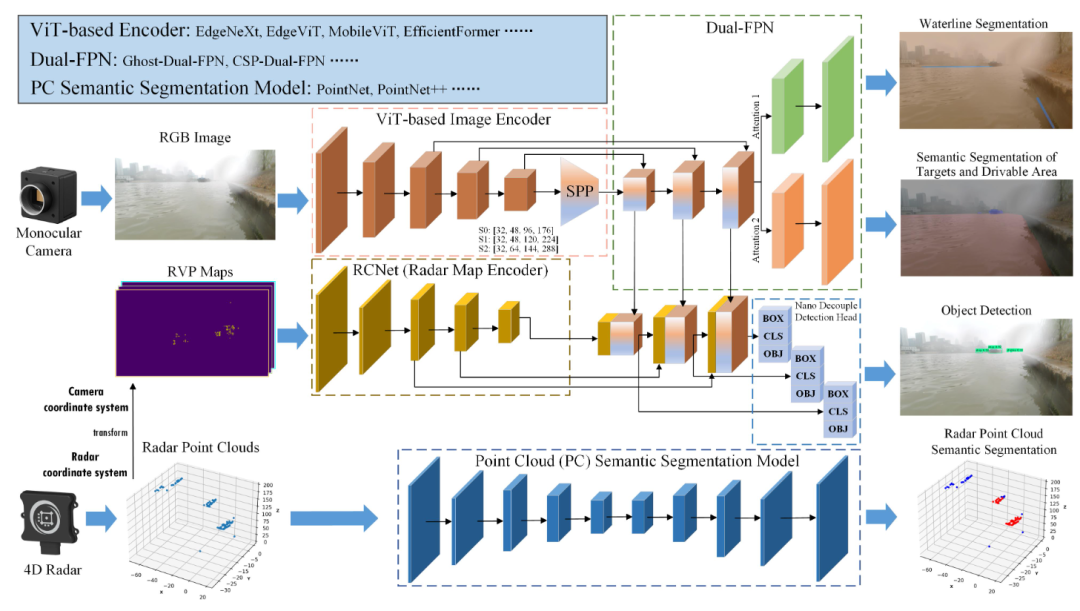
如 Figure 3 所示,Achelous基于安装有单目相机和4D雷达的无人船平台。单目相机获取RGB图像,4D雷达直接获取三维点云。每个雷达点云包含目标的多个物理特征。在这些物理特征中,我们选择了摄像机无法准确感知的目标的距离、速度和反射强度。为了使雷达点云能够辅助基于视觉的目标检测,我们将点云坐标从三维雷达坐标系转换到二维摄像机平面。我们称2D雷达伪图像为RVP图,其中每个通道代表雷达目标的距离、速度和反射强度。
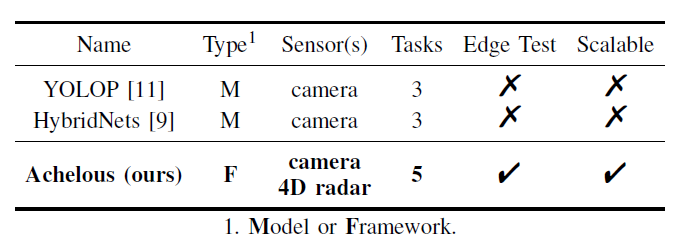
该系统的主体部分包括基于ViT轻量化变体的图像编码器、雷达特征编码器、任务头和点云语义分割模型。如 Figure 2 所示,与其他两种全景感知模型(YOLOP和HybridNets)相比,我们的Achelous支持更多的传感器和任务。此外,Achelous专门执行边缘测试,其中模块是可选和可扩展的。Achelous有三个通道大小,S0, S1和S2。为了加快推理速度,Achelous尽可能地压缩分支和网络碎片,并权衡使用激活函数和分组卷积。此外,网络单元的输入输出通道保持相等,减少了访存开销。
B. ViT-based Image Encoder
在过去的几年中,我们见证了基于视觉transformer (ViT)的模型的出色表现。基于ViT的模型可以基于自注意力机制 [14] 对全局上下文特征进行建模。此外,ViT的预测性能总体上超过了CNN [15][16][17]。ViT在对抗性攻击 [18][19][20]、视觉目标遮挡 [21] 和数据损坏 [22]方面比CNN更鲁棒。多头自注意力可以集成预测特征 [23],但CNN无法,且多头自注意力的信息容量远远大于相同参数的CNN。尽管ViT经常被诟病其推理缓慢,但最近的研究表明设计巧妙的ViT仍然可以与CNN一样快地运行 [24][25][26][27]。基于上述优势,我们利用基于ViT的模型作为图像编码器。遵循backbone的一致范式,所提出的图像编码器有五个阶段,具有多尺度尺寸的特征图,其中最后四个阶段分别包含2、2、6和4层。我们的Achelous初步包含四个基于ViT的轻量级骨干,EdgeNeXt [25], EdgeViT [24], MobileViT [26]和EfficientFormer [27]。遵循主干,空间金字塔池化(SPP) [28] 是为了扩大多尺度图像特征图的感受野。
C. Dual-FPN and Segmentation Heads
特征金字塔网络(Feature Pyramid Network, FPN)是融合多尺度特征的重要模块。Achelous有一个Dual-FPN,用于融合基于ViT的编码器提取的特征,其中前三个特征图是权重共享的,最后一个特征图是权重独立的。在权重共享和权重独立的特征图之间,使用两个shuffle attention [29] 模块对两个不同分割任务的特征进行重测量。受GhostNet [30] 和CSPDarknet [31] 的启发,设计了两种轻量级的FPN, Ghost-Dual-FPN (GDF) 和CSP-Dual-FPN (CDF),其中GDF可以在特征融合阶段显著消除特征冗余,而CDF可以加速特征融合操作。此外,在融合后的特征图后面还有两个分割头,分别用于水线分割、目标和可行使区域的语义分割。
D. Point Cloud Semantic Segmentation Model
由于相机可能会因为恶劣的天气而失效,雷达将接管Achlous的感知。由于雷达无法采用基于视觉的检测模式,雷达点云的语义分割至关重要。基于PointNet [32] 和PointNet++ [33] 的排列不变性和局部特征学习思想,出现了许多点云处理模型。采用PointNet和Pointnet++作为点云语义分割的组件,降低了框架的计算负担,提高了分割速度。此外,将模型的通道数量减少到原来的三分之一,因为雷达点云比激光雷达稀疏得多,而且太多的隐通道是冗余的。
E. Radar Convolution, RCBlock, RCNet and Fusion with Image Features
我们注意到雷达点云具有稀疏和不规则的特点,这意味着传统的卷积包含许多无效操作,并且将特征图作为规则网格。为了使卷积对雷达点云特征提取友好,并减轻特征损失,本文提出雷达卷积(Figure 4),一种简单但高效的卷积算子。我们首先采用3×3的平均池化扩大感受野。与最大池化相比,平均池化可以保留更多的特征信息,聚合局部特征。此外,池化操作比卷积快得多。针对雷达点云的不规则性,引入带偏移量的可变形卷积 [34] 来提取特征; 基于雷达卷积,构建RCBlock和RCNet,如图3所示。RCBlock包含两个1×1卷积来权衡每个空间特征。RCNet的通道数量是基于vit的图像编码器的四分之一,因为雷达点云是稀疏的,不需要那么多的非线性操作的隐特征。
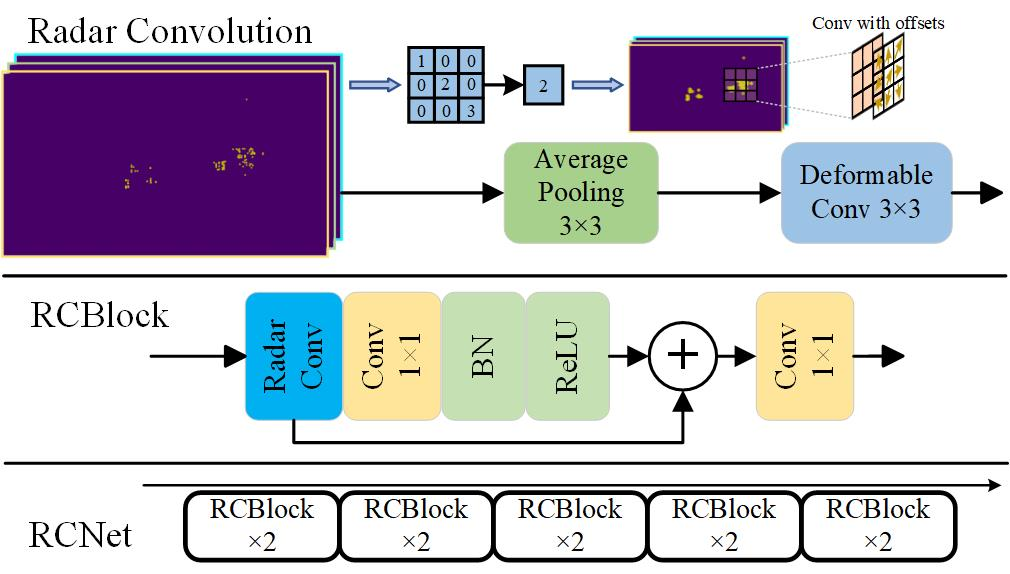
RCNet是一种用于检测的辅助网络,将雷达特征图与Dual-FPN中的图像特征图进行连接,以帮助自动更快地定位目标并提高不利天气情况下的召回率。虽然许多工作在主干和主干 [7][35] 中融合雷达和图像特征,但发现太多的分支会导致推理速度急剧下降。由于Dual-FPN中的图像特征图包含丰富的用于分割的细节底层特征,此外,上采样操作和SPP在不同阶段为特征图配备了多尺度特征。因此,FPN阶段的融合足以实现鲁棒的目标检测。
F. Nano Decouple Detection Head
我们将检测头中的特征图解耦,分别预测边界框、类别和置信度。此外,采用深度可分离卷积,以在很大程度上减少参数。此外,使用anchor- free算法加快推理速度,使用SimOTA [36] 算法提高正样本匹配速度。
Experiments
A. 实验设置
设备. 我们在我们的无人艇上安装了一个索尼IMX-317 RGB相机和一个Oculii EAGLE成像雷达。传感器通过时间戳进行时间同步,通过校准板进行空间同步。
数据.我们捕获了50,000张图像和帧的雷达数据 [41]。每个图像是1920×1080像素。检测分为7类,包括码头、浮标、船员、ship、boat、vessel和kayak。除了这些类之外,drivable area是用于语义分割的另一个类,而clutter是用于点云语义分割的另一个类。水线是一种单类水线分割方法。我们用VOC格式标注了目标检测和语义分割。我们基于边界框的真实值标注点云类别,并通过速度聚类。将数据按7:2:1的比例划分为训练集、验证集和测试集。
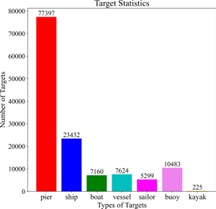
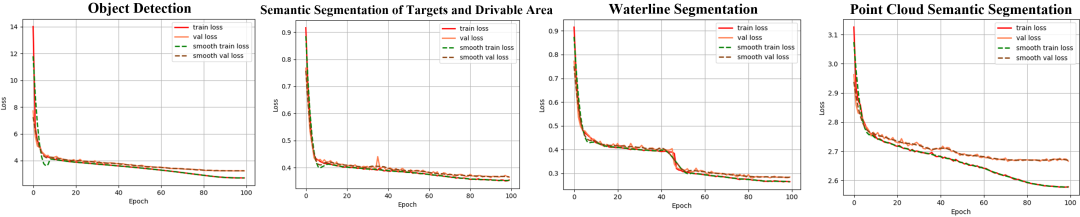
训练与评估.我们调整图像与RVP映射到320×320像素。我们将Achelous训练了100个epoch, batch大小为32,初始学习率为0.03。我们采用动量为0.937的随机梯度下降(SGD)作为优化器和余弦学习率调度器。在训练过程中,我们使用混合精度和指数移动平均线(EMA)。采用基于同方差不确定性的 [10] 多任务训练策略。检测时采用focal+giou损失,分割时采用dice+focal损失,点云分割时采用NLL损失。我们在两个具有数据并行模式的RTX A4000 gpu上从头开始训练Achelous和其他模型。我们在NVIDIA Jetson AGX Xavier(Figure 6)和RTX A4000上测试了所有模型的FPS。我们使用mAP50-95、mAP50和AR50作为指标来评估目标检测,而mIoU则用来衡量图像和雷达点云的语义分割。

B. Achelous与其他模型的比较
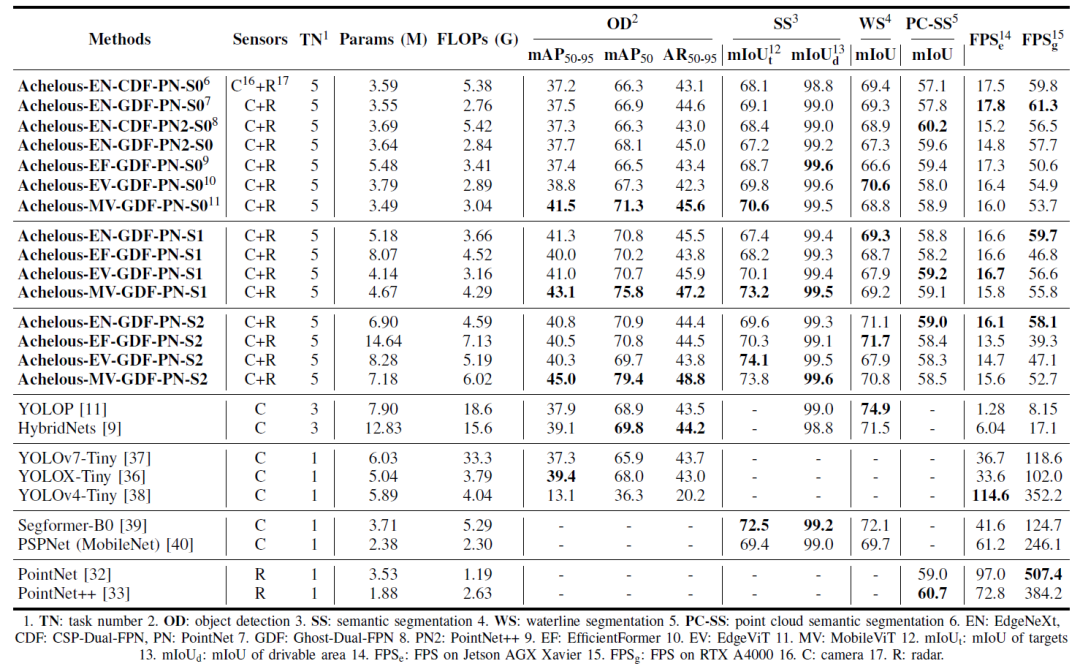
我们将Achelous与其他全景感知模型和单任务模型进行了比较。评估了目标检测、目标语义分割、可驾驶区域分割、水线分割和点云语义分割的性能。我们还在边缘设备(NVIDIA Jetson AGX Xavier)和高性能GPU (RTX A4000)上测试FPS。我们观察到,Achelous在多任务训练中正常收敛(Figure 8)。与其他全景感知模型和单任务模型相比,Achelous在目标检测、目标语义分割和可驾驶区域等方面取得了最先进的性能。以MobileViT为骨干的Achelous在三种大小(S0, S1和S2)的目标检测和语义分割方面取得了最佳性能,大大超过了其他模型。然而,在水线分割方面,YOLOP比Achelous高出约3% mIoU。对于点云语义分割,Pointnet++的Achelous优于PointNet的Achelous。此外,Achelous比YOLOP和HybridNets快得多。在NVIDIA Jetson AGX Xavier上,Achelous的FPS在13 ~ 18之间,基本满足了USV在高速行驶状态下的实时推理。我们还将Achelous和YOLOP的预测结果可视化,如 Figure 9 和 Figure 10 所示。我们可以看到在大多数情况下,无论在黑暗环境、恶劣天气或光照干扰下,Achelous都能比YOLOP更好地检测和分割目标。


C. Speed of Parallel Standalone Models and Achelous
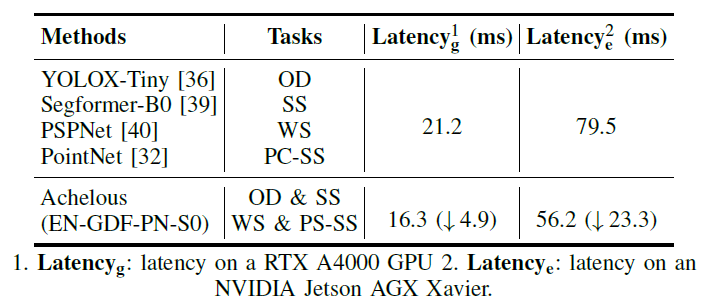
如 Figure 11 所示,我们在Jetson AGX Xavier和RTX A4000上测试了独立并行推理模型和Achelus-EN-GDF-PN-S0的延迟。我们的Achelous无论在Jetson还是RTX A4000上,在执行多个全景感知任务时,Achelous的延迟都低于并行独立模型。证明了多任务模型是全景感知提高效率的必要条件。
D. Ablation Experiments
我们首先对RCNet做了消融实验( Figure 12),在Achelous- EN-GDF-PN-S0中用MobileNetV2替换RCNet,这是一个结构类似的由普通卷积组成的网络。我们注意到mAP50-95下降了0.2,而AP50下降了0.5。实验证明,包含雷达卷积的RCNet比普通卷积计算器能更好地捕获和建模雷达点云特征。

此外,我们还比较了两种不同的融合方法的结果。在骨干网络和FPN阶段融合图像和雷达特征并不能显著提高检测性能,其推理延迟比fpn级融合慢13.2 ms。
E. Visualization and Analysis of Feature Maps
为了验证我们的机器人是否关注了正确的感兴趣区域,我们采用Grad-CAM[42]来可视化FPN中与检测头相连的最后一层的热图。我们选择yolo - m与我们的Achelous-MV-GDF-PN-S2进行比较。我们选择了三个具有挑战性的场景:桥下的黑暗环境、水滴导致的镜头失效和雾天。首先,观察到基于纯视觉的YOLO-X在黑暗环境中表现糟糕,察觉到了一名船员但漏检了另一名船员。
令人兴奋的是,基于视觉和雷达融合的Achelous成功地捕获了远处的水手。其次,当镜头上有水滴时,基于纯视觉的YOLOX-M完全忽略了位于被干扰的区域的目标,但Achelous注意到了被忽视的水手。对于第三种情况,即远处的船只被浓雾所遮蔽,我们的Achelous能够感知到三艘远处的小型船只,而YOLOX-M却不能,这验证了具有远程探测能力的雷达在某些恶劣天气下的重要性。总而言之,在各种具有挑战性的情况下,基于相机和4D雷达的特征级融合的Achelous具有更少的参数,比纯视觉模型可靠得多。
Conclusion
我们提出了一种基于摄像机和4D毫米波雷达的河道全景感知框架Achelous,可以同时执行视觉级和点云级5种不同的感知任务。Achelous是一个高效的框架,可以在NVIDIA Jetson AGX Xavier上实时推理。我们还提出了雷达卷积,可以精细地提取雷达点云稀疏和不规则的特征。在大多数感知任务上,特别是在不利情况下,Achelous的表现也优于其他全景感知模型和单任务模型。希望Achelous能够推动水面全景感知的发展,为研究人员提供一种低成本、高效率的方案。此外,我们正在将目标追踪、实例分割以及更多的神经网络组件、后处理算法、各阶段功能模块以及更多多任务优化算法集成到Achelous框架下。
References
[1] Xuyang Bai, Zeyu Hu, Xinge Zhu, Qingqiu Huang, Yilun Chen, Hongbo Fu, and Chiew-Lan Tai, “Transfusion: Robust lidar-camera fusion for 3d object detection with transformers,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 1090–1099.
[2] Tingting Yang, Zhi Jiang, Ruijin Sun, Nan Cheng, and Hailong Feng, “Maritime search and rescue based on group mobile computing for unmanned aerial vehicles and unmanned surface vehicles,” IEEE transactions on industrial informatics, vol. 16, no. 12, pp. 7700–7708, 2020.
[3] Xiaohui Zhu, Yong Yue, Prudence WH Wong, Yixin Zhang, and Hao Ding, “Designing an optimized water quality monitoring network with reserved monitoring locations,” Water, vol. 11, no. 4, pp. 713, 2019.
[4] Dario Madeo, Alessandro Pozzebon, Chiara Mocenni, and Duccio Bertoni, “A low-cost unmanned surface vehicle for pervasive water quality monitoring,” IEEE Transactions on Instrumentation and Measurement, vol. 69, no. 4, pp. 1433–1444, 2020.
[5] Zhibin Xue, Jincun Liu, Zhengxing Wu, Sheng Du, Shihan Kong, and Junzhi Yu, “Development and path planning of a novel unmanned surface vehicle system and its application to exploitation of qarhan salt lake,” Science China Information Sciences, vol. 62, no. 8, pp. 1–3, 2019.
[6] Mohammad-Hashem Haghbayan, Fahimeh Farahnakian, Jonne Poiko- nen, Markus Laurinen, Paavo Nevalainen, Juha Plosila, and Jukka Heikkonen, “An efficient multi-sensor fusion approach for object detection in maritime environments,” in 2018 21st International Conference on Intelligent Transportation Systems (ITSC). IEEE, 2018, pp. 2163–2170.
[7] Yuwei Cheng, Hu Xu, and Yimin Liu, “Robust small object detection on the water surface through fusion of camera and millimeter wave radar,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 15263–15272.
[8] Keunhwan Kim, Jonghwi Kim, and Jinwhan Kim, “Robust data association for multi-object detection in maritime environments using camera and radar measurements,” IEEE Robotics and Automation Letters, vol. 6, no. 3, pp. 5865–5872, 2021.
[9] Dat Vu, Bao Ngo, and Hung Phan, “Hybridnets: End-to-end perception network,” arXiv preprint arXiv:2203.09035, 2022.
[10] Alex Kendall, Yarin Gal, and Roberto Cipolla, “Multi-task learning using uncertainty to weigh losses for scene geometry and semantics,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 7482–7491.
[11] Dong Wu, Man-Wen Liao, Wei-Tian Zhang, Xing-Gang Wang, Xiang Bai, Wen-Qing Cheng, and Wen-Yu Liu, “Yolop: You only look once for panoptic driving perception,” Machine Intelligence Research, p. 550–562, Nov 2022.
[12] Lili Zhang, Yi Zhang, Zhen Zhang, Jie Shen, and Huibin Wang, “Real- time water surface object detection based on improved faster r-cnn,” Sensors, vol. 19, no. 16, pp. 3523, 2019.
[13] Tao Liu, Bo Pang, Lei Zhang, Wei Yang, and Xiaoqiang Sun, “Sea surface object detection algorithm based on yolo v4 fused with reverse depthwise separable convolution (rdsc) for usv,” Journal of Marine Science and Engineering, vol. 9, no. 7, pp. 753, 2021.
[14] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weis- senborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al., “An image is worth 16x16 words: Transformers for image recognition at scale,” in International Conference on Learning Representations.
[15] Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo, “Swin transformer: Hierarchical vision transformer using shifted windows,” in Proceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 10012–10022.
[16] Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, et al., “Swin transformer v2: Scaling up capacity and resolution,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 12009–12019.
[17] Hangbo Bao, Li Dong, Songhao Piao, and Furu Wei, “Beit: Bert pre-training of image transformers,” in International Conference on Learning Representations, 2021.
[18] Rulin Shao, Zhouxing Shi, Jinfeng Yi, Pin-Yu Chen, and Cho-Jui Hsieh, “On the adversarial robustness of visual transformers,” arXiv preprint arXiv:2103.15670, vol. 1, no. 2, 2021.
[19] Srinadh Bhojanapalli, Ayan Chakrabarti, Daniel Glasner, Daliang Li, Thomas Unterthiner, and Andreas Veit, “Understanding robustness of transformers for image classification,” Mar 2021.
[20] Sayak Paul and Pin-Yu Chen, “Vision transformers are robust learn- ers,” Proceedings of the AAAI Conference on Artificial Intelligence, p. 2071–2081, Jul 2022.
[21] MuhammadMuzammal Naseer, Kanchana Ranasinghe, SalmanH. Khan, Munawar Hayat, FahadShahbaz Khan, and Ming-Hsuan Yang, “Intriguing properties of vision transformers,” Dec 2021.
[22] Matthias Minderer, Josip Djolonga, Rob Romijnders, Frances Hubis, Xiaohua Zhai, Neil Houlsby, Dustin Tran, and Mario Lucic, “Revis- iting the calibration of modern neural networks,” Advances in Neural Information Processing Systems, vol. 34, pp. 15682–15694, 2021.
[23] Namuk Park and Songkuk Kim, “Blurs behave like ensembles: Spatial smoothings to improve accuracy, uncertainty, and robustness,” in International Conference on Machine Learning. PMLR, 2022, pp. 17390–17419.
[24] Junting Pan, Adrian Bulat, Fuwen Tan, Xiatian Zhu, Lukasz Dudziak, Hongsheng Li, Georgios Tzimiropoulos, and Brais Martinez, “Edgevits: Competing light-weight cnns on mobile devices with vision transformers,” in Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XI. Springer, 2022, pp. 294–311.
[25] Muhammad Maaz, Abdelrahman Shaker, Hisham Cholakkal, Salman Khan, Syed Waqas Zamir, Rao Muhammad Anwer, and Fahad Shah- baz Khan, “Edgenext: efficiently amalgamated cnn-transformer archi- tecture for mobile vision applications,” in Computer Vision–ECCV 2022 Workshops: Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part VII. Springer, 2023, pp. 3–20.
[26] Sachin Mehta and Mohammad Rastegari, “Mobilevit: light-weight, general-purpose, and mobile-friendly vision transformer,” arXiv preprint arXiv:2110.02178, 2021.
[27] Yanyu Li, Geng Yuan, Yang Wen, Ju Hu, Georgios Evangelidis, Sergey Tulyakov, Yanzhi Wang, and Jian Ren, “Efficientformer: Vision transformers at mobilenet speed,” Advances in Neural Information Processing Systems, vol. 35, pp. 12934–12949, 2022.
[28] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun, “Spatial pyramid pooling in deep convolutional networks for visual recogni- tion,” IEEE transactions on pattern analysis and machine intelligence, vol. 37, no. 9, pp. 1904–1916, 2015.
[29] Qing-Long Zhang and Yu-Bin Yang, “Sa-net: Shuffle attention for deep convolutional neural networks,” in ICASSP 2021 - 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), May 2021.
[30] Kai Han, Yunhe Wang, Qi Tian, Jianyuan Guo, Chunjing Xu, and Chang Xu, “Ghostnet: More features from cheap operations,” in 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Aug 2020.
[31] Alexey Bochkovskiy, Chien-Yao Wang, and Hong-YuanMark Liao, “Yolov4: Optimal speed and accuracy of object detection,” Apr 2020.
[32] R. Qi Charles, Hao Su, Mo Kaichun, and Leonidas J. Guibas, “Pointnet: Deep learning on point sets for 3d classification and segmentation,” in 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Nov 2017.
[33] CharlesR. Qi, Li Yi, Hao Su, and LeonidasJ. Guibas, “Pointnet++: Deep hierarchical feature learning on point sets in a metric space,” Jun 2017.
[34] Xizhou Zhu, Han Hu, Stephen Lin, and Jifeng Dai, “Deformable convnets v2: More deformable, better results,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 9308–9316.
[35] Yunyun Song, Zhengyu Xie, Xinwei Wang, and Yingquan Zou, “Ms- yolo: Object detection based on yolov5 optimized fusion millimeter- wave radar and machine vision,” IEEE Sensors Journal, vol. 22, no. 15, pp. 15435–15447, 2022.
[36] Zheng Ge, Songtao Liu, Feng Wang, Zeming Li, and Jian Sun, “Yolox: Exceeding yolo series in 2021,” arXiv preprint arXiv:2107.08430, 2021.
[37] Chien-Yao Wang, Alexey Bochkovskiy, and Hong-Yuan Mark Liao, “Yolov7: Trainable bag-of-freebies sets new state-of-the-art for real- time object detectors,” arXiv preprint arXiv:2207.02696, 2022.
[38] Alexey Bochkovskiy, Chien-Yao Wang, and Hong-Yuan Mark Liao, “Yolov4: Optimal speed and accuracy of object detection,” arXiv preprint arXiv:2004.10934, 2020.
[39] Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M Alvarez, and Ping Luo, “Segformer: Simple and efficient design for semantic segmentation with transformers,” Advances in Neural Information Processing Systems, vol. 34, pp. 12077–12090, 2021.
[40] Hengshuang Zhao, Jianping Shi, Xiaojuan Qi, Xiaogang Wang, and Jiaya Jia, “Pyramid scene parsing network,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 2881–2890.
[41] Shanliang Yao, Runwei Guan, Zhaodong Wu, Yi Ni, Zixian Zhang, Zile Huang, Xiaohui Zhu, Yutao Yue, Yong Yue, Hyungjoon Seo, and Ka Lok Man, “Waterscenes: A multi-task 4d radar-camera fusion dataset and benchmark for autonomous driving on water surfaces,” 2023.
[42] Ramprasaath R Selvaraju, Michael Cogswell, Abhishek Das, Ramakr- ishna Vedantam, Devi Parikh, and Dhruv Batra, “Grad-cam: Visual explanations from deep networks via gradient-based localization,” in Proceedings of the IEEE international conference on computer vision, 2017, pp. 618–626.
投稿作者为『自动驾驶之心知识星球』特邀嘉宾,如果您希望分享到自动驾驶之心平台,欢迎联系我们!
① 全网独家视频课程
BEV感知、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、协同感知、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码学习)
 视频官网:www.zdjszx.com
视频官网:www.zdjszx.com
② 国内首个自动驾驶学习社区
近2000人的交流社区,涉及30+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(2D检测、分割、2D/3D车道线、BEV感知、3D目标检测、Occupancy、多传感器融合、多传感器标定、目标跟踪、光流估计)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多模态感知、Occupancy、多传感器融合、transformer、大模型、点云处理、端到端自动驾驶、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向。扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】平台矩阵,欢迎联系我们!


















 823
823

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









