







Fast RCNN算法笔记
Fast RCNN是RCNN算法的改进版。
训练过程
对于原始一张图片,也和RCNN一样提取2000个region proposal,但输入到CNN网络的是一整张图片,而不是和RCNN一样将2000个region proposal一起输入到CNN,在经过CNN网络之后,得到特征图,然后候选区域映射到特征图后的大小不一样,但是后面是全连接层(用于分类,和RCNN的SVM分类器不同),需要特定的输入,所以就在CNN后面和全连接前面加了个ROI层,固定了特征图的输出大小。然后经过全连接后,一部分是softmax做分类损失,一部分是框的回归损失,将这两个损失函数聚合在一起,这个也是和RCNN不同,RCNN是SVM分类损失和框的回归损失分开的,更麻烦。注意Fast RCNN的region proposal没经过CNN直接到ROI池化层的。具体可以看后面结构。训练过程并不是使用了全部的2000个候选区域,而是从中随机抽取正样本和负样本,正样本的划分是候选框与真实的目标边界框IOU大于0.5的为正样本

测试过程
引用了https://blog.csdn.net/u014380165/article/details/72851319的图
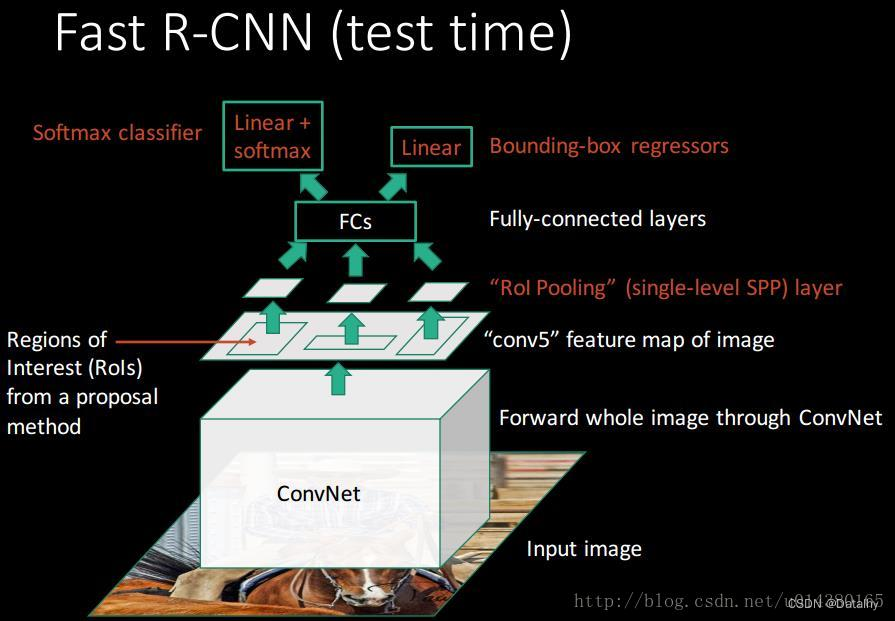
RCNN与Fast RCNN
RCNN


Fast RCNN


可以看到rcnn是4步在不同的网络中做的,fastrcnn候选区域是在ss网络选取的,特征提取,分类,回归则都是在一个CNN网络中做的,后面再想着优化,那就是把region proposal和其它几步放在一个网络中,也是Faster RCNN做的事。
总结
1、可以看到Fast RCNN卷积不再是对每一个region proposal进行,而是对整张图像,减少了很多的重复计算。是这样的,RCNN是先提取候选框然后对每一个候选框进行卷积得到特征矩阵,而FastRCNN也是先在原图上划分很多候选区,但是他只把原始的整张图放进卷积得到一个特征图,然后根据在原始图片上划分的候选区的位置映射到特征图上得到特征矩阵,怎么映射的呢?候选区域在原图上的位置按比例缩放到特征图上。这样就不用每个候选区域经过卷积再得到特征矩阵了。

2、加入了ROI pooling层对特征尺寸变换,RCNN要求输入图像要固定尺寸,会导致图像因为resize后失真,而FastRCNN随意输入图像的大小。
3、将分类和回归放在网络一起训练,用softmax代替了RCNN的SVM。















 915
915











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









