






大家看到标题了吗?如今的大模型一般都是以B为单位的,比如8B、70B等,但是正如标题所说,67M的大模型竟然在推断复杂图表中的因果关系时,这个仅有6700万参数的大模型竟然大打过了拥有万亿参数的GPT-4,这个结果实在令人震惊,背后是因为什么呢?
传统的Transformer
Transformer模型(直译为“变换器”)是一种采用注意力机制的深度学习模型,这一机制可以按输入数据各部分重要性的不同而分配不同的权重。该模型主要用于自然语言处理(NLP)与计算机视觉(CV)领域。
与循环神经网络(RNN)一样,Transformer模型旨在处理自然语言等顺序输入数据,可应用于翻译、文本摘要等任务。而与RNN不同的是,Transformer模型能够一次性处理所有输入数据。注意力机制可以为输入序列中的任意位置提供上下文。如果输入数据是自然语言,则Transformer不必像RNN一样一次只处理一个单词,这种架构允许更多的并行计算,并以此减少训练时间。
Transformer模型于2017年由谷歌大脑的一个团队推出模型#cite_note-:0-2),现已逐步取代长短期记忆(LSTM)等RNN模型成为了NLP问题的首选模型。并行化优势允许其在更大的数据集上进行训练。这也促成了BERT、GPT等预训练模型的发展。这些系统使用了维基百科、Common Crawl等大型语料库进行训练,并可以针对特定任务进行微调。
具体可自行了解
这次微软MIT等采用的因果推理的研究背景
因果推理(causal reasoning)是一种推理过程,遵守有特定因果性的预定义公理或规则。
图灵奖得主Judea Pearl曾通过如下的「因果关系阶梯」(ladder of causation)定义了可能的因果推理类型。
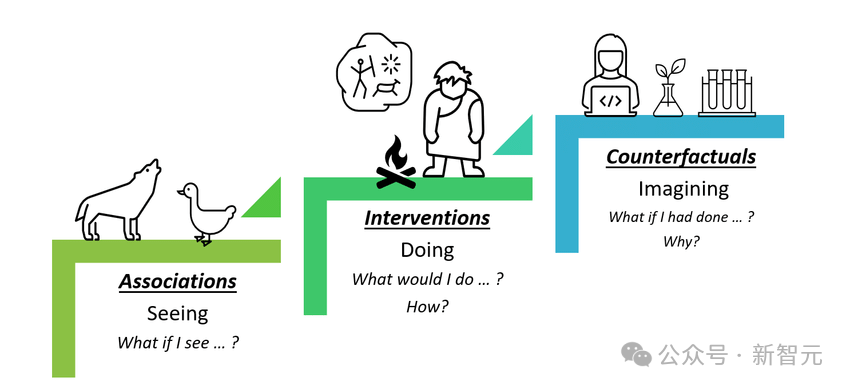
传统的统计方法和机器学习模型往往关注于关联性,即两个或多个变量之间是否存在某种模式或趋势。然而,关联性并不等同于因果性。例如,“冰淇淋销量增加与溺水事件数量增加相关”是一个常见的关联性示例,但这并不意味着吃冰淇淋会导致溺水;实际上,两者可能都与夏天天气变热有关。
相比之下,因果推理旨在解决以下问题:
-
因果效应:确定一个行动或干预对结果的具体影响。
-
反事实推理:如果某个特定的事件没有发生,事情会怎样发展?
-
处理混杂因素:识别和调整那些可能影响因果关系判断的外部因素。
在大模型中,因果推理可以通过以下几种方式实现:
-
潜在结果框架(Neyman-Rubin Causal Model):这涉及到定义一个实验单元在干预和未干预状态下的潜在结果,并试图估计这两个状态之间的差异。
-
结构方程模型(Structural Equation Models, SEMs):通过显式地建模变量之间的因果关系来估计因果效应。
-
因果图(Causal Graphs):使用有向无环图(DAGs)来表示变量之间的因果假设,帮助识别混杂因素并设计有效的统计控制策略。
-
倾向评分匹配(Propensity Score Matching):用于观察数据,通过匹配具有相似倾向得分的个体来近似随机对照试验的效果。
-
反事实推理(Counterfactual Reasoning):基于给定的观察到的数据点,预测如果某些条件不同,结果会如何变化。
在机器学习中,因果推理可以被用来改进预测模型,通过识别和利用因果结构来减少偏差,提高模型的解释性和鲁棒性。此外,因果推理还可以用于指导决策支持系统,使它们能够提供更合理、更可信赖的建议。
值得注意的是,因果推理的有效应用通常需要一些强假设,如无隐藏偏见(Unconfoundedness)和稳定单位处理值假设(Stable Unit Treatment Value Assumption, SUTVA),这些假设在实际数据集中可能不完全成立,因此需要谨慎对待结果。
技术详解
PDF:
这项研究的标题是“通过公理训练教授变换器因果推理”(Teaching Transformers Causal Reasoning through Axiomatic Training)。研究由来自微软研究院(Microsoft Research)、麻省理工学院(MIT)和印度海得拉巴印度理工学院(IIT Hyderabad)的研究人员共同完成。以下是研究的技术细节概述:
公理训练 (Axiomatic Training)
-
目标: 探索文本基AI系统如何能从被动数据中学习因果推理技能,因为生成干预数据成本高昂。
-
方法: 研究者采用了一种公理训练设置,在这种设置中,代理(agent)通过多次演示一个因果公理(或规则)来学习,而不是将公理作为归纳偏置或从数据值中推断出来。
-
关键问题: 代理是否能从公理演示中泛化到新情境。例如,如果一个变换器模型在小图上的因果传递性公理演示上训练,它能否泛化到在大图上应用传递性公理?
模型与训练
-
使用了一个拥有6700万个参数的变换器模型,训练数据包括线性因果链及其一些噪声变异。
-
模型不仅限于训练数据的特定设置,还能很好地泛化到新的图形类型,包括更长的因果链、顺序相反的因果链以及分支图。
-
即使在没有明确针对这些场景进行训练的情况下,模型的表现与GPT-4、Gemini Pro和Phi-3等更大规模的语言模型相当甚至更好。
结果与观察
-
该模型能够在未见过的因果图结构上推断一个变量是否导致另一个变量,显示了从被动数据中学习因果推理的能力。
-
通过公理训练框架,只要提供足够的演示,就可以学习任意公理,这为从被动数据中学习因果推理提供了一个新的范式。
因果无关性陈述(公式格式可能缺失,请从原PDF中查看)
因果无关性陈述可以通过逻辑运算符来表达:
(Xs,ti↛Xs,tj∣Xs,tk)⇒(∀l,n)(Xl,ni↛Xl,nj∣Xl,nk)(X*s,ti*\→Xs,*tj∣Xs,tk)⇒(∀l,n*)(Xl,*ni\→Xl,nj*∣Xl,*nk*)
这里,∧∧ 表示逻辑与,∨∨ 表示逻辑或。对于给定的 (s,t)(s,t) 或 (l,n)(l,n) 对,Xi,Xj,XkX*i,Xj,Xk* 是观测变量 XX 的不交子集。如果前提为真,则后件也必为真。
因果传递性公理(公式格式可能缺失,请从原PDF中查看)
对于稳定的概率因果模型,给定变量 X,Y,ZX,Y,Z 在系统中,传递性公理可表述为:
(X↛Y∣Z)⇒(A↛Y∣Z)∨(X↛A∣Z)∀A∉X∪Z∪Y(X\→Y∣Z)⇒(A\→Y∣Z)∨(X\→A∣Z)∀A∈/X∪Z∪Y
这个表达式可以进一步简化为其因果相关性的版本,通过取反证法得到:
∃A∉X∪Y∪Z s.t. (X→A∣Z)∧(A→Y∣Z)⇒(X→Y∣Z)∃A∈/X∪Y∪Z s.t. (X→A∣Z)∧(A→Y∣Z)⇒(X→Y∣Z)
其中,左侧表达式称为前提(Premise),右侧表达式称为假设(Hypothesis)。
训练数据与损失函数(公式格式可能缺失,请从原PDF中查看)
基于上述公理,可以构造出包含前提 PP 和假设 HH 的训练实例,并标记其正确性('Yes' 或 'No')。例如,若底层真实的因果图拓扑是一个链 X1→X2→X3→⋯→XnX1→X2→X3→⋯→X**n,则一个可能的前提是 X1→X2∧X2→X3X1→X2∧X2→X3,对应的假设 X1→X3X1→X3 将被标记为 'Yes';而另一个假设 X3→X1X3→X1 则会被标记为 'No'。
公理训练框架
该框架用于生成数千个合成符号表达式,用以教授Transformer特定的公理。训练后的模型在新因果结构上进行评估,这些结构在训练集中未曾出现过。例如,模型能够对更长和更复杂的图结构进行泛化,其性能往往优于现有的大型语言模型如GPT-4、Phi-3和Gemini Pro。
延伸方向
-
适用性扩展:虽然目前工作专注于传递性公理,但将此方法扩展至其他因果公理或适用于下游任务的公理(如效应推断)是未来的研究方向。
-
逻辑推理的通用性:公理训练方法可以应用于任何基于公理的形式系统,包括演绎推理等逻辑任务。
这些细节展示了研究中如何利用因果公理来设计训练方案,并评估模型的因果推理能力。
测试:
-
因果链长度测试:
-
当模型被限制在3-6节点的因果链上时,公理训练的模型TS2(NoPE)的表现超过了GPT-4。
-
特别是在长度为6的链上,TS2(NoPE)的准确率达到了0.94,显著高于Gemini Pro和Phi-3的0.62和0.69。
-
-
分支结构测试:
-
对于非线性的因果关系,即引入了Erdos-Renyi随机图作为因果序列,而训练数据仅包含线性链。
-
虽然GPT-4在增加的图大小上获得了最好的准确度,但是TS2(NoPE)模型在除了一个之外的所有图大小上都比Gemini Pro表现更好。
-
即使在具有12个节点和1.4的分支因子的图上,TS2(NoPE)模型的准确率也达到了70%,远高于随机选择的50%。
-
-
额外结果:数据多样性和位置编码的作用:
-
没有位置编码的模型在更长的因果链(直到15个节点)和未见过的复杂图形结构上都表现出了良好的泛化能力。
-
使用SPE和LPE的模型在更长的链上也表现良好,但在复杂图形结构上表现较差。
-
总结
这次这个67M的大模型的测试结果很令人意外,在此前,因果推理一直是模型训练中一个比较冷门的方面,不过这次研究证明了因果推理在Transformer领域也是一个可行的方案。
探索因果推理的世界不仅揭示了人工智能领域的一个重要方面,而且强调了如何通过创新的方法,如公理训练,来增强机器的学习能力。本博客深入研究了因果推理的研究进展,尤其是Transformer模型在学习因果规则方面的潜力。我们看到了通过演示因果公理,模型能够推断出新的因果关系,并在多种场景下展现出令人鼓舞的泛化能力。
然而,挑战依然存在,比如模型在面对更复杂的因果图结构时的局限性。未来的研究需要进一步探索如何让模型不仅在长度上,也在结构和顺序上更好地泛化。此外,位置编码的作用和数据多样性的影响提示我们,对于设计更智能的AI系统来说,这些因素至关重要。
随着技术的进步,我们期待着见证因果推理领域的突破,以及它如何塑造人工智能的未来,使之更加贴近人类的理解方式。毕竟,让机器学会像我们一样思考因果关系,是迈向更高级认知技能的重要一步。
参考&鸣谢
6700万参数比肩万亿巨兽GPT-4!微软MIT等联手破解Transformer密码_腾讯新闻
少部分文本由阿里通义AI生成
















 620
620

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











