







论文链接:Sparse4D: Multi-view 3D Object Detection with Sparse Spatial-Temporal Fusion
代码链接:GitHub - linxuewu/Sparse4D: Sparse4D v1 & v2
作者:Xuewu Lin, Tianwei Lin, Zixiang Pei, Lichao Huang, Zhizhong Su
发表单位:地平线
会议/期刊:无
一、研究背景
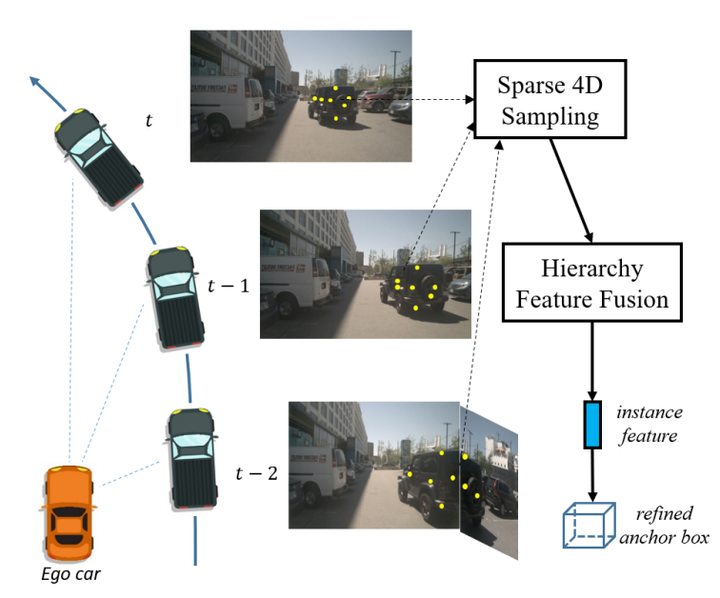
Sparse4D 概述。对于每个候选锚点实例,对多个关键点的多时间戳/视图/缩放特征进行稀疏采样,然后将这些特征分层融合为实例特征,以实现精确的锚点细化。
现有基于多模态融合的方法存在2个主流方法:基于BEV的方法和基于稀疏查询的方法。
然而,基于BEV的方法有3个不可避免的缺点:
(1)图像到BEV的视角转换需要密集的特征采样或重新排列:这一转换过程在操作上较为复杂,计算成本较高,对于预算有限的边缘设备部署来说尤为困难。
(2)最大感知范围受到BEV特征图大小的限制:这使得在感知范围、效率和精确度之间难以取得平衡。在某些情况下,为了扩大感知范围,可能需要牺牲精度和处理速度。
(3)高度维度在BEV特征中被压缩,失去了纹理线索:这意味着BEV方法在处理需要高度信息的任务(如路标检测)时可能不够有效,因为压缩后的特征图缺乏足够的细节来准确识别和解析高度相关的对象或场景细节。
同时,现有的基于稀疏查询的方法还有很大的改进空间:
(1)有限的模型容量:如DETR3D,它仅从每个锚点查询中的单个三维参考点采样特征。这限制了模型捕获和利用周围环境更全面信息的能力,因为单一的参考点可能无法充分代表整个物体或场景的复杂性。
(2)特征对齐不精确:例如,SRCN3D使用RoI-Align技术来采样多视角特征,但该方法在从不同视角精确对齐特征点方面并不高效。如果特征点对齐不精确,可能会影响检测结果的准确性,因为物体的位置和方向估计依赖于这些特征的准确融合。
(3)未充分利用时态上下文:现有的稀疏方法还未能有效利用丰富的时间上下文信息。时间上下文,如连续帧之间的信息,对于提高检测准确性和稳定性非常有帮助,特别是在动态环境中。缺乏对时间维度的利用,使得这些方法在性能上与采用时空融合的最新BEV方法相比存在显著差距。
本文贡献:
(1)提出Sparse4D是第一个具有时域融合的稀疏查询多视图3D检测算法;
(2)提出了一种可变形的4D聚合模块,可以灵活地完成多维(点、时间戳、视图和比例)特征的采样和融合。
(3)引入了深度重加权模块,以缓解基于图像的 3D 感知系统中的不良问题。
(4)在nuScenes 数据集上,Sparse4D优于所有现有的稀疏算法和大多数基于 BEV 的算法,并且在跟踪任务上也表现良好。
二、整体框架
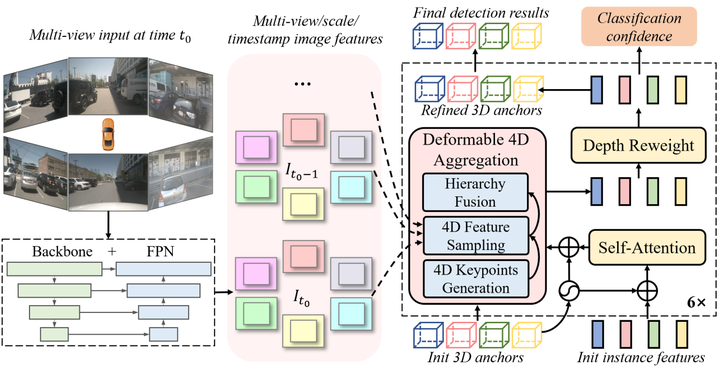
Sparse4D 的整体架构。以多视图图像为输入,首先使用图像特征编码器提取多时间戳/视图/比例特征图。解码器包含多个具有独立参数的细化模块,以图像特征图、实例特征和3D锚点为输入,对3D锚点进行持续细化,以获得准确检测结果。
Sparse4D采用了常见的编码器-解码器架构。
图像编码器包括Backbone(ResNet、VovNet)和FPN。给定某时间t的N张多视图,图像编码器提取多视图多尺度的特征图,得到 。为了利用时间上下文,将最近T帧的图像特征提取为图像特征队列
,其中
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1495
1495

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









