







一、 摘要
提出问题:钻柱振动可分为轴向、侧向和扭转三种类型。这三种方法都会对钻井设备造成严重的磨损,导致故障增加,非生产时间增加,钻井性能下降。钻井时获取实时、高频井下振动数据的成本仍然很高(这里好像跟上次笔记随钻测井有点相似)。
解决问题:因为,我们提出一个方法——可以通过只使用地面钻井参数的机器学习(ML)技术进行估计。利用地面参数预测井下振动严重程度的任务被视为有监督分类的ML问题。
传统解决方法:研究了五种基本的传统技术:最近邻、逻辑回归、naïve贝叶斯、判别分析和决策树。
传统方法优缺点:这些简单的ML技术可以相当准确地预测井下钻具组合内的振动水平。但对于井底钻具组合,预测性能降低。
这证明了ML在预测井底振动方面的可行性,推动了更先进的ML技术的应用,包括深度学习估计器,同时也表明了该技术可以获得的潜在效益
二、简介
引出问题:石油和天然气的钻探包括钻一个长而蜿蜒的钻孔穿过地下,以获取地下深处的储量。钻柱偏心度和井下环境的动态变化会导致局部或全系统的振动,这些情况可能会影响钻井性能。尽管钻井设备已被设计成能够尽可能多地承受振动,但是长久来看,这些问题是不可避免的。故障会导致大量的非生产时间,对相关各方来说代价高昂。
提出解决方法:机器学习(ML)算法是井下振动预测的一种有价值的工具,它可以帮助作业者预测更高风险的钻井环境,并进行相应的计划,以防止未来设备过早损坏、降低钻井性能和潜在的非生产时间。
本文首先简要介绍了ML技术在钻井和工具失效问题中的应用,然后详细介绍了五种有监督的ML方法。然后将这些方法应用到一系列bha(井底钻具组合)内部,以评估这些方法的性能。最后,除了估计井下振动随时间的变化,还研究了对井下工具造成的累积损伤
三、有监督的机器学习算法
为了证明机器学习应用于钻井工程预测问题的可行性,我们使用了五种基本的传统机器学习(ML)分类器,它们分别是
- 高斯朴素贝叶斯分类器
- 再近邻分类器
- 线性判别分析分类器
- 多项逻辑回归分类器
- 决策树分类器
3.1、高斯朴素贝叶斯分类器:高斯朴素贝叶斯分类器是最简单的参数分类器之一,该模型的前提是特征在每个类中是有条件独立的,特征的分布是高斯的。在现实中,独立的假设通常不是这样的,因为任何两个输入变量在统计上不一定独立。但其在许多现实情况下表现得令人惊讶地好。贝叶斯定理表明,对于每一类振动
ν
j
ν_j
νj及其伴随特征
X
=
x
1
,
…
,
x
n
X={x1,…,xn}
X=x1,…,xn,我们有:
P
(
v
j
∣
x
1
,
.
.
.
,
x
n
)
=
P
(
x
1
,
.
.
.
,
x
n
∣
v
j
)
⋅
P
(
v
j
)
P
(
x
1
,
.
.
.
,
x
n
)
(公式
1
)
P(v_j|x_1,...,x_n)=\frac{P(x_1,...,x_n|v_j)\cdot P(v_j)}{P(x_1,...,x_n)}(公式1)
P(vj∣x1,...,xn)=P(x1,...,xn)P(x1,...,xn∣vj)⋅P(vj)(公式1)应用特征的条件独立性的朴素条件,方程就重写成:
P
(
v
j
∣
x
1
,
.
.
.
,
x
n
)
=
∏
i
=
1
n
P
(
x
i
∣
v
j
)
⋅
P
(
v
j
)
P
(
x
1
,
.
.
.
,
x
n
)
(公式
2
)
P(v_j|x_1,...,x_n)=\frac{\prod_{i=1}^nP(x_i|v_j)\cdot P(v_j)}{P(x_1,...,x_n)}(公式2)
P(vj∣x1,...,xn)=P(x1,...,xn)∏i=1nP(xi∣vj)⋅P(vj)(公式2) 其中:
P
(
ν
)
P(ν)
P(ν)为类先验,由训练数据集估计,
P
(
x
i
∣
ν
j
)
P(x_i|ν_j)
P(xi∣νj)是模拟数据的概率分布,
P
(
x
1
,
…
,
x
n
)
P(x_1,…,x_n)
P(x1,…,xn)是一个在所有实例中恒定的量,
P
(
x
i
∣
ν
j
)
P(x_i|ν_j)
P(xi∣νj)由高斯分布给出:
P
(
x
i
∣
v
j
)
=
exp
(
−
(
x
i
−
μ
v
j
)
2
2
σ
v
2
)
2
π
σ
v
j
2
(公式
3
)
P\left(x_i \mid v_j\right)=\frac{\exp \left(-\frac{\left(x_i-\mu_{v_j}\right)^2}{2 \sigma_v^2}\right)}{\sqrt{2 \pi \sigma_{v_j}^2}}(公式3)
P(xi∣vj)=2πσvj2exp(−2σv2(xi−μvj)2)(公式3)
3.2再近邻分类器:
再近邻分类器通常被认为是研究数据集机器学习选项的首选分类,因为数据集的变量之间的相关性知识有限。它是一个基于实例的非参数分类器,不试图从数据集推导出通用模型。相反,它对未分类的实例进行分类,将它们分配给k个最近的实例中占多数的类。
D
s
i
t
a
n
c
e
(
p
,
q
)
=
∑
i
=
1
n
(
p
i
−
q
i
)
2
(公式
4
)
Dsitance(p,q)=\sqrt{\sum\limits_{i = 1}^n{(p_i - q_i)^2}}(公式4)
Dsitance(p,q)=i=1∑n(pi−qi)2(公式4)其中p和q是n维坐标系中
P
=
(
p
1
,
p
2
,
…
,
p
n
)
P =(p_1,p_2,…,p_n)
P=(p1,p2,…,pn)和
q
=
(
q
1
,
q
2
,
…
,
q
n
)
q=(q_1,q_2,…,q_n)
q=(q1,q2,…,qn)的两个实例。
3.3线性判别分析分类器
当假设类有一个共同的协方差矩阵
Σ
Σ
Σ时,它就成更普通的高斯判别分析的一个特例。它是一种生成学习算法,基于特征按照多元高斯分布分布的前提下,建模特征的概率,
X
=
x
1
,
…
,
x
n
X={x_1,…,x_n}
X=x1,…,xn,给定一类振动
ν
j
ν_j
νj。概率密度函数为:
P
(
X
∣
v
j
)
=
exp
(
−
1
2
(
X
−
μ
v
j
)
T
Σ
−
1
(
X
−
μ
v
j
)
)
(
2
π
)
n
∣
Σ
∣
(公式
5
)
P\left(X \mid v_j\right)=\frac{\exp \left(-\frac{1}{2}\left(X-\mu_{v_j}\right)^T \Sigma^{-1}\left(X-\mu_{v_j}\right)\right)}{\sqrt{(2 \pi)^n|\Sigma|}}(公式5)
P(X∣vj)=(2π)n∣Σ∣exp(−21(X−μvj)TΣ−1(X−μvj))(公式5)
μ
v
j
μ_{vj}
μvj和
Σ
Σ
Σ是在训练过程中估计的类均值和协方差矩阵。所有类别的共同协方差假设允许对数概率比来表征线性判别分析,通过它从训练数据中估计高斯分布的参数。
四、实验案例
4.1、总体工作流程
本案例研究的机器学习工作流程从收集的数据的清理和预处理开始,然后通过迭代学习过程优化分类器的超参数,然后采用交叉验证的方法进行学习实验。
需要注意的是在本文中, "intra-BHA"下钻指的是使用单个底部钻具组合的数据进行训练和测试,而“inter-BHA”下钻指的是使用一个底部钻具组合的数据进行训练,并使用另一个底部钻具组合的数据进行测试,但两者都来自同一口井
4.2预处理:
用横向和轴向均方根振幅
ν
l
a
t
e
r
a
l
ν_{lateral}
νlateral和
ν
a
x
i
a
l
ν_{axial}
νaxial计算振动钻柱的合成均方根振幅(简称合成振动)
ν
ν
ν(
ν
ν
ν符号指的是振动,用加速度表示,而不是速度的大小)。由此产生的振动被分为四类严重程度(如表1所示)。
振幅
v
=
ν
l
a
t
e
r
a
l
2
+
ν
a
x
i
a
l
2
(公式
6
)
v=\sqrt{ν_{lateral}^2+ν_{axial}^2}(公式6)
v=νlateral2+νaxial2(公式6)
4.3特征选择
初步研究的一系列特征包括区块位置、井深、钻头深度、钩载荷、ROP、钻压(WOB)、压差、流量、顶部驱动旋转(RPM)和顶部驱动扭矩(简称扭矩)。在最初的十个被认为是相关的特征中,我们要排除那些与目标相关性太弱或者太强的特征,来进一步减少特征的数量。初步选出的特征与目标的相关性如下图所示:
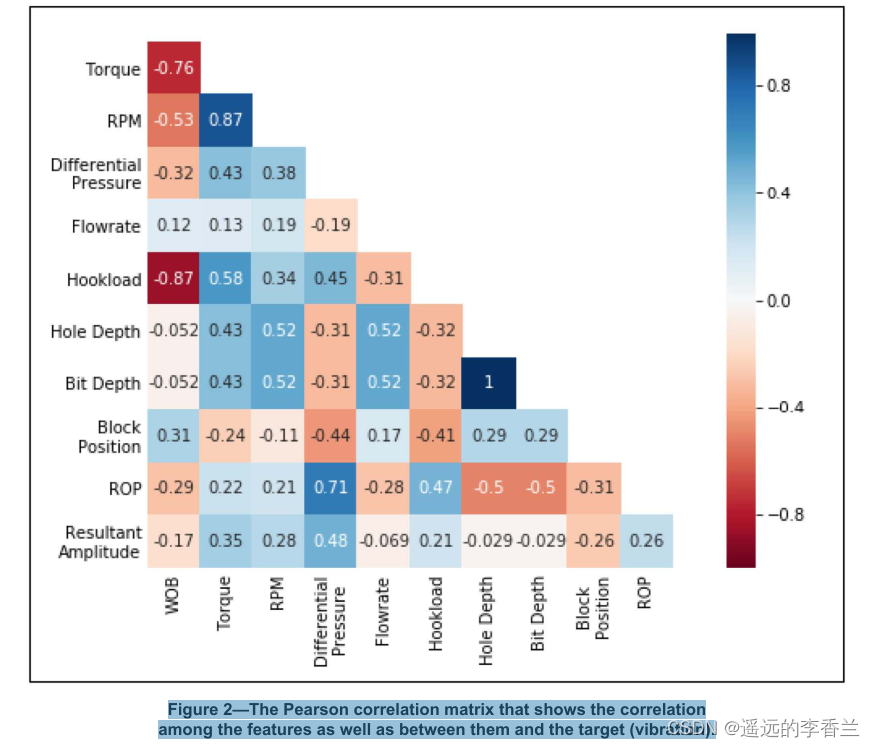
从图中可以看见矩阵显示,扭矩、RPM、压差、钩载荷、ROP和滑车位置都与合成振幅(目标)密切相关。但这些特征之间存在很强的相关性,例如扭矩和RPM、ROP和压差、钩载荷和钻压。因此,考虑到需要限制相互关联过强的特征,学习过程的特征减少为扭矩、ROP、钻压(WOB)。
4.4平滑和缩放:
通过对数据进行简单移动平均线(SMA),对选定的特征和目标进行平滑,以减少噪声的影响。经过多次试验,选择了窗口大小为60秒的SMA。它过滤掉了极端的噪音,同时避免了数据的过度平滑。本案例研究中的机器学习KNN,对数据规模非常敏感,我们使用标准评分归一化来衡量所选特征和目标。
4.5、进行学习
我们使用11个分区的时间序列交叉验证作为测试ML学习者在数据集上的性能的方法。交叉验证是传统的基于模型预测能力的模型选择方法。在时间序列交叉验证中,数据集被分割成k个分区,数据的原始时间顺序不变(即不随机)。在每第k次迭代中,选择前k个分区作为训练数据集,而(k+1)个分区作为验证或测试数据集(如下图所示)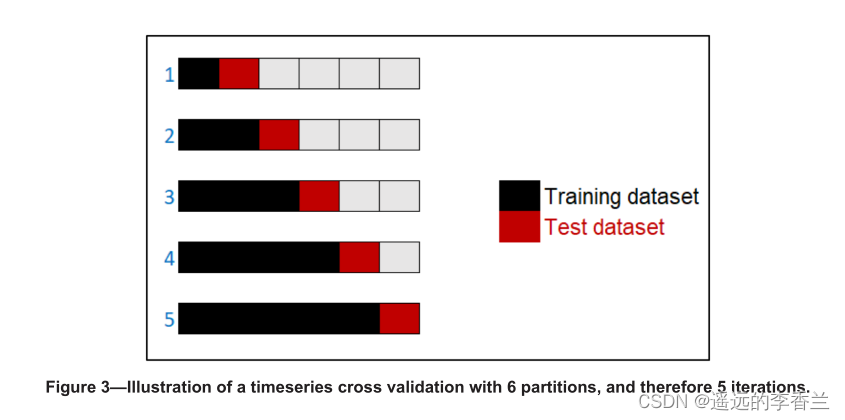
这样的话,除第一个分区外,所有分区都将作为一次验证数据集。因此,对于每个交叉验证,每个性能指标将有10个值。
结果与讨论
结果可分为intra-BHA和inter-BHA。对于前者,展示了来自不同井的多个BHA的结果,其中一个(BHA 5)专注于探索导致非常高或非常低性能的迭代。对于inter-BHA组合,只关注和讨论了两个底部钻具组合(BHA 4和BHA 5)的结果。
Intra-BHA runs:
六种BHAs的时间序列交叉验证结果如下图所示:
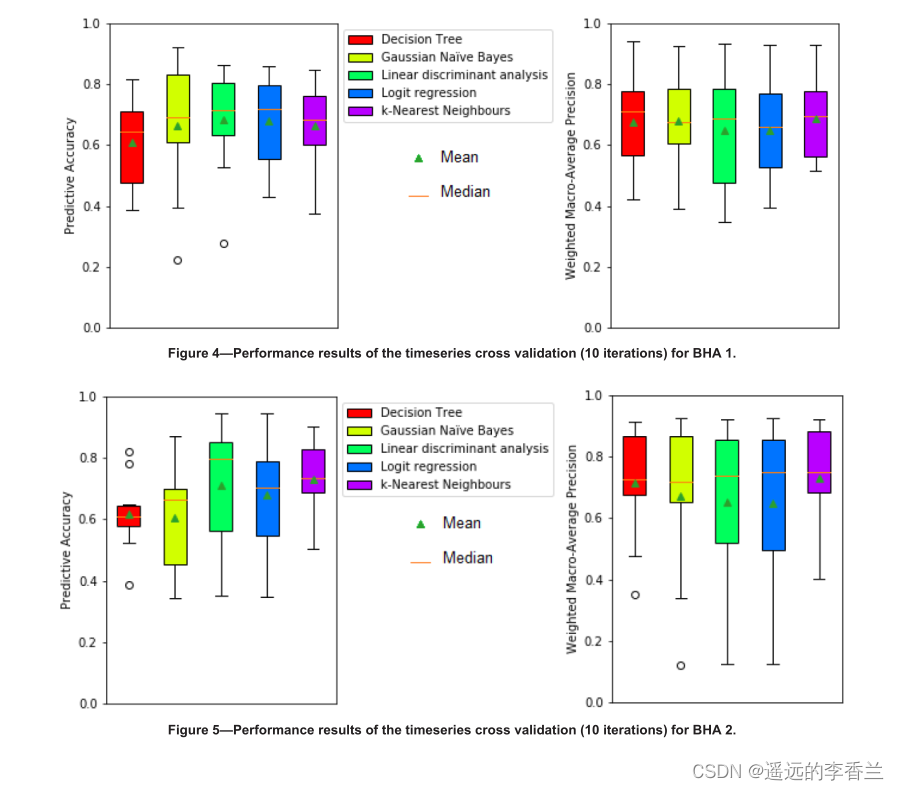
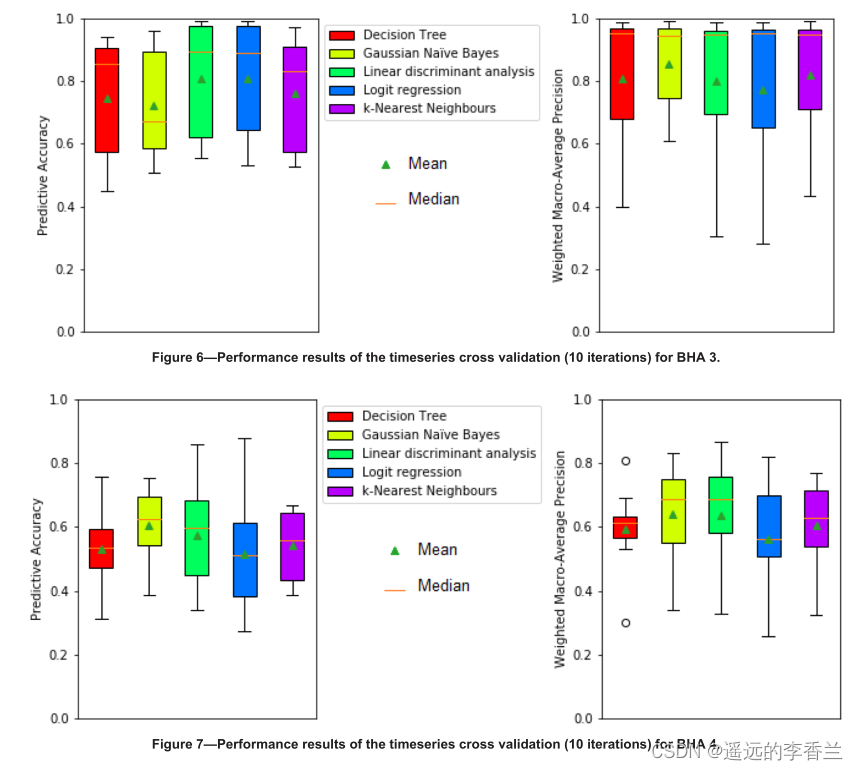
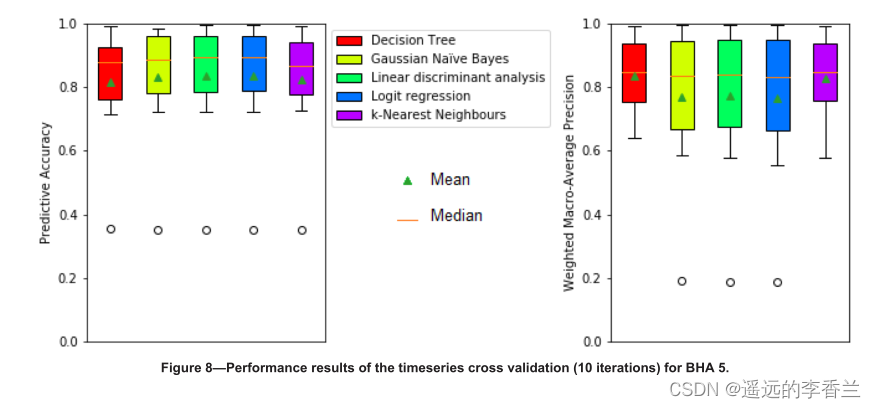
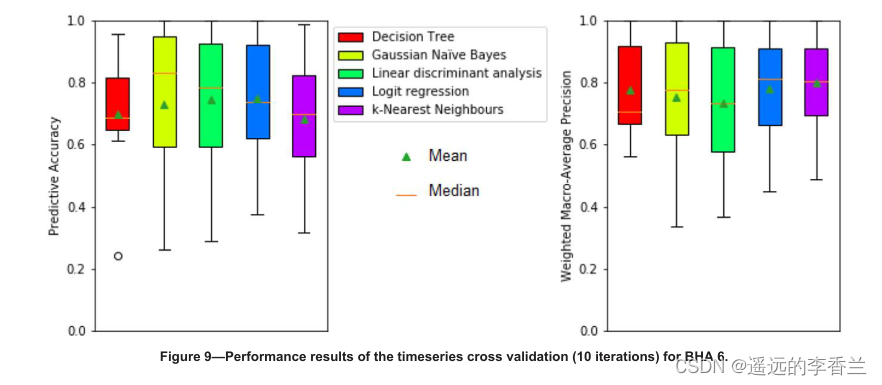
从图4、图7、图8、图9这几张图可以看出预测的准确性和精确度差异很大,这取决于迭代过程中测试的数据的哪一部分。从性能指标的中值和算术平均值来看,学习者的表现远远好于学习随机生成的数据时,所有学习者的准确率约为20%。(原文中还对高性能Intra-BHA和低性能的Intra-BHA做了一个解释,这部分我不明白为什么,暂时不记笔记,因为从整体架构上看应该是比较Intra-BHA和Inter-BHA)。
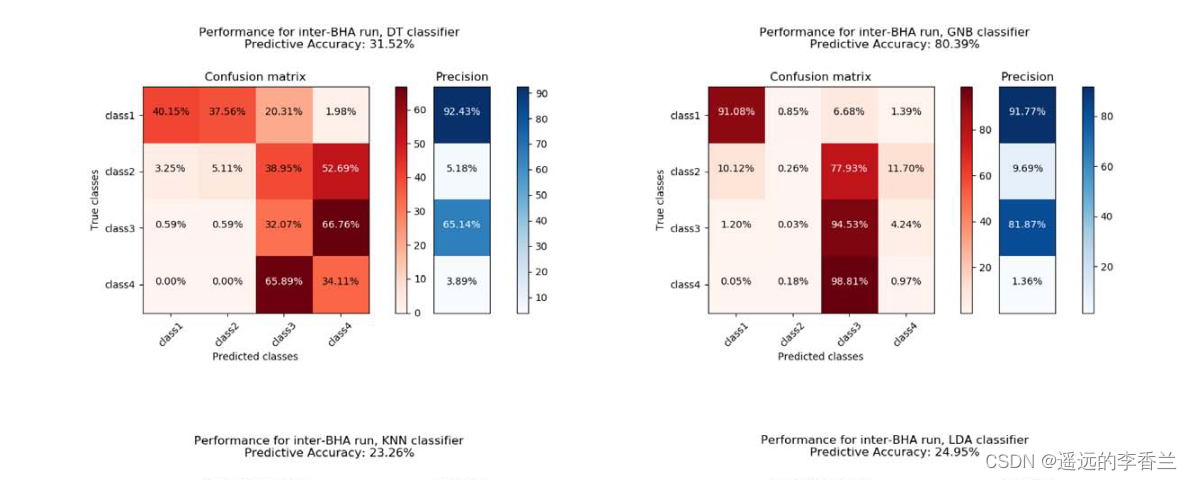
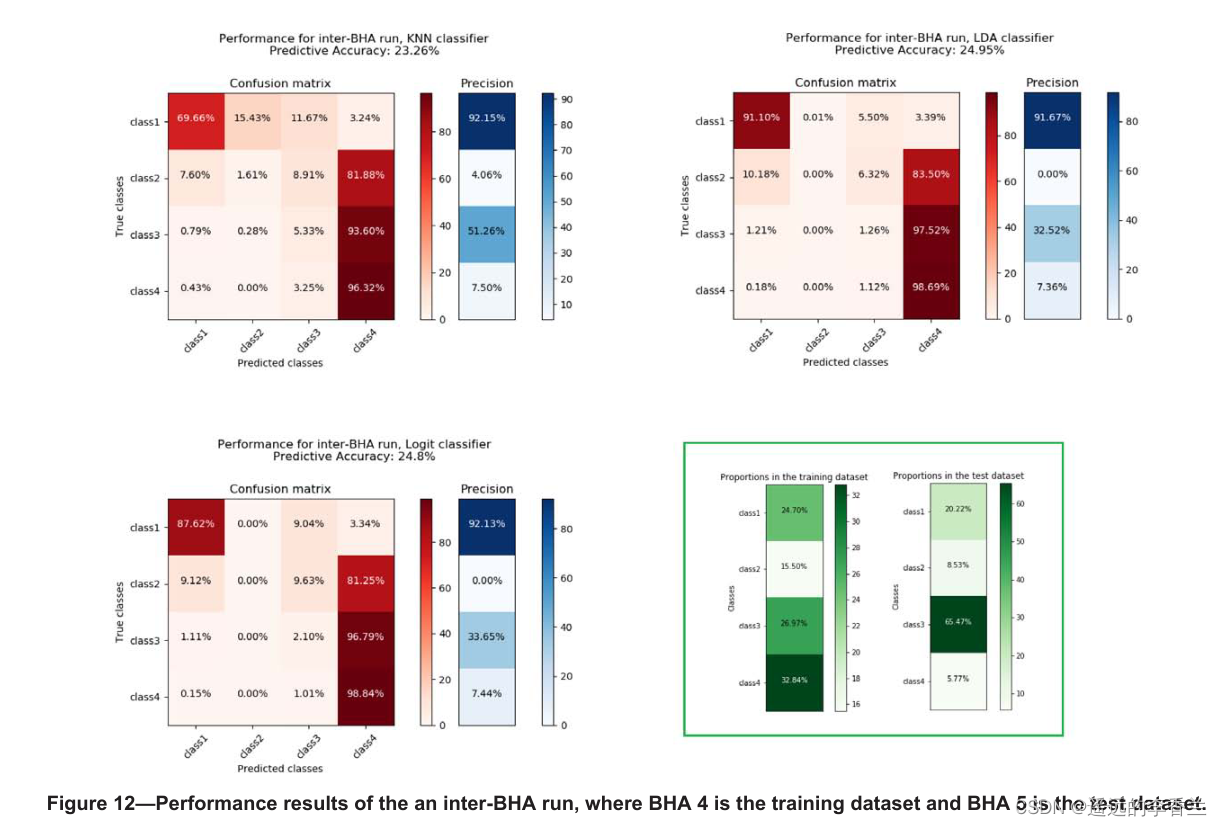
Inter-BHA runs
本节所探讨的Inter-BHA针对的是BHA 4和BHA 5,根据时间顺序,前者是训练数据集,后者是测试数据集,测试和训练结果如下所示:
总结
该研究表明,机器学习(ML)是一种仅利用地面数据监测和预测井底振动的可行方法。使用该技术,井下振动严重程度的预测精度为50% - 80%,这意味着在某些情况下,预测结果可能会产生良好的效果。对于bha间下入作业,由于作业条件和井眼条件不同,预测精度明显降低,而这在训练过程中没有考虑到。如果振动严重程度是预期的预测结果,则仍然需要进行大量的工作,特别是如果要将一个底部钻具组合的经验应用到另一个底部钻具组合时。















 2484
2484











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









