







1、线性模型基本形式
给定有d个属性描述的示例x=(x1,x2,……,xi),其中xi是x在第i个属性上的取值,w=(w1,w2,……,wi),则可以表示为线性关系:
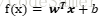
2、线性回归(linear regression):试图学得一个线性模型以尽可能准确地预测实值输出标记。
(1)对于离散属性,若属性存在序(order)关系,可通过连续化将其转化为连续值;若不存在序关系,则可以转换为k维向量;
(2)均方误差是衡量f(x)和y之间区别的最常用性能度量,基于均方误差最小化来进行模型求解的方法称为“最小二乘法”(least square method),在线性回归中,最小二乘法就是试图找到一条直线,使所有样本到直线上的欧氏距离之和最小;
(3)也可令预测值逼近y的衍生物,如对数线性回归(log-linear regression):
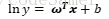
更一般的考虑单调可微函数g(·),得到广义线性模型(generalized linear model):

其中g(·)称为“联系函数”(link function)。
3、对于分类任务,我们要找一个单调可微函数将真实标记y和线性回归模型的预测值联系起来。
(1)最理想的是单位阶跃函数(unit-step function):
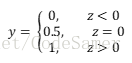
但是由于单位阶跃函数不连续,所以我们可以找近似单位阶跃函数的替代函数——对数几率函数:
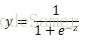
将z=wTx + b带入得到:
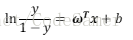
等式左侧被称为对数几率(log odds),对应模型称为“对数几率回归”(logistic regression),虽然名字带回归,但是是一种分类学习算法。
4、线性判别分析(LDA)
(1)一种监督学习的降维技术,概括为“投影后类内方差最小,类间方差最大”;
(2)关于类内散度矩阵、类间散度矩阵、广义瑞利商、二分类问题和多分类任务
(注:理解这一段的需要的很重要的知识点——协方差:表示两个变量总体误差的期望,如果两个变量的变化趋势一致,也就是说其中一个大于自身期望时另一个也大于自身期望,那么两个变量之间的协方差就是正值;如果两个变量的变化趋势相反,即其中一个变量大于自身的期望时另一个却小于自身的期望,那么两个变量之间的协方差就是负值;如果两者是统计独立的,那协方差就是0。
Cov(X, Y) = E[(X-E[X])(Y-E[Y])] = E[XY] - E[X]E[Y] )
5、多分类学习
(1)基本思路是“拆解法”,将多分类任务拆为若干个二分类任务求解;
(2)经典的拆分策略:
① 一对一(OvO):将N个类别两两配对,从而产生N(N-1)/2个分类任务,测试阶段,新样本将同时提交给所有分类器,于是得到N(N-1)/2个分类结果,最终结果通过投票产生;
② 一对其余(OvR):每次将1个类的样例作为正例,所有其他类的样例作为反例来训练N个分类器,测试时若仅有一个分类器的预测为正类,对应的类别标记作为最终分类结果;若有多个为正类,根据分类器的预测置信度。
③ 多对多(MvM):每次将若干类作为正类,若干其他类作为反类,但是正反类构造必须有特殊的设计,常用的是“纠错输出码”(ECOC);
ECOC主要分两步:
1° 编码:对N个类别做M次划分,每次划分将一部分类别化为正类,一部分化为反类,从而形成一个二分类训练集,这样一共产生M个训练集,可以训练M个分类器;
2° 解码:M个分类器分别对测试样本进行预测,这些预测标记组成一个编码,将这个预测编码与每个类别各自的编码进行比较,返回其中距离最小的类别作为最终预测结果。
ECOC编码对分类器的错误有一定的容忍和修正能力,ECOC编码越长,纠错能力越强,但相应的计算、存储开销都会增大。
6、类别不平衡(class-imbalance):指分类任务中不同类别的训练样例数目差别很大。
(1)再缩放(rescaling):当训练集中正、反例数据不均等时,令m+表示正例数,m-表示反例数,此时需对预测值进行缩放调整,有:
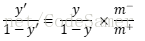
(2)在实际操作中,我们却未必能有效地基于训练集观测几率来推断真实几率,目前主要有三种解决方法:
① “欠采样”(undersampling)——去除一些反例(正例)使得正、反例数目接近;
② “过采样”(oversampling)——增加一些正例(反例)使得正、反例数据接近;
③ “阈值移动”(threshold-moving)——基于原训练集学习,但在训练好的分类器进行与测试,将上面的式子嵌入决策中。
(3)“过采样”代表算法SMOTE,通过对训练集里的正例进行插值来产生额外的正例;
“欠采样”代表算法EasyEnsemble,利用集成学习机制,将反例划分为若干个集合供不同学习器使用。

















 837
837

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









