






数据集准备
因为我本人是更喜欢用更“现代风”一点的数据标注工具,所以这次也索性连roboflow这一个非常好用的框架也一并开荒了,当然这也并不意味着原先推荐大家的Label-Studio是不可用的,修改正确的配置问价后仍然是可用的,这里我们以roboflow进行演示。
Roboflow账号注册
首先进入到roboflow的主页点击Try Roboflow按钮进行roboflow账号的注册。

在此之后完成一系列的设置,验证工作我们会被自动跳转到主页里来了:
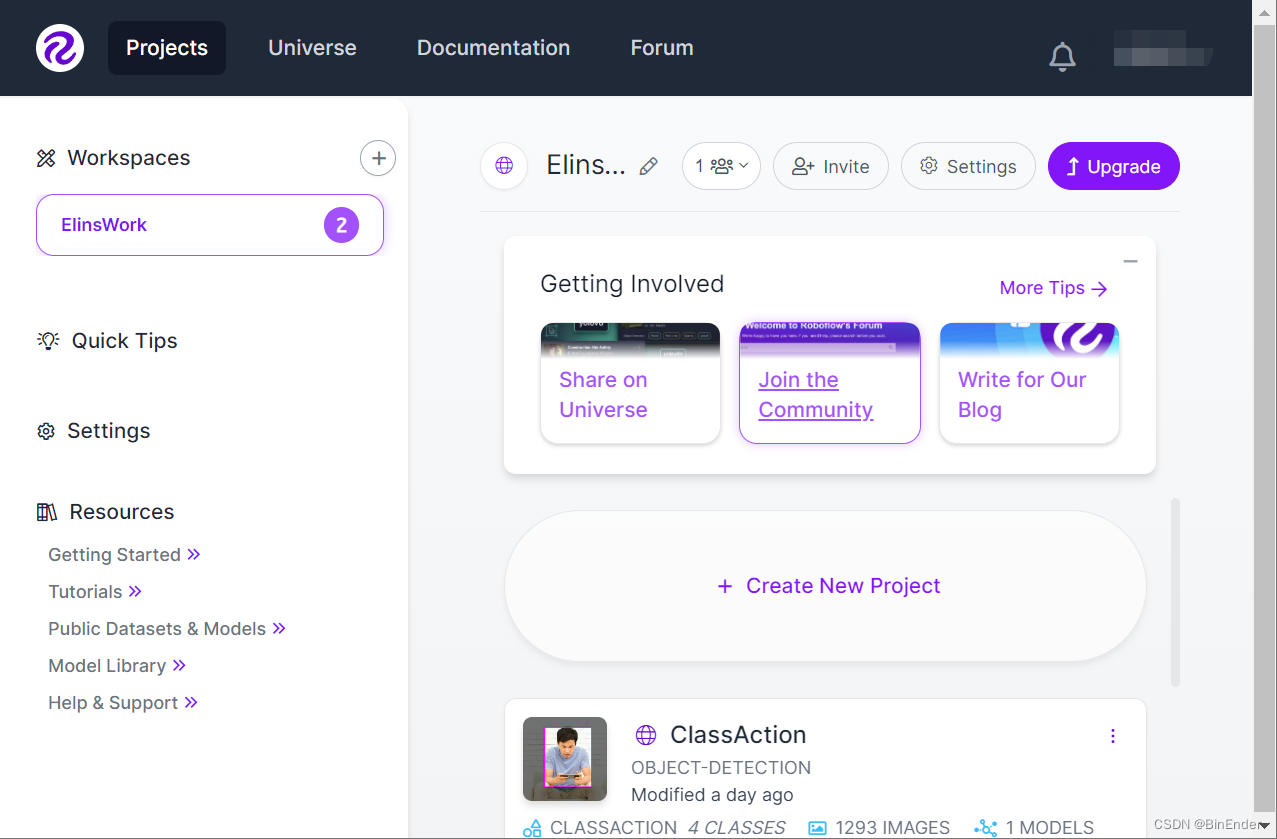
开始项目
这里有一个重要的概念:工作区(WorkSpace),这里代表着你的一个小的工作区,一个工作区可以拥有多个项目(Projects)和多个数据集(Datasets),同时一个账号可以有多个WorkSpace。
点击左上角的+号创建一个工作区,然后进入到工作区,点击Create New Project按钮创建一个新项目。
创建好后我们直接进入这个项目即可开始一系列操作了。
进入到Projects后,我们看到左边的菜单栏是这样的:
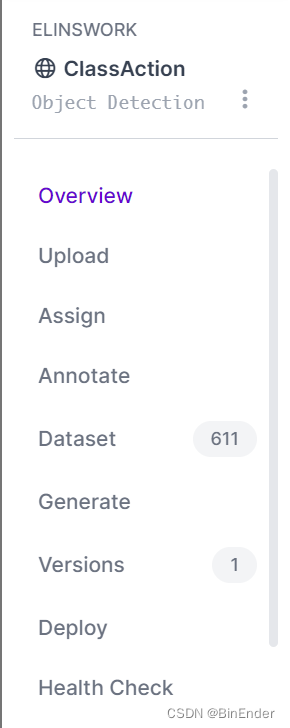
我们的项目逻辑当然是先上传->再标注->再生成的工作流程。那么接下来我们点击upload按钮上传我们的图像文件。
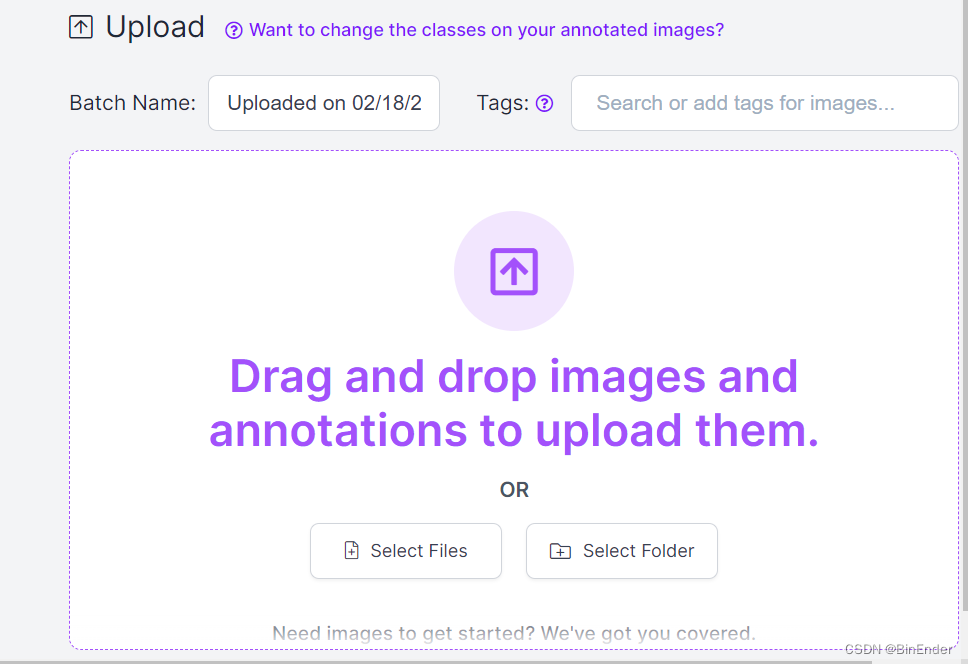
接下来,拖动你的数据集文件夹或者文件即可,但是需要说明的是,这类数据标注平台是有数据压制的,意味着比如你上传了1000张图像,可最终的上传结果可能是800张图片。
开始标注
当你上传完后,点击侧边栏的Annotate按钮,你会发现界面一共有3个卡片,分别是未声明(UNASSIGNED)的图像:这意味着可能上传了一半没上传完的图像,或者是你上传一半之后选择弃用的图像集合。
正在标注的图像集合(ANNOTATING):指你当前正在进行标注的图像集合如果你上传完并通过提示声明了图像,那么你这里应该是有一个选项卡的,默认代表着你当时上传的时间,如果在上传时对name改动了,则选项卡的名称是你当时更改的name。
这里点击进去就好,你会看到图像集合的完整展开,分别为未标注(UNANNOTATED)和已标注(ANNOTATED)。

我们点击未标注的图像集合中的任意一个图像即可进入标注页面。
进入到标注页面如下:
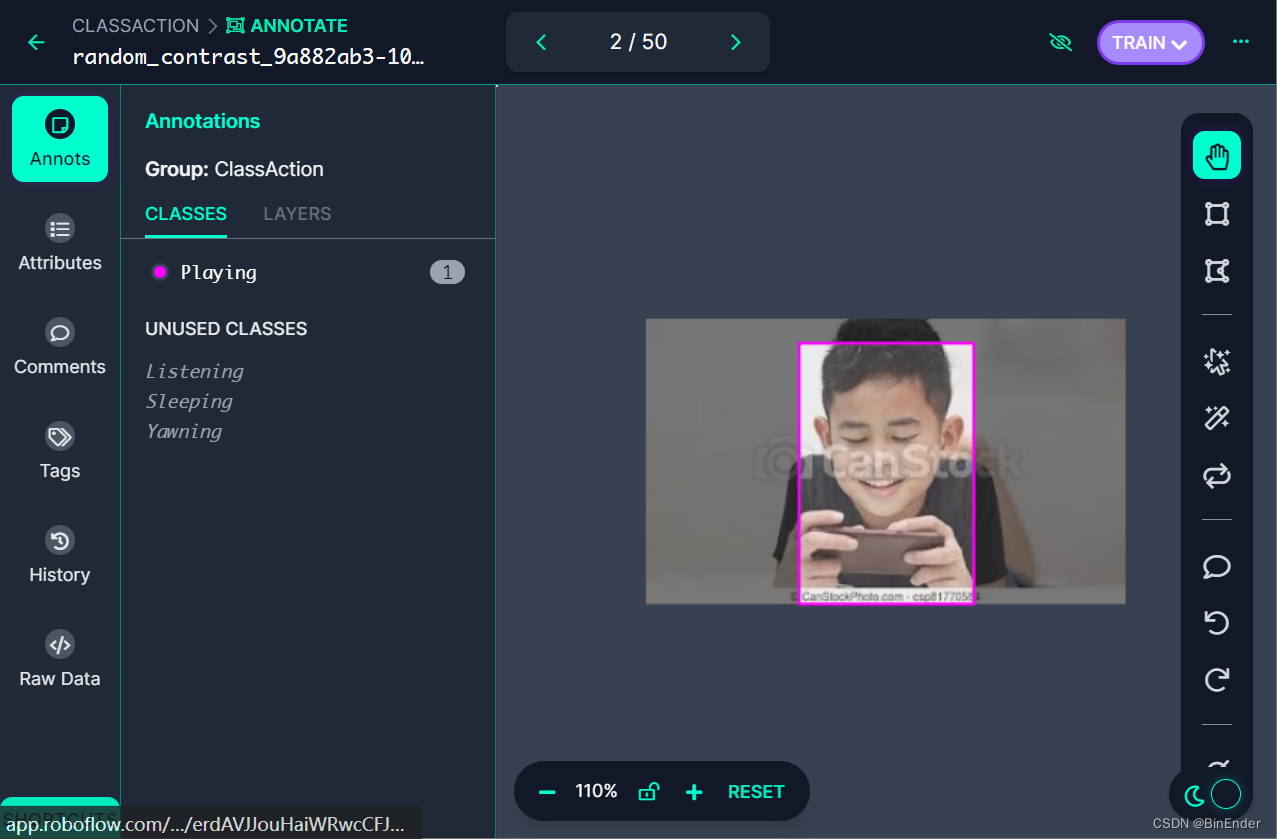
我们只需要在图像区域按住鼠标左键并拖动鼠标即可开始标注,另外拖动锚点框后,会有小弹窗来提示你更改类别。
另外可通过点击LAYERS来修改一个图像上锚点框的优先级顺序,以及删除错误的标注。
roboflow采用了自动保存机制,当你完成一张图片的标注后将会自动保存,再跳转到下一张图像,另外当你的网络发生异常后自动重连时,roboflow会自动跳转到当时的位置并继续标注。
数据集生成
标注完后返回到刚才的图像集合页面,点击右上角Add xxx image to datasets按钮将这些图像添加到数据集中,另外在添加时,你可以使用拖动条来控制训练集,验证集和测试集的比例,roboflow会自动为你分配这些图像的比例,并它们对应的添加到数据集中。
数据下载
接下来,我们回到项目菜单,点击Versions按钮来进入到数据集的版本控制。
可以看到我当前的数据集版本如下:

其中第一行代表数据集的生成时间,下面代表版本号。
我们需要做的是点击Export按钮进行导出即可,导出的方式由你决定。
开始训练
首先我们从上一步的方式下载数据集,这里我选择使用roboflow的Python API进行数据集的下载,因此我们需要下载如下的Python包:
roboflow==0.2.29
ultralytics==8.0.40
# 这里建议使用8.0.40,根据ultralytics开发人员给我的issuse反馈中,8.0.40版本是昨天刚更新的版本,修复了.yaml中的部分问题
数据下载
我们在安装好后上述两个包后,方可使用如下的代码下载数据:
from roboflow import Roboflow
# 初始化roboflow客户端
rf = Roboflow(api_key=input("Please Provide API Key"))
# 通过使用.workspace()和.project()函数加载远端项目
project = rf.workspace("<你的工作空间名称>").project("<你的项目名>")
# 通过.version()获取版本,以及.download()函数下载指定格式的数据集
dataset = project.version(1).download("yolov8")
import os
from IPython.display import clear_output
# 验证数据集的路径存在性,这里.exists()函数修改为你的数据集名称即可
if os.path.exists("<你的数据集名称>"):
clear_output()
print("Dataset already downloaded")
else:
clear_output()
print("Failed to download dataset due to invalid API key or network error")
检验yolo可用性
使用如下代码检验yolo的可用性:
from ultralytics import checks
checks()
得到如下的输出:
Ultralytics YOLOv8.0.40 🚀 Python-3.9.13 torch-1.13.1+cu117 CUDA:0 (NVIDIA GeForce RTX 2060, 6144MiB)
Setup complete ✅ (12 CPUs, 15.5 GB RAM, 137.5/1006.9 GB disk)
数据迁移
在开始真正的模型训练之前之前,我们需要对数据进行一下迁移和配置,这也是标题中说yolov8“反人类”的一个点。
之前自己捣鼓时一直跑不起来的原因是:yolov8的API会强制要求以训练脚本起始位置,在训练脚本的同级目录下放一个叫datasets的目录,而这个目录不存在,即使是在config文件中指明了正确的路径,也依然会检测不到数据集,因为它默认是从datasets中开始找。
所以我们需要创建一个datasets目录,并将通过roboflow下载的数据集迁移进去。
mkdir -p datasets
mv <你的数据集名称> datasets/
这样我们之后,我们使用如下指令检验我们的文件结构:
tree -L 2
其中-L 2指定的是Level2,代表Tree的检索深度:仅检索起始位的目录以及起始位目录下的子目录,结果如下:
.
├── datasets
│ └── ClassAction-1
├── myconf.yaml
├── runs
│ └── detect
├── train.ipynb
├── train.md
└── yolov8l.pt
4 directories, 4 files
这里train.md是我导出的Markdown文件,可以忽略。
配置文件编写
Yolov8仍然保留v5中以.yaml文件为配置文件的传统,我们可以在与训练脚本同级的目录下创建一个.yaml文件代表我们的配置文件。
配置的编写如下:
# 训练,测试和验证配置同v5一样
# 但是需要指出,这个路径是以datasets未开始
# 因此的开始路径是以datasets中的一个数据集文件夹进行开始
train: "ClassAction-1/train/images/"
test: "ClassAction-1/test/images"
val: "ClassAction-1/valid/images"
# 类别名,同v5一样
names:
- Listening
- Playing
- Sleeping
- Yawning
# 类数量,定义同v5一样
nc: 4
开始训练
这里我们使用Ultralytics的Python API进行模型训练,训练代码如下:
from ultralytics import YOLO
# 初始化YOLO示例,参数为带使用的模型的字符串
model = YOLO("yolov8l.pt")
# 调用model.train()开始训练
model.train(
# 指定我们data为刚才我们写好的配置文件
data="myconf.yaml",
# 指定图像的大小
imgsz=640,
# 设置迷你批次的大小
batch=4,
# 设置迭代次数
epochs=100,
# 是否启用v5版本的数据加载器,这里开和不开应该问题不大
v5loader=True
)
或者使用如下的CLI命令行
yolo task=detect mode=train model=yolov8l.pt data=myconf.yaml imgsz=640 batch=4 epochs=100 v5loader=True
运行代码之后就得到了我们在v5十分常见的训练输出:
Ultralytics YOLOv8.0.40 🚀 Python-3.9.13 torch-1.13.1+cu117 CUDA:0 (NVIDIA GeForce RTX 2060, 6144MiB)
yolo/engine/trainer: task=detect, mode=train, model=yolov8l.pt, data=myconf.yaml, epochs=100, patience=50, batch=4, imgsz=640, save=True, save_period=-1, cache=False, device=None, workers=8, project=None, name=None, exist_ok=False, pretrained=False, optimizer=SGD, verbose=True, seed=0, deterministic=True, single_cls=False, image_weights=False, rect=False, cos_lr=False, close_mosaic=10, resume=False, min_memory=False, overlap_mask=True, mask_ratio=4, dropout=False, val=True, split=val, save_json=False, save_hybrid=False, conf=0.001, iou=0.7, max_det=300, half=False, dnn=False, plots=True, source=ultralytics/assets/, show=False, save_txt=False, save_conf=False, save_crop=False, hide_labels=False, hide_conf=False, vid_stride=1, line_thickness=3, visualize=False, augment=False, agnostic_nms=False, classes=None, retina_masks=False, boxes=True, format=torchscript, keras=False, optimize=False, int8=False, dynamic=False, simplify=False, opset=None, workspace=4, nms=False, lr0=0.01, lrf=0.01, momentum=0.937, weight_decay=0.001, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=7.5, cls=0.5, dfl=1.5, fl_gamma=0.0, label_smoothing=0.0, nbs=64, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.9, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, mosaic=1.0, mixup=0.15, copy_paste=0.3, cfg=None, v5loader=True, tracker=botsort.yaml, save_dir=runs/detect/train2
Overriding model.yaml nc=80 with nc=4
需要指明的是生成的结果路径是这样的:runs/detect/train而非v5的runs/exp/train。这一变动也是需要注意的,其中detect表明的是任务类型,我们要进行目标检测,所以任务类型自然为detect,train代表的是结果的运行模式为训练模式。
模型验证
我们可以直接使用model(img)的方式进行推理:
result = model("./datasets/ClassAction-1/test/images/04749410-10_jpg.rf.cfa123f05036efa827e2701c3bfca518.jpg")
result[0]
得到的输出结果如下:
image 1/1 /home/elin/model_training/yolov8/datasets/ClassAction-1/test/images/04749410-10_jpg.rf.cfa123f05036efa827e2701c3bfca518.jpg: 640x640 1 Yawning, 73.6ms
Speed: 0.9ms pre-process, 73.6ms inference, 3.3ms postprocess per image at shape (1, 3, 640, 640)
Ultralytics YOLO <class 'ultralytics.yolo.engine.results.Boxes'> masks
type: <class 'torch.Tensor'>
shape: torch.Size([1, 6])
dtype: torch.float32
+ tensor([[270.00000, 78.00000, 464.00000, 416.00000, 0.86361, 3.00000]], device='cuda:0')
可以看到,模型的输出为shape为[1,6],这似乎是简化了模型的输出,通过观察模型的输出可知:前四位分别为锚点框的x1,x2,y1,y2(应该是这个顺序),第五位为置信度,第六位为模型的类别。
模型保存
我们可以通过调用model.export()函数导出模型,该函数接收一个参数为format,这里我将其导出为ONNX模型为,因此函数使用为model.export(format='onnx')。当然如果你有直接导出为TensorRT的需求,可以将format更改为engine进行尝试(当然这种API方法我没有尝试)。
我的个人习惯为使用trtexec命令行进行TensorRT模型的导出。
trtexec --onnx="<your model>.onnx" --saveEngine="<your model>.(engine/plan)" --int8 --best
这里--saveEngine传递时可以指定为.engine文件或者.plan文件,前者用于TensorRT API,后者用于Triton Inference Server API,--int8代表导出的TensorRT模型使用INT8权重进行量化处理,--best表示导出最优模型。
结语
这一次Yolov8的确做到了性能提升,另外通过内置的API可以直接进行模型的推理,这无疑是极大程度的便利了AI科学家以及AI开发者。
但是数据结构的强制更新以及模型输出结果的变化,会让像我这样从v5过度到v8的用户会非常不适。慢慢适应吧。
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











