






点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
论文作者 | Zhenggang Tang
编辑 | 3D视觉之心
无需为场景变更训练新NeRF
NeRF通常用于表示复杂的3D场景,当场景被修改时,机器人需要重新捕获多个视图来重新训练新的NeRF。这个过程:
会丢弃原始场景中的重要信息
耗时
如图1所示,NeRFDeformer[1]期望允许通过单个RGBD图像将给定的NeRF场景变换为新的观察到的场景,即检索变换后的场景几何并从不同的视角渲染新场景。
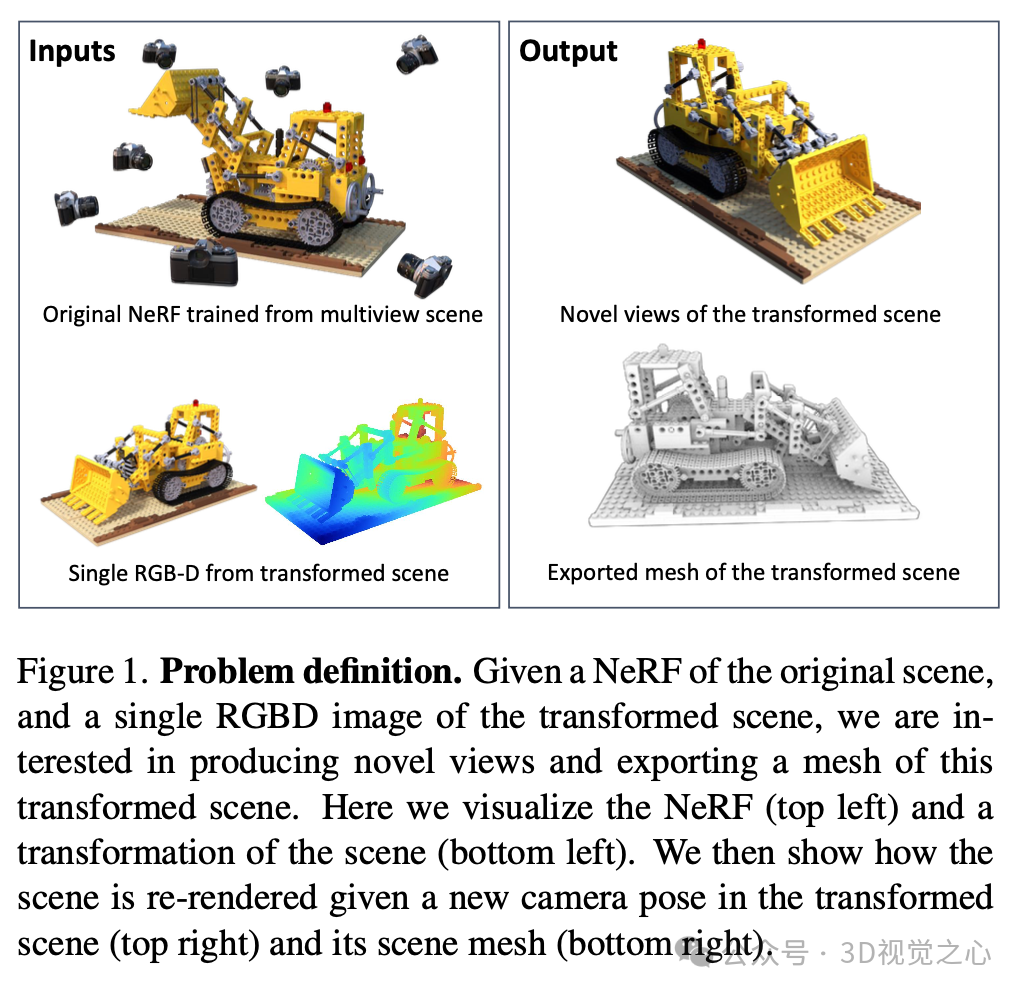
目前大多数NeRF编辑方法并没有提供自动匹配变换后场景的机制,因此需要手动定义变换(这对于非刚性变换来说并不简单)。在NeRFDeformer的问题设置中,用户输入不可用。其他成功的工作研究了通过时间进行的NeRF变换,其中时间组件被密集采样。相比之下,NeRFDeformer仅假设对变换后的场景进行一次RGBD视图的观察。尽管这种单次观测(在没有访问原始NeRF场景的情况下)可以通过预训练方法直接检索变换后的场景,但这种方法难以恢复对象的真实几何。
使用单个RGBD图像变换NeRF带来了挑战:
观察到的非刚性变换是什么?
对象的哪些部分相对应?
未见部分(在RGBD图像中不可见)是如何变形的?
受网格形状操作的启发,NeRFDeformer通过将变换建模为3D场景流来解决这个问题。该流是通过场景表面上的3D锚点进行刚性变换的加权线性混合。与先前工作中使用的基于MLP的流相比,这种定义更加灵活,可以表达一个近似的逆流。由于流的定义利用了从原始场景到变换后场景的锚点,本方法设计了一种新的稳健的基于NeRF的对应匹配方法,在像素和3D空间进行两步过滤。
开源链接:https://github.com/nerfdeformer/nerfdeformer
NeRFDeformer方法
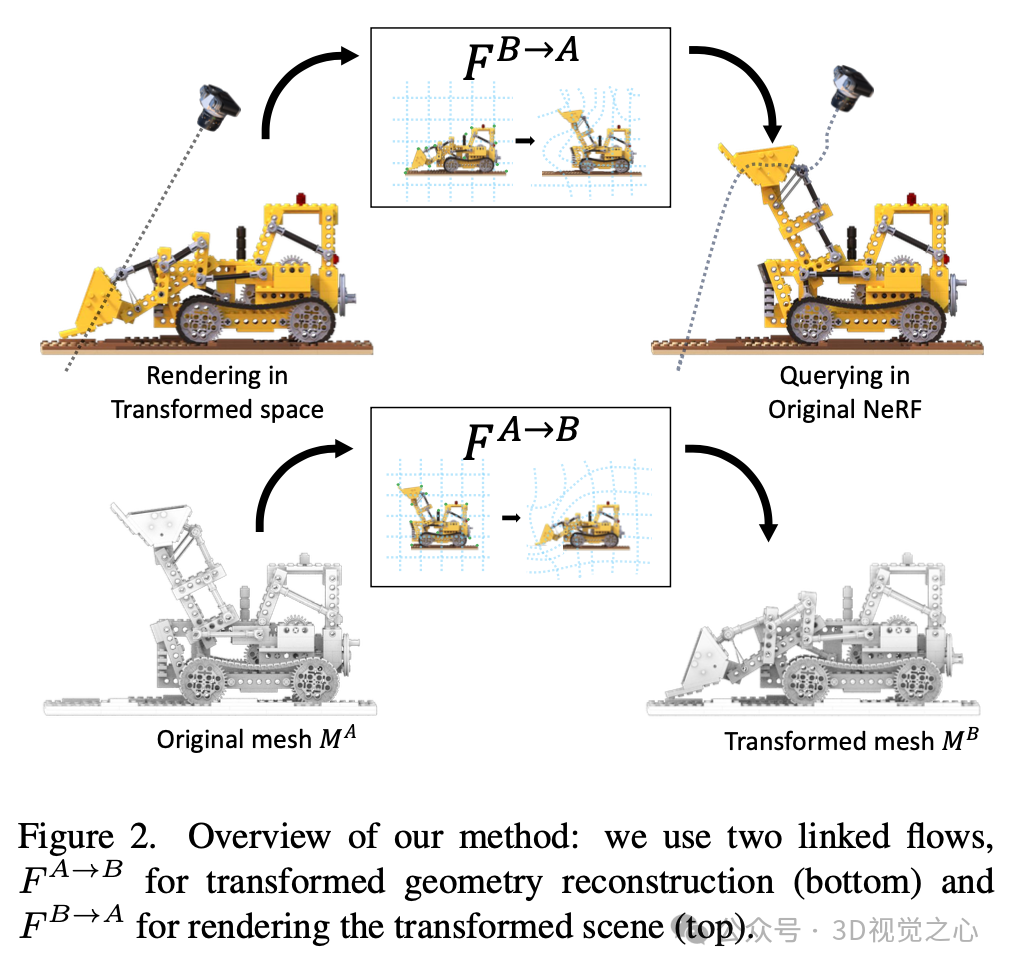
如图2,考虑一个原始场景A已经变换为场景B,目标是双重的:从新的视角渲染变换后的场景B,并提取变换后的场景几何MB。为了解决这些目标,假设具备以下条件:
一个预训练的NeRF ,可以用来从任意相机姿态渲染原始场景
一个单一的RGBD图像,从相机姿态捕捉变换后的场景
方法的核心是恢复两个场景之间的前向F 和后向F 3D场景流。
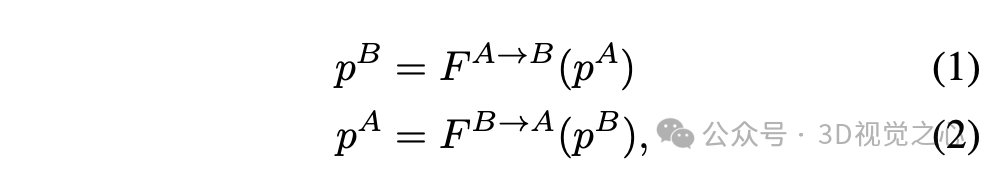
给定原始场景中的一个点 和方向 ,可以从NeRF中查询到颜色 和密度 :
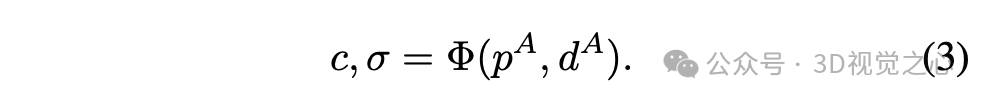
为了渲染描绘变换后场景B的新视图,在变换后场景中沿一条射线采样点 ,并应用后向3D场景流 获得对应的点 。每个点的方向 是通过沿射线的相邻点之间的变换差异计算的,以保持局部几何。这些变换后的点和方向然后被输入到原始基于NeRF的渲染中,如公式(3)所示。
同样的,网格 由顶点 和三角面 组成,通过经典的逐步立方算法从原始场景的NeRF 中获得。变换后的网格 则通过将前向流应用于所有原始顶点来获得:

通过重复使用三角面 来保留拓扑结构。因此,很明显,这两个3D场景流在新视图渲染过程中以及支持恢复变换后场景的几何结构中起着关键作用。因此,核心是恢复这些场景流。
3D 场景流作为局部刚性变换的线性混合
在这项工作中定义了前向流,将原始空间 (A) 中的任意位置 映射到变换空间 (B) 中的位置 。该映射被表述为刚性变换 ξ 的加权线性混合,这些刚性变换锚定在不同的3D点上。锚点是通过逐步立方算法从原始NeRF 中提取的三角网格 的顶点 ,如图3所示。
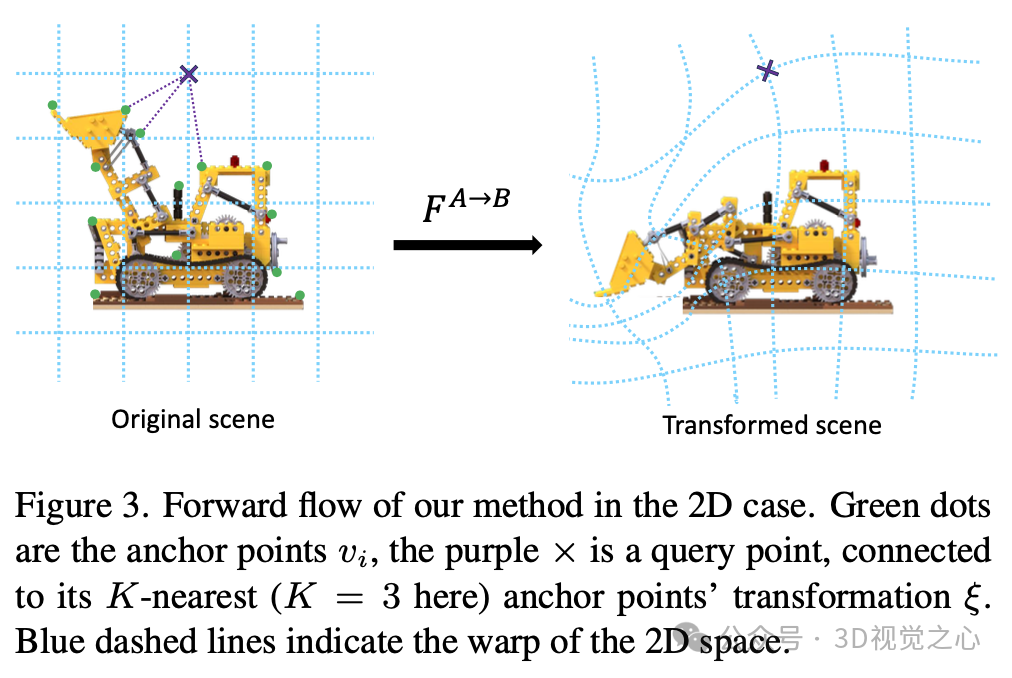
每个顶点 都有一个相关的6维刚性变换 ξ,它包含旋转 、旋转中心 和平移 ;因此,刚性变换及其逆变换的公式如下:
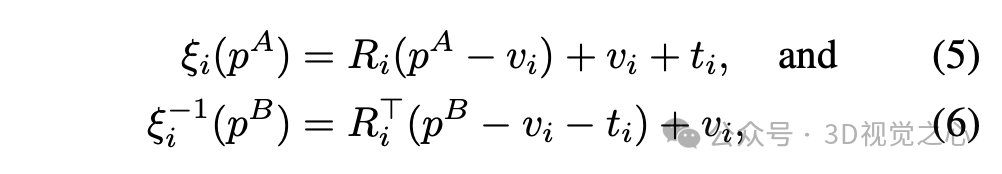
其中,每个旋转矩阵 和平移向量 可以视为依赖于对应锚点 的参数量。
3D流通过计算以下刚性变换的归一化加权和来定义,以获得变换后的点 :
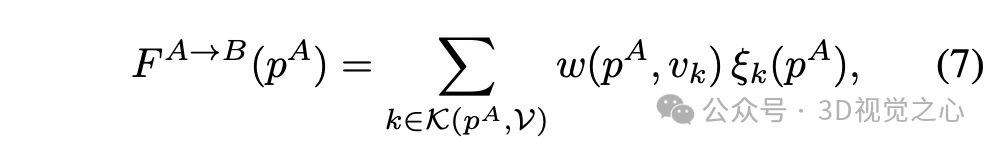
其中,求和范围是最近邻锚点的索引集合 ,返回与点 最近的 个顶点索引。每个权重定义如下:

需要注意的是,在公式(7)中,最远的邻点权重为零。后向流定义如下:
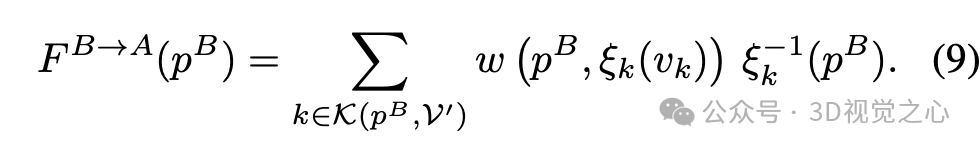
特别是,后向流使用变换后的顶点:
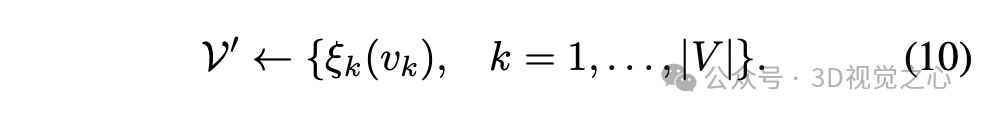
注意,根据公式(5),有 。
前向流和后向流定义相比先前工作中使用的带循环损失的MLP流有两个优势:
无需训练即可从前向流中提取后向流
前向和后向流仅在所有线性变换相似的表面区域附近是循环的。
因此无需在空旷空间中强制其循环。此外,流定义允许在远离表面区域时提供额外的灵活性,同时鼓励在表面区域附近的循环行为,这对于准确的几何重建和新视图合成是必要的。
场景流优化的嵌入式变形图
为每个锚点 查找并参数化旋转矩阵 和平移向量 。通过优化损失函数
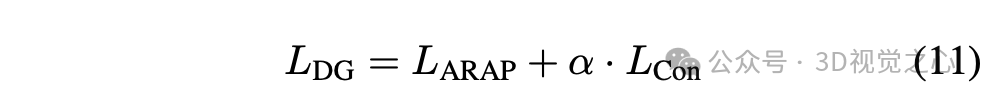
来学习变换组件 和 。其中:
ARAP损失 :正则化两个变换组件
一致性损失 :通过3D对应点学习平移项
ARAP损失应用于简化后的网格以提高计算效率。在实践中,当调用变换时,参数化函数 和 是通过在简化网格顶点上定义的可学习旋转矩阵和平移向量的加权组合计算的。该计算是可微的,因此可以端到端训练。ARAP损失正则化每个锚点顶点变换应用于其邻居时的平方距离与实际变换后邻居位置之间的距离。
一致性损失 约束具有对应点的顶点的平移。为了对变换进行约束,首先识别场景A和B之间的一组对应点。设集合 表示具有对应关系的顶点索引。因此有以下对应点集合:。选择这些点的过程在下文中描述,一致性损失定义如下:
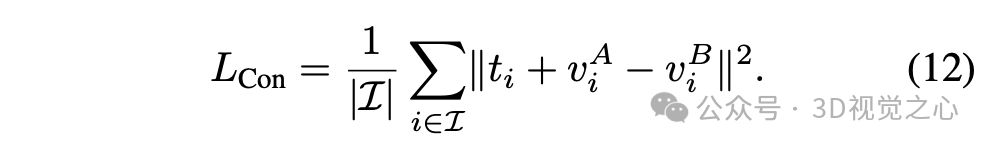
请注意,这里不使用旋转矩阵 ,因为在操作3D顶点,因此不需要旋转来变换它们。此外,不使用任何直接的视觉损失(RGB或深度),因为合理密集的对应点足以学习3D流。
稳健的基于NeRF的对应匹配
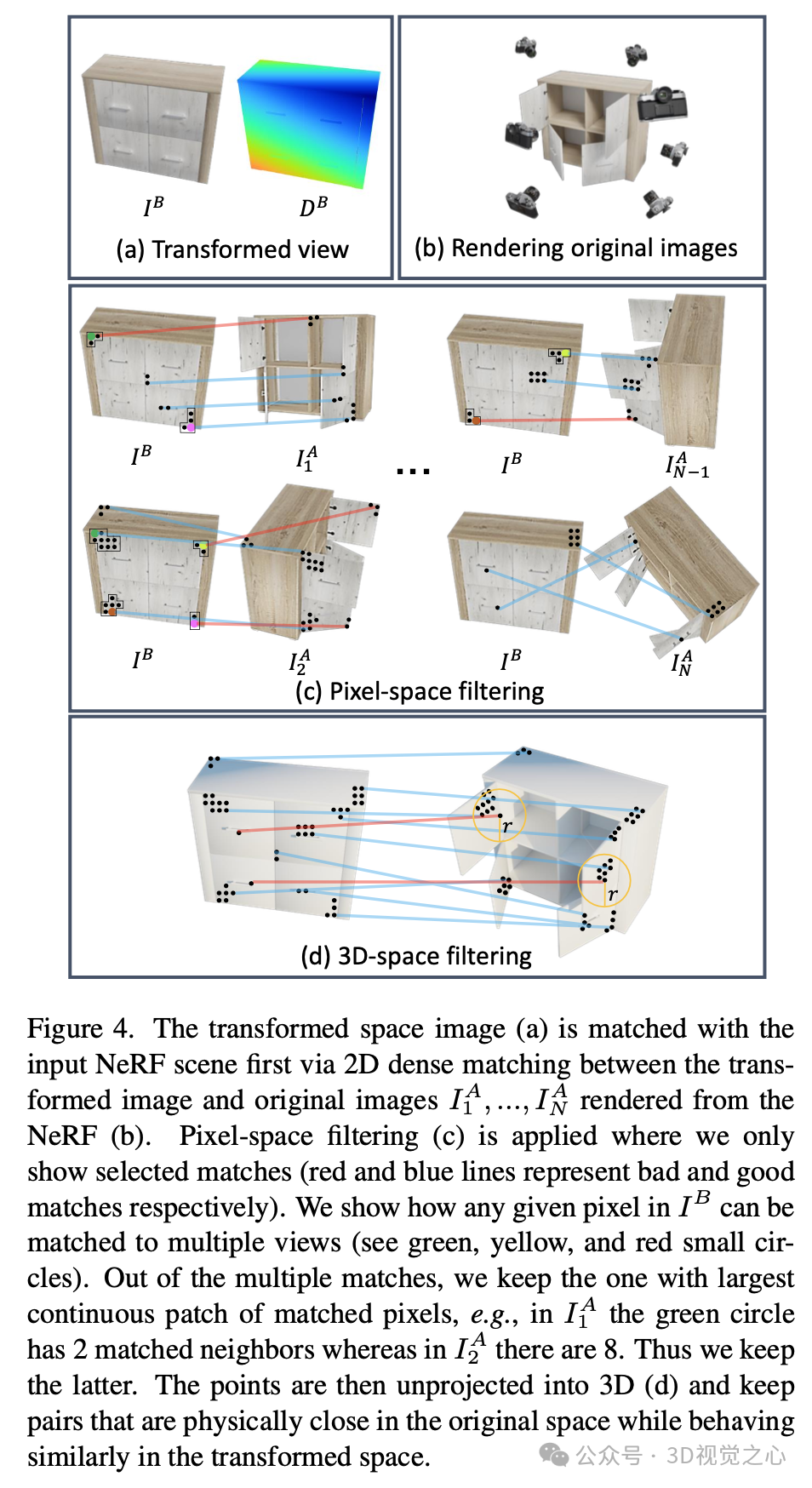
我们旨在生成原始NeRF场景和变换后的场景(由单个RGBD图像表示)之间的可靠对应关系,如图4(a)所示。受ASpanFormer工作的启发,首先在变换后的RGB组件和原始NeRF生成的渲染图像之间找到基于RGB的对应关系,并在像素空间进行初步过滤。最后,将像素对应提升到3D空间,并在3D空间中过滤误匹配。
2D对匹配与过滤
首先,从提供的NeRF渲染一组覆盖对象半球的图像(图4(b))。使用ASpanFormer在变换后的图像和我们的RGB NeRF渲染图像之间进行密集的RGB匹配,并过滤掉低置信度的对应关系。为了处理变换后的图像与不同渲染图像之间的多重匹配(给定像素可能匹配多个图像中的位置),从中选择置信度最高的一对。该置信度由像素邻域密度大小决定,例如,更多相邻像素匹配的数量越多,匹配越可能有效(图4(c))。
3D空间过滤
使用前述的像素对应关系,通过提供的深度信息将其位置提升到3D空间。为了确定哪些对应对是有效的,首先在原始场景中对点进行聚类,然后比较这些聚类在变换后的场景中的行为(图4(d))。如果一个聚类未能保持其紧凑结构,则过滤掉偏离的点。其直觉如下:在原始场景中相邻的点对在变换后的场景中应该保持相邻。
为了定义锚点 ,对于原始空间中任何有效对的点,我们找到在网格上提取的最近顶点。然后将这个锚点与其在3D空间中的对应点连接。最终,这些锚点匹配用于优化我们的3D流,如前所述。
实验效果

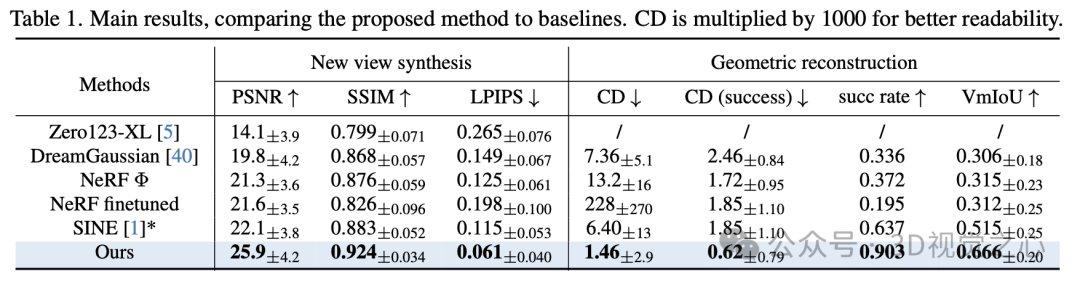
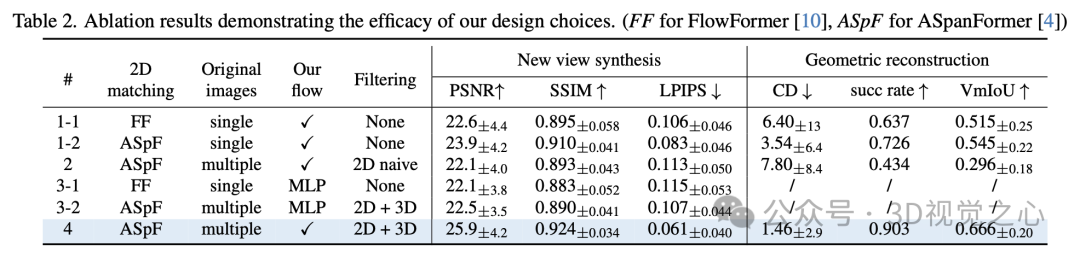

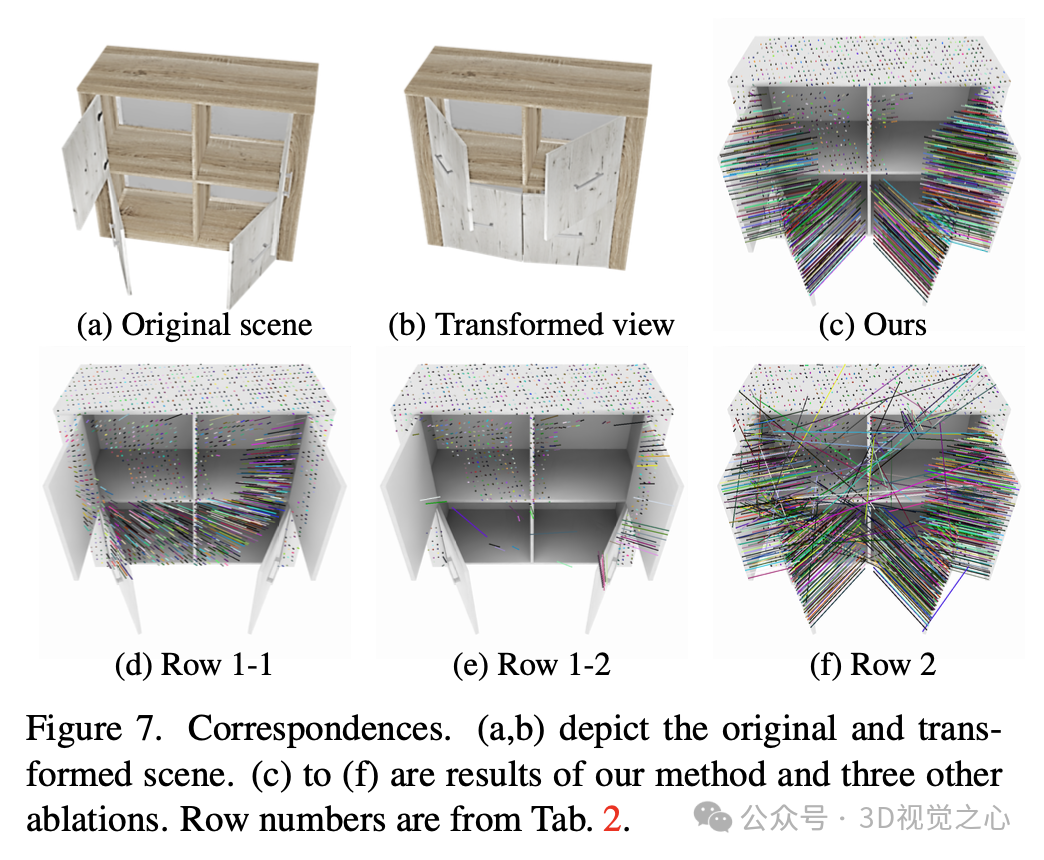
总结一下
NeRFDeformer成功地利用单次RGBD观测来变换NeRF场景。该方法使用局部线性变换在表面上将原始配置映射到变换后的配置。为了学习这些线性变换,引入了一种新的方法来在NeRF场景和单次RGBD观测之间找到密集的对应关系。
未来方向:
探索放宽对深度输入的需求,例如通过利用关于形状或场景组成的先验知识
通过场景流接地扩散模型以帮助确定生成应集中在哪些地方
参考
[1] NeRFDeformer: NeRF Transformation from a Single View via 3D Scene Flows
投稿作者为『自动驾驶之心知识星球』特邀嘉宾,欢迎加入交流!
① 全网独家视频课程
BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、大模型与自动驾驶、Nerf、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)
 网页端官网:www.zdjszx.com
网页端官网:www.zdjszx.com
② 国内首个自动驾驶学习社区
国内最大最专业,近3000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型、端到端等,更有行业动态和岗位发布!欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦感知、定位、融合、规控、标定、端到端、仿真、产品经理、自动驾驶开发、自动标注与数据闭环多个方向,目前近60+技术交流群,欢迎加入!扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】全平台矩阵

















 2548
2548

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









