






点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
编辑 | 自动驾驶之心
写在前面&个人理解
自动驾驶技术的进步需要越来越复杂的方法来理解和预测现实世界场景。视觉语言模型(VLMs)正作为具有显著潜力影响自动驾驶的革命性工具而崭露头角。本文提出了DriveGenVLM框架,用于生成驾驶视频并利用VLMs进行理解。为实现这一目标,采用了一种基于去噪扩散概率模型(DDPM)的视频生成框架,旨在预测现实世界中的视频序列。随后,利用一种称为“基于第一人称视频的高效上下文学习”(EILEV)的预训练模型,探索了生成的视频在VLMs中使用的充分性。该扩散模型使用Waymo开放数据集进行训练,并通过FVD评分进行评估,以确保生成视频的质量和真实性。EILEV为这些生成的视频提供了相应的叙述,这可能在自动驾驶领域带来益处。这些叙述可以增强对交通场景的理解,辅助导航,并提高规划能力。DriveGenVLM框架中将视频生成与VLMs相结合,标志着在利用先进AI模型解决自动驾驶复杂挑战方面迈出了重要一步。
当前领域背景概述
自动驾驶领域中将先进的预测模型集成到车辆系统或交通系统中,对于提高安全性和效率变得越来越关键。在众多的传感技术中,基于camera的视频预测脱颖而出,成为了一个核心组成部分,它提供了动态且丰富的现实世界数据源。通过采用前沿的扩散模型方法,本研究不仅促进了自动驾驶技术的发展,还为在提升车辆安全性和导航精度方面应用预测模型设立了新的基准。
目前,AI生成的内容是计算机视觉和人工智能领域的主要研究方向之一。由于内存和计算时间的限制,生成逼真且连贯的视频是一个具有挑战性的领域。在自动驾驶领域,从车辆前置camera预测视频尤为重要,这在自动驾驶和高级驾驶辅助系统(ADAS)的上下文中尤为关键,本文利用车辆周围camera的视频来预测未来的帧。
生成模型也已被应用于交通和自动驾驶领域,这些模型因其理解驾驶环境的能力而越来越受到认可。目前,视觉语言模型(VLMs)正被用于自动驾驶应用。为了提高VLMs的实用性并探索生成模型在VLMs中视频内容的应用,验证生成模型的预测以确认其在现实场景中的相关性和准确性至关重要。DriveGenVLM引入了上下文中的VLM作为一种方法,通过提供驾驶场景的文本描述来验证基于扩散的生成模型预测的视频。
扩散模型是一类深度生成模型,其特点主要包括两个阶段:(i)前向扩散阶段,其中初始数据通过在多个步骤中添加高斯噪声而逐渐被破坏;(ii)反向扩散阶段,其中生成模型旨在通过逐步学习反转扩散过程来从添加噪声的版本中重建原始数据,逐步进行。去噪扩散概率模型(DDPM)是一种常见的生成模型类型,旨在通过扩散过程学习和生成特定的目标概率分布。DDPM已被验证比传统的生成模型(如GANs和VAE)更为有效。
生成长视频需要大量的计算资源。一些工作通过基于自回归的模型克服了这一挑战。然而,自回归模型可能导致不现实的场景转换和长视频序列中的持续不一致性,因为这些模型缺乏从更长片段中同化模式的机会。为了克服这一点,MCVD 采用了一种训练方法,通过独立且随机地屏蔽所有先前或后续帧来为各种视频生成任务准备模型。同时,FDM 引入了一个基于扩散概率模型(DDPMs)的框架,该框架能够生成扩展的视频序列,并在不同设置下实现现实且连贯的场景完成。NUWAXL 介绍了一种“扩散之上的扩散”架构,旨在通过“粗到细”的方法生成扩展视频。
近年来,基于文本的大型语言模型(LLMs)的受欢迎程度急剧上升。此外,在自动驾驶领域还引入了各种生成式视觉语言模型(VLMs)。提出了RAGDriver ,以利用上下文学习来实现高性能、可解释的自动驾驶。我们利用EILEV 的上下文学习能力来生成驾驶场景的描述。在DriveGenVLM中,上下文VLMs使我们能够处理由扩散框架预测的视频,这些视频随后可以被其他基于视觉的模型识别,从而可能为自动驾驶中的决策算法做出贡献。据我们所知,DriveGenVLM是首个将视频生成模型和视觉语言模型(VLM)集成到自动驾驶领域的工作。
主要有那些创新点?
将条件去噪扩散概率模型应用于驾驶视频预测领域;
在Waymo开放数据集的不同camera角度下测试视频生成框架,以验证其在现实世界驾驶场景中的可行性。
利用上下文视觉语言模型生成预测视频的描述,并验证这些视频是否可应用于基于视觉语言模型的自动驾驶。
一些基础预备知识
1)DDPM
去噪扩散概率模型(Denoising Diffusion Probabilistic Model, DDPM)是一种在机器学习和计算机视觉领域备受关注的生成模型。DDPM通过一个前向过程将数据转换为噪声,以及一个后向过程从噪声中重建原始数据来工作。前向过程的目标是将任何数据转换为基本先验分布,而后续的目标则是开发转换核以撤销这种转换。为了生成新的数据点,首先从先验分布中抽取一个随机向量,然后通过反向马尔可夫链进行祖先采样。这种采样技术的关键在于训练反向马尔可夫链以准确复制前向马尔可夫链的时间反向进程。
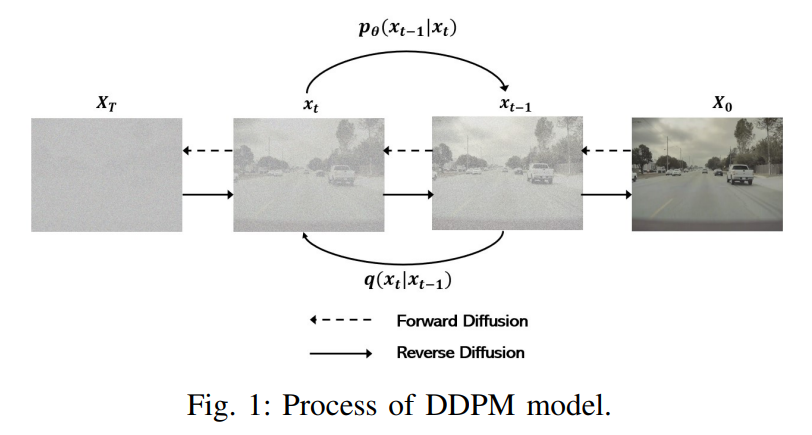
对于条件扩展,其中建模的x依赖于观测值y。给定数据分布x0 ∼ q(x0),前向过程生成一系列随机变量x1, x2,..., xT。x0表示原始的无噪声数据,而x1则包含了少量的噪声。这个过程一直持续到xT,此时xT几乎与x0无关,并且类似于从单位高斯分布中抽取的随机样本。xt的分布仅依赖于xt−1,转移核是:
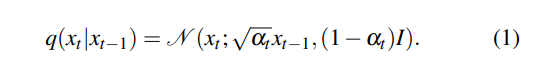
联合分布由等式2中的扩散过程和数据分布q(x0, y)定义。
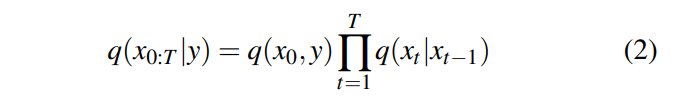
将这些模型称为扩散概率模型(Diffusion Probabilistic Models,DPMs),这些模型通过反转扩散序列来工作。对于给定的xt和y,我们使用神经网络来估计θ,作为的近似。这个估计使我们能够通过从标准高斯分布中采样开始来获取的样本,这是因为扩散过程的初始状态类似于高斯分布。随后,我们通过θ从迭代地向后采样到。在给定y的条件下,采样得到的x0:T的联合分布可以表示为:
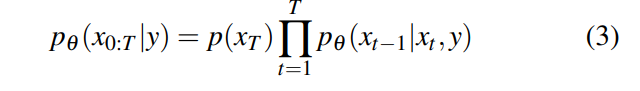
在这里,表示与θ无关的单位高斯分布。训练条件DPM涉及调整θ,以使其在全范围的t、和y值上与紧密匹配。
2)在视觉语言模型(VLMs)上的上下文学习
In-context学习最初在GPT-3的论文中提出,它指的是模型能够在单次交互中根据提供的上下文学习或调整其响应的能力,而无需对其基础模型进行任何显式更新或再训练。
这里采用了EILEV,这是一种训练技术,旨在增强第一人称视频中的视觉语言模型(VLMs)的上下文学习能力。如图3所示,EILEV在交错上下文-查询场景下的架构涉及使用来自BLIP-2的未修改视觉transformer来处理视频片段。得到的压缩标记与初始上下文-查询实例序列中的文本标记混合。然后,将这些组合标记输入到BLIP-2的静态语言模型中,以生成新的文本标记。该方法可以泛化到分布外的视频和文本,以及通过上下文学习罕见的动作。我们利用预训练模型为驾驶视频生成语言叙述,以验证生成的结果是否可解释且现实。
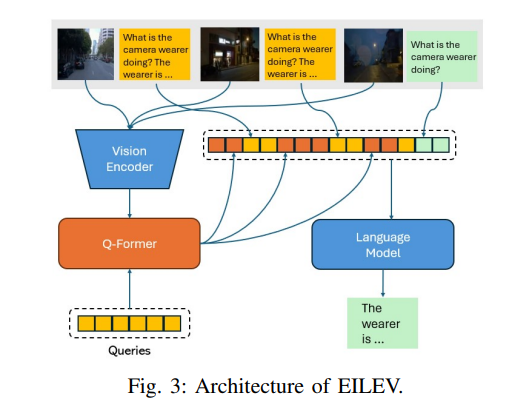
DriveGenVLM方法
生成长时间、连贯且逼真的视频仍然是一个挑战。灵活扩散模型(Flexible Diffusion Model, FDM)通过使用条件生成模型来解决这个问题。在DriveGenVLM中,采用了类似的方法。为了采样具有大量帧的连贯视频,可以使用生成模型在少量帧的条件下采样任意长度的视频。我们的目标是在一些帧的条件下,采样出连贯且逼真的驾驶场景视频。这里采用了一种顺序程序,通过生成模型来采样任意长度的视频,该模型一次只能采样或基于少量帧进行条件处理。
广义上,我们将采样方案定义为一系列元组,其中每个元组由一个向量组成,表示要采样的帧的索引,以及一个向量,表示在阶段s = 1,...,S中用作条件的帧的索引。
1)训练框架
DDPM图像框架采用了U-net结构。该架构的特点是一系列层,这些层首先降低空间维度,然后再进行上采样,其间穿插着卷积残差网络块和专注于空间注意力的层。
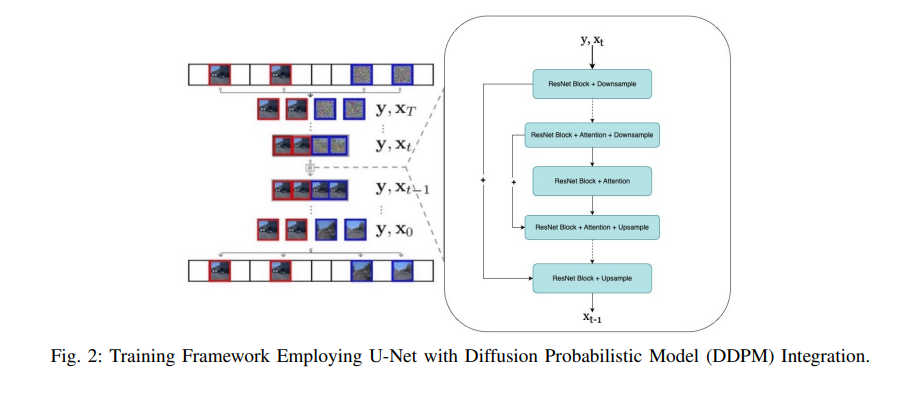
该架构如图2所示。DDPM迭代地将噪声XT转换为视频帧X0。带有红色边框的框表示条件。右侧显示了每个DDPM步骤的UNet架构。

算法1展示了如何使用采样方案来采样视频。生成模型可以根据视频帧的其他子集来采样任何子集。模型可以生成任何选择的X和Y。
2)Sampling Schemes
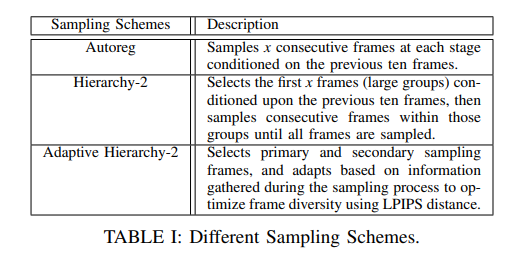
每种采样方案的相对效率在很大程度上取决于手头的数据集,且没有普遍最优的选择。在本文中,尝试了三种采样方案,如表I所示。第一个也是最直接的方案是Autoreg,它通过在每个步骤中对前十个帧进行条件设置来采样十个连续帧。另一个方案是Hierarchy2,它采用多层采样方法,第一层有十个等距选择的帧,覆盖视频中未观察到的部分,这些帧以十个观察到的帧为条件。在第二层中,以组为单位连续采样帧,同时考虑最近的先前帧和后续帧,直到所有帧都被采样。最后使用了Adaptive Hierarchy-2(Ad),这只能通过实现FDM来实现。Adaptive Hierarchy-2在测试期间战略性地选择条件帧,以优化帧多样性,这通过它们之间的成对LPIPS距离来衡量。
实验对比分析
1)数据集
Waymo-open数据集是一个广泛应用的数据集,它利用多种传感器来辅助自动驾驶技术的进步。该数据集包含来自Waymo自动驾驶汽车群组的高质量传感器数据,并由超过1000小时的视频组成。这些视频是通过各种传感器拍摄的,如激光雷达、雷达和五个camera(前后及侧面),它们始终提供汽车周围的完整视图,即我们所说的360度视野。这组数据有着非常细致的标注,包括车辆、行人、骑自行车者以及道路上其他物体的标记。这使得它对于该领域的研究人员或工程师来说非常有用,可以帮助他们提升自动驾驶汽车中的感知(理解)、预测(猜测接下来会发生什么)和模拟算法的技能。数据集V2格式旨在与Apache Parquet文件格式及其支持的组件一起使用。在这里,组件是一组相关的字段/列,它们是理解每个单独字段所必需的。
2)实验设置
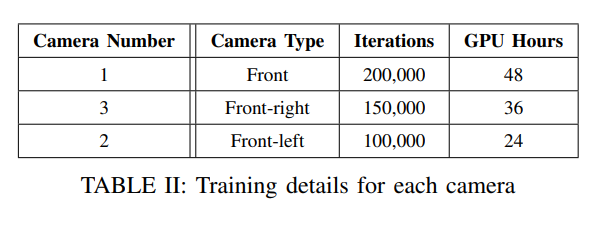
为了验证算法在真实驾驶场景中的有效性,利用了Waymo开放数据集,该数据集涵盖了多个城市的不同真实世界环境。我们从数据集中提取了所有五个现有camera的数据。然后对数据集进行了预处理,并从三个camera(前camera、前左camera和前右camera)中提取了数据,总共处理了138个视频。其中,包含所有三个camera的108个视频被平均分配用于训练,而每个camera各有10个视频用于测试集。训练视频中发现的最大帧数为199帧,最小帧数为175帧左右。因此,将所有视频的帧数限制为175帧,分辨率降低到了128×128,并转换成了4D张量。
该模型在Debian GNU/Linux 11系统上运行,该系统配备了8核Intel Cascade Lake处理器和具有24GB内存的NVIDIA L4 GPU。我们使用了bs大小为1、学习率为0.0001的设置。每个camera训练的详细信息如表II所示。前camera是从头开始训练的,没有使用任何预训练权重,迭代了200,000次。前右camera使用了来自camera1的预训练权重,并训练了150,000次迭代,而前左camera则使用了来自camera3的预训练权重,训练了100,000次迭代。总共花费了108个GPU小时进行训练。
利用FVD(Frechet视频距离)评估,这是一种用于评估模型在视频生成或未来帧预测等任务中生成的视频质量的度量标准。类似于用于图像的Frechet Inception Distance(FID),FVD衡量生成视频分布与真实视频分布之间的相似性。FVD对于评估视频的时间一致性和视觉质量非常有用,因此它是视频合成模型基准测试的一个宝贵工具。
3)结果
表III、表IV和表V总结了我们在Waymo开放数据集上对三个camera进行实验得到的FVD分数,这些实验采用了不同的采样方案。结果表明,自适应层次-2采样方法优于其他两种方法。
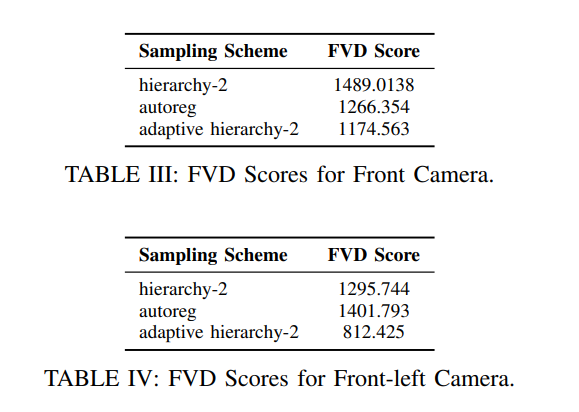
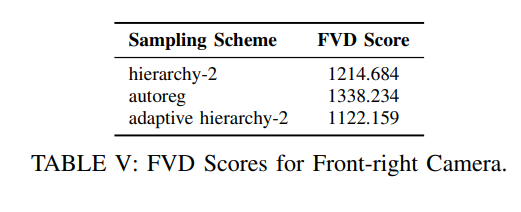
图4-6展示了使用自适应层次-2采样方案(产生最低FVD分数)为每个camera生成的预测视频。每个子图包含每个camera生成的2个视频示例。带有红色边界框的帧是真实帧,预测帧位于每个对应帧的下方。生成的视频以每个示例的前40帧为条件。



FDM在Waymo数据集上的训练展示了其在连贯性和逼真度方面的能力。然而,它仍然难以准确解释现实世界驾驶中的复杂逻辑,如交通和行人的导航。这种局限性很可能是由于现实场景中存在的额外挑战,这些挑战在模拟环境中是不存在的。
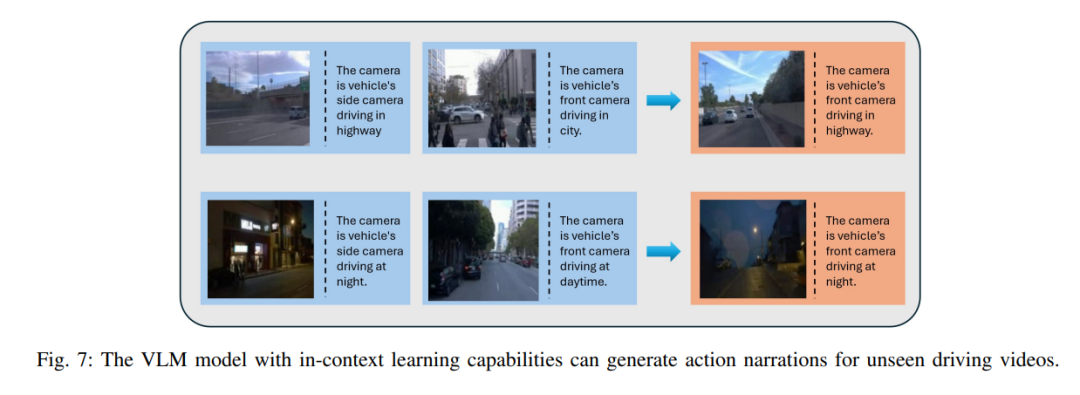
为了验证我们生成的视频是否可解释且可用于视觉语言模型,我们在Ego4D数据集上使用了预训练的EILEV模型,即eilev-blip2-opt-2.7b ,来测试我们生成的驾驶视频。我们利用了描述camera角度、驾驶环境和一天中时间的视频片段和文本对。结果如图7所示。模型生成的动作叙述显示在橙色框中。值得注意的是,前两个视频中没有共享任何动词和名词类别组合,如蓝色框所示。我们可以观察到,模型能够识别出车辆正在高速公路上行驶,且摄像头位于前方。对于第二个视频,模型识别出车辆正在夜间使用前置摄像头行驶。在VLMs上进行上下文学习预训练的模型与生成的模型配合良好,表明这些视频是可解释的,并且有可能被基于VLMs的算法所使用。
参考
[1] DriveGenVLM: Real-world Video Generation for Vision Language Model based Autonomous Driving.
投稿作者为『自动驾驶之心知识星球』特邀嘉宾,欢迎加入交流!重磅,自动驾驶之心科研论文辅导来啦,申博、CCF系列、SCI、EI、毕业论文、比赛辅导等多个方向,欢迎联系我们!

① 全网独家视频课程
BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、大模型与自动驾驶、Nerf、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)
 网页端官网:www.zdjszx.com
网页端官网:www.zdjszx.com
② 国内首个自动驾驶学习社区
国内最大最专业,近3000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型、端到端等,更有行业动态和岗位发布!欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦感知、定位、融合、规控、标定、端到端、仿真、产品经理、自动驾驶开发、自动标注与数据闭环多个方向,目前近60+技术交流群,欢迎加入!扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】全平台矩阵

















 780
780

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









