







复习日。
作业:
尝试找到一个kaggle或者其他地方的结构化数据集,用之前的内容完成一个全新的项目,这样你也是独立完成了一个专属于自己的项目。
要求:
- 有数据地址的提供数据地址,没有地址的上传网盘贴出地址即可。
- 尽可能与他人不同,优先选择本专业相关数据集
- 探索一下开源数据的网站有哪些?
对于数据的认识,很重要的一点是,很多数据并非是为了某个确定的问题收集的,这也意味着一份数据你可以完成很多不同的研究,自变量、因变量的选取取决于你自己-----很多时候针对现有数据的思考才是真正拉开你与他人差距的最重要因素。
现在可以发现,其实掌握流程后,机器学习项目流程是比较固定的,对于掌握的同学来说,工作量非常少。所以这也是很多论文被懂的认为比较水的原因所在。所以这类研究真正核心的地方集中在以下几点:
- 数据的质量上,是否有好的研究主题但是你这个数据很难获取,所以你这个研究有价值
- 研究问题的选择上,同一个数据你找到了有意思的点,比如更换了因变量,做出了和别人不同的研究问题
- 同一个问题,特征加工上,是否对数据进一步加工得出了新的结论-----你的加工被证明是有意义的。
后续我们会不断给出,在现有框架上,如何加大工作量的思路。
进阶思考:
- 数据本身是否能够支撑起这个研究?---数据的数目、质量
- 数据的来源是否可靠?
- 什么叫做数据的质量?
- 筛选数据源的标准是什么?
输入:
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns # 添加这行导入
import warnings
warnings.filterwarnings("ignore")
# 设置中文字体(解决中文显示问题)
plt.rcParams['font.sans-serif'] = ['SimHei'] # Windows系统常用黑体字体
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号
# 1. 加载数据
df = pd.read_csv("Medicaldataset.csv")
# 2. 数据概览
print("数据前5行:")
print(df.head())
print("\n数据结构:")
print(df.info())
# 3. 数据清洗
# 检查缺失值
print("\n缺失值统计:")
print(df.isnull().sum())
#删除数据中的最前列的数字序号
df.drop(columns=df.columns[0], inplace=True)
# 检查重复值
print("\n重复值统计:")
print(df.duplicated().sum())
# 无重复值
# 4. 对象类型特征处理
# 查看对象类型特征
print("\n对象类型特征:")
print(df.select_dtypes(include=['object']).columns)
# 对对象类型进行标签编码
mapping = {
'negative': 0,
'positive': 1,
}
df['Result'] = df['Result'].map(mapping)
# 查看编码后的结果
print("\n编码后的Result列:")
print(df['Result'].head())
# 5. 可视化
# 绘制直方图
df.hist(bins=20, figsize=(20, 15))
plt.suptitle('特征分布直方图', fontsize=16)
plt.show()
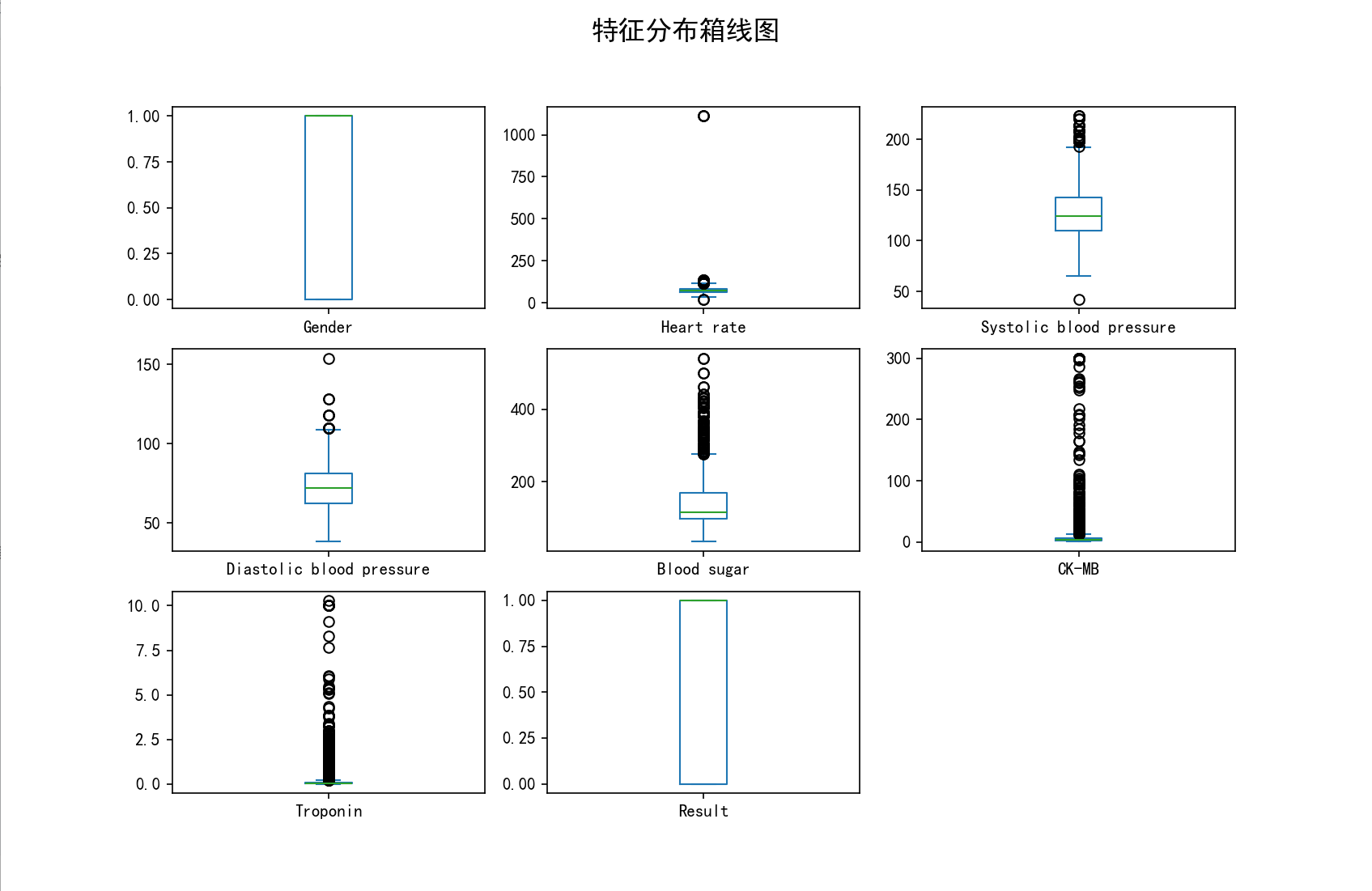
# 绘制箱线图
df.plot(kind='box', subplots=True, layout=(3, 3), figsize=(15, 10), sharex=False, sharey=False)
plt.suptitle('特征分布箱线图', fontsize=16)
plt.show()
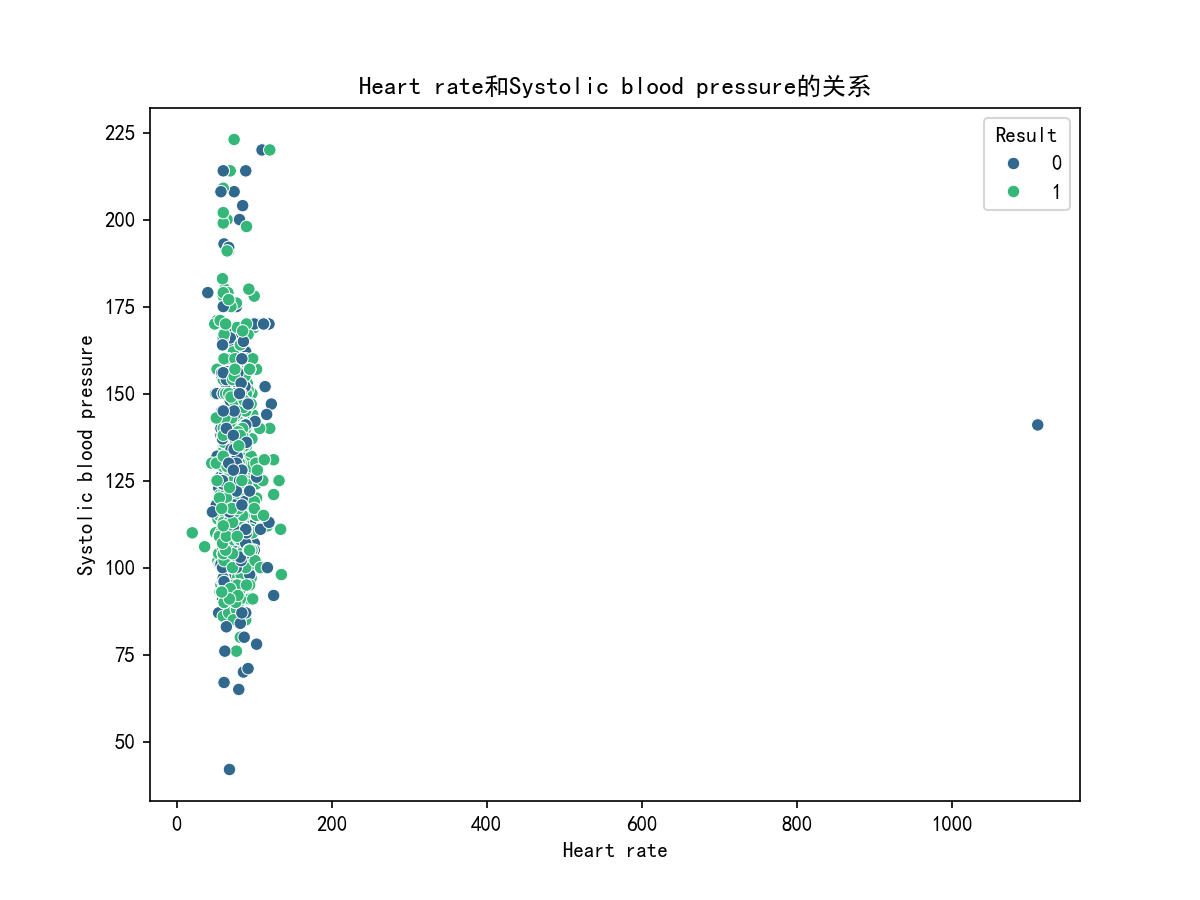
#Heart rate和Systolic blood pressure的关系
plt.figure(figsize=(8, 6))
sns.scatterplot(x='Heart rate', y='Systolic blood pressure', data=df, hue='Result', palette='viridis')
plt.title('Heart rate和Systolic blood pressure的关系')
plt.show()
# 6. 数据划分
X = df.drop(columns=['Result']) # 特征
y = df['Result'] # 目标变量
# 划分训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 7. 随机森林分类器模型训练
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(random_state=42)
model.fit(X_train, y_train)
# 8. 模型评估
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, roc_auc_score
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)
roc_auc = roc_auc_score(y_test, y_pred)
print("\n模型评估:")
print(f"准确率: {accuracy:.4f}")
print(f"精确率: {precision:.4f}")
print(f"召回率: {recall:.4f}")
print(f"F1分数: {f1:.4f}")
print(f"AUC: {roc_auc:.4f}")
#网格搜索优化随机森林模型
from sklearn.model_selection import GridSearchCV
param_grid = {
'n_estimators': [100, 200, 300],
'max_depth': [None, 10, 20, 30],
'min_samples_split': [2, 5, 10],
'min_samples_leaf': [1, 2, 4],
'max_features': ['auto', 'sqrt', 'log2'],
'bootstrap': [True, False],
'criterion': ['gini', 'entropy'],
}
grid_search = GridSearchCV(estimator=model, param_grid=param_grid, cv=5,
scoring='accuracy', n_jobs=-1, verbose=0) # 将verbose改为0
grid_search.fit(X_train, y_train)
# 输出最佳参数和最佳分数
print("\n最佳参数:")
print(grid_search.best_params_)
print("\n最佳分数:")
print(grid_search.best_score_)
# 使用最佳参数重新训练模型
best_model = grid_search.best_estimator_
best_model.fit(X_train, y_train)
# 8. 模型评估
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, roc_auc_score
y_pred = best_model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)
roc_auc = roc_auc_score(y_test, y_pred)
print("\n网格搜索优化随机森林模型评估:")
print(f"准确率: {accuracy:.4f}")
print(f"精确率: {precision:.4f}")
print(f"召回率: {recall:.4f}")
print(f"F1分数: {f1:.4f}")
print(f"AUC: {roc_auc:.4f}")
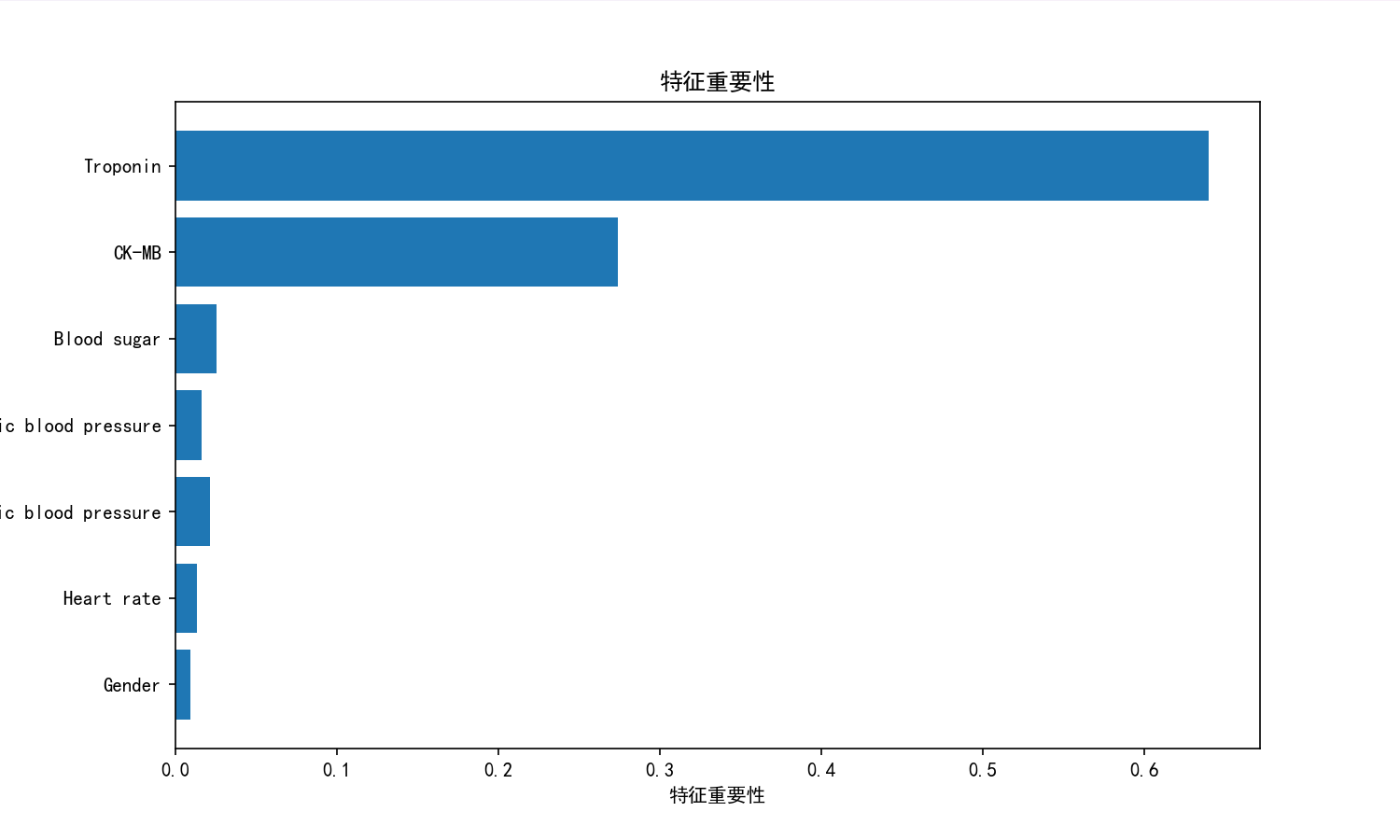
# 9. 特征重要性
feature_importances = model.feature_importances_
feature_names = X.columns
plt.figure(figsize=(10, 6))
plt.barh(feature_names, feature_importances)
plt.xlabel('特征重要性')
plt.title('特征重要性')
plt.show()
输出:
数据前5行:
Age Gender Heart rate Systolic blood pressure Diastolic blood pressure Blood sugar CK-MB Troponin Result
0 64 1 66 160 83 160.0 1.80 0.012 negative
1 21 1 94 98 46 296.0 6.75 1.060 positive
2 55 1 64 160 77 270.0 1.99 0.003 negative
3 64 1 70 120 55 270.0 13.87 0.122 positive
4 55 1 64 112 65 300.0 1.08 0.003 negative
数据结构:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1319 entries, 0 to 1318
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Age 1319 non-null int64
1 Gender 1319 non-null int64
2 Heart rate 1319 non-null int64
3 Systolic blood pressure 1319 non-null int64
4 Diastolic blood pressure 1319 non-null int64
5 Blood sugar 1319 non-null float64
6 CK-MB 1319 non-null float64
7 Troponin 1319 non-null float64
8 Result 1319 non-null object
dtypes: float64(3), int64(5), object(1)
memory usage: 92.9+ KB
None
缺失值统计:
Age 0
Gender 0
Heart rate 0
Systolic blood pressure 0
Diastolic blood pressure 0
Blood sugar 0
CK-MB 0
Troponin 0
Result 0
dtype: int64
重复值统计:
0
对象类型特征:
Index(['Result'], dtype='object')
编码后的Result列:
0 0
1 1
2 0
3 1
4 0
Name: Result, dtype: int64
libpng warning: Interlace handling should be turned on when using png_read_image
libpng warning: Interlace handling should be turned on when using png_read_image
模型评估:
准确率: 0.9811
精确率: 0.9817
召回率: 0.9877
F1分数: 0.9847
AUC: 0.9790
最佳参数:
{'bootstrap': False, 'criterion': 'gini', 'max_depth': None, 'max_features': 'sqrt', 'min_samples_leaf': 1, 'min_samples_split': 2, 'n_estimators': 300}
最佳分数:
0.9914691943127962
网格搜索优化随机森林模型评估:
准确率: 0.9773
精确率: 0.9758
召回率: 0.9877
F1分数: 0.9817
AUC: 0.9741
可视化图片: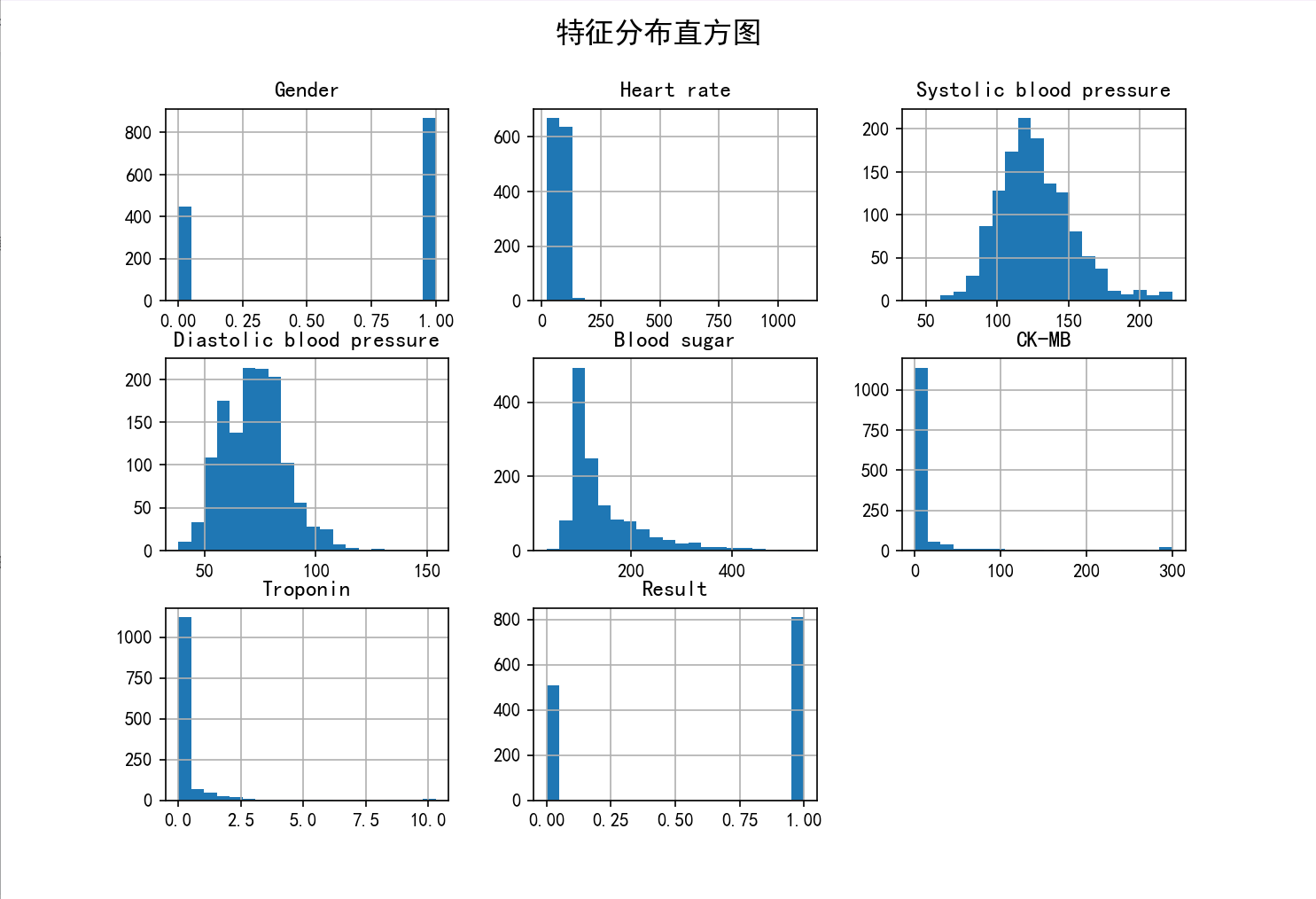

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









