






作者 | 地平线开发者 编辑 | 大模型没那么大
原文链接:https://zhuanlan.zhihu.com/p/1894072843572080728
点击下方卡片,关注“大模型没那么大”公众号
大模型巨卷干货,即可获取
本文只做学术分享,如有侵权,联系删文
1. 前言
我们知道,大模型现在很火爆,尤其是 deepseek 风靡全球后,大模型毫无疑问成为为中国新质生产力的代表。百度创始人李彦宏也说:“2025 年可能会成为 AI 智能体爆发的元年”。
随着科技的飞速发展,大模型的影响力日益凸显。它不仅在数据处理和分析方面展现出了强大的能力,还为各个领域带来了前所未有的创新机遇。在众多应用场景中,智能驾驶无疑是备受瞩目的一个领域。
智能驾驶作为未来交通的重要发展方向,具有巨大的潜力和市场需求。大模型的出现,为智能驾驶的发展注入了强大的动力。它可以通过对大量驾驶数据的学习和分析,实现更加精准的环境感知、路径规划和决策控制。例如,大模型可以实时识别道路上的障碍物、交通标志和其他车辆,预测潜在的危险情况,并及时做出相应的驾驶决策,从而提高驾驶的安全性和舒适性。
在这样的一种大趋势下,笔者将针对智能驾驶场景,讲一讲大模型的应用前景以及存在的瓶颈!!!
2.自动驾驶中的大模型
自动驾驶领域的大模型主要涵盖感知(Perception)、决策(Decision-making)和控制(Control) 等多个方面,那么可以应用于自动驾驶中的大模型可以分为;
2.1 感知层(Perception)
感知层主要依赖 计算机视觉(CV)和多模态大模型(MMML),处理摄像头、雷达、激光雷达等传感器数据。
2.1.1 计算机视觉模型
Tesla Vision(特斯拉)
Tesla Vision 是 特斯拉(Tesla) 开发的一套基于纯视觉(Camera-only)的自动驾驶感知系统,完全放弃了激光雷达(LiDAR)和毫米波雷达(Radar),仅依靠摄像头和 AI 算法进行环境感知。该系统用于 Tesla Autopilot 和 FSD(Full Self-Driving),目前在 FSD V12 版本中已经实现端到端 Transformer 训练。
Tesla Vision 具有以下核心特点:
纯视觉(Camera-only)感知:自 2021 年起,特斯拉宣布移除毫米波雷达,完全依靠摄像头。8 个摄像头覆盖 360° 视角,包括前、后、侧方摄像头。
基于 Transformer 的端到端AI:Tesla Vision 早期使用卷积神经网络(CNN)进行目标检测、分割和轨迹预测。 FSD V12 采用 端到端 Transformer 模型,用 BEV(Bird's Eye View)+ 视频 Transformer 进行感知。利用神经网络自动标注驾驶数据,大规模训练 AI 驾驶模型。BEVFormer / Occupancy Network 将 2D 视觉数据转化为 3D 环境模型,提高自动驾驶感知能力。
端到端学习(End-to-End Learning):早期 FSD 采用模块化架构(Perception → Planning → Control),FSD V12 采用端到端神经网络,直接学习驾驶行为,无需手工编写规则。
Tesla Vision 的工作原理:
感知(Perception):通过 8 个摄像头输入视频流。采用 Transformer 处理时序数据,形成 BEV(俯视图)Occupancy Network 预测周围动态环境(车辆、行人、红绿灯等)。
规划(Planning):FSD V12 直接通过 Transformer 计算驾驶路径,无需手工编码。AI 学习人类驾驶行为,进行转向、加速、刹车等决策。
控制(Control):车辆根据 AI 计算的轨迹执行驾驶动作。特斯拉自研 AI 芯片Dojo 提供超大规模计算能力。
2.1.2 多模态大模型
在自动驾驶领域,多模态大模型(Multimodal Large Models, MML)能够融合多个传感器数据(如摄像头、激光雷达、毫米波雷达、IMU 等)来提升感知、决策和控制能力。以下是当前主流的多模态大模型:
BEVFusion
BEVFusion 融合激光雷达 + 摄像头数据,提升 3D 目标检测能力。严格来说,BEVFusion 本身并不算一个典型的大模型(LLM 级别的超大参数模型),但它可以被视为自动驾驶中的大模型趋势之一,特别是在感知层的多模态融合方向。目前主流的 BEVFusion 主要用于 3D 目标检测,并非大语言模型(LLM)那样的百亿、千亿级参数模型。例如,Waymo、Tesla 的 BEV 模型参数量远低于 GPT-4 级别的 AI 大模型。而且任务范围局限于感知,主要用于将 2D 视觉(RGB 图像)和 3D 激光雷达(LiDAR 点云)融合,输出鸟瞰图(BEV)用于目标检测、占用网络等。不直接涉及自动驾驶的决策和控制,不像 Tesla FSD V12 那样实现端到端驾驶。
虽然 BEVFusion 不是超大参数模型,但它具备大模型的一些核心特征:
多模态(Multimodal)融合:融合 RGB视觉 + LiDAR + Radar,类似 GPT-4V(图像+文本)这种多模态 AI 方向。
Transformer 结构:新一代 BEVFusion 开始采用 BEVFormer(Transformer 结构),可扩展成更大规模的计算模型。
大规模数据驱动:需要超大规模的数据集(如 Waymo Open Dataset、Tesla 数据库)进行训练,符合大模型训练模式。
Segment Anything Model (SAM)(Meta)+ DINO(自监督学习)
SAM 是由 Meta AI 发布的一种通用图像分割模型,可以对任何图像中的任何物体进行分割,而无需特定的数据集进行微调。DINO(基于 Vision Transformer 的自监督学习方法) 由 Facebook AI(现 Meta AI)提出,能够在无监督情况下学习图像表示,广泛用于物体检测、跟踪和语义分割。SAM 和 DINO 结合后,可以极大提升自动驾驶中的 感知精度、泛化能力和数据效率。其结合方式可以总结为:
DINO 作为自监督学习特征提取器,提供高质量的视觉表示。 SAM 作为通用分割工具,利用 DINO 提供的特征进行高精度分割。 结合 BEVFusion、Occupancy Network,增强 3D 语义感知。 其在自动驾驶中的应用可以是:
无监督 3D 语义分割:DINO 预训练提取高质量视觉特征,SAM 进行目标分割,提高语义理解能力。
BEV 视角感知(鸟瞰图增强):DINO 适应跨尺度检测,SAM 用于 BEV 视角的动态目标分割。
动态物体跟踪:结合 SAM 的强大分割能力,可更精准跟踪行人、骑行者等。
2.2 规划与决策(Decision-making & Planning)
这一层面涉及强化学习、端到端 Transformer 以及大语言模型(LLM)用于自动驾驶策略决策
2.2.1 强化学习与决策模型
自动驾驶的决策层需要处理复杂的动态环境,包括车辆行驶策略、避障、变道、红绿灯响应等。强化学习(RL, Reinforcement Learning)和决策大模型(LLM, Large Decision Models)已成为关键技术,能够学习人类驾驶员的策略并在不同交通场景下进行智能决策。其基本框架为马尔可夫决策过程(MDP),主要的强化学习方法有(下图):
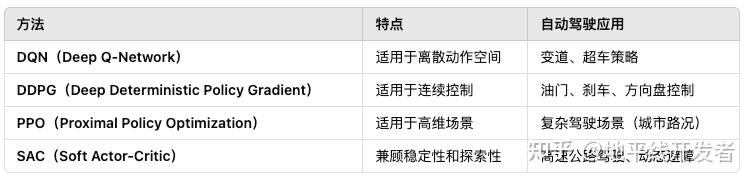
其应用实例有:
Waymo & Tesla:采用 DDPG/PPO 进行端到端驾驶策略优化。 Uber ATG:使用 DQN 进行交通信号识别和决策。
2.2.2 端到端 Transformer
端到端(End-to-End, E2E)Transformer 在自动驾驶中融合感知、预测、规划,实现端到端学习,摆脱传统模块化架构的局限。Tesla FSD V12 采用 Vision Transformer(ViT)+ GPT 进行端到端自动驾驶,而 GriT(Grid Transformer) 则专注于端到端路径规划,提供更高效的轨迹优化。
Vision Transformer (ViT) + GPT
Tesla FSD V12 采用 Vision Transformer (ViT) + GPT 结构,实现端到端驾驶控制,直接从摄像头输入生成方向盘转角、油门、刹车等控制信号。详细见前文。
GriT( Grid Transformer)
GriT(Grid Transformer) 是一种基于 Transformer 的路径规划模型,能够在复杂环境下进行高效轨迹规划。其核心思想为:
采用栅格(Grid-based)方法进行端到端轨迹预测。
适用于动态环境,如城市道路、高速公路、交叉路口等。
结合 Transformer 结构进行全局路径优化,避免局部最优问题。
GriT 主要结构为:
1、输入(多模态信息)
摄像头(前视 & 侧视)、LiDAR 点云(可选)、HD 地图信息。
目标检测(行人、车辆、红绿灯)。
车辆当前状态(速度、加速度、方向等)。
2、Transformer 编码(Grid-based Representation)
采用栅格化(Grid-based Representation),将环境信息编码为网格结构。
使用Self-Attention计算,学习全局路径规划策略。
3、轨迹预测 & 规划
通过 Transformer 计算最优驾驶轨迹。
适应不同交通状况(红绿灯、变道、避障等)。
GriT 在自动驾驶中的应用
1、复杂路口决策
GriT 能够预测多个可能路径,并选择最优轨迹,避免碰撞。
2、动态避障
在高速公路、城市驾驶场景下,实时避让前方障碍物或慢速车辆。
3、路径全局优化
传统路径规划方法(如 A*、Dijkstra)易陷入局部最优,而 GriT 通过 Transformer 提高全局规划能力。
2.2.3 发展趋势
1、ViT + GPT 端到端感知 & 规划进一步优化
结合更多传感器数据(如雷达)提升安全性。
提高自监督学习能力,减少数据标注需求。
2、GriT 结合 BEV,提升轨迹规划能力
未来 GriT 可能与 BEV 结合,提高 3D 规划能力。
提高对动态环境的适应性,优化驾驶策略。
3、多智能体 Transformer 强化学习
未来可训练多车辆协同驾驶,提高车队自动驾驶能力。
结合 RL(强化学习)优化自动驾驶策略。
2.3 控制层(Control)
控制层是自动驾驶的核心模块之一,负责将感知和规划结果转换为具体的车辆控制指令(方向盘、油门、刹车)。近年来,大模型(如 Transformer、RL-based Policy Network)正在革新自动驾驶控制层,使其更智能、更平滑、更适应复杂环境。
DeepMind MuZero:无模型强化学习框架,可用于动态驾驶控制优化。
Nvidia Drive Orin / Thor:专用 AI 芯片结合 Transformer 网络,用于高精度自动驾驶控制。
2.4 端到端自动驾驶大模型
部分大模型实现了从感知到控制的端到端学习:
OpenPilot(Comma.ai):开源自动驾驶系统,基于 Transformer 训练的行为克隆模型。
DriveGPT(类似 AutoGPT 的自动驾驶 LLM):将 LLM 应用于驾驶策略。
目前,特斯拉 FSD V12 是最先进的端到端 Transformer 自动驾驶大模型。
论文辅导来啦

知识星球交流社区
近4000人的交流社区,近300+自动驾驶公司与科研结构加入!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(大模型、端到端自动驾驶、世界模型、仿真闭环、3D检测、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎加入。

独家专业课程
端到端自动驾驶、大模型、VLA、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频
学习官网:www.zdjszx.com

















 2479
2479

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









