







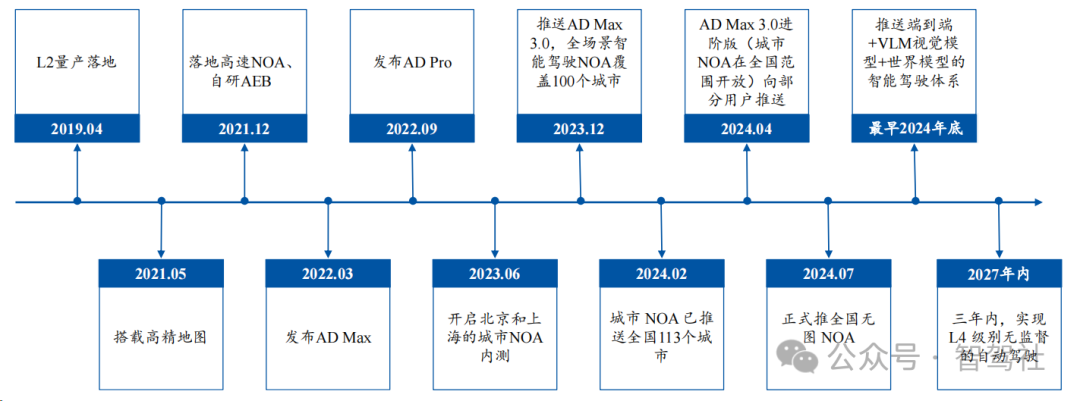
1、 无图 NOA 全量推送,向 One Model 进发
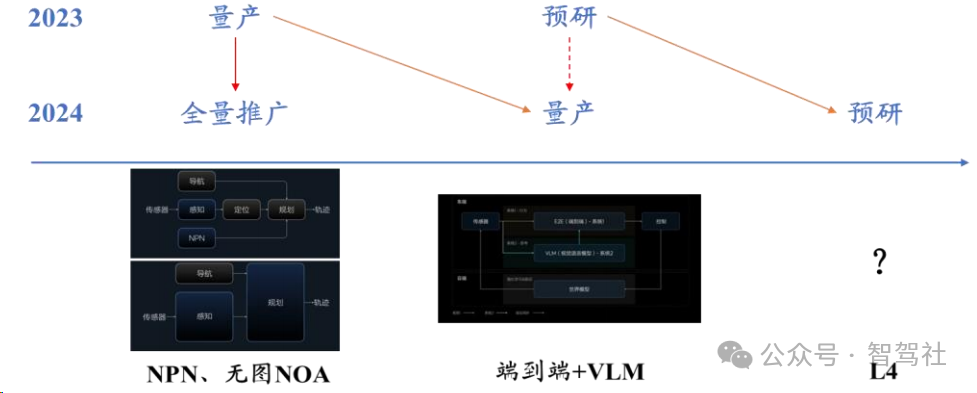
理想全国无图 NOA 全量推送实现快速追赶。理想 2021 年开始自研自动驾驶,并于2021 年 12 月落地高速 NOA 功能,进展处于国内领先水平,而蔚来、小鹏分别在 2020年 10 月、2021 年 1 月落地高速领航功能,比理想进展快 14 个月与 11 个月,理想的自动驾驶起步相对较晚。在之后的自动驾驶竞争中,焦点也由“0 到 1”的功能落地转向“1 到 10”的开城:小鹏于 2022 年 9 月国内首发城市 NGP 功能,打响城市领航辅助功能落地第一枪,极狐、阿维塔、问界等玩家纷纷跟进。理想紧跟 NOA 开城浪潮,在 2023 年 4 月宣布“年底前完成 100 个城市的落地推送”,实现自动驾驶领域的快速追赶。此后理想自动驾驶加速迭代,算法从传统模块化架构演进至分段式端到端,并向 One Model 演进;在功能上,理想于 2024 年 7 月全量推送全国无图NOA,并计划三年内实现 L4 级别的无监督自动驾驶。
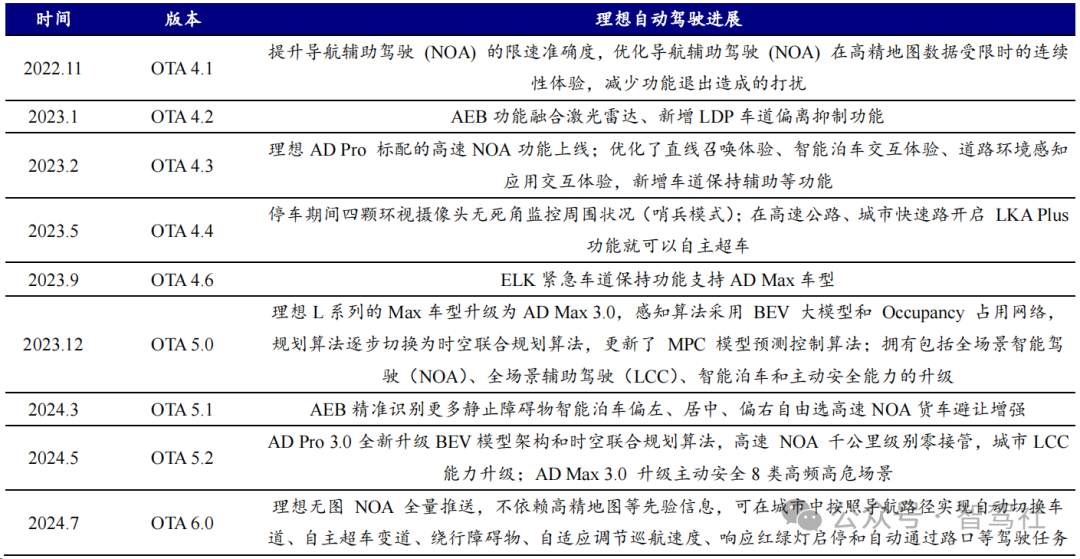
自动驾驶成为“一号工程”,分段式端到端架构支撑理想无图 NOA 快速上线。在汽车智能化愈发受到重视的当下,理想已经将自动驾驶开发摆在显著地位。2023 年 6月,理想在首届家庭科技日上透露其自动驾驶的细节,在感知算法层面采用采用 BEV大模型、使用 Occupancy 网络、自研神经先验网络(NPN)、训练端到端的信号灯意图网络(TIN)提高感知准确度,在规控算法层面应用了模仿学习的方法,持续迭代规控模型,意味着 AD 自动驾驶进入大模型时代,在 AI 大模型算法下,理想做到不依赖高精度地图的百城 NOA 推送。在使用 NPN 算法以轻图方式推进百城的同时,理想双线并进,在 2023 年 10 月预研基于分段式端到端架构的无图 NOA,只有感知、规划与导航三个模块,其中感知与规划均模型化,中间使用规则串行。在该架构下,理想于 2024 年 7 月全量推送无图 NOA。

以自动驾驶重构核心竞争力,理想智驾赢得用户认可,渗透率快速攀升。将自动驾驶开发摆在显著地位的理想,在功能实现突破后,也让用户选择智驾车型的热情水涨船高。据钛媒体数据,理想无图 NOA 发布后,AD Max 选配率显著升高:在到店试驾环节,用户 NOA 试驾占比从 5 月 23.8%提升到 7 月 46.5%,翻倍提升,用户考虑购车时更愿意了解体验理想的智能驾驶;在购车环节,用户选购 AD Max 的定单占比从 5 月份的 37%提升至 7 月份的 49%。单车型来看,7 月,理想 L9 车型 75%的用户选购 AD Max,理想 L8 达到 56%,理想 L7 达到 65%,L6 也有 22%,在北上广深,理想智驾车型的比例已经达到 70%,表明理想的智驾功能正在得到越来越多用户的认可。根据理想的数据显示,面向 AD Max 车型的无图 NOA 的升级覆盖的用户数量超 24 万,随着智驾功能在用户购车需求中的权重不断上升,重构核心竞争力的理想有望在智能化的竞争中维持领先。
2、 端到端+VLM+世界模型,理想自动驾驶迎来“尤里卡”时刻
2.1、 端到端+VLM 构成快慢系统,最早 2024 年底推出
人类思考包含快系统(系统 1)和慢系统(系统 2)。诺贝尔经济学奖得主,心理学家 Daniel 在《思考,快与慢》中指出人类的思考有两种方式,“系统 1”是快速的、本能的、自动的、情绪化的、潜意识的、条件反射的;“系统 2”是缓慢的、刻意的、逻辑的、缜密细致的。大脑通常把很多身体运动相关的功能交给系统 1 来处理,比如一些本能行为,皮肤的烫伤,迎面飞来的物体,需要我们尽可能快的速度做出反应;而语言等抽象能力被大脑交给了系统 2 的新大脑皮层,这里可以处理非常复杂的问题,并且有强可塑性。正常驾驶员开车过程中 95%的时间使用系统 1,5%的时间使用系统 2,所以人不需要每天学习 Corner Case 就能够学会开车。
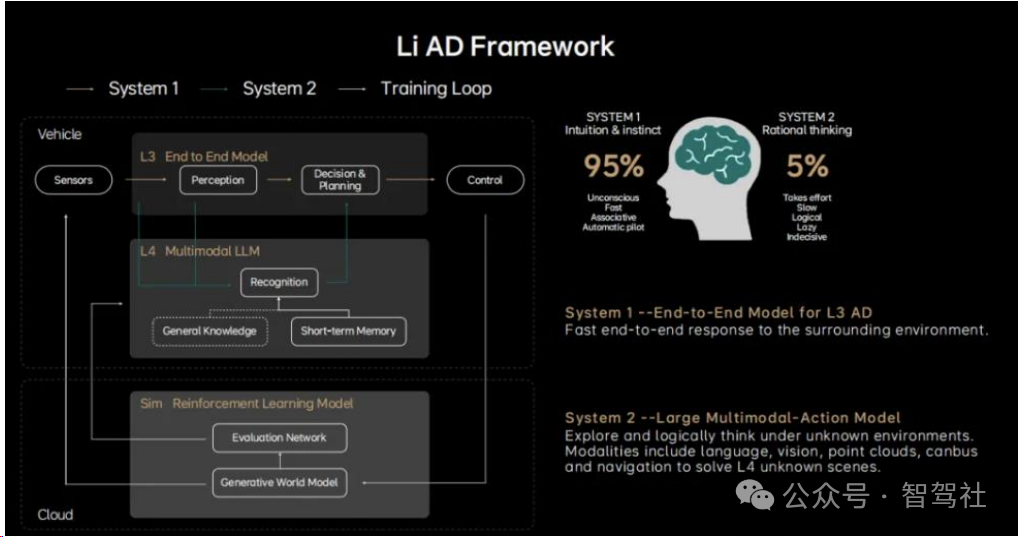
在理想的自动驾驶开发框架中,也具有快慢系统。快系统(系统 1)偏直觉,用以处理大部分常规场景,类似肌肉记忆的应激反应来处理一些直觉、快速响应的事情,在驾驶场景中可以直观理解为传感器看到场景紧接着车来做出决策和动作;慢系统(系统 2)偏思考,负责未知场景或者是复杂场景处理,解决各种复杂路况,解决泛化的问题、未知的问题。系统时时刻刻在运行,并输出两个决策,系统 1 发挥主要的作用,系统 2 会在复杂场景中起到参考或者咨询的作用,增强系统 1 的决策。
系统 1 为端到端模型,年内实现由感知到规划的统一。在端到端架构下,能够实现高效的信息传递,减少信息损失;能够实现高效的计算,一次性完成推理的延迟更低;能够实现高速的迭代,在数据驱动下做到周级甚至是亚周级的迭代。在理想的架构中,系统 1 是一个端到端的模型,输入的是传感器数据、自车的状态信息以及导航信息,输出动态障碍物、道路结构、通用障碍物 OCC 以及规划好的行驶轨迹。端到端的最终目的是为了将传感信息映射为行驶轨迹,另外动态障碍物、道路结构、通用障碍物 OCC 的输出是为了描绘周边环境并且通过环境信息显示呈现给用户,同时作为端到端模型的辅助监督。在系统 1 方面,理想称通过 100 万个 Cilps 进行训练,大概一个月经过十轮左右的训练,基本就可以完成一个无图 NOA 的上限水平。
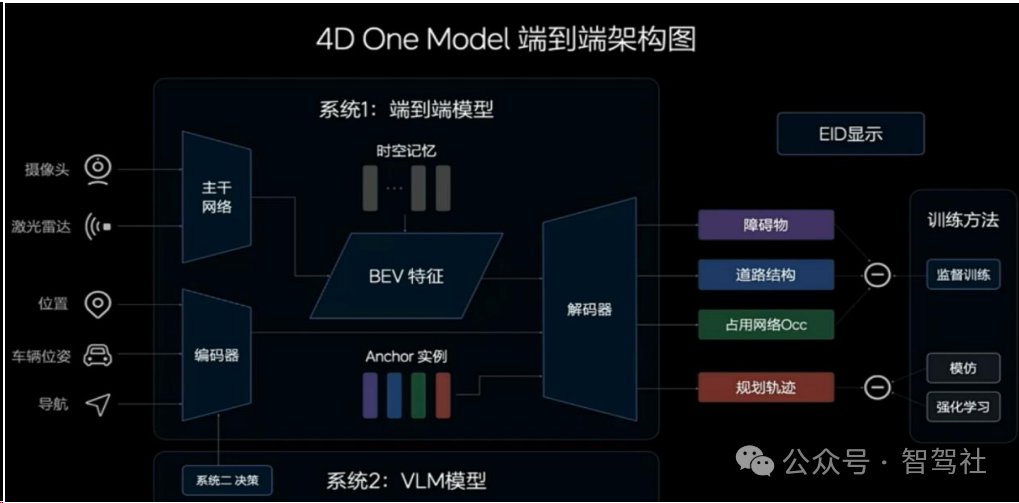
以知识驱动通往 L4。通过在 L2 时代,自动驾驶面对的是已知的场景,算法上只需要部分感知环节进行一部分的模型化,在其它部分还是以基于规则为主。随着开城的进行,最终要做到全国的开放(理想将这视为 L3 时代),自动驾驶需要面临更加丰富的场景,数据驱动的算法成为主流,算法上的变化表现在所有的模块感知、规控都逐渐模型化,完整的端到端从感知、跟踪、预测、决策到规划都模型化。而到L4 时代自动驾驶系统需要处理的都是真实世界未知的场景,即使是端到端算法也不一定能实现良好应对,理想认为在这种场景中,需要知识驱动,需要自动驾驶具有常识、能够对真实世界进行理解,这就需要多模态的视觉语言模型或者世界模型。
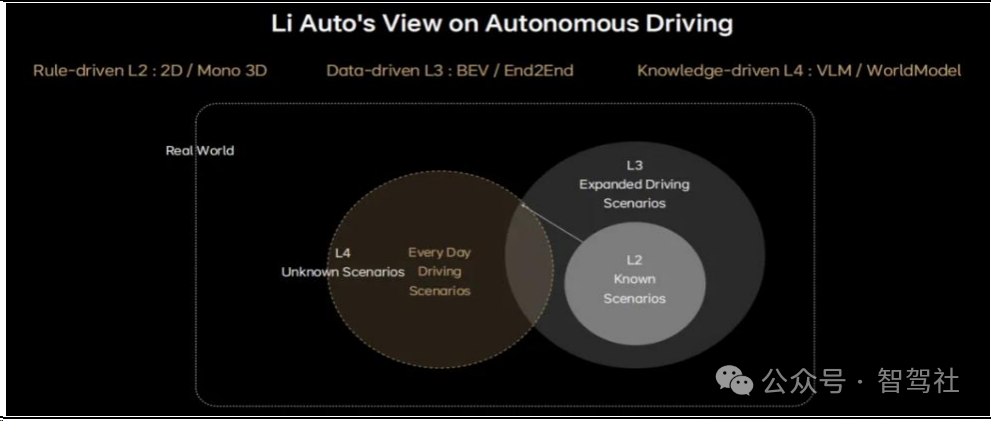
通过 VLM/世界模型才能够应对真实世界中的未知场景
系统 2 为视觉语言模型(VLM),知识驱动打开通往 L4 之路。“知识驱动”的范式加入了系统 2 为系统 1 的端到端模型兜底,系统 2 具有一定的理解世界的常识,是针对驾驶场景特化的大语言模型,可以解决各种各样的 Corner Case 和泛化的问题,快慢系统结合,最终就能够解决 L4 整体的车端框架。具体来看,120 度和 30 度相机时刻观察周围的环境,并且与导航地图的图像进行模态对齐,对齐的结果将被输入到 VLM 的核心——视觉语言模型解码器,同时系统 1 也可以通过 Prompt 问题库向系统 2 随时提问,一起输入到视觉语言模型解码器中;解码器通过自回归输出对环境的理解、驾驶的决策建议以及驾驶的参考轨迹,结果返回到系统 1,辅助系统 1进行轨迹规划。L3 阶段,系统 1 发挥主要的作用,系统 2 起到参考或者咨询特殊情况的作用;而到 L4 阶段,系统 2 会发挥更多作用,其能力决定了能不能到 L4。
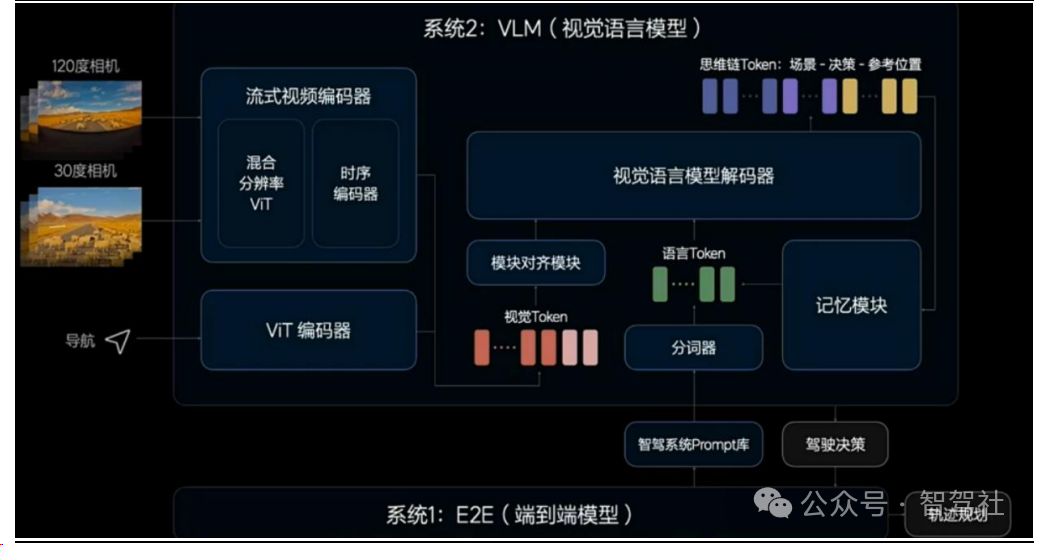
视觉大语言模型可以很好的识别驾驶场景并做出决策
系统 2 实现车端部署,随硬件升级有望实现系统 1 与系统 2 的融合。系统 1 作为端到端模型参数量只有 3 亿,而系统 2 作为大模型,其参数量达到了 22 亿,比端到端模型高一个量级。理想为将 VLM 模型部署在车端的 Orin-X 上,进行了一系列优化,最终将整体的推理性能优化 13 倍,实现 0.3 秒推理一次,车端运行频率是 0.34Hz。而系统 1 则在十几赫兹高频运行,如果系统 2 能够运行时延更低、判断更加准确,则有望实现快慢模型合一。理想正在预研将模型做更大、帧率变更高,同时车端算力芯片也需要进行相应升级以支撑系统 2 的高速稳定运行。
2.2、 世界模型+数据闭环助力理想快速迭代
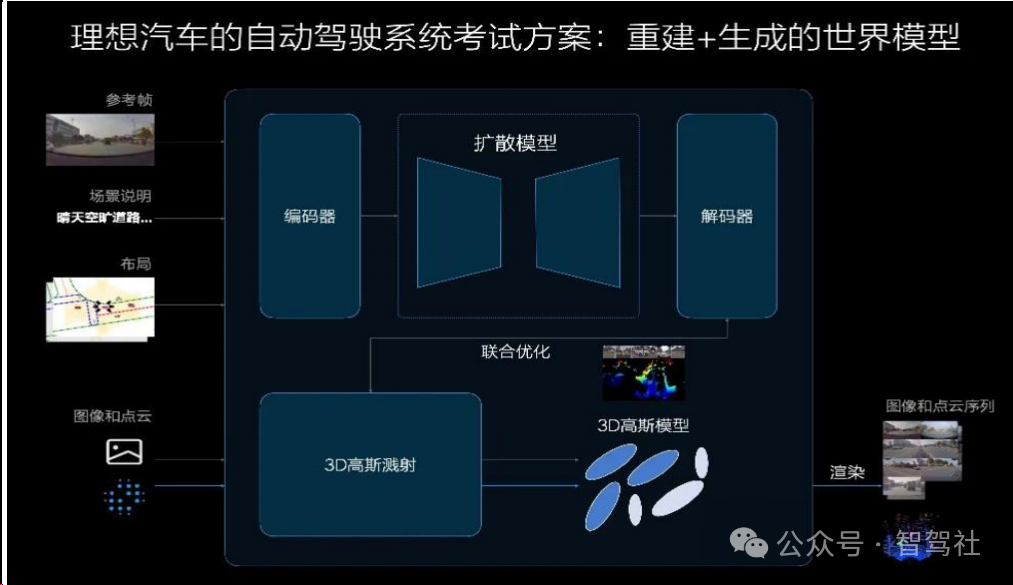
数据驱动之下,验证能力帮助自动驾驶快速铺开。理想通过快速试错的方式快速推广无图方案,具体流程是先找封闭区域验证范式,一旦跑通立马加上安全兜底策略进行推广、慢慢铺开,而要做全国范围的无图 NOA,通过铺人力的方式进行验证不仅成本高,且周期较长。在之前的自动驾驶开发中,是先设计功能再研发,一项项功能去测试验证;而在数据驱动的时代,理想认为传统的功能验证应当转变为对自动驾驶能力的“考试”。理想在云端构建了世界模型,配合车端的影子模式进行验证,一旦通过世界模型的“考试”,立马部署做实车测试,大大加速研发的流程。
重建+生成的世界模型具有良好的泛化性。理想使用重建+生成的方式进行世界模型的建构,可以解决重建式仿真的模糊拖影问题,也可以解决生成式仿真的幻觉问题,取长补短,能够生成很多符合真实世界规律但是没有见过的场景,内部也称其为系统 3。世界模型不仅能够加速自动驾驶验证、缩短研发流程,还可以蒸馏出能够部署在车端的 VLM 模型,效果好于从头训练的 VLM 模型。此外世界模型能够与数据闭环进行很好的联动,假设车主接管后,一段 Clip 通过影子模式数据回传云端,云端世界模型自动生成类似场景,变成错题库,同时在已有错题库中检索或在数据库中挖掘类似场景,联合训练出新模型;新模型再回到世界模型中进行两次考试:一次在原场景中,一次在生成的类似场景中,通过自动化的闭环训练模型。
数据方面,理想拥有超过 87 万的车主,形成了全国最大的自动驾驶车队,在过去几年车队的累计行驶里程已经超过 200 亿公里,截至 2024 年 7 月,理想的智能驾驶累计行驶里程超过 20.6 亿公里。理想为筛选数据,定义了五星级司机标准,并对用户进行打分,超过 90 分的车主只占 3%,累计筛选了超过 100 万公里的数据,到 2024年底可能超过 500 万公里。训练数据以 20-30s 左右的 Clips 形式存在,记录司机驾驶的完整数据,包括视觉传感、车辆状态、油门刹车等操作信息数据。在训练方面,端到端本质上是模仿学习,目的是学习行驶轨迹,但仅模仿学习的效果有限,因此理想使用模仿学习+强化学习的方案,让模型在犯错的时候被惩罚,模型就会知道什么驾驶行为是错的,训练出来的模型无论是驾驶技巧还是价值观都会非常正确。
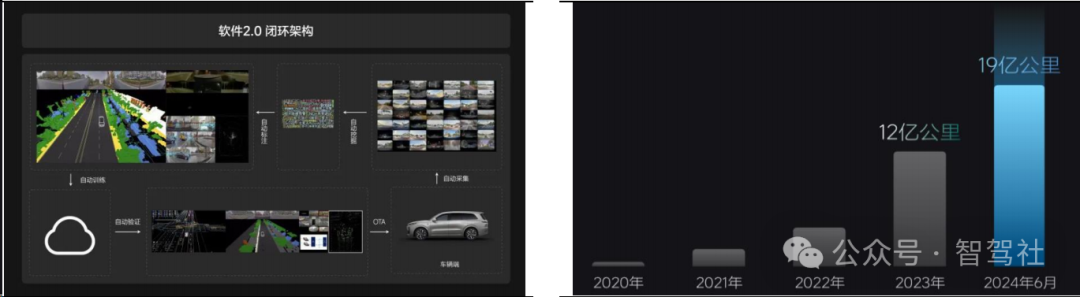
理想端到端+VLM 自动驾驶最早 2024 年底推出。理想的研究团队已经完全通过了正常的研究验证,在全国无图 NOA 正式推送的时候,向测试用户推送由 300 万 Clips训练出来的端到端+VLM 的监督型自动驾驶体系,并在 2024 年底至 2025 年初推出超过 1000 万 Clips 训练的端到端+VLM 的带有监督的自动驾驶体系。

理想自动驾驶演进中,端到端范式减少大量代码
2.3、 理想 NOA 实现不限城市、不限道路的通行能力,体验升级
理想当前的无图 NOA 的四大能力:哪里都能开、绕行丝滑、路口轻松、默契安心。
(1)无图无先验,哪里都能开;全国不限城市、不限道路:实时理解能力提升,不依赖先验信息真正做到哪里都能开。不限道路、不限城市,偏僻小城窄路、乡村小路、错综山路等都能流畅通行,无车道线、临时施工等路段都不再是问题。

(2)时空联合,绕行丝滑,决策时机更果断:全新时空规划模型的应用让无图NOA 真正像人一样思考和规划。遇到电瓶车、自行车、行人无规则穿行或车道停车乱象等复杂行车场景,也能更丝滑、更高效地进行绕行。
(3)路口轻松,上帝视角,通行更高效:理想汽车使用 BEV 视觉模型融合导航匹配算法,对车道结构和导航特征充分融合,达成了范围更广、信息更丰富的“上帝视角”有效解决复杂路口走错路的问题实现了超远视距选路的能力。
(4)分米级微操,驾驶更默契,家人更安心:与用户心理安全边界匹配默契更早更准预测加塞车辆、横穿车辆和骑行人,更精确控制距离,更得当地加速减速。让全家人在使用智能驾驶时谨慎而不紧张,安全且更安心。
未来的端到端+VLM 还将具备通用障碍物理解能力,超视距导航能力,道路结构理解能力,拟人的规划能力。
3、 组织面向端到端,云端算力大扩充,理想加码自动驾驶布局
3.1、 量产和预研双线并行,成立端到端实体组织
明确 RD 与 PD 明暗双线,组织架构上支撑自动驾驶快速迭代。理想 2023 年雁栖湖会议后明确 RD 和 PD 两条脉络研发智驾,其中 PD 是量产研发与产品交付,负责工程落地,包括推送给全量用户、千人团测等版本,是市场看得到的明线,在 2023 年是 NPN 和无图的量产交付,在目前是双系统的交付;RD 是研发,负责预研技术,是市场看不到的暗线,在 2023 年是端到端双系统的预研,在目前是统一快慢系统以及 L4 的预研,后者还在探索,可能会整合一套理解加生成合一的超级大模型,通过蒸馏或者强化学习的方式,把大模型的知识都放到车端。如此滚动开发架构下,理想只用大约一年多的时间便完成了 NPN、无图、端到端+VLM 的三代迭代。
2024 年 7 月,理想内部成立“端到端自动驾驶”的实体组织,整体超过 200 人,其他团队成员灵活支援项目。RD 和 PD 两大组共 800 人,其中 PD 包含智能行车、智能泊车、智能安全等;“端到端”的研发主力部署在算法研发组,其中 RD 下设感知算法、行为智能、认知智能等组,其中行为智能包含端到端架构、端到端模型、控制模型等,认知智能包含认知模型、云端模型等组。
3.2、 加大投入拓展云端算力,自研芯片补充车端算力
云端算力加速布局,为自动驾驶训练进化提供牢固地基。截至 2024 年 8 月,理想云端算力规模已达到 4.5EFlops,一年的租卡约 10 亿元,而据理想智能驾驶副总裁郎咸朋介绍,支撑 VLM 和端到端的训练大概需要几十 EFlops 的算力储备,如果做到 L3和 L4 自动驾驶,一年光是训练算力的花销大概为 10 亿美金。随着数据和算力的补充,端到端架构衍生出来的城市智驾,将很可能达到高速上的驾驶体验。
自研芯片补充车端算力。据 36 氪汽车资料,理想从 2023 年 11 月开始大幅推进自研智驾芯片,自研的主要模块为 NPU,后端设计部分外包给中国台湾的世芯电子,然后再交由台积电完成制造。目前理想已经设立了约 200 人的智驾芯片团队,芯片将会在 2024 年内完成流片。
















 652
652

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











