







[3D检测系列-PV-RCNN] PV-RCNN论文详解、PV-RCNN代码复现
一、论文详解
1、3D voxel CNN
特征:首先将输入点P划分为空间分辨率为L×W×H的小体素,其中非空体素的特征直接计算为所有内部点的逐点特征的平均值。 常用的特征是 3D 坐标和反射强度。 该网络利用一系列 3×3×3的3D 稀疏卷积将点云逐渐转换为具有 1×、2×、4×、8× 下采样大小的特征量。 每个级别的这种稀疏特征量可以被视为一组体素特征向量。通过将编码的 8 倍下采样 3D 特征量转换为 2D 鸟瞰特征图,按照基于anchor的方法生成高质量的 3D 提议。 具体来说沿 Z 轴堆叠 3D 特征量以获得 L/8 × W/8 鸟瞰特征图。 每个类有 2× L/8 × W/8 个 3D 锚框,采用该类的平均 3D 对象大小,并为鸟瞰特征图的每个像素评估两个 0°、90° 方向的锚。 采用基于锚的方案的 3D 体素 CNN 主干网络比基于 PointNet 的方法实现了更高的召回性能
2、体素到关键点场景编码
2.1、关键点抽样
采用FurthestPoint-Sampling (FPS)算法从点云P中采样少量n个关键点K = {p1,····,pn},KITTI数据集n=2048 ,Waymo 数据集n=4,096 。这种方法使关键点分布在非空体素周围,可代表整个场景。
2.2、体素抽象
![]() 表示为 3D voxel CNN 的第 k 层中的体素特征向量集
表示为 3D voxel CNN 的第 k 层中的体素特征向量集
![]() 作为特征向量集每个体素的 3D 坐标,Nk为第k层非空体素数量
作为特征向量集每个体素的 3D 坐标,Nk为第k层非空体素数量
然后对于每个关键点 pi,首先在第 k 层的半径 rk 中识别其相邻的非空体素,以检索体素特征向量集。

表示相对位置
代表语义体素特征
代表Pi相邻体素集(就是由上面二者相关联得到)
通过 PointNetblock将中的体素特征转换以生成关键点 pi 的特征:

M(·) 表示从相邻集合 中随机采样至多
个 体素以节省计算量。G(·) 表示多层感知器网络以对体素特征和相对位置进行编码。沿通道最大池化操作 max(·) 将不同数量的相邻体素特征向量映射到关键点 pi 的特征向量
。 通常,还在第 k 层设置多个半径,以聚合具有不同感受野的局部体素特征,以捕获更丰富的多尺度上下文信息。
上述体素集抽象是在3D体素CNN的不同层次上进行的,不同层次的聚合特征可以串联起来生成关键点pi的多尺度语义特征

其中生成的特征![]() 结合了从体素特征
结合了从体素特征 中基于 3D 体素 CNN 的特征学习和从体素集抽象中基于 PointNet 的特征学习。
3、VSA模块(体素集抽象模块)
VSA作用:对从3D CNN特征量到关键点的多尺度语义特征进行编码
原始点云特征,将关键点 pi 投影到 2D 鸟瞰坐标系,并利用双线性插值从鸟瞰特征图中获得特征
。pi 的关键点特征通过连接其所有相关特征得到进一步丰富,这些特征具有很强的保留整个场景的 3D 结构信息的能力,并且还可以大大提高最终检测性能。

3.1、 预测关键点权重
提出了一个预测关键点加权 Predicted Keypoint Weighting(PKW) 模块 ,以通过来自点云分割的额外监督来重新加权关键点特征。分割标签可以直接由3D检测框注释生成,即通过检查每个关键点是在ground-truth 3D框的内部还是外部。
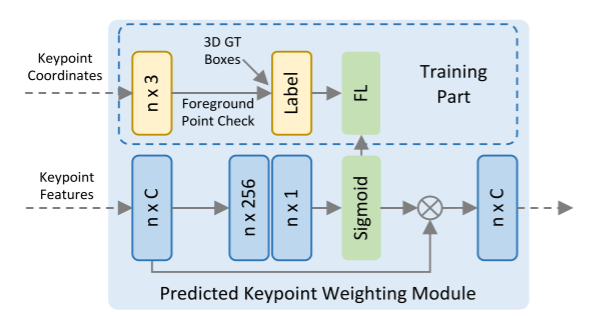
每个关键点的特征的预测特征权重![]() 可以表示为:
可以表示为:

其中 A(·) 是具有 sigmoid 函数的三层 MLP 网络,用于预测 [0, 1] 之间的前景置信度。 PKW 模块由具有默认超参数的焦点损失(链接:链接:Focal loss for dense object detection)进行训练,用于处理训练集中前景/背景点的不平衡数量。
4、提案细化的关键点到网格 RoI 特征抽象
在上一步中,将整个场景归纳为少量具有多尺度语义特征的关键点。给定由 3D 体素 CNN 生成的每个3D提议(RoI),每个 RoI 的特征需要从关键点特征![]() 中聚合准确和强大的提案细化。 提出了基于集合抽象操作的关键点到网格 RoI 特征抽象,用于多尺度 RoI 特征编码。
中聚合准确和强大的提案细化。 提出了基于集合抽象操作的关键点到网格 RoI 特征抽象,用于多尺度 RoI 特征编码。
4.1、通过集合抽象进行 RoI 网格池化
提出 RoI-grid pooling 模块将关键点特征聚合到具有多个感受野的 RoI-grid 点。 我们在每个 3D 提议中统一采样 6 × 6 × 6 网格点,表示为![]() 。 采用集合抽象操作从关键点特征中聚合网格点的特征。 具体来说,首先将网格点
。 采用集合抽象操作从关键点特征中聚合网格点的特征。 具体来说,首先将网格点 在半径
内的相邻关键点识别为:

其中使 被附加与从关键点
得到的局部相对位置
![]() 相关联。 然后采用PointNet-block聚合相邻关键点特征集
相关联。 然后采用PointNet-block聚合相邻关键点特征集![]() 以生成网格点
以生成网格点的特征为:
![]()
4.2、3D 提案细化和置信度预测
给定每个框提案的 RoI 特征,提案细化网络学习预测相对于输入 3D 提案的大小和位置(即中心、大小和方向)残差。 细化网络采用 2 层 MLP,并有两个分支分别用于置信度预测和框细化。对于置信度预测分支,采用 3D RoI 与其对应的 ground-truth 框之间的 3D Intersection-over-Union (IoU) 作为训练目标。 对于第 k 个 3D RoI,其置信度训练目标 被归一化为 [0, 1] 之间
![]()
其中是第 k 个 RoI w.r.t 的ground-truth的IoU。然后训练置信分支以最小化预测置信目标时的交叉熵损失,
是网络的预测分数
![]()
框细化分支的框回归目标采用传统的基于残差的方法进行编码,并通过平滑 L1 损失函数进行优化。
5、训练损失
与second网络损失相同

二、代码复现
先附上环境配置:
Ubuntu18.04
python3.6
pytorch 1.8.0 torchvision 0.9.0 cuda 11.1
1、Copy代码
git clone https://github.com/open-mmlab/OpenPCDet2、安装一些功能包
按照requirements来安装需要的依赖,我自己是按照txt中需要的一个一个的安装的,官方则是直接安装。但是环境就是玄学,为了避免出现问题我已经安装过的我怕系统重新给我下载会出现问题。因此我是对照txt将我还没下载的库自己手动下的,下面这个是官网的代码,可以一键直接下载。记得使用镜像源不然很慢。
cd OpenPCDet
pip install -r requirements.txt安装Spconv:
pip install spconv-cu11.1注意:此处的-cu11.1是你cuda的版本,我这里是11.1根据自己的cuda版本来下载。
安装pecet:
python setup.py develop如果你不确定自己有没有安装成功可以打开终端:
python
import spconv
import pcdet如果没有报错则验证成功。
安装mayavi:
conda install mayavi3、数据集的准备
这个地方不需要重新介绍(我有点懒),大家可以参考我另外一篇文章,直接看数据集准备的那部分。直接设置软连接,里面也包括了如何下载Kitti数据集的方法。
然后这个地方还需要对数据集做处理,不然后面出现以下错误:
File "../pcdet/datasets/kitti/kitti_dataset.py", line 378, in __getitem__ sample_idx = info['point_cloud']['lidar_idx'] KeyError: 'point_cloud'

解决方法:
进入tools/文件下:
python -m pcdet.datasets.kitti.kitti_dataset create_kitti_infos cfgs/dataset_configs/kitti_dataset.yaml4、网络运行检测:
首先需要下载一个预训练权重:
这个权重需要fanqiang:https://drive.google.com/file/d/1lIOq4Hxr0W3qsX83ilQv0nk1Cls6KAr-/view?usp=sharing
然后这个是已经下载好的:
将下载好的权重放在tools/文件下就可以了。
然后进入tools文件夹下:
python test.py --cfg_file cfgs/kitti_models/pv_rcnn.yaml --batch_size 8 --ckpt pv_rcnn_8369.pth --save_to_file!!!!开始训练啦!!!!
注意:如果你的内存不大的话可以把batch_size改为4,4都还不行的话就改成1。
然后下面就是检测完成的结果!!!
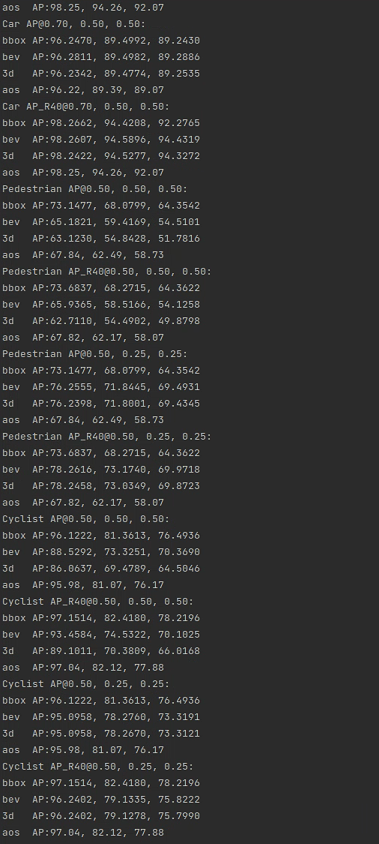
结果保存在:![]()
自己写的所以有点复杂,但是至少能完成嘿嘿。如果各位有优化欢迎评论区讨论!!















 1489
1489











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











