







 本文介绍了DQN算法及其存在的经验浪费和相关更新问题,提出了经验回放作为解决方案,通过存储和随机抽样transition来打破序列相关性。进一步探讨了改进的经验回放——优先级重放,利用TD误差进行非均匀抽样,并通过学习率变换平衡训练。这种方法提高了样本效率,尤其适用于深度强化学习中的高效训练。
本文介绍了DQN算法及其存在的经验浪费和相关更新问题,提出了经验回放作为解决方案,通过存储和随机抽样transition来打破序列相关性。进一步探讨了改进的经验回放——优先级重放,利用TD误差进行非均匀抽样,并通过学习率变换平衡训练。这种方法提高了样本效率,尤其适用于深度强化学习中的高效训练。
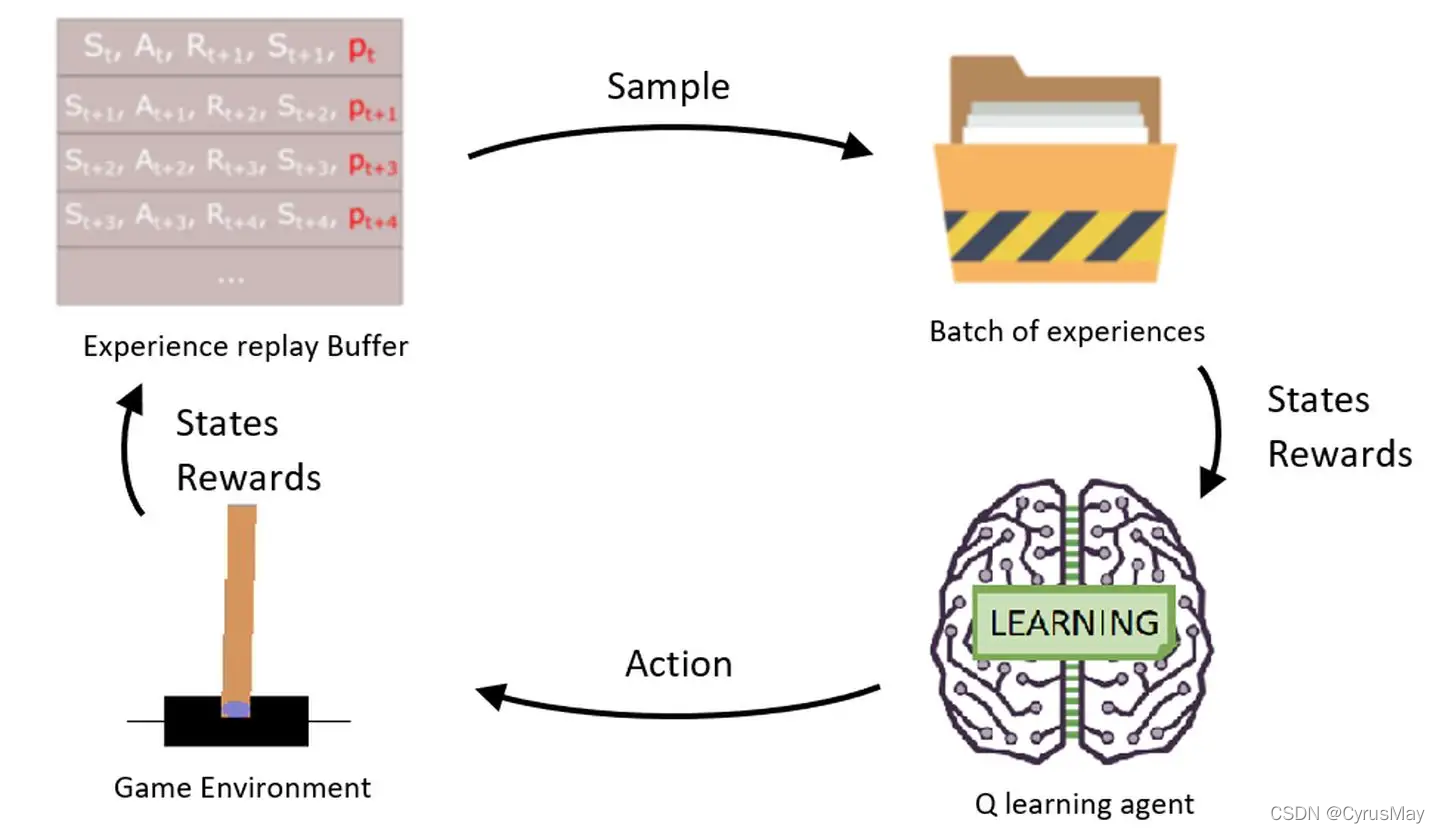
强化学习—— 经验回放(Experience Replay)
1、DQN的缺点
1.1 DQN
- 近似最优动作价值函数: Q ( s , a ; W ) ∼ Q ⋆ ( s , a ) Q(s,a;W)\sim Q^\star (s,a) Q(s,a;W)∼Q⋆(s,a)
- TD error: δ t = q t − y t \delta_t=q_t-y_t δt=qt−yt
- TD Learning: L ( W ) = 1 T ∑ t = 1 T δ t 2 2 L(W)=\frac{1}{T}\sum_{t=1}^{T} \frac{\delta_t^2}{2} L(W)=T1t=1∑T2δt2
1.2 DQN的不足
1.2.1 经验浪费
- 一个 transition为: ( s t , a t , r t , s t + 1 ) (s_t,a_t,r_t,s_{t+1}) (st,at,rt,st+1)
- 经验(所有的transition)为: { ( s 1 , a 1 , r 1 , s 2 , ) , . . . ( s t , a t , r t , s t + 1 ) , . . . , s T , a T , r T , s T + 1 } \{(s1,a1,r1,s2,),...(s_t,a_t,r_t,s_{t+1}),...,s_T,a_T,r_T,s_{T+1}\} {(s1,a1,r1,s2,),...(st,at,rt,st+1),...,sT,aT,rT,sT+1}
1.2.2 相关更新(correlated update)
通常t时刻的状态和t+1时刻的状态是强相关的。
r
(
s
t
,
s
t
+
1
)
r(s_t,s_{t+1})
r(st,st+1)
2 经验回放
2.1 简介
- 一个transition为: ( s t , a t , r t , s t + 1 ) (s_t,a_t,r_t,s_{t+1}) (st,at,rt,st+1)
- 回放容器(replay buffer)为:存储n个transition
- 如果超过n个transition时,删除最早进入容器的transition
- 容器容量(buffer capacity)n为一个超参数: n 一 般 设 置 为 较 大 的 数 , 如 1 0 5 ∼ 1 0 6 具 体 大 小 取 决 于 任 务 n一般设置为较大的数,如10^5\sim 10^6\\具体大小取决于任务 n一般设置为较大的数,如105∼106具体大小取决于任务
2.2 计算步骤
- 最小化目标为: L ( W ) = 1 T ∑ t = 1 T δ t 2 2 L(W)=\frac{1}{T}\sum_{t=1}^{T} \frac{\delta_t^2}{2} L(W)=T1t=1∑T2δt2
- 使用随机梯度下降(SGD)进行更新:
- 从buffer中随机抽样: ( s i , a i , r i , s i + 1 ) (s_i,a_i,r_i,s_{i+1}) (si,ai,ri,si+1)
- 计算TD Error: δ i \delta_i δi
- 随机梯度为: g i = ∂ δ i 2 2 ∂ W = δ i ⋅ ∂ Q ( s i , a i ; W ) ∂ W g_i=\frac{\partial \frac{\delta_i^2}{2}}{\partial W}= \delta_i \cdot \frac{\partial Q(s_i,a_i;W)}{\partial W} gi=∂W∂2δi2=δi⋅∂W∂Q(si,ai;W)
- 梯度更新: W ← W − α g i W\gets W-\alpha g_i W←W−αgi
2.3 经验回放的优点
- 打破了序列相关性
- 重复利用过去的经验
3. 改进的经验回放(Prioritized experience replay)
3.1 基本思想
- 不是所有transition都同等重要
- TD error 越大,则transition更重要: ∣ δ t ∣ |\delta_t| ∣δt∣
3.2 重要性抽样(importance sampling)
用非均匀抽样替代均匀抽样
3.2.1 抽样方式
- p t ∝ ∣ δ t ∣ + ϵ p_t \propto |\delta_t|+\epsilon pt∝∣δt∣+ϵ
- transition依据TD error进行降序处理,rank(t)代表第t个transition:
p
t
∝
1
r
a
n
k
(
t
)
+
ϵ
p_t \propto \frac{1}{rank(t)}+\epsilon
pt∝rank(t)1+ϵ
总而言之,TD error越大,被抽样的概率越大,通常按Mini-batch进行抽样。
3.2.2 学习率变换(scaling learning rate)
为了抵消不同抽样概率造成的学习偏差,需要对学习率进行变换
- SGD: W ← W − α ⋅ g W\gets W-\alpha \cdot g W←W−α⋅g
- 均匀抽样:学习率对于所有transition都一样(转换因子为1): p 1 = p 2 = . . . = p n p_1=p_2=...=p_n p1=p2=...=pn
- 非均匀抽样:高概率对应低学习率: ( n ⋅ p t ) − β β ∈ [ 0 , 1 ] (n\cdot p_t)^{-\beta}\\ \beta \in [0,1] (n⋅pt)−ββ∈[0,1]网络刚开始训练时,β设置较小,随着网络训练,逐渐增加β至1。
3.2.3 训练过程
- 如果一个transition最近被收集,还未知其TD Error,将其TD Error设为最大值,即具有最高的优先级。
- 每次从replay buffer中选取出一个transition,然后更新其TD Error: δ t \delta_t δt
3.3 总结
| transition | sampling probabilities | learning rates |
|---|---|---|
| ( s t , a t , r t , s t + 1 ) (s_t,a_t,r_t,s_{t+1}) (st,at,rt,st+1) | p t ∝ ∣ δ t ∣ + ϵ p_t \propto |\delta_t|+\epsilon pt∝∣δt∣+ϵ | α ⋅ n ⋅ ( p t ) − β \alpha \cdot n\cdot (p_t)^{-\beta} α⋅n⋅(pt)−β |
| ( s t + 1 , a t + 1 , r t + 1 , s t + 2 ) (s_{t+1},a_{t+1},r_{t+1},s_{t+2}) (st+1,at+1,rt+1,st+2) | p t + 1 ∝ ∣ δ t + 1 ∣ + ϵ p_{t+1}\propto |\delta_{t+1}|+\epsilon pt+1∝∣δt+1∣+ϵ | α ⋅ n ⋅ ( p t + 1 ) − β \alpha \cdot n\cdot (p_{t+1})^{-\beta} α⋅n⋅(pt+1)−β |
| ( s t + 2 , a t + 2 , r t + 2 , s t + 3 ) (s_{t+2},a_{t+2},r_{t+2},s_{t+3}) (st+2,at+2,rt+2,st+3) | p t + 2 ∝ ∣ δ t + 2 ∣ + ϵ p_{t+2}\propto |\delta_{t+2}|+\epsilon pt+2∝∣δt+2∣+ϵ | α ⋅ n ⋅ ( p t + 2 ) − β \alpha \cdot n\cdot (p_{t+2})^{-\beta} α⋅n⋅(pt+2)−β |
本文内容为参考B站学习视频书写的笔记!
by CyrusMay 2022 04 10
我们在小孩和大人的转角
盖一座城堡
——————五月天(好好)——————

















 3133
3133

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









