









1.介绍
AVOD(Aggregate View Object Detection)算法和MV3D算法在思路上非常相似,甚至可以说,AVOD是MV3D的升级版本
总的来说,和MV3D相比,AVOD主要做了以下一些改进:
(1)MV3D中使用VGG16的一部分进行特征提取。在AVOD中,作者使用了引入FPN层的Encoder-Decoder结构进行高分辨率点云和图片特征提取(如下图示);
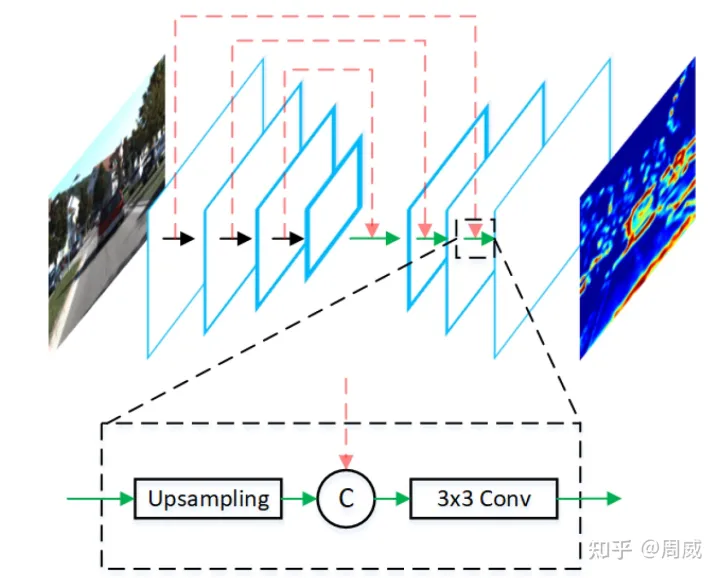 图1 AVOD中的特征提取层D
图1 AVOD中的特征提取层D
(2)MV3D中使用8个角点(每个角点由一个三维坐标表示)描述3D BBox。在AVOD中,作者使用4个角点(只包含x,y)和2个高度(共4*2+2=10)来描述一个3D BBox。

(3)还有一些改动我们后面再说
2 AVOD网络结构和流程
AVOD的网络结构如下图所示。
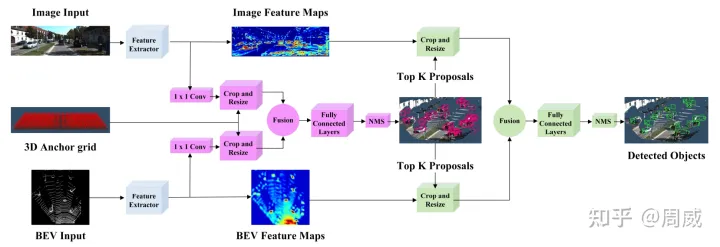
具体包括:
输入——>特征提取——>1×1卷积——>裁剪和大小缩放——>特征融合——>全连接——>NMS——>裁剪和大小缩放——>特征融合——>全连接——>NMS
2.1 输入
从图中可以看出,网络的输入有两个(并不是三个,3D Anchor grid某种意义上不算输入)。这两个输入分别为(1)图片输入;(2)俯视视角的3D点云数据。
图片数据不多说,就是前视图。BEV数据由两部分组成,分别为(1)高度图;(2)密度图。这里和MV3D不同的是,MV3D中还有强度图,AVOD作者觉得强度图的增益并不多,就把这个图给删了,这样还能降低计算量。
(a)高度图的获取方式:
选择点云数据的BEV视角[-40,40] × [0,70]的区域,划分为0.1米大小的一个个小方格(假设方格是个数是 H H H× W W W)。在每个小方格里,将高度区域为 [0,2.5] 划分为M个切片,每个切面范围内找到最大高度点云对应的高度即可。这样总共获得了 H H H× W W W× M M M大小的高度图输入。
(b)密度图的获取方式:
每个单元格的密度计算公式为 m i n min min( 1.0 1.0 1.0, l o g ( N + 1 ) l o g 16 \frac{log(N+1)}{log16} log16log(N+1)),其中N是单元格里点云数量。
2.2 特征提取
Feature Extractor的结构在图1中已经给出了,其实这种结构在图像分割领域非常常见,结构这块就不多说了。
至于作者为什么选择这种Encoder-Decoder的结构(引入FPN层代替VGG16),是因为在MV3D中,像行人这样的小物体的俯视图中本身就很小,然后进行特征提取后,长宽会被进一步地被压缩,以至于在特征图上可能都占不了一个像素点,那么对这类小物体的检测精度就不够了。
2.3 1 1 1 × 1 1 1 卷积
特征提取结束后,作者先利用卷积操作对特征图进行降维。为什么要用卷积进行降维呢?
论文中作者提到:
Attempting to extract feature crops directly from high dimensional feature maps imposes a large memory overhead per input view. As an example, extracting 7 x 7 feature crops for 100K anchors from a 256-dimensional feature map requires around 5 gigabytes1 of memory assuming 32-bit floating point representation
总结来说,也就是不降维的话,模型在提取feature crops的时候内存消耗会非常大。
2.4 裁剪和大小缩放
这一步其实也不难理解,我们现在有很多3D Anchor(输入的3D Anchor grid)。我们要将这些3D Anchor映射到俯视视角和前视视角。那么就分别获得了这两个视角各自的2D Anchor(分别记做A和B,A为BEV视角2D Anchor,B为图片视角2D Anchor)。
然后将这些2D Anchor作为待裁剪的区域,分别裁剪由特征网络和 1 1 1 × 1 1 1 卷积输出的BEV特征图(记做C)和RGB特征图(记做D)。裁剪后统一将裁剪的区域缩放到 7 7 7 × 7 7 7大小。
这里贴一下代码实现,具体如下:
# Do ROI Pooling on BEV
# self._proposal_roi_crop_size = [7,7]
bev_rois = tf.image.crop_and_resize(
bev_feature_maps,
bev_proposal_boxes_norm_tf_order,
tf_box_indices,
self._proposal_roi_crop_size,
name='bev_rois')
# Do ROI Pooling on image
img_rois = tf.image.crop_and_resize(
img_feature_maps,
img_proposal_boxes_norm_tf_order,
tf_box_indices,
self._proposal_roi_crop_size,
name='img_rois')
2.5 特征融合
完成裁剪和大小缩放后,将裁剪的BEV特征图(记做C)和RGB特征图(记做D)按位均值操作,即可完成融合。
2.6 全连接和NMS
融合的特征用作两个全连接层的输入,一个全连接层用来进行3D BBox的回归,另一个全连接层用来进行前景/背景置信度的估计。
回归的参数为
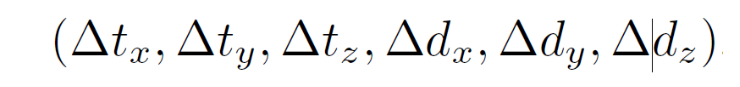
前三个为Anchor和Ground-Truth之间中心点的偏移,后三个为Anchor和Ground-Truth之间尺度(长宽高)的比例的对数。(与MV3D相同)
文章选用了Smooth L1损失进行回归,选用了交叉熵用于前景背景分类。至此,作者完成了第一轮粗略的RPN操作。
2.7 更细粒度的Region Proposal
上面我们进行了一轮完成的RPN过程,粗略地获得了一系列看起来还可以的3D BBox。但是还是不够,因为框还是比较多,位置也不足够准确。
所以作者又进行了一轮RPN。过程是
(1)先在粗略选择的Proposal中选择前K个最好的3D BBox
(2)然后继续将这些3D BBox映射到BEV视角和前视视角,分别获得对应视角上的2D BBox
(3)利用BEV视角的2D BBox在BEV特征上进行裁剪和Resize,得到裁剪重塑的BEV特征
(4)利用前视视角的2D BBox在图像特征上进行裁剪和Resize,得到裁剪重塑的图像特征
(5)利用按位平均操作,实现裁剪重塑的BEV特征和裁剪重塑的图像特征的融合
(6)全连接层引出三个分支,分别用于处理融合特征,得到三个输出,输出内容为输出框的位置回归,朝向估计以及类别分类。
(7)完成
上述有关朝向估计,作者在原论文中也做了特别的说明。
作者提到了在MV3D中,朝向估计是依赖于长边估计的,也就是检测出来的3D检测框的哪个边最长,朝向就沿着这个方向。
当然,这会有两个问题。其一就是车辆可能符合这样的规律,但行人不一定符合这个设定。其二就是,假设长边确定了,可能有两个相差180度的方向都沿着这个长边。如下图4所示,假设知道了BEV视角的检测框(绿色),可能有两个相差180的朝向都沿着长边。
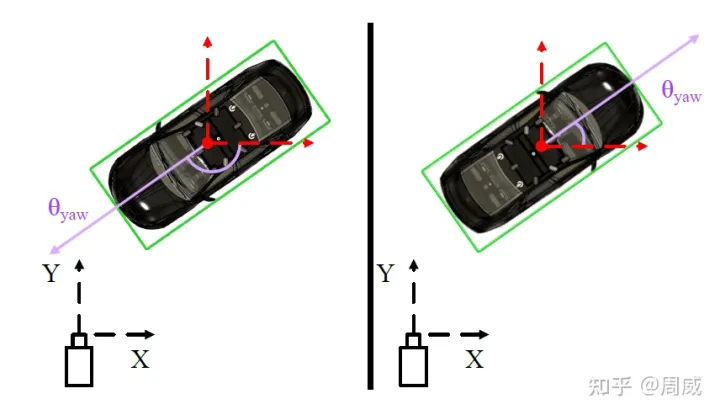
为了避免这样的歧义,作者引入了两个角度 (
x
θ
x_{θ}
xθ,
y
θ
y_{θ}
yθ)
=
=
=
(
c
o
s
θ
,
s
i
n
θ
)
(cosθ,sinθ)
(cosθ,sinθ) 约束朝向。

















 3722
3722

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









