










中文编码问题的处理核心都是——保证所有的编码方式一致即可,包括编译器、数据库、浏览器编码方式等,而Python通常的处理流程是将unicode作为中间转换码进行过渡。先将待处理字符串用unicode函数以正确的编码转换为Unicode码,在程序中统一用Unicode字符串进行操作;最后输出时,使用encode方法,将Unicode再转换为所需的编码即可,同时保证编辑器服务器编码方式一致。
PS:当然Python3除外!这篇文章比较啰嗦,毕竟是在线笔记和体会嘛,望理解~
在详细讲解概念之前,先讲述我最近遇到的字符编码的两个问题及解决。下图是最常见到几个问题编码问题:

参考资料:
详解 python 中文编码与处理
python字符编码与解码unicode、str和中文 'ascii' codec can't decode
Python的中文编码问题-segmentfault
书籍《Python核心编程(第二版)》和《Python基础教程(第二版)》
一. raw_input输入str转换unicode处理
背景:在做Python定向图片爬虫时,会通过raw_input输入关键词如“主播”,会爬取标题title中包含"主播"的URL,再去到具体的页面爬取图集。
问题:如果是自定义字符串直接通过: s=u'主播' 定义为Unicode编码,再与同样为Unicode编码的title.text(下一篇文章详细介绍该爬虫)比较即可。但是如果需要raw_input输入呢?而且在通过unicode或decode转换过程中总是报错,为什么呢?
主要问题是如何将str转换为unicode编码(How to convert str to unicode),默认python编码方式ascii码。
unicode(string[, encoding[, errors]])
>>> help(unicode)
Help on class unicode in module __builtin__:
class unicode(basestring)
| unicode(object='') -> unicode object
| unicode(string[, encoding[, errors]]) -> unicode object
|
| Create a new Unicode object from the given encoded string.
| encoding defaults to the current default string encoding.
| errors can be 'strict', 'replace' or 'ignore' and defaults to 'strict'.# coding=utf-8
import sys
def getTitle(key,url):
#title = driver.find_element_by_xpath()
title = u'著名女主播Miss与杰伦直播LOL'
print key,type(key)
print title,type(title)
if key in title:
print 'YES'
else:
print 'NO'
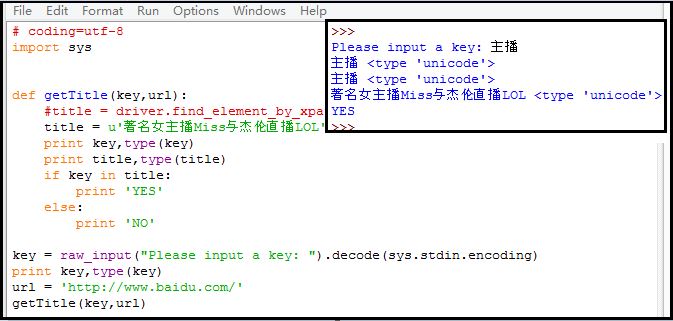
key = raw_input("Please input a key: ")
print key,type(key)
url = 'http://www.baidu.com/'
getTitle(key,url)输出如下图所示:
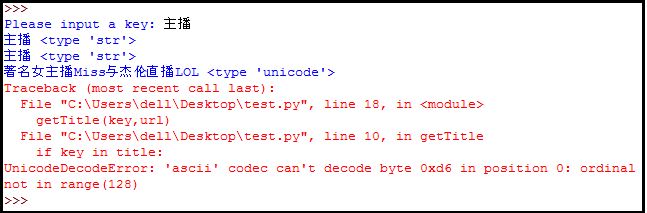
"UnicodeDecodeError: 'ascii' codec can't decode byte" 需先将str转换为unicode编码,但是我s.decode('utf-8')就报错 "UnicodeDecodeError: 'utf8' codec can't decode byte"。
s = '主播'
s.decode('utf-8').encode('gb18030')python raw-input odd behavior with accents containing strings
它是将终端的输入编码通过decode转换成unicode编码
key = raw_input("Please input a key: ").decode(sys.stdin.encoding)
二. 读取中文文件乱码处理
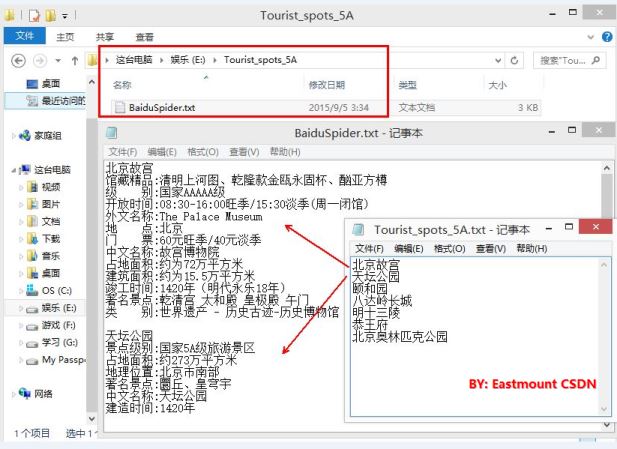
此时你的爬虫仅仅是能从raw_input中输入进行处理或者定义unicode的字符串进行定向爬取,但是如果关键词很多就需要通过读取文件来实现。如下图所示,是我"Python爬取百度InfoBox"这篇文章。同样,你会遇到各种中文乱码问题需要处理。
举个简单例子:通过Selenium爬取百度百科Summary第一段。
# coding=utf-8
import sys
import os
import urllib
import time
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import selenium.webdriver.support.ui as ui
from selenium.webdriver.common.action_chains import ActionChains
#driver = webdriver.PhantomJS(executable_path="G:\phantomjs-1.9.1-windows\phantomjs.exe")
driver = webdriver.Firefox()
wait = ui.WebDriverWait(driver,10)
def getTitle(line,info):
print 'Fun: ' + line,type(line)
driver.get("http://baike.baidu.com/")
elem_inp = driver.find_element_by_xpath("//form[@id='searchForm']/input")
elem_inp.send_keys(line)
elem_inp.send_keys(Keys.RETURN)
elem_value = driver.find_element_by_xpath("//div[@class='lemma-summary']/div[1]").text
print 'Summary ',type(elem_value)
print elem_value,'\n'
info.write(line.encode('utf-8')+'\n'+elem_value.encode('utf-8')+'\n')
time.sleep(5)
def main():
source = open("E:\\Baidu.txt",'r')
info = open("E:\\BaiduSpider.txt",'w')
for line in source:
line = line.rstrip('\n')
print 'Main: ' + line,type(line)
line = unicode(line,"utf-8")
getTitle(line,info)
else:
info.close()
main()1.我先把Baidu.txt修改为utf-8编码,同时读入通过unicode(line,'utf-8')将str转换为unicode编码;
2.Selenium先通过打开百度百科,在输入关键词"北京故宫"进行搜索,通过find_element_by_xpath爬取"故宫"的summary第一段内容,而且编码方式为unicode;
3.最后文件写操作,通过line.encode('utf-8')将unicode转换成utf-8,否则会报错UnicodeDecodeError: 'ascii'。
总之过程满足:编码=》Unicode=》处理=》utf-8或gbk
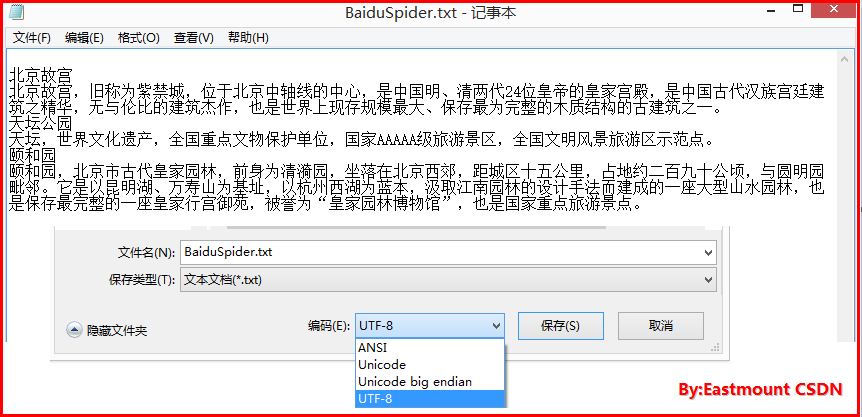
由于创建txt文件时默认是ascii格式,而文字为'utf-8'格式时会报错。当然你也可以通过CODECS方法创建制定格式文件。
codes是COder/DECoder的首字母组合。它定义了文本跟二进制值的转换方式,跟ASCII那种用一个字节把字符转换成数字的方式不同,Unicode用的是多字节。这也导致了Unicode支持多种不同的编码方式。codes支持的四种编码方式包括:ASCII、ISO 8859-1/Latin-1、UTF-8和UTF-16。
import codecs
#用codecs提供的open方法来指定打开的文件的语言编码,它会在读取的时候自动转换为内部unicode
info = codecs.open(baiduFile,'w','utf-8')
#该方法不是io故换行是'\r\n'
info.writelines(key.text+":"+elem_dic[key].text+'\r\n')
三. Unicode详解
PS: 该部分主要参考书籍《Python核心编程(第二版)》作者Wesley J.Chun
什么是Unicode
Unicode字符串声明通过字母"u",它用来将标准字符串或者是包含Unicode字符的字符串转换成完全的Unicode字符串对象。Python1.6起引进Unicode字符串支持,是用来在多种双字节字符的格式、编码进行转换的。
Unicode是计算机支持这个星球上多种语言的秘密武器。在Unicode之前,用的都是ASCII码,每个英文字符都是以7位二进制数的方式存储在计算机内,其范围是32~126。当用户在文件中键入A时,计算机会把A的ASCII码值65写入磁盘,然后当计算机读取该文件时,它会首先把65转换成字符A再显示到屏幕上。
但是它的缺点也很明显:对于成千上万的字符来说,ASCII实在太少。而Unicode通过使用一个或多个字节来表示一个字符的方法,可以表示超过90,000个字符。
>>> s1 = "中文"
>>> s1
'\xd6\xd0\xce\xc4'
>>> print s1,type(s1)
中文 <type 'str'>
>>> s2 = u"中文"
>>> s2
u'\xd6\xd0\xce\xc4'
>>> print s2,type(s2)
ÖÐÎÄ <type 'unicode'>
>>> 编码转码
Unicode支持多种编码格式,这为程序员带来了额外的负担,每当你向一个文件写入字符串的时候,你必须定义一个编码(encoding参数)用于把对应的Unicode内容转换成你定义的格式,通过encode()函数实现;相应地,当我们从这个文件读取数据时,必须"解码"该文件,使之成为相应的Unicode字符串对象。
str1.decode('gb2312') 解码表示将gb2312编码字符串转换成unicode编码
str2.encode('gb2312') 编码表示将unicode编码的字符串转换成gb2312编码
>>> s = '中文'
>>> s
'\xd6\xd0\xce\xc4'
>>> print s,type(s)
中文 <type 'str'>
>>> s.decode('gb2312')
u'\u4e2d\u6587'
>>> print s.decode('gb2312'),type(s.decode('gb2312'))
中文 <type 'unicode'>
>>> len(s)
4
>>> len(s.decode('gb2312'))
2
>>> t = u'中文'
>>> t
u'\xd6\xd0\xce\xc4'
>>> len(t)
4
>>> print t,type(t)
ÖÐÎÄ <type 'unicode'>
>>> Unicode实际应用
1.程序中出现字符串时一定要加个前缀u
2.不要用str()函数,而是用unicode()代替
3.不要用过时的string模块——如果给它的是非ASCII字符,它会把一切搞砸
4.不到必要时不要再程序里面编解码Unicode字符。只在你要写入文件或数据库或网络时,才调用encode()函数;相应地,只在需要把数据读回来时才调用decode()函数
5.由于pickle模块只支持ASCII字符串,尽量避免基于文本的pickle操作
6.假设构建一个用数据库来读写Unicode数据的Web应用,必须保持以下对Unicode的支持
· 数据库服务器(MySQL、PostgreSQL、SQL Server等)
· 数据库适配器(MySQLLdb等)
· Web开发框架(mod_python、cgi、Zope、Django等)
数据库方面确保每张表都用UTF-8编码,适配器如果不支持Unicode如MySQLdb,则必须在connect()方法里面用一个特殊的关键字use_unicode来确保得到的查询结果是Unicode字符串。mod_python开启对Unicode的支持即可,只要在request对象里面把text-encoding设为“utf-8”就OK了。同时浏览器也注意下。
总结:使用应用程序完全支持Unicode,兼容其他的语言本身就是一个工程。它需要详细的考虑、计划。所有涉及的软件、系统都需要检查,包括Python的标准库和其他要用到的第三方扩展模块。你甚至需要组件一个经验丰富的团队来专门负责国家化(I18N)问题。
四. 常用处理方法总结
源自:http://xianglong.me/article/learn-python-1-chinese-encoding/
结合我遇到的两个问题,归纳了以下几点。常见中文编码问题解决方法包括:
1.遵循PEP0263原则,声明编码格式
在PEP 0263--Defining Python Source Code Encodings中提出了对Python编码问题的最基本的解决方法:在Python源码文件中声明编码格式,最常见的声明方式:
#!/usr/bin/python
# -*- coding: <encoding name> -*-注意,coding:encoding只是告诉Python文件使用了encoding格式的编码,但是编辑器可能会以自己的方式存储.py文件,因此最后文件保存的时候还需要编码中选指定的ecoding才行。
2.字符串变量赋值时添加前缀u,使用 u'中文' 替代 '中文'
str1 = '中文'
str2 = u'中文'如果你要声明的字符串变量中存在非ASCII的字符,那么最好使用str2的声明格式,这样你就可以不需要执行decode,直接对字符串进行操作,可以避免一些出现异常的情况。
3.重置默认编码
Python中出现这么多编码问题的根本原因是Python 2.x的默认编码格式是ASCII,所以你也可以通过以下的方式修改默认的编码格式:sys.getdefaultencoding()默认是'ascii'编码。
#设置编码utf-8
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
#显示当前默认编码方式
print sys.getdefaultencoding() 其原理: 首先, 这个就是Python语言本身的问题。因为在Python 2.x的语法中, 默认的str并不是真正意义上我们理解的字符串, 而是一个byte数组, 或者可以理解成一个纯ascii码字符组成的字符串, 与Python 3中的bytes类型的变量对应; 而真正意义上通用的字符串则是unicode类型的变量, 它则与Python 3中的str变量对应。本来应该用作byte数组的类型, 却被用来做字符串用, 这种看似奇葩的设定是Python 2一直被人诟病的东西, 不过也没有办法, 为了与之前的程序保持兼容.。
在Python 2中作为两种字符串类型, str与unicode之间就需要各种转换的方式。首先是一种显式转换的方式, 就是encode和decode两种方法。在这里这两货的意思很容易被搞反, 科学的调用方式是:
str --- decode方法 ---> unicode
unicode --- encode方法 ---> str
4. 终极原则:decode early, unicode everywhere, encode late
Decode early:尽早decode, 将文件中的内容转化成unicode再进行下一步处理
Unicode everywhere:程序内部处理都用unicode,比如字符串拼接、替换、比较等操作
Encode late:最后encode回所需的encoding, 例如把最终结果写进结果文件
按照这个原则处理Python的字符串,基本上可以解决所有的编码问题(只要你的代码和Python环境没有问题)。前面讲述的两个问题解决实质也是这样,只是有些取巧即可。
5.使用decode().encode()方法
网页采集时,代码指定#coding:utf-8,如果网页的编码为gbk需要这样处理:
html = html.decode('gbk').encode('utf-8')
6.输入变量raw_input中文编码
将终端的输入编码str通过decode转换成unicode编码,再使用unicode处理:
key = raw_input("Please input a key: ").decode(sys.stdin.encoding)
7.文件读写操作
由于默认的txt文件为ANSI编码,读取时通过unicode转码,经过“ 编码=》Unicode=》处理=》utf-8或gbk ”顺序即可。同时文件输出时encode('utf-8')转换txt为UTF-8格式。 终极代码:
info = codecs.open(baiduFile,'w','utf-8')
8.升级Python 2.x到3.x
最后一个方法:升级Python 2.x,使用Python 3.x版本。这样说主要是为了吐槽Python 2.x的编码设计问题。当然,升级到Python 3.x肯定可以解决大部分因为编码产生的异常问题。毕竟Python 3.x版本对字符串这部分还是做了相当大的改进的。
在Python 3.0之后的版本中,所有的字符串都是使用Unicode编码的字符串序列,同时还有以下几个改进:
· 默认编码格式改为unicode
· 所有的Python内置模块都支持unicode
· 不再支持u'中文'的语法格式
所以,对于Python 3.x来说,编码问题已经不再是个大的问题,基本上很少遇到上述的几个异常。
总结
最后希望文章对你有所帮助,尤其是你刚好遇到这个问题的,由于是结合最近做的东西,所以文章比较杂乱,但如果你刚好需要,确实能解决你的问题的。
纪伯伦曾说过:“你无法同时拥有青春和关于青春的知识;因为青春忙于生计,没有余暇去求知;而知识忙于寻求自我,无法享受生活。”
同样现在找工作的我,无法在拥有扎实基础知识的同时又兼顾深度的项目理解,但我更倾向于分享知识,因为它就是寻求自我,就是享受生活,就是编程之乐~


















 203
203

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











