






点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
今天自动驾驶之心为大家分享一篇基于Nerf的Occupancy相关工作,系论文一作东京大学甘万水博士(在读)投稿,如果您有相关工作需要分享,请在文末联系我们!
SimpleOccupancy的主要贡献点 (Hightlight)
较为早期提出使用体渲染进行3D occupancy表征学习的工作,早于UniOcc及其后续工作RenderOcc。
文章提出了一个框架,从网络设计,损失函数设计,以及评价指标三个方面综合讨论了使用体渲染进行occupancy估计的潜力,同时搭建了与单目深度估计方法的对比排行榜并且实现了最优的效果。
似乎是首次引入了符号距离场(SDF)进行进行3D重建任务的探讨,并且首次介绍了使用深度自监督的方法来训练,最后通过提出的离散深度指标验证了有效性。
通过提出的离散采样进行基于点级别的分类预训练,可以实现对现有语义occupancy框架的性能提升,例如SurroundOcc。
文章总体通过体渲染的方式参考Monodepth2, 完成了对驾驶场景的几何表征学习,包括深度,体素(occupancy),以及Mesh。文章对后续语义occupancy 以及驾驶场景的3D重建都有较大参考价值。
背景知识
对于驾驶场景的感知,我们不需要特别细节的场景的3D构造,因而使用离散化的几何表达可以有效节省计算资源,例如使用体素(voxel)来表达3D空间的占有(occupancy)情况。继2021年的TESLA的AI Days的鸟瞰图(BEV)感知之后,在2022年, TESLA 首先在年中CVPR 2022 Workshop 向学界展示了3D occupancy的价值,而后又在10月份的AI Days上更充分向公众展示了更多细节。3D occupancy 估计并不新鲜,先于TESLA, SemanticKITTI 数据集已于ICCV 2019 提出并得到广泛的关注。得益于TESLA大厂的认证加持,2022年之后,3D occupancy估计 在学术和工业界都吸引了从业人员的讨论和更多关注。当然,最新的热点变成了world model,world model是模型对给定当前场景的进一步的理解和推演。重要的基础就是对场景3D理解,所以本文提出的基于渲染的优化方法以及几何表达有益于world model。
文章总体框架以及对应的相关工作
文章的总体框架如下图,这里只介绍跟本文强相关的论文和代码。文章的code-based是基于surrounddepth。整个code不是基于mmdetection框架,所以较为容易理解和移植相关模块到mmdetection。

网络设计
网络结构部分较为简单(Simple), 这里重点讲解一下论文中三种最终的输出表达, 密度(density), 概率(probability)以及符号距离场(SDF)。
密度(density): 直接将最后的voxel表征为density, 每个位置经过三线性插值得到的就是那个位置的密度。也就是以下体渲染公式中的这个值 ,同时,通过以下渲染,我们将3D 空间中的密度沿着每个像素的射线,渲染得到深度图,接下来就可以进行2D平面的有监督或者自监督:

概率(probability):我们发现在有深度图监督的情况下,将density归一化到0-1会有更好的效果,同时也方便选取最佳阈值来判断空间点是否occupied。注意归一化之后文章改进了渲染方式,详见论文代码。
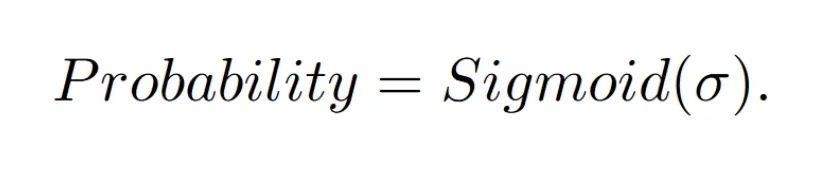
符号距离场(SDF):由于密度和概率都是难以确定场景的几何表面,为了更为细节的3D场景重建,文章也采用了符号距离场作为voxel的输出表征,然后经过以下公式转换为density,再进行体渲染。注意这个公式的转换是在体渲染的softplus激活函数之前以及 的初始值为1,听说作者调了很久才调出来。
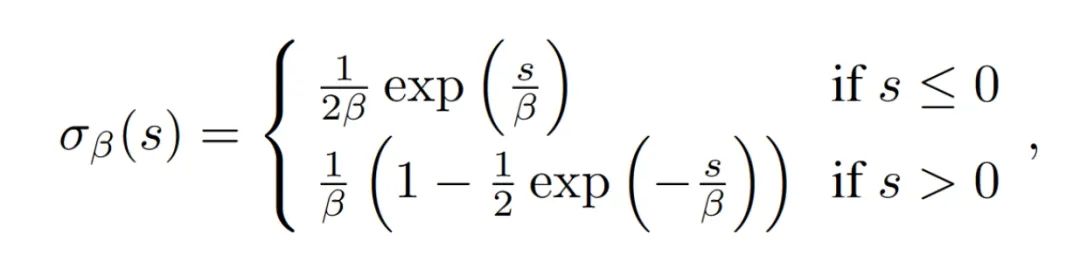
下边罗列一些实验代码参考:
本文标题和2D到3D反投影部分参考自:simple-bev, 同时,论文也做了其他两种投影方式LSS 和基于attention的query;
3D卷积网络参考自:HybridNet;
渲染部分参考自:V4D;
SDF转density参考自:Monosdf。
损失函数设计
有监督:
1) 启发于NeRF的采样,将空间的点二分为empty和occupied 点,其中empty点采样于lidar和点云之间,occupied点即为点云。使用二分类损失函数进行优化。需要注意对于不可视区域以及没有点云的区域(如天空),是优化不到的。
2) 同样启发于NeRF的采样,通过渲染的方式获取深度图,然后使用稀疏的真值深度图进行有监督。
自监督的损失函数部分参考自:Monodepth2。
评价指标
对于评价指标,本文有以下思考:
1)对于自动驾驶场景的点云较为稀疏,特别是远处的部分,如果没有人为标注融合多帧点云,获取稠密的体素(voxel)表达是不可行的。
2)对于整个3D表征空间,我们只能确定知道点云和lidar 之间的部分,对于对于不可视区域以及没有点云的区域(如天空),是没有办法进行评估的。
3)用体素(voxel)表达3D空间是一种离散的表达,一些量化误差是不可避免的,但我们可以在感知任务可接受的范围内进行评估,如0.2 米和0.4 米。
4)对于评估的真实label的构建应该尽可能的简单通用,这样方便工业界和学术研究,这也是本文的出发点之一。
基于以上考虑,我们进一步探讨了两种评价指标:一是基于关键点的分类指标,以及类似于深度估计的评估的离散深度评价指标,如下图所示。
这里我们发现分类指标不能真实反映驾驶场景的评估需求,同时我们也思考了重建指标例如Chamfer distance,但从对比图可以看出,这些指标对于以驾驶为中心的评估依然有缺陷。以驾驶为中心的评估来说,我们提出和采用的离散深度指标更为合适。
离散深度指标的评价,我们需要对于每个rays上的离散采样点,找出其第一个occupied的点(离lidar最近的点),然后计算这个点到这条ray上点云的距离作为损失距离(误差)。
具体实现上,我们需要全局的一个最佳阈值来判断空间点是empty 或者occupied。为此,对于probability的输出表达我们离散遍历[0,1]的阈值区间,对于sdf的输出表达,离散遍历的是[-0.5,0.5]的阈值区间。取出一个最佳阈值的结果为最后的评估结果。


实验设计以及结果分析
对于网络结构的消融实验主要在DDAD数据集上,因为单帧的点云,DDAD的密度比Nuscene高。对于自监督的实验以及sdf和density的对比,是在Nuscene上做的,因为DDAD的车辆的ego pose不是很准, 而对于 基于渲染的深度自监督,我们需要准确的ego pose完成图像一致性约束(photometirc loss)。其实Nuscene 也不是很准,因为其少了一个z轴的运动。但是影响不大,还是可以完成有效的自监督。
论文进行了较为详尽的实验,这里主要罗列一些主要的结论:
1)网络结构上,ResNet 101 比 50更好一点但不多,如果没有初始化ResNet的imagenet预训练权重,实验结果差很多;
2)论文对比了三种2D到3D的转换,发现最简单的基于插值的转换方式效果是最好的,其他两种计算量多一些但没有发现好处;
3)有监督的实验中,基于渲染深度的监督好于采样点分类监督。从论文中可视化渲染的深度图可以看出,特别是对于靠近天空的区域,由于采样点不能覆盖,采样点分类监督效果很差。
4)自监督实验中,基于sdf的输出表征在离散深度指标上好于probability和density,但在深度指标上三者没有太明显的差距。从可视化的mesh可以看出(论文 Fig.5),sdf的表征有更好的重建效果,结合离散深度指标也得以验证。
5)对于深度指标,文章对比了三个单目深度估计的网络,可以看到,基于渲染的方式能够实现较优的深度估计。另外,没有来自传感器的车辆姿态,从posenet中联合训练姿态估计,通过渲染的方式不能够学习到有效的深度尺度,效果差。
6)虽然本文没有涉及语义估计,在本文的框架下,采用相同的基于关键点采样的方式对这些点进行多分类监督,我们基于Surroundocc做了实验,从可视化可以看到,也是能过学习出有效的场景分布,同样的,由于靠近天空部分有没有点云,导致对于3d 体素 顶部,会出现偏向于建筑或者植被的估计,因为对于那些位置,这两者经常出现。
总结
本文提出了一个简单的占据估计框架,从网络设计,损失函数设计,评价指标三方面综合讨论了在3D 体素(voxel)的表达空间下的occupancy 估计,深度估计,以及mesh重建三者的关联。这是一个面向基础几何表达 的工作。希望对于语义occupancy以及world model的任务,有一定启发和帮助。
一些视频序列展示
RGB, Depth and Mesh:
Self-supervised learning with SDF (Max depth = 52 m )
Self-supervised learning with Density (Max depth = 52 m)
文章提出的采样点的多分类可以作为3D 语义occuapncy的预训练,可以看到不需要稠密的voxel标签,也能训练出合理的3D 语义occupancy估计:
最后
近期也有一些自监督的工作结合了语义信息,都是很优秀的工作,大家也可以关注,这里稍微罗列如下,也欢迎补充:
OccNeRF:https://github.com/LinShan-Bin/OccNeRF
SelfOcc:https://github.com/huang-yh/SelfOcc
S4C:https://ahayler.github.io/publications/s4c/
RenderOcc:https://arxiv.org/abs/2309.09502
代码已开源,欢迎大家引用,给小星星,转发,评论和讨论,非常感谢!
@article{gan2023simple,
title={A Simple Attempt for 3D Occupancy Estimation in Autonomous Driving},
author={Gan, Wanshui and Mo, Ningkai and Xu, Hongbin and Yokoya, Naoto},
journal={arXiv preprint arXiv:2303.10076},
year={2023}
}参考:
文章链接:https://arxiv.org/pdf/2303.10076.pdf
代码链接:https://github.com/GANWANSHUI/SimpleOccupancy)
投稿作者为『自动驾驶之心知识星球』特邀嘉宾,如果您希望分享到自动驾驶之心平台,欢迎联系我们!
① 全网独家视频课程
BEV感知、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、协同感知、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)
 视频官网:www.zdjszx.com
视频官网:www.zdjszx.com
② 国内首个自动驾驶学习社区
近2000人的交流社区,涉及30+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(2D检测、分割、2D/3D车道线、BEV感知、3D目标检测、Occupancy、多传感器融合、多传感器标定、目标跟踪、光流估计)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多模态感知、Occupancy、多传感器融合、transformer、大模型、点云处理、端到端自动驾驶、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向。扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】平台矩阵,欢迎联系我们!
















 377
377











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









