







回顾与前言
在上一篇博客中,我们通过小明习得“买瓜秘笈”的故事了解了机器学习的大概流程以及一些相应的基本术语。在接下来的文章中,我们将开始学习具体的机器学习算法啦!
学习什么知识模型都是一个从简到难的过程。很多时候未知的问题要通过将其分割成已经解决的问题,复杂的模型要通过简单模型的变形、组合来解决,比如说今天学习的线性模型看似很简单,非线性模型是通过映射等手段将其转化为线性模型而解决的;以及多分类问题也是将其分解成多个二分类问题而解决的。这是一种很经典的数学思维所以大家不要小看第三章 线性模型哦~
第三章 线性模型
对于第三章 线性模型我们主要将学习用途最广泛的对数几率回归的算法。
线性模型是最基本的模型,其基本形式是:
y = a x + b y=ax+b y=ax+b
但是这种一维的形式实在是太简单了,于是我们从多维的线性模型开始,也就是将 x x x以及系数都变成向量形式,即:
f ( x ) = w T x + b f(\boldsymbol{x})=\boldsymbol{w}^T\boldsymbol{x}+b f(x)=wTx+b
但是一般情况下,只有数值型的属性数据才能够放入模型进行回归。而实际问题中很多属性并不是通过数值表示的,比如上篇博客提到的西瓜的三个属性“色泽”“瓜蒂”“声响”是通过“光亮”“蜷缩”“浑浊”等词语表示的,标签“好瓜”“坏瓜”也是通过词语表示的。所以,我们要事先将这些属性、标签转化成数值型数据。
- 对于定序尺度的变量,比如{好瓜, 坏瓜}、{大,中,小}我们就可以分别设置每个标签对应一个数值;
比如:
{ 好 瓜 → 1 坏 瓜 → 0 { \ \ \ \ \ \ \ }\left\{\begin{array}{ll} 好瓜\rightarrow1 \\ 坏瓜\rightarrow0 \end{array}\right. { 好瓜→1坏瓜→0
{ 大 → 1 大 → 0.5 小 → 0 { \ \ \ \ \ \ { \ \ \ \ \ \ \ }\ }\left\{\begin{array}{ll} 大\rightarrow1 \\ 大\rightarrow0.5 \\ 小\rightarrow0 \end{array}\right. ⎩⎨⎧大→1大→0.5小→0
- 对于变量值之间无法排序,也就是说各个属性值可能是并列的,比如颜色属性{绿色,黑色}与方向属性{东,南,西,北};
如果属性有k个可能的取值,我们可以设置一个k维向量来表示属性值, 每个分量取值均为0或1代表是否是对应的属性值。
比如:绿色 → \rightarrow →(1,0)
{\ \ \ \ \ \ \ \ \ } 南方 → \rightarrow →(0,1,0,0)
(ps:类似于经济学研究中虚拟变量的设置)
对数几率回归
回到西瓜的例子,我们现在已经将西瓜的标签{好瓜,坏瓜}设置成{0,1}。显然,这里的标签值就是线性模型中的 y y y值, x x x则是西瓜的各种属性值。
如果将其带入基本模型 f ( x ) = w T x + b f(\boldsymbol{x})=\boldsymbol{w}^T\boldsymbol{x}+b f(x)=wTx+b 之中,我们则会得到一个单位跃阶函数,如下图:
在 w T x + b > 0 \boldsymbol{w}^T\boldsymbol{x}+b>0 wTx+b>0时, y = 1 y=1 y=1,
当 w T x + b < 0 \boldsymbol{w}^T\boldsymbol{x}+b<0 wTx+b<0时, y = 0 y=0 y=0。
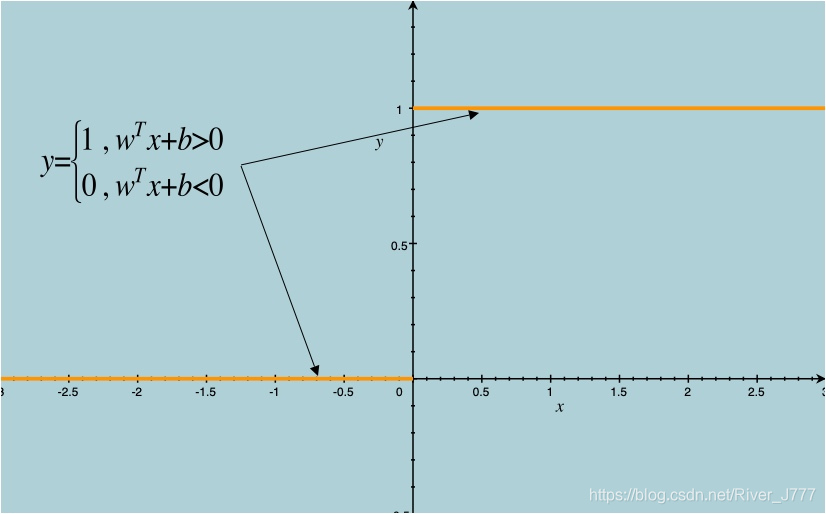
但是,跃阶函数并不是连续可微的,很难进行回归,于是数学家们找到了一个近似函数 ,称之为对数几率函数如图:
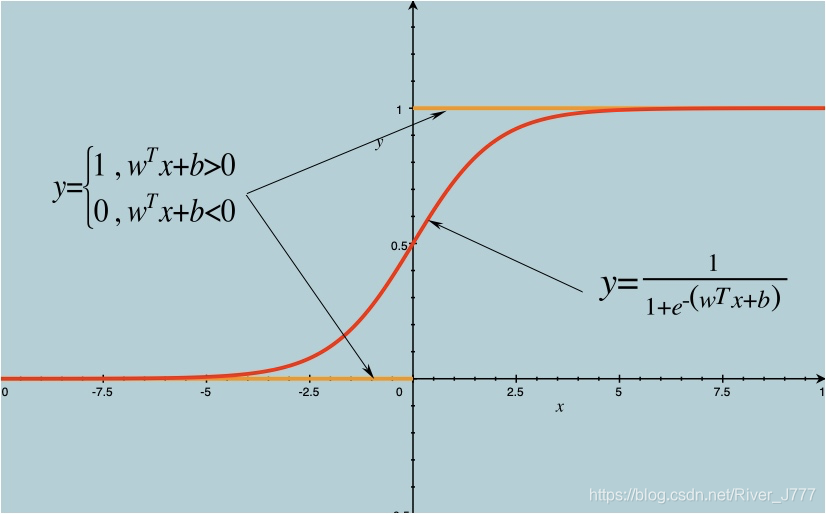
从图中我们可以看出,对数几率函数用来近似单位跃阶函数的两条极大的优点:
- 除了x=0附近,它可以把自变量转化成非常接近1或0的值;
- 它在x=0附近变化很陡。
凭借这两条优点,数学家们利用对数几率函数用来近似单位跃阶函数发明了对数几率回归,也叫做逻辑回归。(其实严格意义来说是分类方法,而不是回归方法)
对于 w T x + b \boldsymbol{w}^{T} \boldsymbol{x}+b wTx+b,我们通常会在 x \boldsymbol{x} x最后加入一列1作为常数项 b b b的系数,记作 x ^ \hat{\boldsymbol{x}} x^便可以将 w T x + b \boldsymbol{w}^{T} \boldsymbol{x}+b wTx+b转化为 β T x ^ \boldsymbol{\beta}^{T} \hat{\boldsymbol{x}} βTx^,以此来简化模型。
接着我们就可以用极大似然法对参数 β \boldsymbol{\beta} β进行估计。
极大似然法的核心理念是“发生概率越大的事件越有可能发生”。所以我们要求出事件发生的概率,也就是在给定数据集后所有样本取到其对应标签的概率,定义为似然函数,并求最大值。不同的样本之间视为独立的,所以其联合事件的概率是各个样本概率的连乘,即:
ℓ ( β ) = ∏ i = 1 m p ( y i ∣ x ^ i ; β ) \ell(\boldsymbol{\beta})=\prod_{i=1}^{m} p\left(y_{i} | \hat{\boldsymbol{x}}_{i} ; \boldsymbol{\beta}\right) ℓ(β)=i=1∏mp(yi∣x^i;β)
取对数并不会改变似然函数的最大值点,所以为了方便计算,我们一般要取对数:
ℓ ( β ) = ∑ i = 1 m ln p ( y i ∣ x ^ i ; β ) \ell(\boldsymbol{\beta})=\sum_{i=1}^{m} \ln p\left(y_{i} | \hat{\boldsymbol{x}}_{i} ; \boldsymbol{\beta}\right) ℓ(β)=i=1∑mlnp
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1937
1937











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









