






🌐 社群导航
🔗 点击加入➡️【AIGC/LLM/MLLM/3D/自动驾驶】 技术交流群
最新论文解读系列

论文名:Temporal Regularization Makes Your Video Generator Stronger
论文链接:https://arxiv.org/pdf/2503.15417
开源代码:https://haroldchen19.github.io/FluxFlow/

导读
时间质量是视频生成的一个关键方面,因为它能确保各帧之间的运动连贯和动态逼真。然而,实现高时间连贯性和多样性仍然具有挑战性。在这项工作中,我们首次探索了视频生成中的时间增强方法,并引入了用于初步研究的FLUXFLOW,这是一种旨在提升时间质量的策略。FLUXFLOW在数据层面操作,无需对架构进行修改即可应用可控的时间扰动。在UCF - 101和VBench基准测试上的大量实验表明,FLUXFLOW显著提升了包括U - Net、DiT和基于自回归(AR)架构等各种视频生成模型的时间连贯性和多样性,同时保留了空间保真度。这些发现凸显了时间增强作为一种简单而有效的方法在提升视频生成质量方面的潜力。
简介
追求逼真的视频生成面临着一个关键困境:虽然空间合成(例如,StableDiffusion系列、基于自回归(AR)的方法)已经实现了显著的保真度,但确保时间质量仍然是一个难以实现的目标。现代视频生成器,无论是扩散模型还是自回归模型,经常生成存在时间伪影的序列,例如闪烁的纹理、不连续的运动轨迹或重复的动态,这暴露了它们无法稳健地建模时间关系的问题(见图1)。
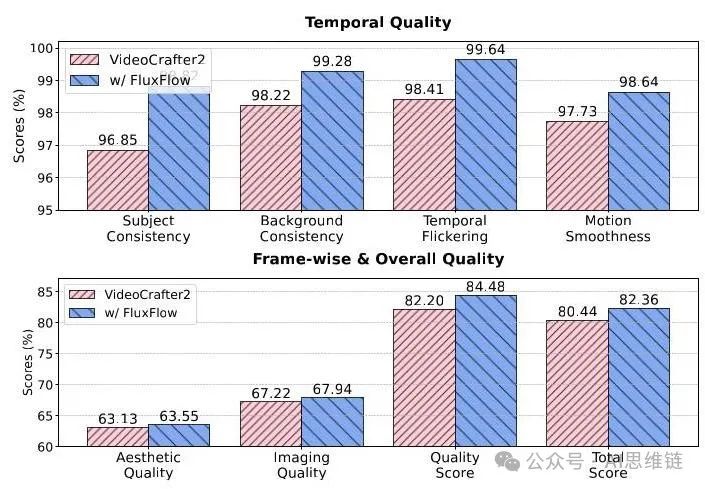
图2. 使用VBench指标对VideoCrafter2和FLUXFLOW在时间质量(上)以及逐帧和整体质量(下)方面进行的比较。FLUXFLOW在显著提升生成视频的时间质量的同时,还能保持甚至提高逐帧和整体质量。
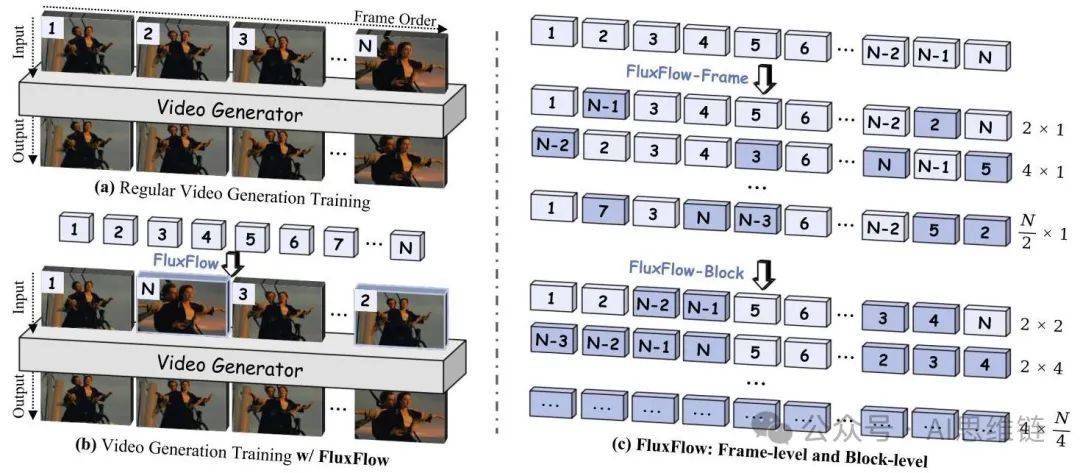
图3. FLUXFLOW概述。(a) 标准视频生成在固定的帧顺序上进行训练,这可能会限制模型学习时间动态的能力。(b) FLUXFLOW在训练期间引入可控的时间扰动,作为一种即插即用的增强策略。(c) 本研究从两个层面探索FLUXFLOW:帧级(上)和块级(下)。在帧级中,Num 表示被打乱的单个帧的数量。在块级中,Num1 Num2表示一个由Num2个连续帧组成的块。
方法
1. 预备知识
现代视频生成模型主要分为三种范式:基于U - Net的、基于扩散变换器(DiT)的和基于自回归(AR)的。本节概述了用于U - Net和DiT的(潜在)扩散模型,以及基于AR方法的下一个令牌预测。
扩散模型(Diffusion Models,DMs)是概率生成框架,它通过前向过程将数据逐渐破坏成高斯噪声,随后通过去噪学习逆转这一过程。前向过程定义在个时间步上,利用参数化技巧逐步向原始数据添加噪声以获得。相反,反向过程使用去噪网络对进行去噪以恢复。训练目标公式如下:
其中表示真实噪声,表示可学习参数,是可选的条件输入。模型训练完成后,通过对随机高斯噪声进行迭代去噪来生成数据。
潜在扩散模型(Latent Diffusion Models,LDMs)通过在紧凑的潜在空间中操作扩展了扩散模型,显著提高了计算效率。潜在扩散模型不是在像素空间中执行扩散过程,而是使用自动编码器将输入视频编码为潜在表示,其中。然后在潜在空间中进行扩散过程和去噪过程。训练目标与扩散模型类似,但应用于潜在表示:
最后,使用解码器将生成的潜在表示解码回像素空间,得到生成的视频。
下一令牌预测。自回归(AR)视频生成可以表述为下一令牌预测,类似于语言建模。视频通过分词器转换为离散视频令牌序列。与大语言模型(LLMs)类似,使用过去的视频令牌作为上下文来预测下一个视频令牌。具体来说,训练目标是最小化以下负对数似然(NLL)损失:
其中,预测的下一个的条件概率由具有参数的Transformer解码器建模。
2. FLUXFLOW
虽然空间增强(如翻转、裁剪)通常用于增强空间鲁棒性,但在视频生成中,时间维度的正则化仍然不足。为了弥补这一差距,我们提出了FLUXFLOW,这是一种数据级的时间增强策略,在训练期间对视频序列的时间结构进行扰动。在这一初步探索中,FLUXFLOW以两种模式运行:帧级和块级扰动,每种模式针对不同的时间尺度,如图3所示。
帧级扰动。FLUXFLOW - FRAME通过打乱序列中的单个帧来引入细粒度的干扰。如图3(c)(上)所示,给定一个视频序列
,我们随机打乱一部分帧,这由扰动比率 控制。形式上:
其中 是随机选择的帧子集,满足 。 之外的帧保持其原始位置,维持部分时间一致性。这种扰动迫使模型重建合理的时间关系,增强其超越确定性帧间依赖的泛化能力。
块级扰动。FLUXFLOW - BLOCK通过对连续的帧块重新排序,在更粗的尺度上进行操作,如图3(c)(下)所示。输入序列 被划分为 个大小为 的不重叠块,使得:
其中 。然后,这些块的一个子集 以概率 被随机重新排序,得到:
(6)
块级扰动模拟了现实中的时间干扰,例如运动速度或方向的变化,同时保留粗略的运动模式。
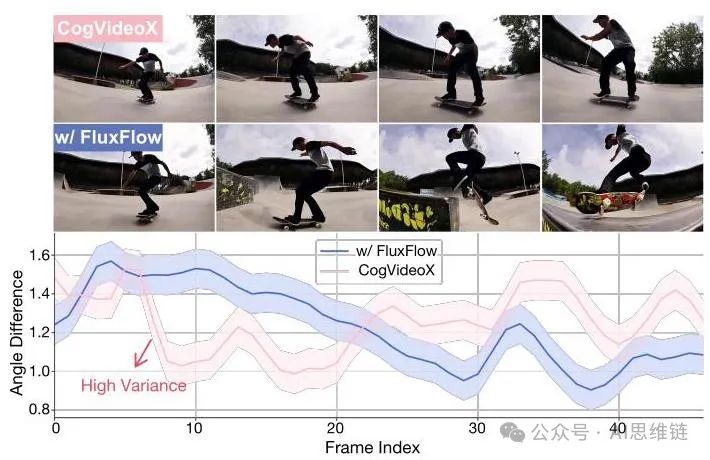
图4. FLUXFLOW增强时间连贯性的示意图。(上)来自CogVideoX的示例帧,分别为未使用和使用FLUXFLOW的情况,展示了使用后者时更大的运动动态。(下)各帧间时间角度差异的比较。FLUXFLOW始终实现较低的角度差异,表明与基础模型相比,时间连贯性得到了改善。说明:一名滑板运动员在滑板公园表演技巧,动作节奏快,相机角度动态变化。
实现。FLUXFLOW被实现为一种在训练期间应用的预处理策略。每个扰动(帧级或块级)都独立应用,以评估其对时间质量的影响。图3(b)展示了组合训练管道。下面的伪代码给出了该算法的具体示例。
算法1 FLUXFLOW伪代码

3. 使用FLUXFLOW模型学到了什么?
为了更好地理解FLUXFLOW对模型时间学习能力的影响,我们评估了它对时间连贯性和时间多样性的影响。为此,我们选择了三组具有不同时间动态的文本提示:静态、慢速和快速(详细信息见附录§A)。我们的观察结果如下:
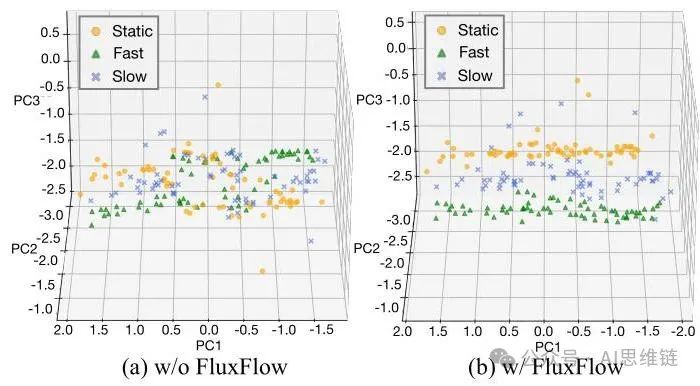
图5. FLUXFLOW改善时间特征多样性的示意图。(a) 未使用FLUXFLOW时,在固定原始帧序列上训练的模型无法区分不同时间范式的特征。(b) 使用FLUXFLOW时,特征分离更明显,反映出时间表示能力增强。
观察1:FLUXFLOW增强了时间连贯性。如图4所示,我们分析了从一个“快速”提示生成的视频。未使用FLUXFLOW生成的视频表现出突然且不稳定的时间变化,反映出不一致的运动动态。相比之下,使用FLUXFLOW生成的视频展示出明显更大且更平滑的运动动态。角度差异的定量分析进一步支持了这一观察结果。通过比较连续帧之间的角度差异,我们发现基础模型产生的这些差异具有高方差,反映出不稳定的时间过渡。相比之下,FLUXFLOW始终实现较低的角度差异,表明它能够在保持预期运动动态的同时稳定时间变化。
观察2:FLUXFLOW改善了时间多样性。图5展示了生成视频的时间特征表示。未使用FLUXFLOW时(图5(a)),从不同时间提示(静态、慢速和快速)生成的视频特征大部分重叠,表明模型难以区分不同的时间范式。这种缺乏分离反映了基线模型无法捕捉多样的时间动态。相比之下,使用FLUXFLOW时(图5(b)),时间特征在三种时间范式中分离更明显,反映出模型表示多样时间模式的能力增强。
这些发现凸显了FLUXFLOW在提高基线模型时间能力方面的关键作用,使它们能够生成时间上一致且多样的视频,更符合输入提示的预期运动动态。
实验
在本节中,我们进行了广泛的实验,以回答以下研究问题(RQ):
:FLUXFLOW能否在保持空间保真度的同时提高时间质量?
2:FLUXFLOW是否有助于学习运动/光流动力学?
3:FLUXFLOW能否在长期生成中保持时间质量?
:FLUXFLOW对其关键超参数的敏感度如何?
1. 实验设置
基础模型。为了全面评估FLUXFLOW的有效性,我们将其应用于三种不同的视频生成架构:(i)基于U-Net的:VideoCrafter2。(ii)基于自回归(AR)的:NOVA - 0.6B。(iii)基于DiT的:CogVideoX - 2B。为了确保公平和一致的比较,我们在OpenVidHD - 上使用FLUXFLOW作为额外的训练阶段对基础模型进行一个轮次的微调,遵循它们的默认配置(例如,分辨率、帧长度)。将结果与在相同设置下但未进行时间增强(即不使用FLUXFLOW)训练的模型进行比较。值得注意的是,FLUXFLOW与模型无关,可以无缝集成到任何视频生成架构的训练流程中。
评估。我们在两个广泛使用的视频生成基准上评估FLUXFLOW,重点关注时间连贯性和整体视频质量:
-
UCF - 101:一个大规模的人类动作数据集,包含101个动作类别的13320个视频。我们使用以下指标:
(i)弗雷歇视频距离(Fréchet Video Distance,FVD),用于评估时间连贯性和运动真实感。
(ii)Inception分数(Inception Score,IS),用于评估帧级质量和多样性。
-
VBench:一个综合基准,旨在从16个维度评估视频生成质量。为了具体评估时间和帧级质量,我们关注以下关键维度:
(i)时间质量:主体一致性、背景一致性、时间闪烁、运动平滑度和动态程度。
(ii)逐帧质量:美学质量和成像质量。
(iii)整体质量:总分、质量得分和语义得分。
这些基准和指标提供了全面的评估,使我们能够严格评估FLUXFLOW对时间动态和空间保真度的影响。
2. 质量和保真度提升(研究问题1)
我们在表1和表2中展示了FLUXFLOW - FRAME和FLUXFLOW - BLOCK在VideoCrafter2(VC2)、NOVA和CogVideoX(CVX)上的定量比较,并在图6中展示了定性比较。每个模型根据其默认帧长采用三种设置进行评估。具体而言,在定性比较中,FLUXFLOW - FRAME分别在VC2、NOVA和CVX上以和的形式展示。我们有以下观察结果:
表1. FLUXFLOW - FRAME的评估。“+ 原始”指不使用FLUXFLOW进行训练,而“+ 数量 × 1”表示使用不同的FLUXFLOW - FRAME策略。我们对每个模型的最佳结果进行了阴影标注,对第二佳结果进行了下划线标注。
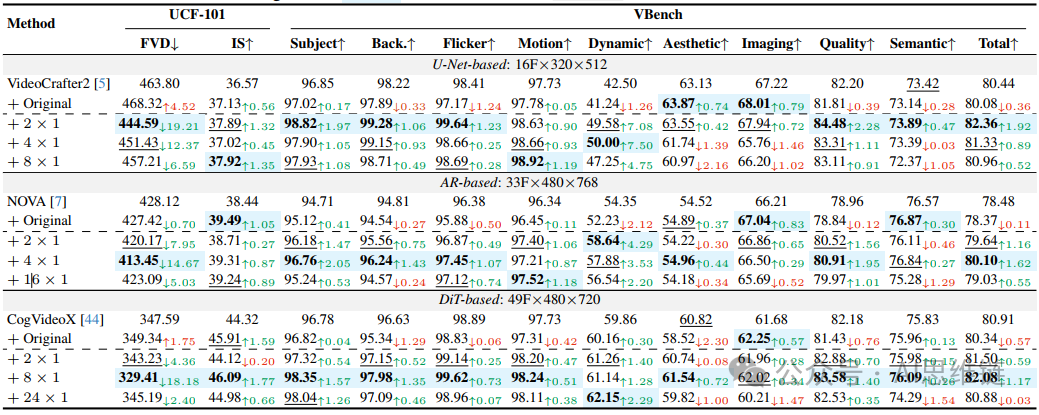
表2. FLUXFLOW - BLOCK的评估。“ + 数量1 × 数量2”表示使用不同的FLUXFLOW - BLOCK策略。
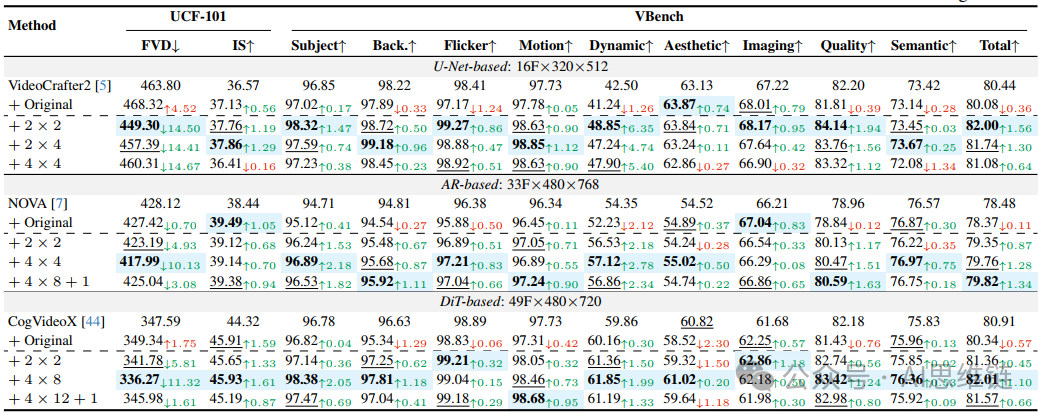
观察3:FLUXFLOW在保留空间保真度的同时提高了时间质量。FLUXFLOW-FRAME和FLUXFLOW-BLOCK都显著提高了时间质量,这在表1、表2中的指标(即FVD、主观评价、闪烁、运动和动态)以及图6中的定性结果中得到了证明。例如,在VC2中漂移汽车的运动、在NOVA中追逐自己尾巴的猫的运动,以及在CVX中冲浪者乘风破浪的运动,在使用FLUXFLOW后明显变得更加流畅。重要的是,这些时间上的改进是在不牺牲空间保真度的情况下实现的,这从水花飞溅、烟雾轨迹和波浪纹理的清晰细节以及空间和整体保真度指标中可以得到证明。
观察4:最佳的时间扰动强度因模型而异。理想的扰动强度取决于基础模型的默认帧长。例如,在表1中,16帧的VC2使用策略表现最佳,而49帧的CVX从策略中受益最大。然而,过度的扰动可能会破坏空间一致性,这凸显了在训练过程中选择特定于模型的扰动的重要性。
观察5:帧级扰动优于块级扰动。虽然帧级和块级扰动都能提高时间质量,但帧级扰动通常能带来更好的效果。这可以归因于它们更细的粒度,允许进行更精确的时间调整。相比之下,块级扰动可能由于块内更强的时空相关性而引入过多的噪声,从而限制了它们的有效性。因此,帧级策略能产生更平滑、更连贯的运动过渡。

图6. FLUXFLOW在VideoCrafter2(顶部)、NOVA(中间)和CogVideoX(底部)上的定性结果。
3. 时间动态的用户研究(研究问题2)
为了回答,我们首先参考图4,它突出了FLUXFLOW捕捉平滑连贯光流变化的能力,特别是在复杂运动场景中;以及图6,它展示了其卓越的运动真实感和动态性。基于这些发现,我们进一步对20对视频进行了用户研究(图8),以评估用户在五个维度上对运动质量的主观感知:运动多样性、运动真实感、运动平滑度、时间连贯性和光流一致性,使用两种类型的提示:动作速度(快和慢)和运动模式(线性和非线性)。我们观察到:
观察6:FLUXFLOW显著促进了时间动态学习。如图8所示,FLUXFLOW有效地分解并学习了运动动态,在复杂轨迹和快速时间变化方面表现出色。具体来说,(i)运动多样性:更广泛、更多样的运动轨迹,特别是在动态或非线性场景中。(ii)光流一致性:更平滑、更连贯的过渡,减少突然变化和伪影。(iii)运动真实感和平滑度:更自然、更流畅的运动,特别是在复杂和精细的轨迹中。(iv)时间连贯性:帧与帧之间的动态稳定,且不影响其他维度。
4. 超长序列的时间质量(研究问题3)
为了回答并评估FLUXFLOW是否能在极端条件下保持时间质量,我们特别使用16帧的VC2来生成128帧的视频,如图9所示。这使我们能够验证FLUXFLOW是否能够克服长序列生成中常见的累积误差和时间不稳定性挑战。我们给出以下观察结果:
观察7:FLUXFLOW在极端条件下能有效保持时间质量。如图9所示,定性比较(顶部)表明,FLUXFLOW保持了动态背景的一致性并生成了更平滑的过渡,而基线模型(VC2)出现了时间伪影,如闪烁和运动不一致。从定量角度(底部)来看,灰色区域突出显示了相对于原始16帧生成的得分下降情况。FLUXFLOW显著减少了这些下降,在主观一致性、背景一致性、时间闪烁和运动平滑度方面取得了更优的得分,确保了超长序列场景下的高时间质量。
5. 消融与敏感性分析(研究问题4)
为了更好地研究FLUXFLOW的有效性,我们进行了两项消融研究,以评估其对洗牌间隔约束和扰动程度的敏感性,如图7所示:(i)帧/块间隔,以及(ii)扰动程度。
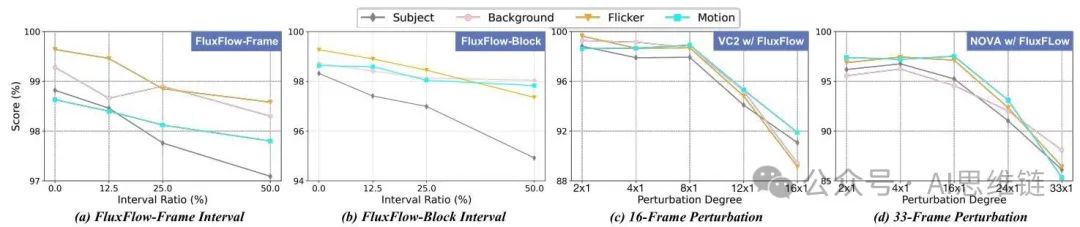
图7. 基于VBench时间指标对FLUXFLOW的消融和敏感性分析。(a,b) 使用和配置时,打乱间隔约束对VC2的影响。(c,d) 扰动程度对16帧VC2和33帧NOVA的影响。
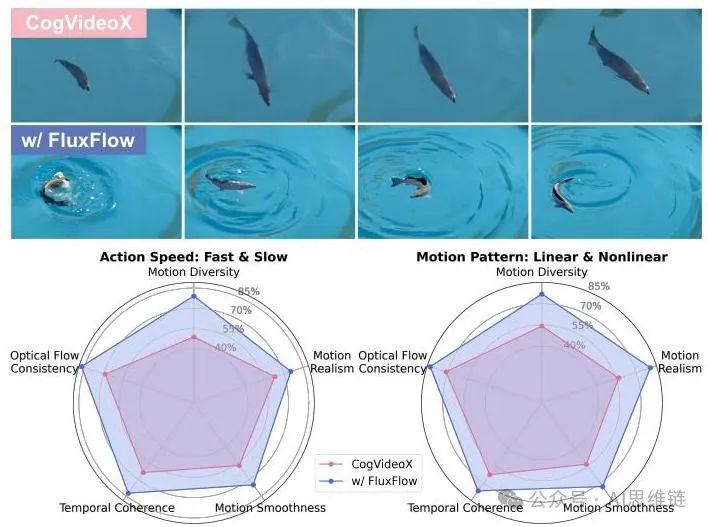
图8. 比较CVX和使用FLUXFLOW的用户研究结果。(上)来自非线性运动模式的示例帧,其中FLUXFLOW在处理复杂轨迹方面表现出色。说明:一条鱼在清澈的蓝色池塘里绕圈游动。(下)用户在时间动态评估标准上的评分。更多细节请参考附录§A。
帧/块间隔分析。我们分析了打乱间隔约束对帧级(FLUXFLOW - 帧)和块级(FLUXFLOW - 块)的影响。打乱间隔定义了打乱的帧或块之间的最小距离。例如,在间隔为8帧的帧级打乱中,任意两个打乱的帧之间必须至少间隔8帧。如图7(a,b)所示,使用和打乱配置对VC2进行消融实验表明,去除间隔约束(间隔比)在所有指标上都能取得最佳性能。较大的约束(例如或)会导致明显的性能下降。这表明允许无间隔约束的自由打乱能使模型更好地利用时间信息,支持了过度约束会降低模型学习到的时间模式多样性这一假设。
扰动程度分析。我们进一步研究了过度扰动是否会导致显著的性能下降。如图7(c,d)所示,我们对16帧VC2和33帧NOVA进行了帧级消融实验。结果表明,当扰动程度超过总帧数的一半时,性能开始显著下降。这一观察结果与Obs@一致,Obs@强调扰动超过一半的帧会因上下文信息不足而破坏模型推断正确时间顺序的能力。
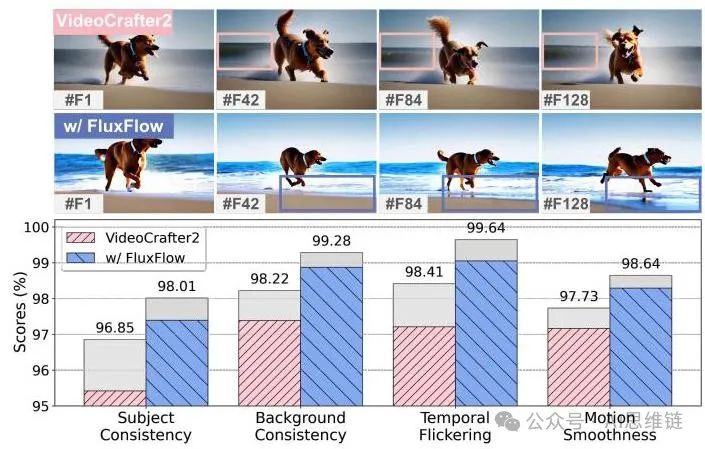
图9. 额外条件下的性能比较。(上)16帧VC2生成128帧的示例帧,分别为未使用和使用FLUXFLOW的情况,展示了使用后者时动态背景的一致性。说明:一只狗沿着海滩奔跑,在海浪中溅起水花。(下)VBench上时间质量指标的比较,灰色区域表示在额外条件场景下的性能下降。
总结
在这项工作中,我们提出了FLUXFLOW,这是一种开创性的时间数据增强策略,旨在提高视频生成中的时间质量。这一初步探索引入了两种简单而有效的方法:帧级(FLUXFLOW - 帧)和块级(FLUXFLOW - 块)。通过解决现有主要关注架构设计和条件约束方法的局限性,FLUXFLOW填补了该领域的一个关键空白。大量实验表明,集成FLUXFLOW可显著提高时间连贯性和整体视频保真度。我们相信FLUXFLOW为未来时间增强策略的研究奠定了有前景的基础,为更稳健和时间一致的视频生成铺平了道路。

















 464
464

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









