







背景
2025年1月21日,豆包实时语音大模型在豆包App(7.2.0 新春版)全量开放,引发了广泛关注。这一语音交互体验,与OpenAI公布的GPT-4o模型实时语音功能体验类似,未来拥有广阔的应用前景。
因此,本章我们深入了解豆包实时语音大模型的使用过程,并分析其背后的实现原理。
目标
基于豆包开源的Github代码,在本地搭建一个实时语音大模型,并体验其效果。
搭建过程
豆包大模型的背后支持团队 火山引擎 提供了开源代码Demo,我们基于该项目进行相关部署实践。
1. 拉取代码
git clone https://github.com/volcengine/rtc-aigc-demo
2. 注册账号
访问火山引擎官网(https://www.volcengine.com/) ,注册账号并登录。
说明:
首次注册火山引擎账号并使用,需要进行实名认证,按照官网提示完成即可。
3. 准备工作
3.1 获取API Key
-
访问火山引擎控制台https://console.volcengine.com/home
-
点击右上角个人头像->API访问密钥
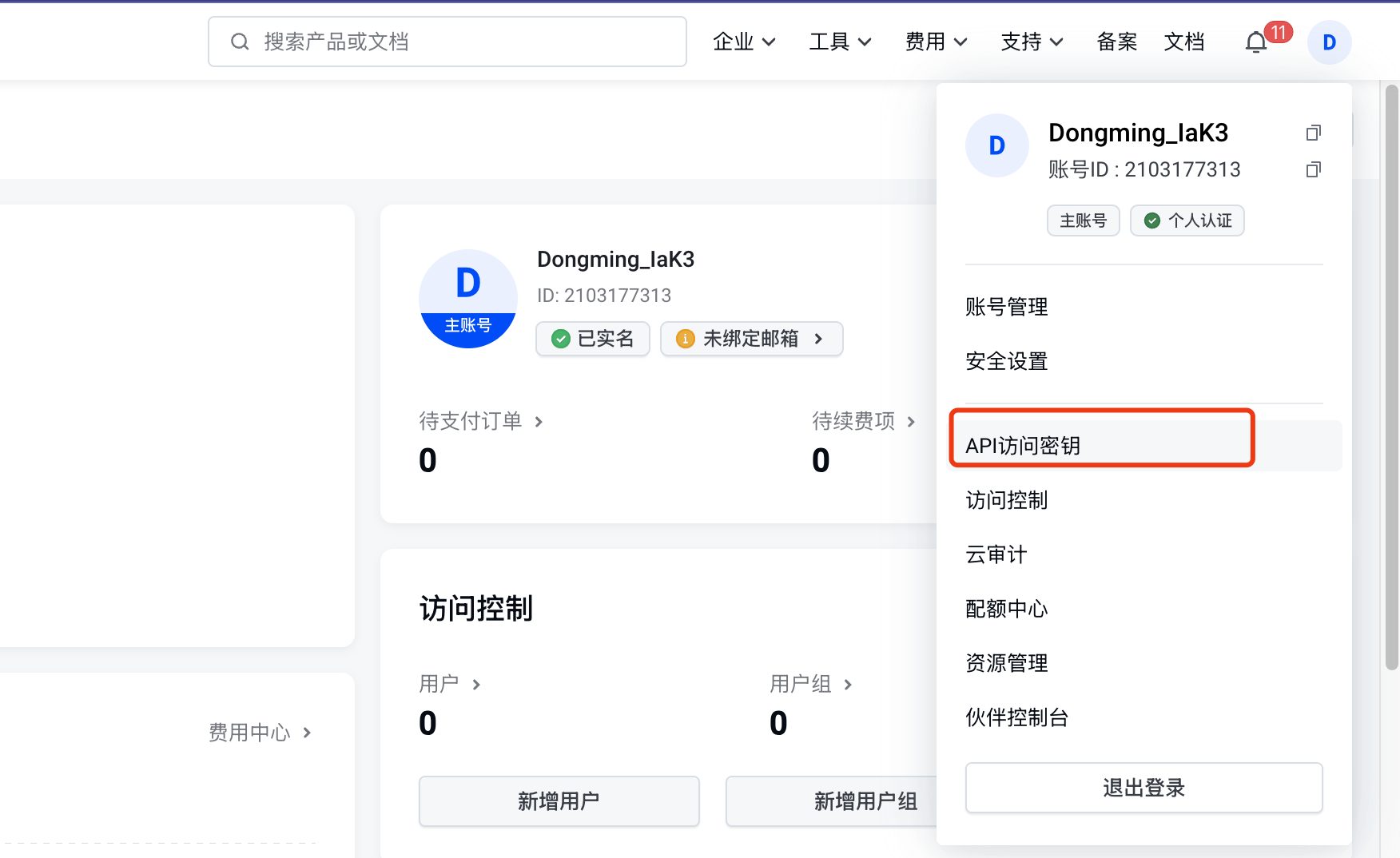
-
新建密钥
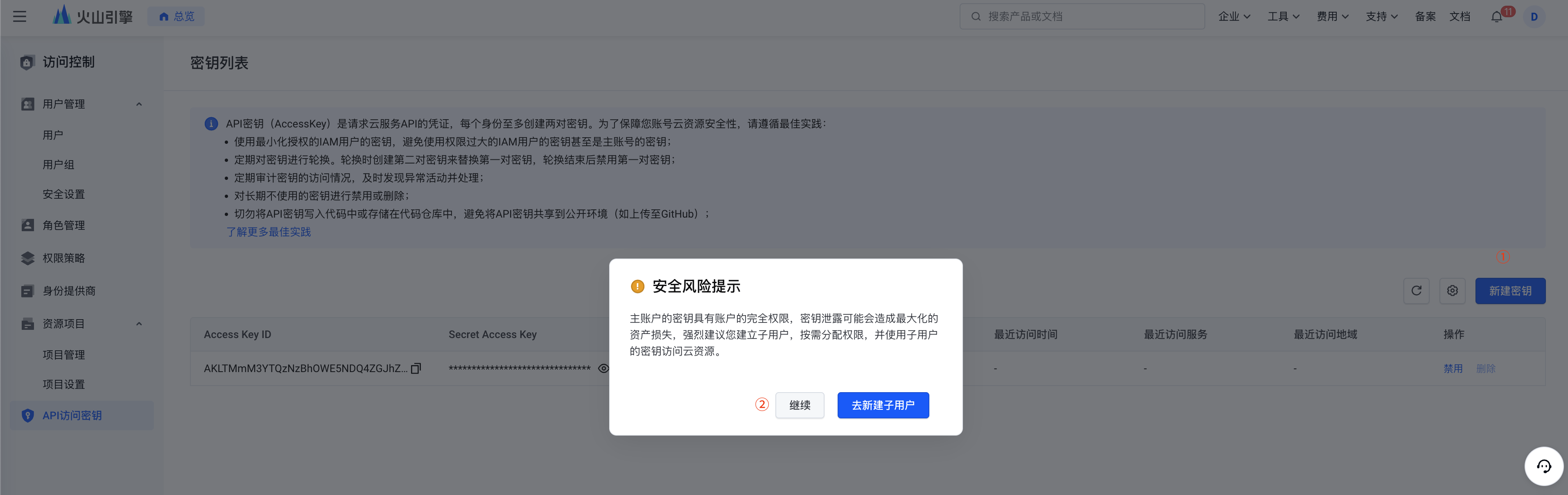
说明:
- 火山引擎API密钥分主账号和子账号,一般为了安全情况下,使用子账号。
- 本例中优先跑通流程,所以安全性要求不高,使用主账号减少操作步骤。
- 点击继续后,使用手机获取验证码,即可完成API Key创建。
3.2 开通 RTC 服务(获取AppID和AppKey)
-
访问火山引擎控制台的
实时音视频https://console.volcengine.com/rtc/guide -
申请开通 RTC 服务
-
创建应用:点击左侧应用管理->创建应用
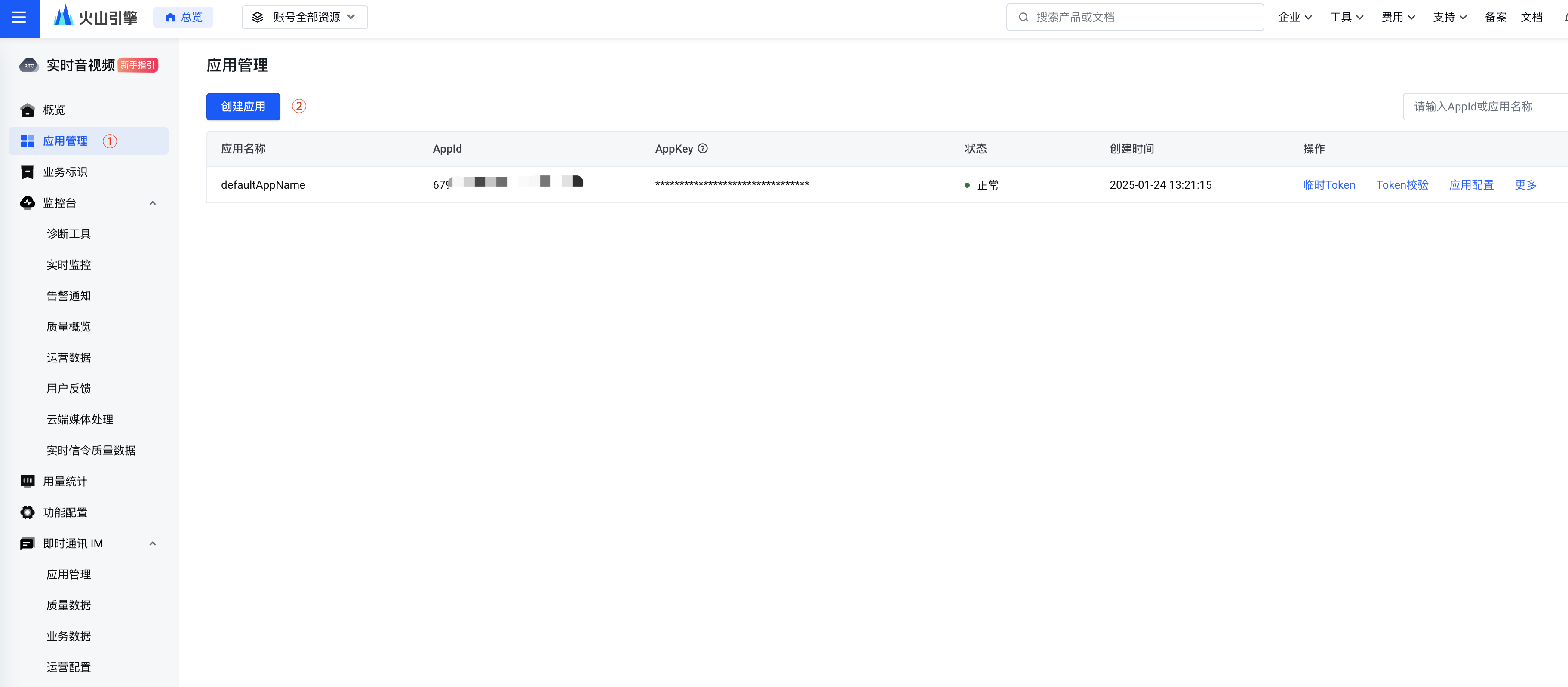
说明:
- 默认情况下,开通RTC服务后,会自动创建一个默认应用,本例中使用默认应用。
- 如果需要创建新应用,则需要填写应用名称、应用描述、应用类型、应用场景、应用权限等信息。
- 获取应用AppID和AppKey:复制默认应用的
AppID和AppKey,后续配置中需要使用。
3.3 获取临时Token
-
接着上一步的步骤,在页面中点击
临时Token
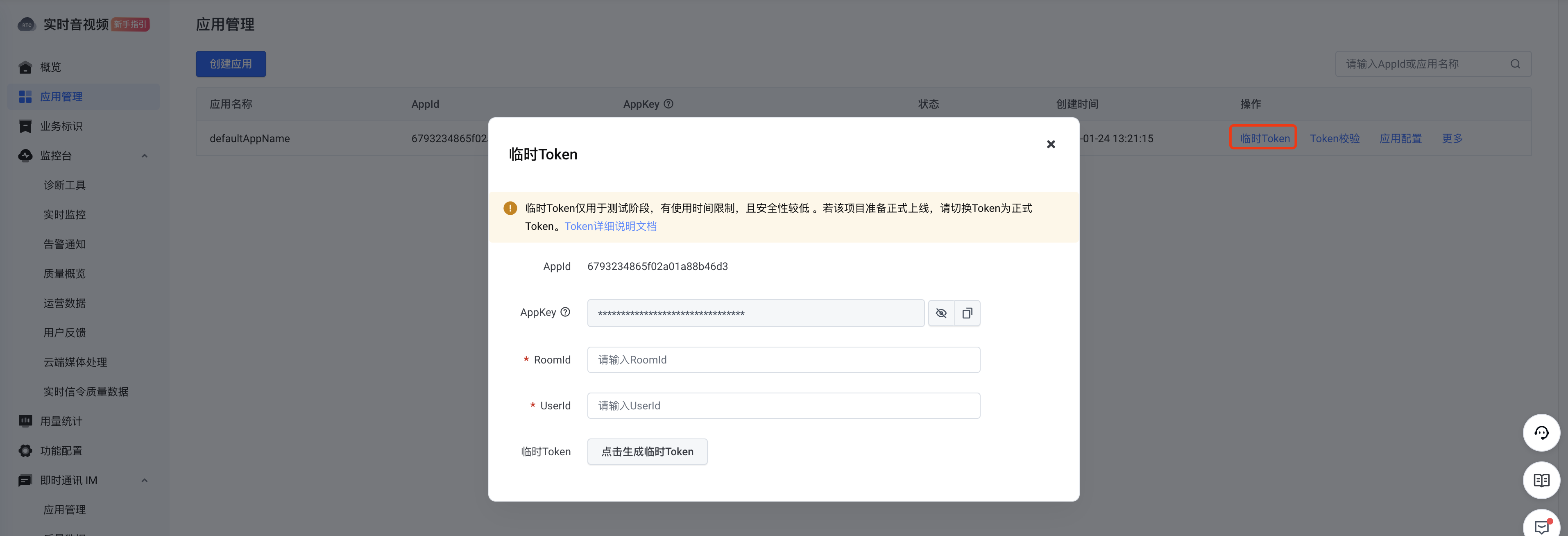
-
在弹出的页面中,输入自定义的
RoomId和UserId,点击生成临时Token
说明:
RoomId可以自定义,本例中命名为my_demo_roomUserId可以自定义,本例中命名为my_demo_user
- 获取临时Token后,复制Token,后续配置中需要使用。
3.4 开通 ASR 与 TTS 服务服务
- 访问火山引擎控制台的
语音技术https://console.volcengine.com/speech/app - 创建应用:点击左侧
应用管理->创建应用 - 根据提示,填写应用名称、应用简介,勾选语音合成、流式语音识别服务。
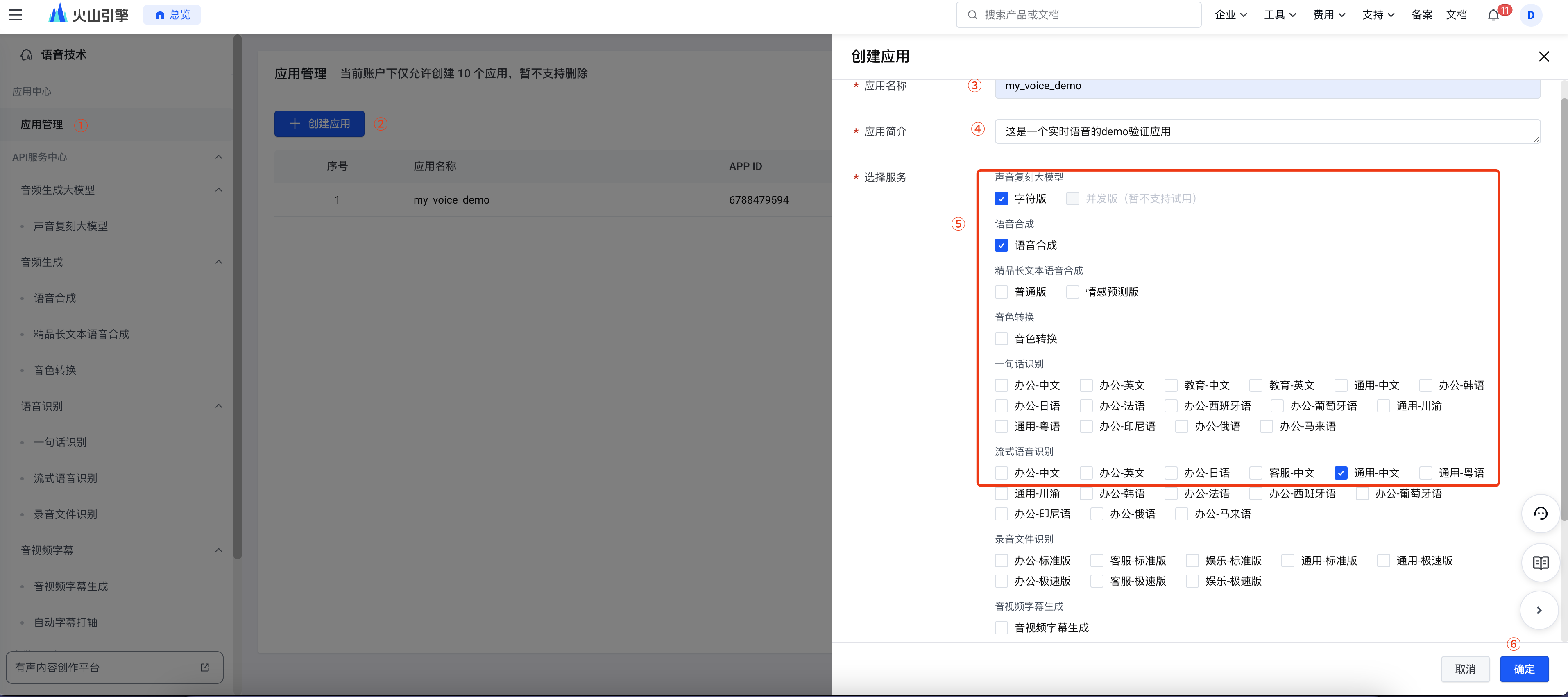
- 创建应用后,获取应用的
APP ID
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











