







参考文献:
https://zhuanlan.zhihu.com/p/86340957
https://zhuanlan.zhihu.com/p/354842740
https://www.guyuehome.com/39798
https://zhuanlan.zhihu.com/p/40271319
1,配置环境
conda create -n avod python=3.5
conda install tensorflow-gpu=1.3.0
conda install matplotlib
conda install -c conda-forge opencv
conda install pandas
conda install pillow
conda install scipy
pip3 install -U scikit-learn
1.1 解决conda install py-opencv 时出现 failed with initial frozen solve. Retrying with flexible solve 的问题
pip3 install --upgrade pip
pip install opencv-python
1.2 import tensorflow TypeError: init() got an unexpected keyword argument 'serialized_options
conda remove tensorflow-gpu
pip uninstall tensorflow
conda install tensorflow-gpu=1.3.0
重装tensorflow,版本冲突
2,下载代码编译代码
代码地址:https://github.com/Qin-xs/avod_Re
2.1 wavedata依赖库
它的目录在 wavedata/wavedata/tools/core/lib 中,在lib文件夹下按顺序执行下列指令
conda activate avod
cd src
cmake ..
make
2.2 protobuf文件
protobuf是google的一个开源的用来做数据通信的库,关于它的介绍大家有兴趣可以去网上查。在avod/protos文件中有很多.proto文件,这些文件定义了通信用的数据内容和格式,但是想在程序中使用他们,得使用protobuf对他们进行编译,给每个.proto文件生成一个python文件。编译也很简单,执行下面一条指令就行.
protoc avod/protos/*.proto --python_out=
执行中之后会提示你有语法错误,不用管他,看avod/protos文件中是否生成了python文件,只要生成了,这一步就可以结束了。
3 配置环境
工程是基于python编写的,定义了很多模块,这些模块之间需要互相调用,但各个模块又是相对独立的,所以需要把各个模块的路径添加到python的环境变量中,以方便他们之间互相调用。
在终端输入这条指令打开设置环境变量的文件
sudo vim ~/.bashrc
在文件的最后输入添加下面两行(注意,这里面的路径是绝对路径,这是我电脑里的路径,大家要根据自己电脑的存放路径来改)
export PYTHONPATH=$PYTHONPATH:'/home/siat/project/project_detect/avod_Re/wavedata'
export PYTHONPATH=$PYTHONPATH:'/home/siat/work/object_detection/avod_Re-master'
配置环境变量以后,为了让它生效,需要重新打开终端,然后再使用如下指令重新进入anaconda环境
source ~/.bashrc
conda activate avod
4, 准备数据集
4.1 下载数据集
https://www.cvlibs.net/datasets/kitti/eval_object.php?obj_benchmark=3d
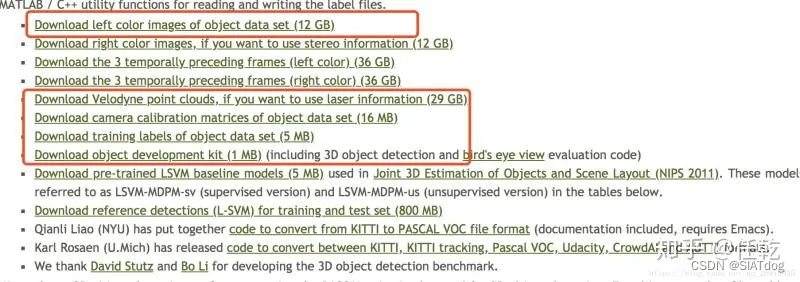
4.2 下载附加文件
这个附加数据文件包括两部分:
trainval.txt、train.txt、val.txt:这三个文件帮助程序把训练数据又重新分为训练集和验证集
planes:这个是作者自己生成的路面平面拟合参数,它的用处等我们后面讲详细代码时再讲
下载地址为:https://drive.google.com/drive/folders/1yjCwlSOfAZoPNNqoMtWfEjPCfhRfJB-Z
4.3 整理数据目录
程序读取文件是按照一定的目录结构读取的,它们的目录结构如下图:
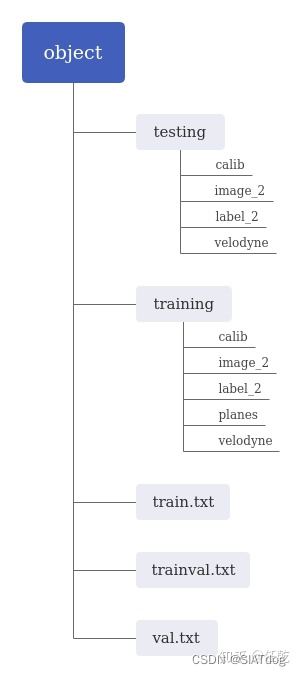
要注意的是,testing和training中都有image_2、velodyne两个文件夹,但它们的内容是不同的,分别是测试集和训练集中的内容,而它们都有的calib、label_2两个文件夹中的内容是相同的。
object文件夹放在~/Kitti/文件夹中,这是程序默认的,如果不想放这个目录里,得修改程序,所以我们先不找这个麻烦了,就先放这了。
mkdir -p ~/Kitti/object/
5,生成Mini-batch
Mini-batch 是 RPN 所需要的东西,在终端中输入如下指令即可生成
python scripts/preprocessing/gen_mini_batches.py
执行过程需要几分钟,等一等吧。
如果成功,会在avod/data目录下生成label_clusters和mini_batches两个文件夹
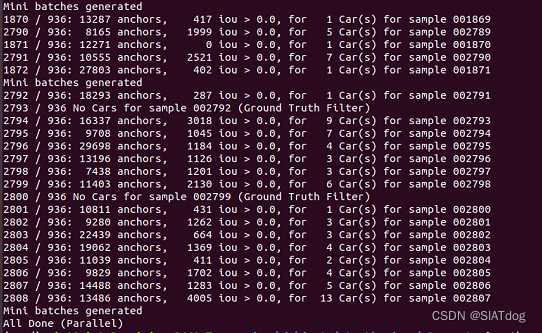
终端会显示下面的图像
6,训练
一条指令启动训练
python avod/experiments/run_training.py --pipeline_config=avod/configs/pyramid_cars_with_aug_example.config --device='0' --data_split='train'
终端会显示以下图像:

在我的电脑配置下需要执行十几个小时左右,跑一晚上就好了,我的电脑GPU型号是:GTX 3090
7,验证
执行如下命令:
python avod/experiments/run_evaluation.py --pipeline_config=avod/configs/pyramid_cars_with_aug_example.config --device='0' --data_split='val'
如果这时候会提示如下信息
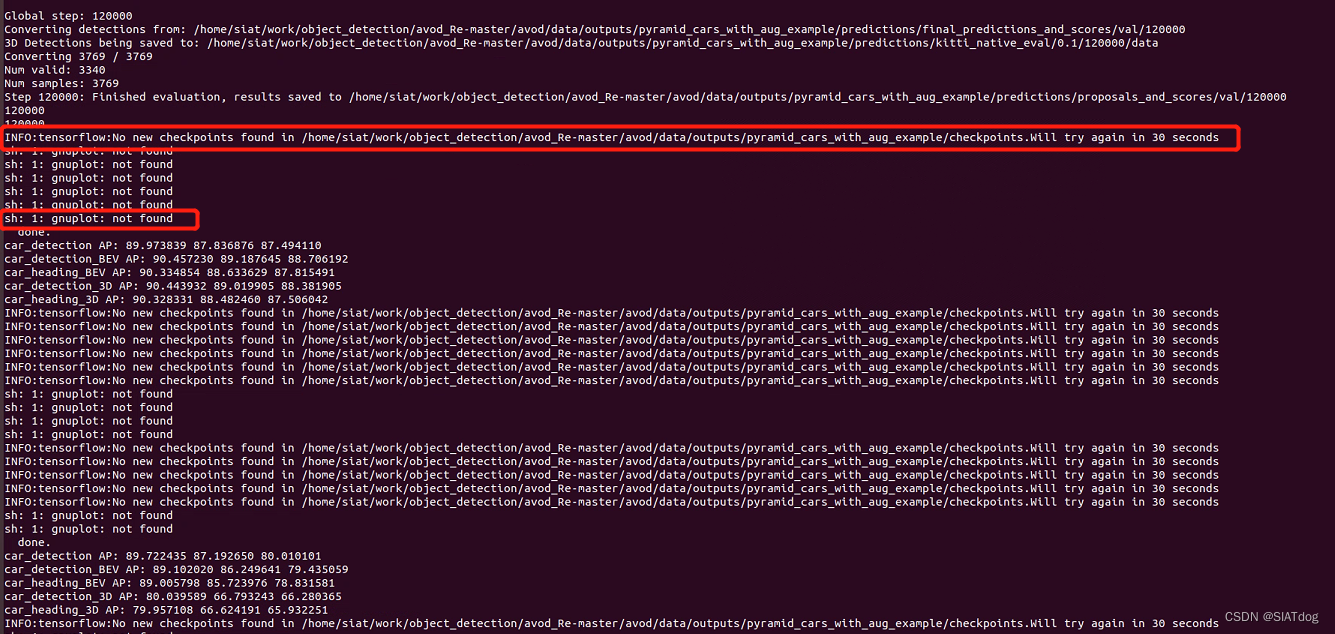
INFO:tensorflow:No new checkpoints found in /home/avod/avod/data/outputs/pyramid_cars_with_aug_example/checkpoints. Will try again in 30 seconds
第一种解决方法:
在avod/configs/pyramid_cars_with_aug_example.config 里面将pyramid_cars_with_aug_example/改为pyramid_cars_with_aug_example/checkpoints/
失败
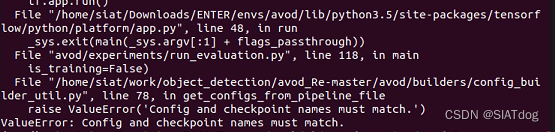
第二种解决方法:
将avod/core/evaluator.py #449 pyramid_cars_with_aug_example,然后把它改成你自己outputs下的真实文件夹名字就行

在我的电脑配置下需要执行30小时左右
接着等吧
执行完以后使用下面的指令调用tensorboard画出训练过程中的各个指标的变化趋势
conda install -c conda-forge tensorboard
cd avod/data/outputs/pyramid_cars_with_aug_example
tensorboard --logdir logs
7.2 TensorFlow错误:TypeError: init() got an unexpected keyword argument ‘serialized_options’
问题其实很简单,TensorFlow和protobuf的版本不匹配,
pip install -U protobuf
7.3 AttributeError: module ‘tensorflow.python.estimator.estimator_lib’ has no attribute ‘SessionRunHook’
问题其实很简单,TensorFlow和tensorboard的版本不匹配,
tensorboard 1.15.0
tensorflow 1.3.0
pip uninstall tensorboard
pip install tensorboard==1.11.0
居然成功
注意,这只是调用了tensorboard,输入指令以后终端会给出如下提示
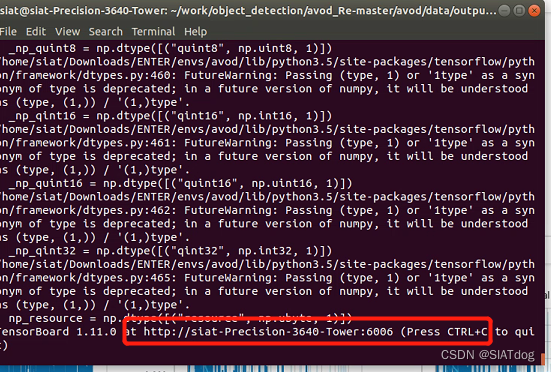
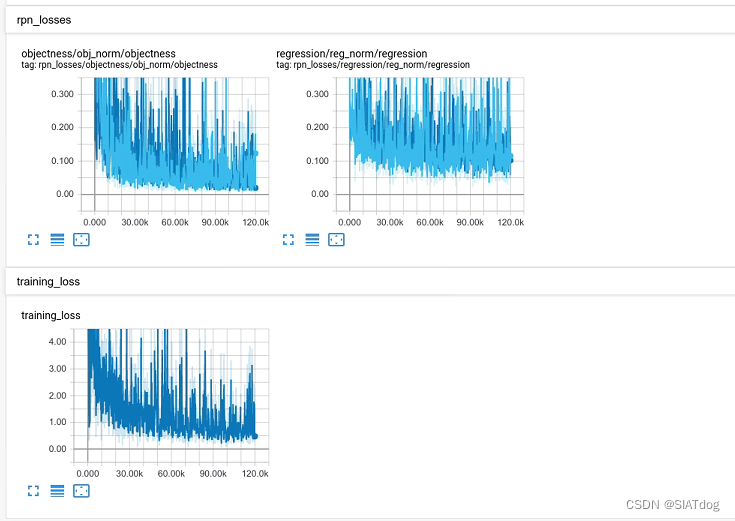
这告诉我们,如果想看变化趋势的曲线,需要在浏览器中打开终端提示的网址,我的曲线如下图所示

我们可以看到,里面有rpn_loss、avod_loss等指标的变化趋势(感觉跳动有点大)

8, Inference
执行run inference,执行这一步是干啥的,暂时还不清楚
python avod/experiments/run_inference.py --checkpoint_name='pyramid_cars_with_aug_example' --data_split='val' --ckpt_indices=120 --device='0'
9, 查看结果
这一步是生成带预测框的2d图片,输入指令
python demos/show_predictions_2d.py
会生成图片,自动存放在文件夹avod/data/outputs/pyramid_cars_with_aug_example/predictions/images_2d/predictions/val/120000/0.1中
这里放几张图片看下效果吧

到这里,就完成网络所有的训练和使用流程了。















 3242
3242











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









