








51TECH是一款技术专栏内容
对最前沿、最硬核的技术进行全实战解析
我们相信技术的变革力量
我们信技术的向善美好
我们希望将最宝贵的经验和思考,与行业共享
就在51TECH

2023年,什么概念最火?
数据驱动闭环。它是实现自动驾驶量产落地的必经之路,是决定自动驾驶下半场胜负的关键变量。
构建一个行之有效的数据驱动闭环系统,到底存在哪些痛点和难点?
数据闭环关键在数据,如何能快速、高效、低成本处理、流转并挖掘海量数据?
本期51TECH邀请51Sim数据挖掘高级架构师蔡鸿,深入分析数据驱动闭环流程中的行业痛点,并全面拆解51Sim一体化数据处理平台Dataverse的研发思路与技术突破,希望为行业带来一些思考与启发。
干货满满~千万不要错过!
完整的数据驱动闭环是指从量产车、采集车在路侧实地采集的交通场景,通过技术手段还原成仿真场景,进入测试环节用于算法测试,再更新和升级量产车的过程。
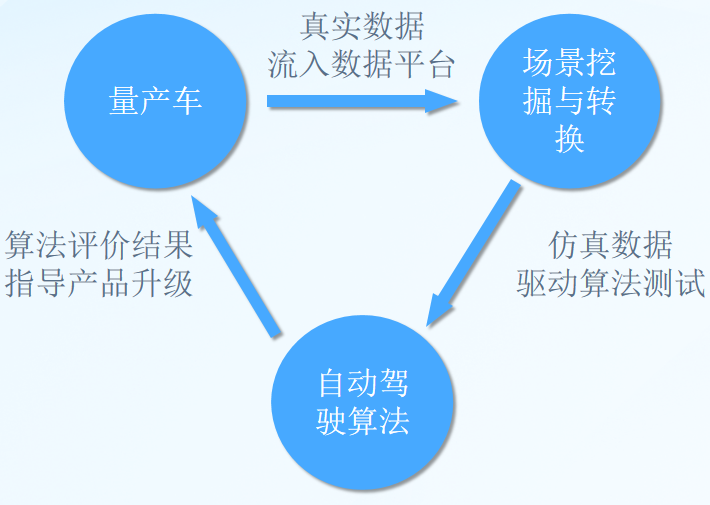
▲图为数据驱动闭环流程
这种闭环流程和技术虽然能够不断迭代优化自动驾驶系统的性能,但由于关键链路涉及多个领域,当前行业内(包括数据采集商、软硬件供应商、车厂、算法公司等在内)尚未出现能提供统一视野、融合所有的环节、一体化打通整条链路的产品或者平台。
这将是自动驾驶数据驱动急需解决的问题。
数据驱动闭环四大技术难点
具体来说,我们认为,数据驱动闭环,尤其是在数据处理领域,存在四大技术难题。
01 真实场景如何还原成仿真场景
量产车和采集车从路侧采集上来的场景,是真实的世界场景数据。
不同的采集供应商,存在不同的采集方案和存储格式。而算法测试需要的是仿真场景,不同的仿真软件供应商,在仿真数据管理方面也存在一定的区别。因此算法公司和车厂会面临如何对这不同的数据进行转换处理的难题。如果数据转换过程无法很好地完成,那么这个闭环链路就受到很大的影响。
02 缺乏有效的信息提取手段
数据和信息是两个不同的概念,虽然它们经常被混淆使用。
数据是指原始的、未经处理的数字、文字或符号等形式的记录,通常不具有意义和价值。而信息则是基于数据的处理和加工而产生的,是具有意义和价值的数据集合。
举例来说,一张汽车摄像头捕捉到的图像就是数据,而这张图像经过处理,识别出对手车的切入动作,就是有用的信息。
数据需要经过挖掘算法,生成有价值的信息才能被有效利用。但采集过程中不同的来源和结构会导致数据处理流程复杂化;各种误差和数据分布本身的噪声,以及不同的路况、车辆和行人的多种交互模式,会产生非常复杂的场景,这一切都会导致数据挖掘的难度大大增加,而关键信息往往隐藏在海量场景数据之中。
因此,如何有效地利用海量场景数据,产生出对自动驾驶有价值的信息,将是整个行业面临的一个共同挑战。
03 海量数据处理的成本和效率问题
从依靠专家经验手工编辑仿真场景的时代,到大数据的时代,数据量的增长是非常可观的。
然而这却是一个幸福的烦恼。因为一方面,一个场景混合了不同形式的数据,单一数据的体量就达到了几十MB甚至几个GB;另一方面,量产环境之下,每天采集的数据量又很多,导致每天需要处理的总数据量可能超过上百TB甚至数百PB。这个数据量级是传统软件开发和数据处理方法难以承受的。
因此,海量路采场景的利用效率是一个突出的问题。此外,人工数据标注的成本也非常高昂,急需一种全流程自动化的技术手段。
04 上下游链路割裂,数据流转困难
采集供应商仅负责采集数据,而算法团队仅关注于算法研发,不同的团队使用不同的开发语言和技术处理数据,我们发现这是一个很大的问题。
这意味着缺乏高效的数据处理和挖掘能力,导致不少车厂和自动驾驶公司虽然有数据,甚至有海量数据,却没法提取出关键场景信息,更没法进入仿真流程。
因此,需要一个更高效的数据处理系统,能够从海量数据中提取有用的信息,并支持上下游技术的整合,从而真正地实现数据驱动的闭环。
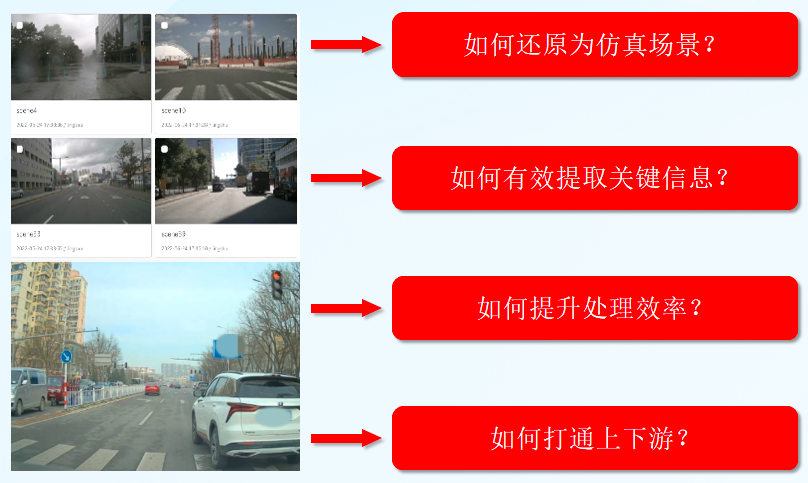
▲图为数据驱动闭环的核心问题
Dataverse关键技术剖析
那么是否存在一些技术手段,可以解决上述这些问题呢?
接下来,就请大家跟随我们的脚步,全面拆解Dataverse,看看Dataverse为解决自动驾驶数据驱动闭环落地难题,带来了怎样的技术突破与行业创新。
产品介绍:51Sim是51WORLD于2017年孵化的智能驾驶仿真测试子公司,在汽车仿真行业深耕多年。通过服务诸多自动驾驶算法公司以及主流车厂,51Sim积累了大量数据驱动闭环技术方面的宝贵经验,并形成了一个一体化的数据处理平台:Dataverse。
Dataverse打通了数据处理、仿真场景挖掘与转换等环节,并支持上下游技术的整合,具备数据清洗、数据计算、数据管理、数据可视化、场景挖掘等能力,帮助实现智能驾驶规控算法数据驱动的仿真闭环。
01 场景还原
实采场景对于自动驾驶算法测试的价值,首先在于还原为仿真场景。
如何更准确地表达仿真场景是场景还原的关键。51WORLD是ASAM标准委员会成员,参与OpenX系列标准的制定,我们的团队在仿真场景的表达与执行,积累了非常专业的经验和技术能力。
OpenX标准可以表达场景的静态信息和动态信息。
经过多年的耕耘,我们不仅可以高效生成OpenSCENARIO 1.x场景,而且在最新的OpenSCENARIO 2.0标准的探索和制定方面,也已经处于行业领先地位。OpenSCENARIO 2.0具有更加灵活和强大的表达能力,我们通过动态编译技术、场景泛化技术,把实采场景转换成OpenSCENARIO 2.0仿真场景,可以进一步提升仿真测试的效率和覆盖率。
在经过场景还原处理后,实采场景就可以转化成仿真场景进入仿真引擎了。那么下一个问题来了:采集的场景数量是巨大的,我们如何才能从海量场景中过滤出关键场景进行仿真?

▲图为真实场景到仿真场景的转换
02 关键场景挖掘技术
关键场景通常指的是一些具有挑战性的驾驶场景,如高速公路并道、复杂路况交通、拥堵情况下的切入切出等。这些场景往往是在现实生活中比较少见的,但是对于自动驾驶测试来说非常重要。
然而传统仿真技术往往是基于规则或预定义的场景进行仿真,无法充分模拟现实生活中的各种复杂情况和组合,往往难以挖掘到关键场景。
而我们基于深度学习技术,结合专家经验训练模型,从几个不同维度对场景数据进行深度挖掘,形成一套先进的自动驾驶场景挖掘体系。这种技术是一种创新性的方法,具有开创性的意义,打开了自动驾驶场景挖掘的一个新方向。
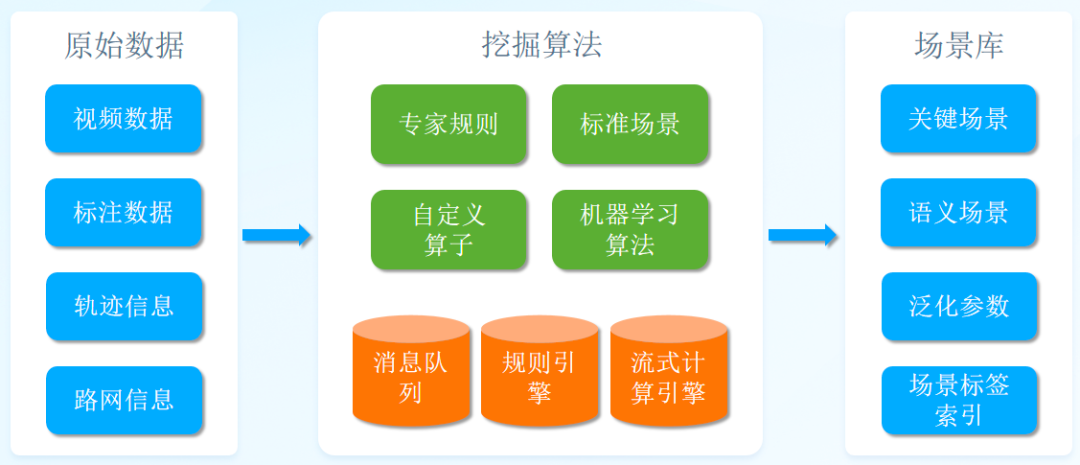
▲图为算法挖掘流程
-
关键场景挖掘与逻辑化、语义化
算法测试不仅关注像前车切入、前车急刹等简单场景,而且还关注在不同组合条件下的复杂切入、急刹场景。而我们的技术可以做到细粒度的复杂场景分类。那么这种分层次的场景分类是如何做到的?
我们实现了一个层次化的场景逻辑引擎,并向应用层提供一个描述性的脚本语言。通过编写这种描述性脚本,就能够从大量的驾驶数据中,自动挖掘出关键场景。
场景引擎自动分析轨迹、环境、地形等信息。具体而言,场景引擎提取车辆的运动状态,如加速度、速度、曲率;环境信息如路况、天气、交通标志和信号灯;以及地形信息如道路拓扑、车道线信息等。然后把这些信息和脚本中定义的语义描述结合起来,综合判断并生成行驶模式和触发条件,就可以自动挖掘出各种关键场景,形成一套完整的场景模型。
有了场景模型,再通过预定义的逻辑场景,对各项参数分布进行统计分析,就可以把关键场景进行语义化。经过语义化过后的逻辑场景,具备强大的泛化能力,可以生成更多具体的虚拟仿真场景。我们认为场景的逻辑化和语义泛化是提高自动驾驶系统性能的有力武器。
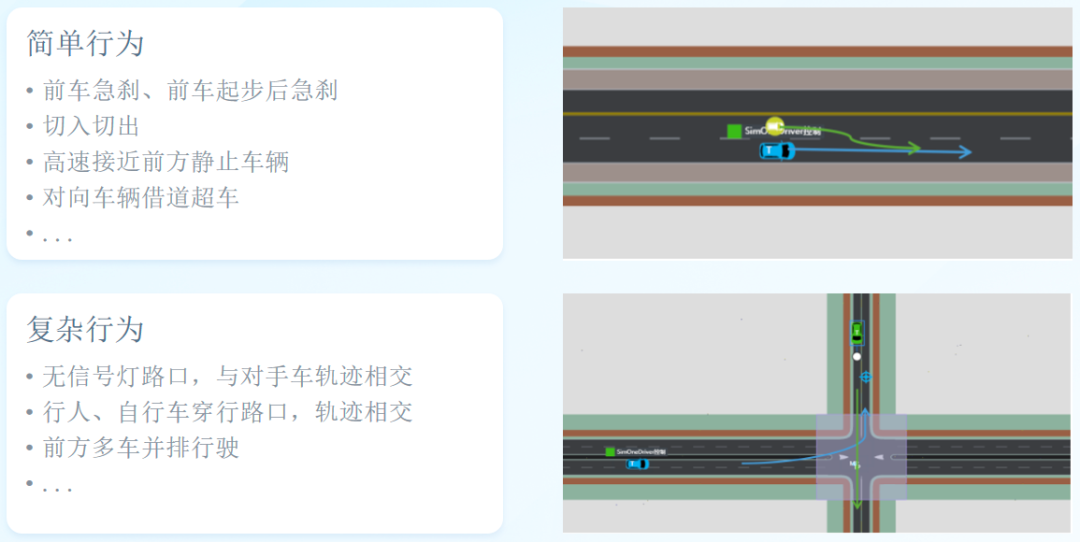
▲图为挖掘的关键场景库
-
边缘场景挖掘
为了更进一步提升关键场景的覆盖率,我们还从统计学的维度实现边缘场景识别。我们认为这种技术是机器学习和自动驾驶场景挖掘的创新性结合。真实世界中的数据,并非只有确定分类的场景才具有仿真价值。一些无法用确定参数进行描述的场景也具有很高的仿真价值。比如具有某种程度的拥堵场景、距离靠近但没有跨线和切入行为的几辆对手车,此类场景虽然没有具体的分类和参数化信息,但是对于检验自动驾驶算法在复杂环境下的反应能力具有很高的价值。
为此我们定义了一种场景复杂度的概念。我们认为复杂度低的场景,其测试的价值不大,用户一般可以在场景检索中把复杂度低的场景过滤掉;而复杂度高的场景,认为其包含边缘场景的可能性高,测试时应予以重点关注。
-
相似性场景挖掘
自动驾驶场景数据本身具有某种隐含语义表示,在统计过程中,会体现出某种规律性。这种规律性可以帮助用户快速查找与某个场景相似的其他场景、作为深层特征进行场景聚类分析,因而可以在不同层面产生价值,帮助分析交通拥堵状态、行为模式、道路结构模式、对手车行驶风格、危险等级等。为此,我们进行了第三个维度的挖掘。
在这个维度我们同样也采用了深度学习的方法,实现了将场景信息向量化。
03 并行计算技术在场景处理中的应用
现在我们已经有了场景还原和场景信息挖掘的能力,可以说从算法上解决了数据处理的问题。那么距离数据驱动闭环真正落地还有哪些阻碍呢?棘手的工程实现的问题此时就突显出来了。
自动驾驶路采场景的数据量大,而且每一个场景数据都包含多种数据格式,涵盖了各种高度复杂的因素。传统的工具链方法,无论从数据规模上还是数据处理方式上,都不具备处理这些数据的能力。
我们认为解决这个问题的关键是并行计算技术。并行计算在传统大数据领域是一种常规的技术,但是由于自动驾驶数据本身的特性,这种技术还无法直接拿来应用。我们经过一系列的探索,对并行计算进行创新性的改造,实现了一个并行场景数据处理平台。
与传统的处理方式相比,我们实现的平台技术是云原生的,可以灵活地调整算力来适配不同环境下的数据流量,从而实现高度的可扩展性。
到此为止,我们从架构上解决了数据并行化的问题,但是传统的工具链路大多是用C++和Python开发的程序,如何集成到主要由Java开发的大数据技术栈中呢?接下来的部分我们来解开这个迷题。
04 云原生平台化
通常数据处理工具链是个定制化很强的程序,主流开发语言是C++和Python。工具链有供应商提供,也有算法公司自主研发,因此需要用一种一体化的方法集成到平台中。
针对这些行业特点,为了满足定制化需求和提供二次开发能力,我们不仅把Dataverse平台定位为数据处理平台,还把Dataverse打造成一个灵活的二次开发平台。我们的思路是实现一套微服务架构,从三个不同的层面提供系统对接方法。
-
第一个层面是提供标准的Restful接口,可以对大部分平台功能进行系统调用。
-
第二个层面是实现了一种插件式的开发流程,使用户可以把特定的数据处理算子对接到Dataverse平台中,实现定制化需求。我们定义了一套数据处理并行程序开发框架,只要用户程序按照一套简单的模式进行开发,就可以轻松接入平台中,成为整个数据处理链路的一部分。
-
第三个层面是以SDK的形式开放了各类服务和存储资源的访问。考虑到数据处理程序主要用到Python语言、高性能仿真系统主要用到C++语言、大数据处理一般用到Java语言,Dataverse提供三种语言的SDK,使用户可以灵活地选择不同的语言进行二次开发。既可以把存量的数据处理模块接入平台,也可以完全基于并行计算的模式开发各种新的数据处理算子,实现不同的数据需求,一举解决了数据流转问题,打通了整条数据链路。
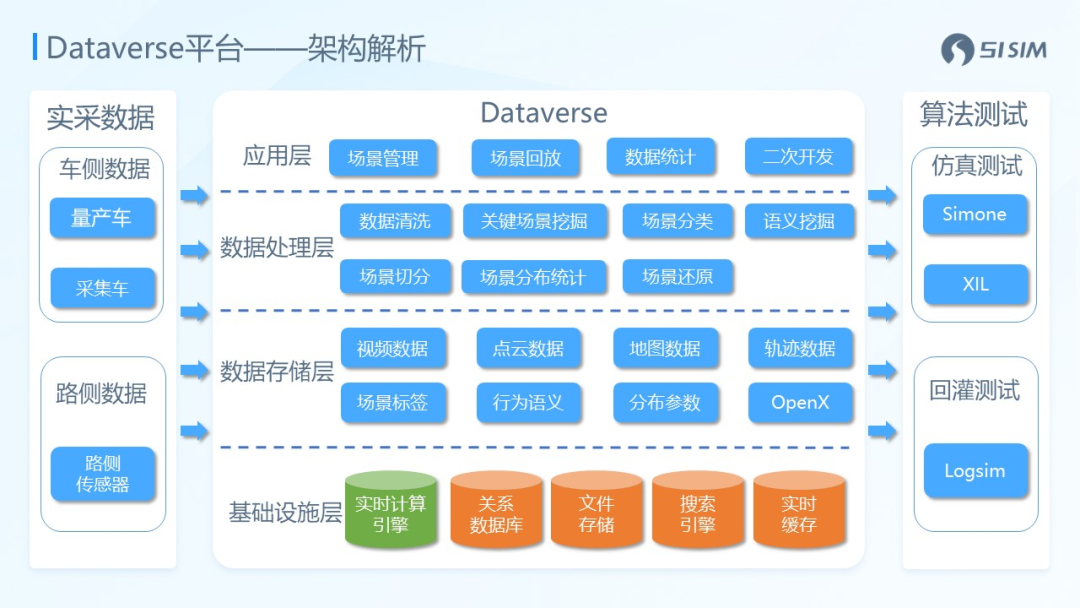
▲图为平台技术架构
未来展望
我们认为AIGC技术将会在数据驱动闭环中发挥很大的作用。AIGC一方面可以生成非常逼真的数据,另一方面其生成的数据在真实世界中不存在一一映射关系,完全是虚拟数据。因此,完全可以通过AIGC技术,来生成适合于算法仿真测试的大量场景。相信在不久的将来,当数据驱动完全成熟以后,自动驾驶将会进入一个全方位的AI驱动的新时代。
未来,Dataverse将继续改进和优化,为自动驾驶技术的进一步发展提供更强有力的支持。
















 1267
1267

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











