






点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
编辑 | 自动驾驶之心
【RenderOcc,首篇仅使用2D标签训练多视图3D占用模型的新范式】作者从多视图图像中提取NeRF风格的3D体积表示,并使用体积渲染技术来建立2D重建,从而实现从2D语义和深度标签的直接3D监督,减少了对昂贵的3D占用标注的依赖。大量实验表明,RenderOcc的性能与使用3D标签完全监督的模型相当,突显了这种方法在现实世界应用中的重要性。已开源。
题目: RenderOcc: Vision-Centric 3D Occupancy Prediction with 2DRendering Supervision
作者单位: 北京大学,小米汽车,港中文MMLAB
开源地址: GitHub - pmj110119/RenderOcc
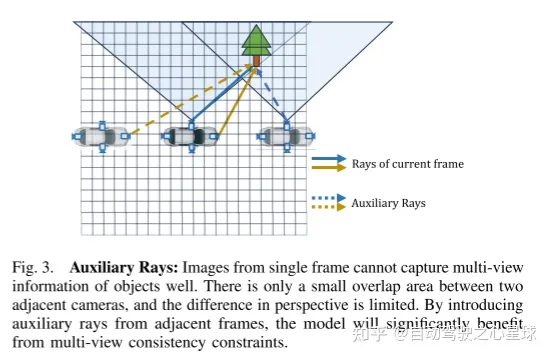
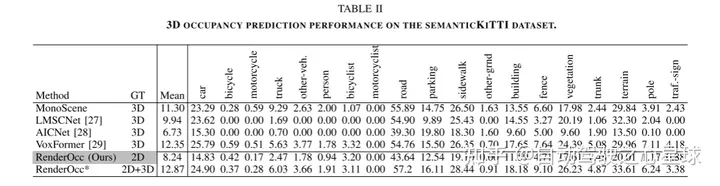
3D占用预测在机器人感知和自动驾驶领域具有重要前景,它将3D场景量化为带有语义标签的网格单元。最近的工作主要利用3D体素空间中的完整占用标签进行监督。然而,昂贵的标注过程和有时模糊的标签严重限制了3D占用模型的可用性和可扩展性。为了解决这个问题,作者提出了RenderOcc,这是一种仅使用2D标签训练3D占用模型的新范式。具体而言,作者从多视图图像中提取NeRF风格的3D体积表示,并使用体积渲染技术来建立2D重建,从而实现从2D语义和深度标签的直接3D监督。此外,作者引入了一种辅助光线方法来解决自动驾驶场景中的稀疏视点问题,该方法利用顺序帧为每个目标构建全面的2D渲染。RenderOcc是第一次尝试仅使用2D标签来训练多视图3D占用模型,从而减少了对昂贵的3D占用标注的依赖。大量实验表明,RenderOcc的性能与使用3D标签完全监督的模型相当,突显了这种方法在现实世界应用中的重要性。
网络结构:
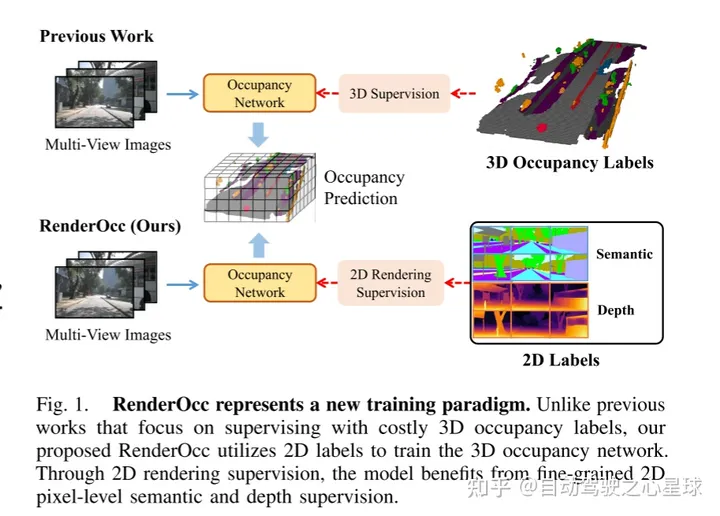
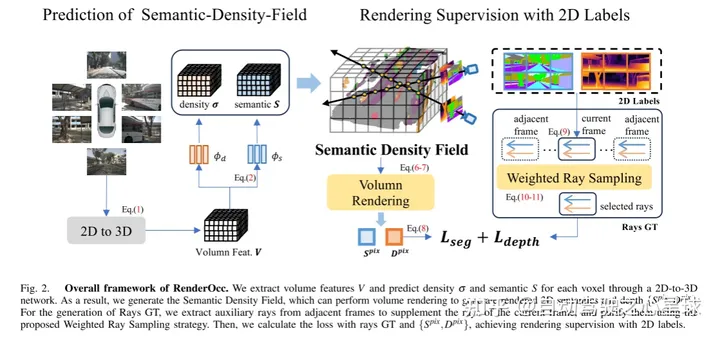
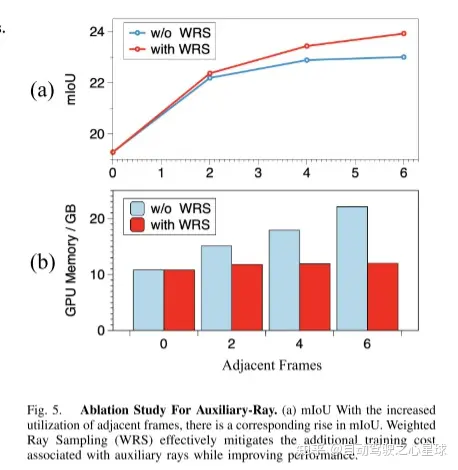
图2.RenderOcc的总体框架。本文通过 2D 到 3D 网络提取体积特征并预测每个体素的密度和语义。因此,本文生成了语义密度场(Semantic Density Field),它可以执行体积渲染来生成渲染的 2D 语义和深度。对于Rays GT的生成,本文从相邻帧中提取辅助光线来补充当前帧的光线,并使用所提出的加权光线采样策略来净化它们。然后,本文用光线 GT 和 {,} 计算损失,实现2D标签的渲染监督。
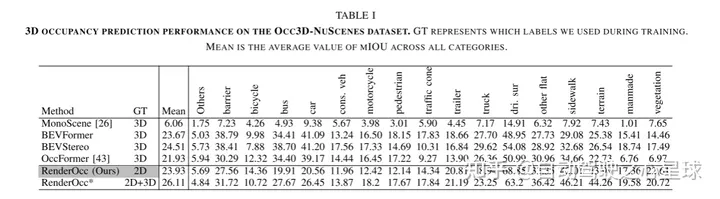
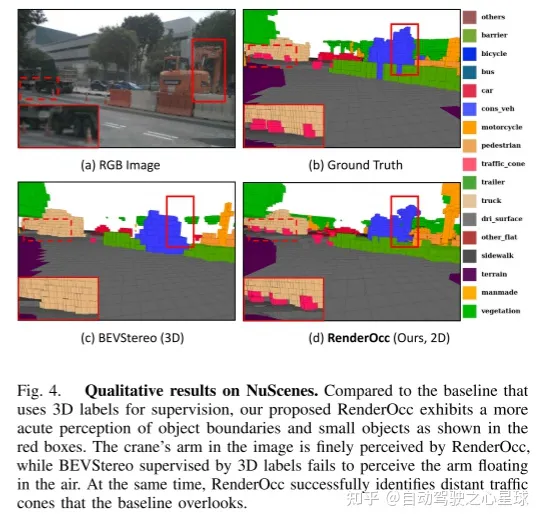
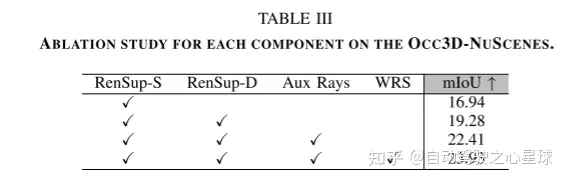
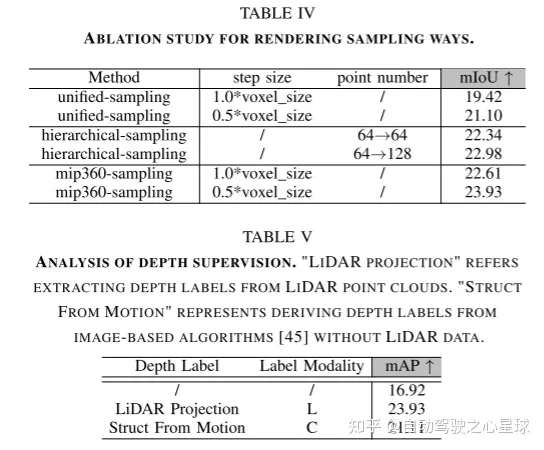
实验结果:

投稿作者为『自动驾驶之心知识星球』特邀嘉宾,如果您希望分享到自动驾驶之心平台,欢迎联系我们!
① 全网独家视频课程
BEV感知、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、协同感知、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)
 视频官网:www.zdjszx.com
视频官网:www.zdjszx.com
② 国内首个自动驾驶学习社区
近2000人的交流社区,涉及30+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(2D检测、分割、2D/3D车道线、BEV感知、3D目标检测、Occupancy、多传感器融合、多传感器标定、目标跟踪、光流估计)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多模态感知、Occupancy、多传感器融合、transformer、大模型、点云处理、端到端自动驾驶、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向。扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】平台矩阵,欢迎联系我们!


















 212
212

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









