







语言模型
Transformer 神经网络
Transformer 是一种基于自注意力机制的新型神经网络。下图展示了 2017 年文章《Attention is all you need》中描述的 Transformer 单元结构图:
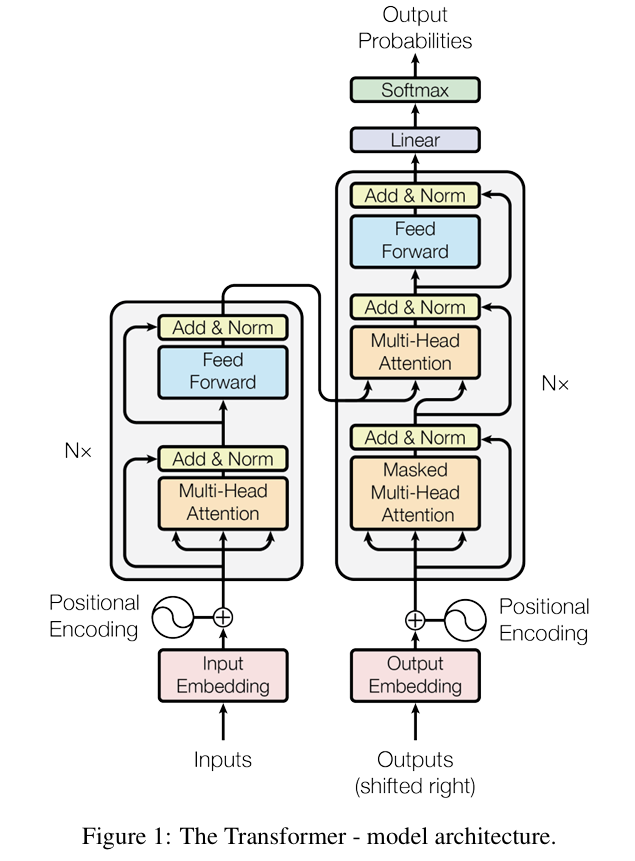
本单元的主要模块——多头注意力机制基于自注意力机制。自注意力机制是一种根据特定单词的上下文对其嵌入进行转换的机制,它同时考虑了单词在此上下文中相互的影响。语言中的单词彼此相关,自注意力机制建议通过为每个单词创建三类向量来考虑每个单词之间关系的“权重”:值(
v
v
v)、查询(
q
q
q)和键(
k
k
k)。为了确定单词
w
i
w_i
wi 对单词
w
j
w_j
wj 在特定语境中的影响力“权重”,构造函数:
f
(
v
⃗
i
,
k
⃗
i
,
q
⃗
j
)
=
ρ
(
k
⃗
i
,
q
⃗
j
)
⋅
v
⃗
i
f(\vec{v}_i, \vec{k}_i, \vec{q}_j) = ρ(\vec{k}_i, \vec{q}_j)⋅\vec{v}_i
f(vi,ki,qj)=ρ(ki,qj)⋅vi
其中函数
ρ
\rho
ρ 确定向量
k
⃗
i
\vec{k}_i
ki 和
q
⃗
j
\vec{q}_j
qj 的接近度,通常是普通的标量积。然后,更新后的词向量
o
u
t
j
out_j
outj 被定义为其他词对词
w
j
w_j
wj 本身的“影响”的集合:
o
u
t
j
=
∑
i
=
1
n
ρ
(
k
⃗
i
,
q
⃗
j
)
⋅
v
⃗
i
out_j = \sum\limits_{i=1}^nρ(\vec{k}_i, \vec{q}_j)⋅\vec{v}_i
outj=i=1∑nρ(ki,qj)⋅vi
在这种情况下,向量 value、query 和 key 具有以下含义:
- value 向量 - 表示待处理的词向量的向量
- query 向量 - “query” 向量,即从 evaluated 词传递过来的向量,用于确定上下文中另一个词的影响
- key 向量 - 用于确定给定词对上下文中另一个词的影响的“key” 向量
这三个向量均由三个参数化矩阵构成:
Q
Q
Q、
V
V
V 和
K
K
K。接收词向量作为输入,将这三个矩阵乘以原始向量
w
i
w_i
wi,即可得到自注意力所需的三个向量:
v
⃗
i
=
V
w
⃗
i
\vec{v}_i = V\vec{w}_i
vi=Vwi
q
⃗
i
=
V
Q
⃗
i
\vec{q}_i = V\vec{Q}_i
qi=VQi
k
⃗
i
=
V
K
⃗
i
\vec{k}_i = V\vec{K}_i
ki=VKi
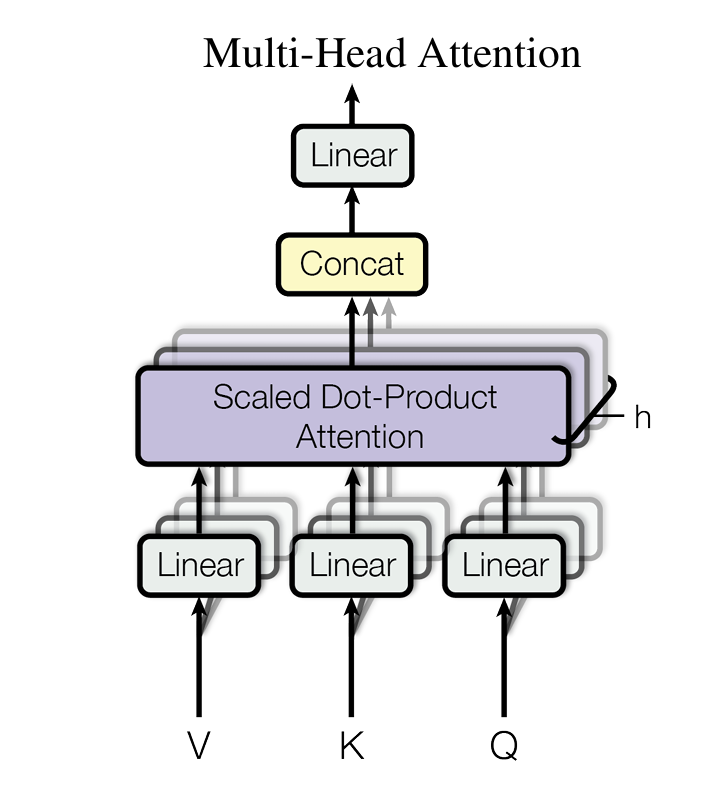
这些矩阵是系统的可训练参数。多头注意力机制包括在每一层并行计算此类变换的多个变体。
语言建模
语言模型通常是指任何能够根据上下文预测缺失单词或后续单词的系统。通常,在使用语言模型时,会使用一些简单的术语。假设我们知道词汇表,即在给定语言中可能遇到的所有单词的集合。这些单词通常被称为token,将文本分解成token的过程称为tokenization。在实际的语言模型中,一个token通常并不真正代表一个单词;每个单词通常包含多个token,因此token可以粗略地被视为一种特定形式的词素。目前,我们不会深入讨论tokenization过程的细节,尽管我们将在本讲中更详细地讨论它,因为现在您可以将token视为单词的一些固定部分,甚至可以视为整个单词。
在这种情况下,语言模型是整个词典的条件概率分布模型,其中条件作用于某些上下文。这一机制在 RNN 讲座中有详细描述。
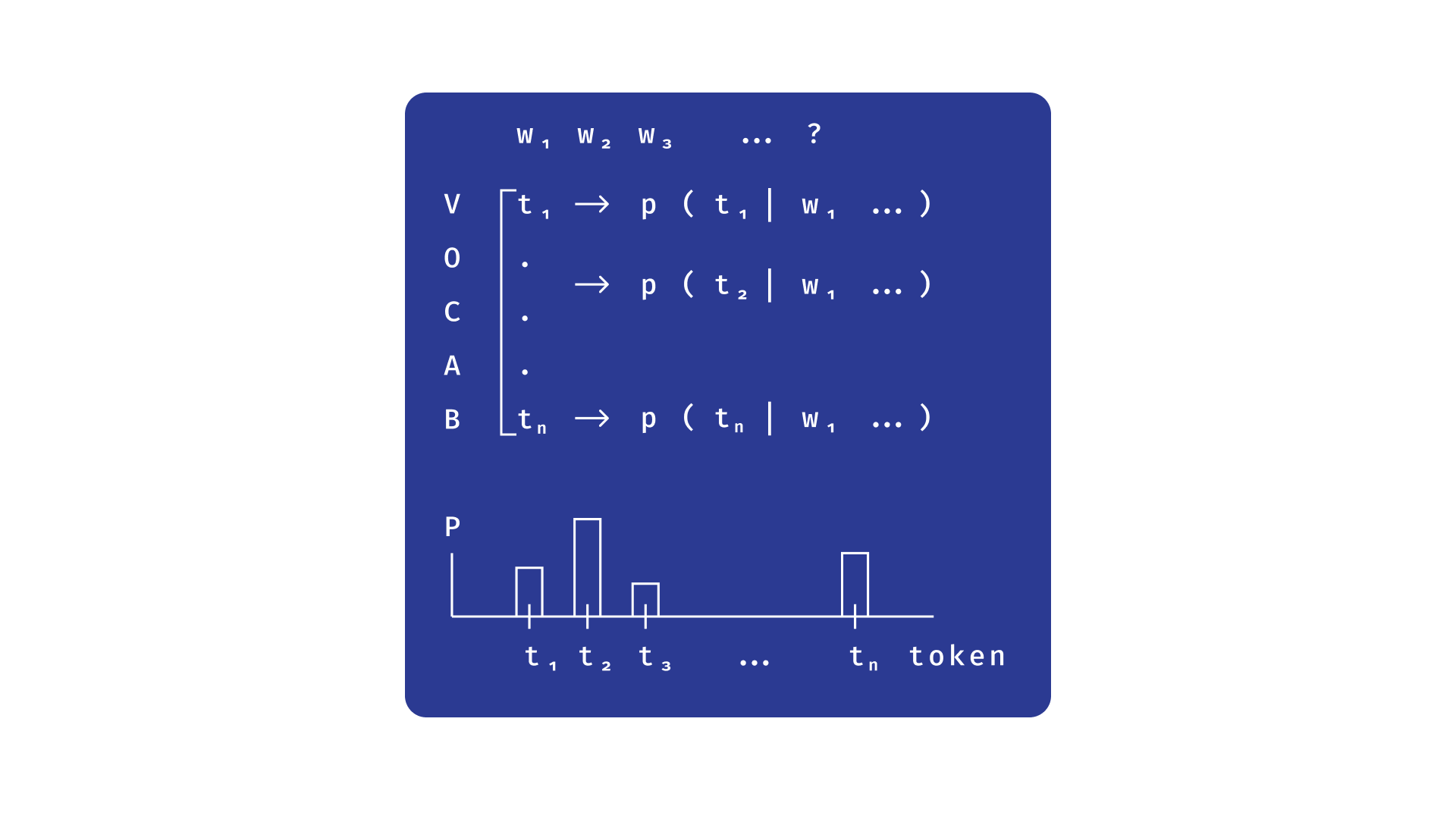
换句话说,语言模型是一种能够根据上下文预测单词的工具。在最佳情况下,如果预测质量足够高,这类模型能够根据对先前单词作为上下文单词的预测,完成或撰写整篇文章。在本讲座中,我们将探讨一些流行的语言模型的工作原理,以及为什么语言模型可以用来构建通用的方法来解决各种自然语言处理问题。
在之前的课程中,您已经在循环神经网络的讨论中接触过语言建模的问题。语言建模可以分为以下几类:
- 正向语言建模(根据之前的上下文预测下一个单词)
- 逆向语言建模(根据后续上下文预测文本中的前一个单词)
- 掩码语言建模(预测缺失的单词)
困惑度
事实上,在训练语言模型中, P ( t i ∣ c o n t e x t ) P(t_i|context) P(ti∣context) 模型的具体结构并非最重要的问题。假设我们已经找到了所有技术难题的解决方案:我们找到了一个能够有效学习所需概率分布的优秀模型,收集了大量训练数据,拥有了性能良好的显卡,并找到了有效并行计算的方法。然而,我们缺少一个重要的组件来开始训练——需要最小化的损失函数。那么,如何将语言模型的训练问题简化为最小化某个函数的问题呢?
事实证明,有一个广泛用于训练语言模型的标准函数:困惑度。困惑度衡量的是模型在特定语境中遇到特定单词时的“惊讶程度”。困惑度 (Perplexity) 的定义如下:
P ( W ) = l n ( ∏ i = 1 N p ( w i ) ) = ∑ i = 1 n l n ( P ( w i ) ) P(W) = ln({\prod_{i=1}^{N} p(w_i)}) = ∑\limits_{i=1}^nln(P(w_i)) P(W)=ln(i=1∏Np(wi))=i=1∑nln(P(wi))
其中 W W W 是某个特定的 token 序列 w 1 . . . w n w_1 ... w_n w1...wn。表达式中的第二个等式非常重要,因为它是实际计算困惑度的唯一方法。因为词典通常包含数十万、数百万甚至数千万个 token,因此无法直接计算概率乘积——因为这个数字会非常小。
困惑度的直观理解可以如下:假设文本整体是一个结构,代表一组用于放置特定单词的位置。特定文本就是用单词对这些位置进行的特定填充。在这种情况下,遇到特定文本的概率是多少?这是遇到第一个词 w 1 w_1 w1、第二个词 w 2 w_2 w2、第三个词 w 3 w_3 w3 等的概率。即 p ( w 1 ) ⋅ p ( w 2 ) ⋅ p ( w 3 ) ⋅ . . . p(w_1)\cdot p(w_2) ⋅ p(w_3) ⋅ ... p(w1)⋅p(w2)⋅p(w3)⋅... 然而,直接计算这种概率乘积并对其进行任何运算非常困难,因为这个数字会非常小。因此,使用了所谓的 对数技巧 - 对概率乘积取对数,并将乘积的对数转换为对数和。 l n ( ∏ i = 1 N p ( w i ) ) = ∑ i = 1 n l n ( P ( w i ) ) ln({\prod_{i=1}^{N} p(w_i)}) = ∑\limits_{i=1}^nln(P(w_i)) ln(i=1∏Np(wi))=i=1∑nln(P(wi))
自监督学习
语言建模任务属于自监督学习类任务。事实上,从形式上来说,这项任务应该归于监督学习领域,一方面,因为模型学习预测某些标签;另一方面,数据无需预先标记——所有必要信息都已包含在文本中。这类任务被称为自监督学习。这非常好,因为无需标记庞大的数据集来训练大型模型。
BERT
世界上最早也是最著名的语言模型之一是 BERT(基于 Transformer 的双向编码器表示)。
2017 年,谷歌发布了其产品,该产品由一组基于大量英语互联网文本语料库训练的编码器组成。
提出该架构的文章迄今为止已被引用超过 1000 次。如果您想了解更多关于 BERT 架构的信息,也可以访问 链接。
BERT 的目标是生成通用的嵌入向量,使其能够完美地解决几乎所有的 NLP 任务。为了解决这一雄心勃勃的任务,BERT 的创建者基于以下假设:
能够有效预测上下文中缺失词的嵌入向量能够相当准确地建模语言的语义结构
这个事实可能看起来很奇怪:根据上下文预测缺失词的任务本身就很奇怪。然而,所有现代法学硕士 (LLM) 都基于这种(或类似的)方法。
以下是加拿大裔美国苏联科学家、OpenAI 联合创始人之一 Ilya Sutskever 对此的看法:
我将尝试解释为什么预测下一个词需要深入理解。假设你正在阅读一本侦探小说:故事情节复杂,细节错综复杂,人物众多,谜语迭出,事件层出不穷。想象一下,在书的最后一页,作者写道:“犯罪者是……”。尝试预测这个词
在这方面,总体而言,BERT 的工作分为两个阶段:预训练和微调
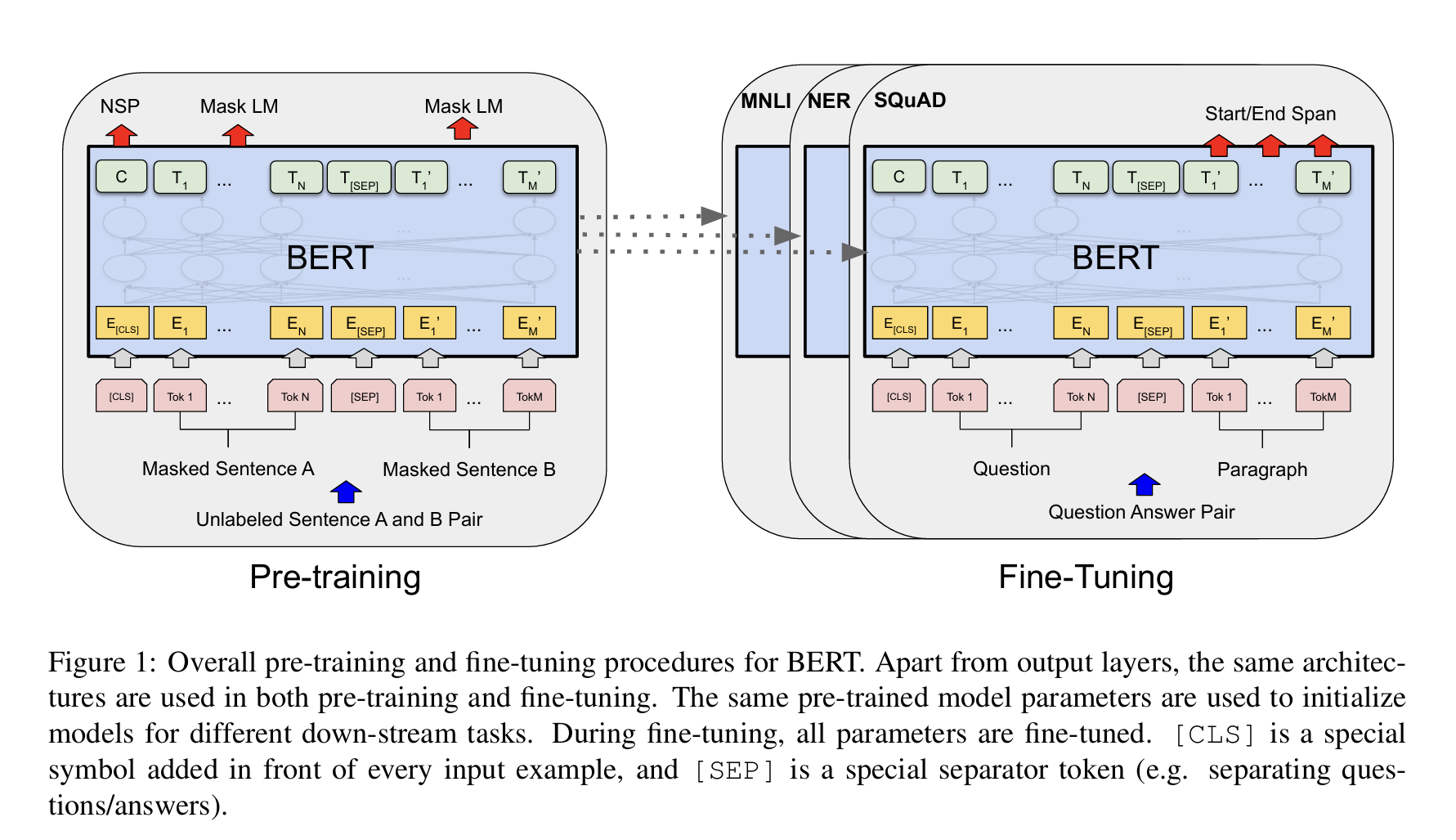
图1. BERT的总体预训练和微调过程。除了输出层外,相同的结构也用于预训练和微调。相同的预训练模型参数用于为不同的下游任务初始化模型。在微调过程中,所有参数都会被微调。[CLS]是一个特殊符号,添加在每个输入示例前面,而[SEP]是一个特殊的分隔符号(例如:分隔问题/答案)。
预训练
Pre-Training
此阶段的特点是模型学习形成这样的嵌入,基于此可以有效地预测缺失词。
这些嵌入具有语境性的属性。这意味着同一个词的嵌入在不同的语境下会有不同的向量表示。这是通过以下方式获得的:有一些静态嵌入用作自注意力机制的输入向量表示。然后,这些嵌入通过 N N N 层 Transformer 编码器进行前向传播(原始 BERT 有两个版本:一个版本 N = 12 N=12 N=12,另一个版本 N = 24 N=24 N=24,第一个版本包含 1.1 亿个参数,第二个版本包含 3.4 亿个参数)。

图2: BERT输入表示。输入嵌入是令牌嵌入、分段嵌入和位置嵌入的总和。
因此,使用困惑度作为损失函数,模型根据标准变压器方案为每一层训练查询、键和值矩阵。
微调
Fine-Tune
BERT 的主要特点是,从中获得的嵌入几乎可以用于解决任何问题。第一种选择是进一步训练一个新的模型来解决目标问题,即“自上而下”地使用 BERT 的输出作为输入,再单独训练一个新模型。这种方法的优点在于相对简单,但缺点在于,在某些情况下,它需要更多的计算资源和时间,而且解决问题的质量仍然比第二种方法差。
第二种选择我们很熟悉——微调,我们在讨论迁移学习时遇到过,这里也提到了。每一层的矩阵 Q Q Q、 V V V 和 K K K 可以进一步训练来解决特定问题。
以下是这类问题的简短列表:
-
NER(命名实体识别)——命名实体的识别。从技术层面上讲,这项任务归结为根据文本中指定类别的命名实体对标记进行标记。
-
问答 (Q&A) - 识别并总结针对特定文本提出的问题的答案。
-
文本蕴涵识别 (RTE) - 判断两个陈述之间是因果关系、相互矛盾还是中立。
-
确定文本的语调 - 判断特定陈述的积极性、消极性或中立性。
分词
每个模型通常都会训练一个特定的分词器。分词有一些共同的特征,可以归因于所有类似 bert 的模型。例如,使用特殊分词 <SEP> 和 <CLS>。<SEP> 分词用于确定句子或其他完整文本片段的结尾。<CLS> 分词用于标记已处理片段的结尾,系统会将其视为单个文本,并据此计算自注意力机制。
Huggingface
使用 Huggingface 的总体思路是通过 Transformers 框架中实现的标准化接口加载模型。(注意:Google Colab 并未预装该接口,您需要通过 pip 进行加载。)
我们将加载一个类似 bert 的模型,用于生成缺失的文本片段。该模型名为“bart-large”。
from transformers import BartTokenizer, BartForConditionalGeneration
tokenizer = BartTokenizer.from_pretrained('facebook/bart-large')
model = BartForConditionalGeneration.from_pretrained('facebook/bart-large')
text = "Hello, my name is <mask>"
inputs = tokenizer(text, return_tensors="pt")
outputs = model.generate(**inputs)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
输出:
Hello, my name is Alex.
我们可以生成多个令牌。
from transformers import BartForConditionalGeneration, BartTokenizer
model = BartForConditionalGeneration.from_pretrained("facebook/bart-large", forced_bos_token_id=0)
tok = BartTokenizer.from_pretrained("facebook/bart-large")
example_english_phrase = "I Believe In <mask> Under My <mask>"
batch = tokenizer(example_english_phrase, return_tensors="pt")
generated_ids = model.generate(batch["input_ids"])
tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
输出:
[‘I Believe In God Under My Skin’]
或者像这样:
example_english_phrase = "Hello, My Name Is <mask> Color Is Green"
batch = tokenizer(example_english_phrase, return_tensors="pt")
generated_ids = model.generate(batch["input_ids"])
tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
输出:
[‘Hello, My Name Is Lucy and My Color Is Green’]
然而,该模型不能很好地处理文本完成问题。
example_english_phrase = "I Believe In <mask>"
batch = tok(example_english_phrase, return_tensors="pt")
generated_ids = model.generate(batch["input_ids"])
tok.batch_decode(generated_ids, skip_special_tokens=True)
输出:
[‘I Believe In You’]
位置编码
与循环神经网络等相比,自注意力结构的一个问题是,经典的自注意力机制没有考虑词条的序列,而这在语言中至关重要。
为了解决这个问题,有人提出在句子中使用特殊的词序“标记”,这些标记由所谓的位置编码向量指定。
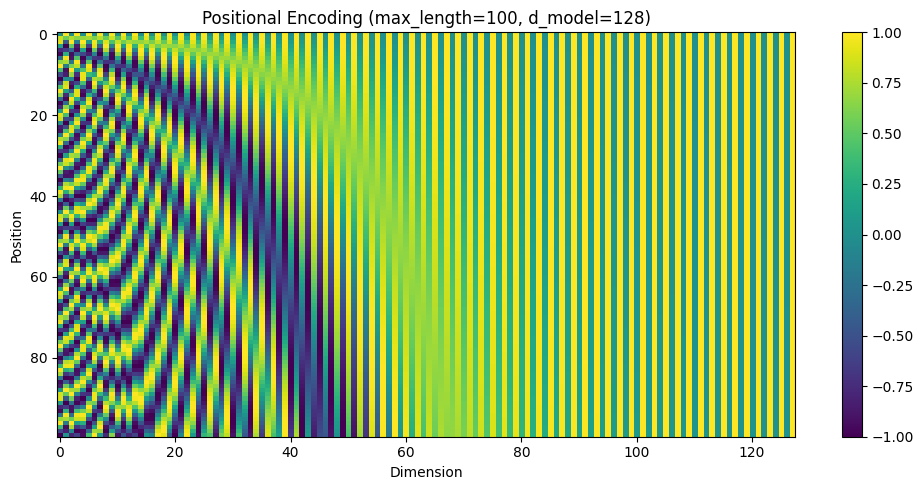
通常,存在多种构建位置编码的方法,甚至可以创建可训练的嵌入。以下(略微复杂的)方法已在业界扎根:
假设我们要将词条 t t t 的序数编码为一个维度为 d d d 的向量。那么,该向量的第 i i i 个坐标将由三角函数给出:
p
i
t
=
s
i
n
(
w
k
t
)
,
i
=
2
k
p_i^t = sin(w_k t), i = 2k
pit=sin(wkt),i=2k
p
i
t
=
c
o
s
(
w
k
t
)
,
i
=
2
k
+
1
p_i^t = cos(w_k t), i = 2k + 1
pit=cos(wkt),i=2k+1
其中
w
k
=
1
1000
0
2
k
d
w_k = \frac{1}{10000^{\frac{2k}{d}}}
wk=10000d2k1
import numpy as np
import matplotlib.pyplot as plt
import torch
def gen_pe(max_length, d_model, n):
pe = torch.zeros(max_length, d_model)
position = torch.arange(0, max_length, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-np.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
return pe
def visualize_pe(max_length, d_model, n):
pe = gen_pe(max_length, d_model, n)
plt.figure(figsize=(10, 5))
plt.imshow(pe.squeeze(), cmap='viridis', aspect='auto')
plt.title(f"Positional Encoding (max_length={max_length}, d_model={d_model})")
plt.xlabel('Dimension')
plt.ylabel('Position')
plt.colorbar()
plt.tight_layout()
plt.show()
# 可视化参数
max_length = 100
d_model = 128
n = 10000
visualize_pe(max_length, d_model, n)
输出:
# 可视化参数
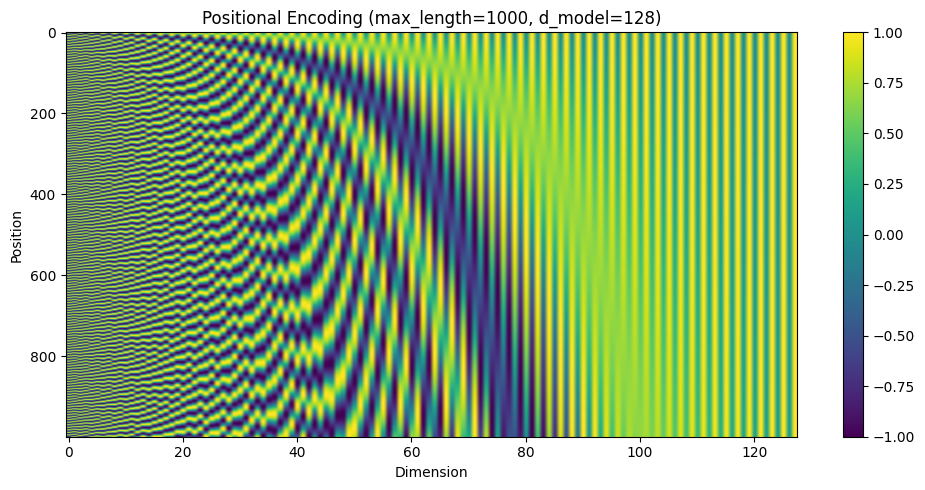
max_length = 1000
d_model = 128
n = 10000
visualize_pe(max_length, d_model, n)
输出:
# 可视化参数
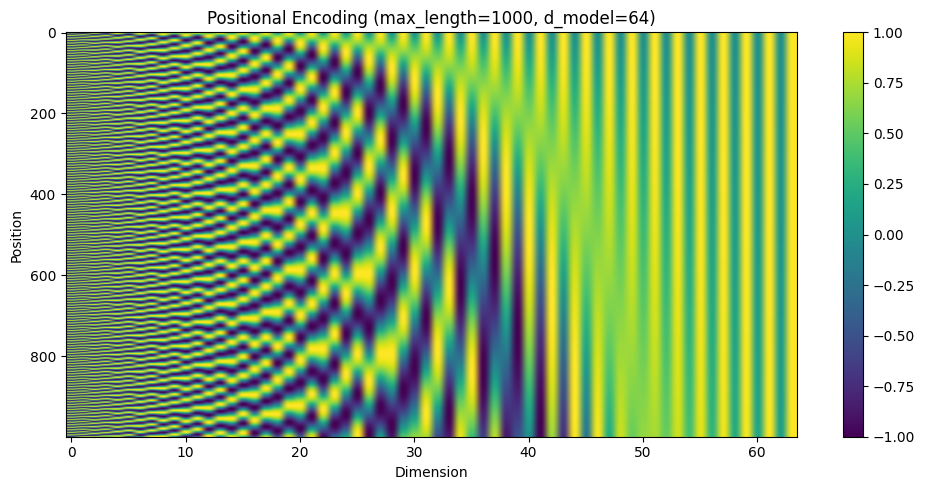
max_length = 1000
d_model = 64
n = 10000
visualize_pe(max_length, d_model, n)
输出:
多语言嵌入
有些模型可以同时用多种语言进行训练。这样的模型被称为多语言模型。构建多语言模型的方法有很多种。
让我们考虑一个流行的多语言模型,它基于一种名为LABSE的特殊BERT再训练技术。该架构在 2022 年的论文《语言无关的 BERT 句子嵌入》中提出。
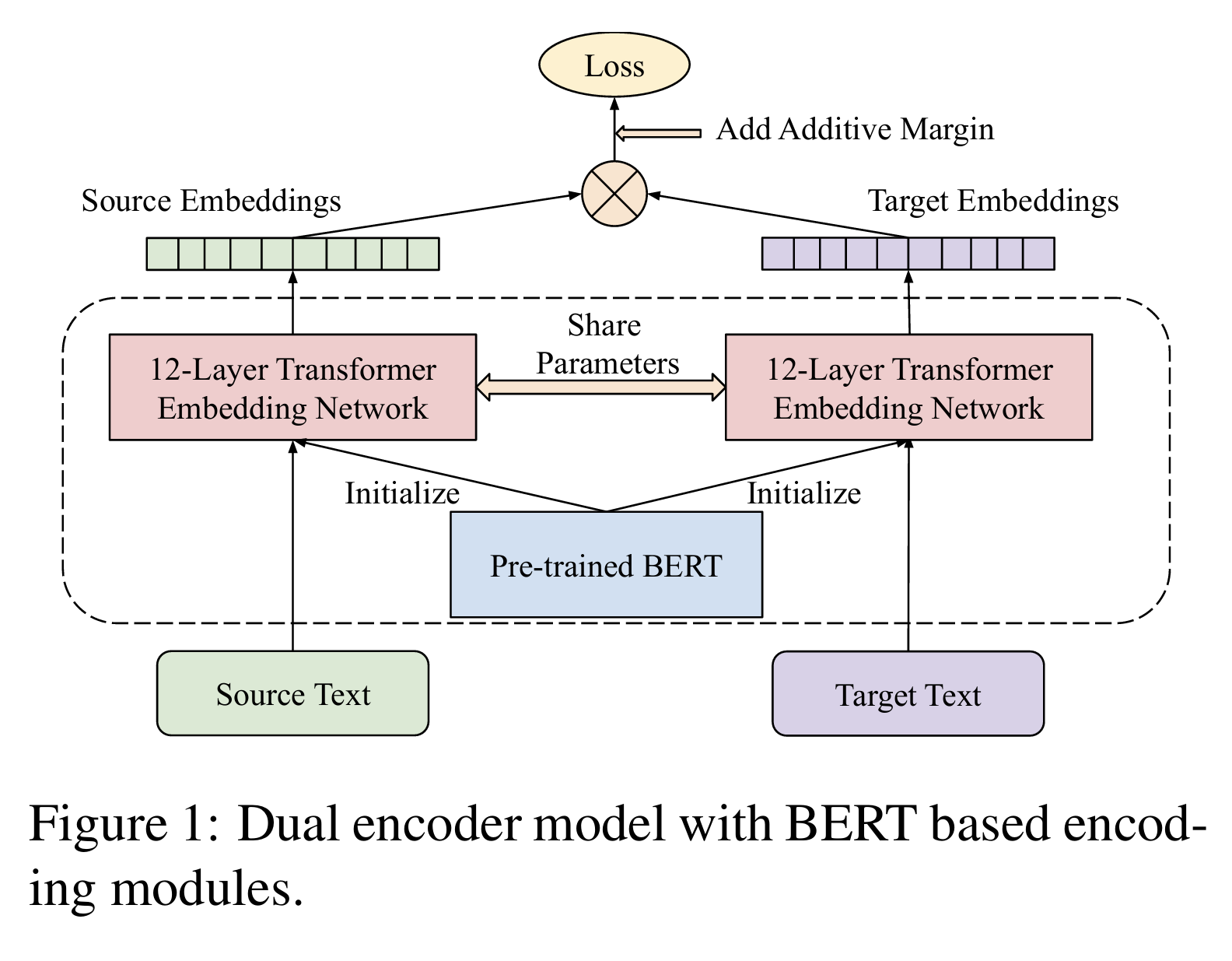
在这种情况下,学习多语言嵌入是基于使用 12 级 Transformer 模型来近似不同语言中相同句子的嵌入,该模型在不同语言中形成具有相同权重的嵌入。让我们进行一个小实验,检查该模型是否真的具有多语言特性。
import numpy as np
from sentence_transformers import SentenceTransformer
import matplotlib.pyplot as plt
# 加载 LABSE 模型
model = SentenceTransformer('LabSE')
# 俄语和英语的随机句子
ru_sentences = [
"Солнце светит ярко в ясном небе.",
"Дети играют во дворе.",
"Кофе очень вкусный сегодня утром.",
"Морской воздух полезен для здоровья.",
"Зима приносит много снега."
]
en_sentences = [
"The sun shines brightly in the clear sky.",
"Children play in the yard.",
"Coffee tastes great today morning.",
"Sea air is healthy for health.",
"Winter brings a lot of snow."
]
输出:

embeddings_ru = model.encode(ru_sentences)
embeddings_en = model.encode(en_sentences)
# 计算余弦距离矩阵
similarity_matrix = np.dot(embeddings_ru, embeddings_en.T)
# 矩阵可视化
plt.figure(figsize=(10, 8))
plt.imshow(similarity_matrix, cmap='hot', interpolation='nearest')
plt.colorbar()
plt.title("Cosine Similarity Matrix")
plt.xlabel("Sentences")
plt.ylabel("Sentences")
plt.show()
print("Similarity matrix:")
print(similarity_matrix)
输出:
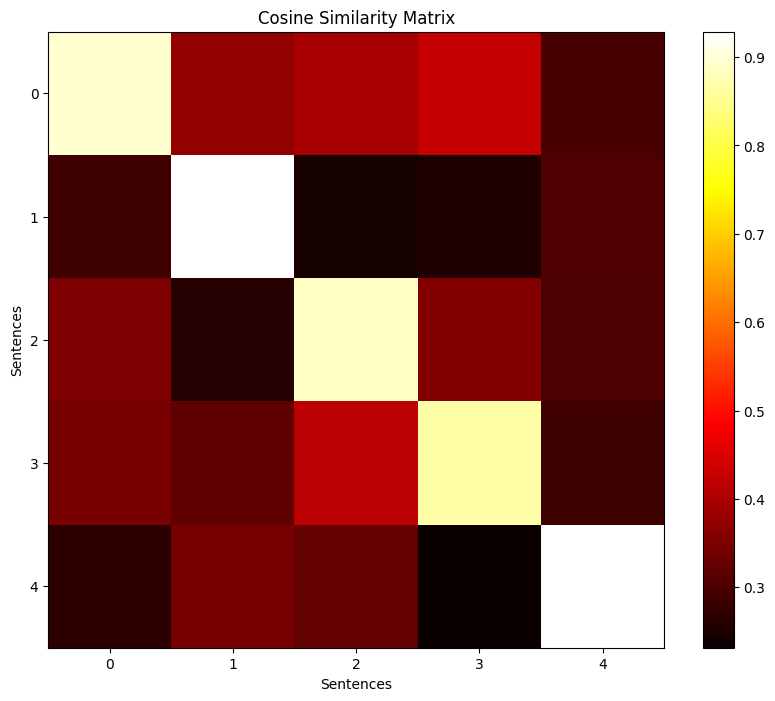
Similarity matrix:
[[0.8946872 0.37413913 0.3953758 0.42664015 0.29803836]
[0.28703174 0.92642796 0.24674855 0.25569195 0.30463776]
[0.35156956 0.26104498 0.8876055 0.3570332 0.30249947]
[0.34635916 0.32278377 0.41682693 0.86828506 0.28749764]
[0.2671177 0.34387994 0.32551455 0.23172364 0.9286376 ]]
LLM
大型语言模型 (LLM) 是具有大量参数(从数十亿到数千亿)的语言模型(通常也基于 Transformer 编码器构建),适用于解决自然语言处理中的任意问题,这些问题本身通常也以自然语言的形式呈现。
LLM 的关键特性在于能够解决那些难以通过严格形式化解决的问题。此外,LLM 通常能够很好地处理摘要、机器翻译、命名实体提取以及回答文本相关问题等任务。
通常,在使用 LLM 生成文本时,用户请求和任务上下文在技术上是分离的(后者通常称为系统提示,它规范对用户请求的响应的上下文、样式和内容)。
使用 LLM 时的标准超参数是温度 (Temperature) 和 top_p。温度 (Temperature) 是一个决定生成 token 可变性的参数。每个后续 token 都是根据字典中的概率分布随机生成的,如下所示:
c
o
n
t
e
x
t
=
w
1
.
.
.
w
n
−
1
→
D
v
context = w_1 ... w_{n-1} → D_v
context=w1...wn−1→Dv
其中
D
v
=
p
1
,
p
2
,
.
.
.
p
∣
V
∣
D_v = p_1, p_2, ... p_{|V|}
Dv=p1,p2,...p∣V∣。Temperature 是一个参数,它通过将概率除以某个数
T
T
T 来帮助“平滑”分布。如果
T
T
T 接近于零,那么最有可能出现的 token 会获得更高的生成概率,而概率较小的 token 几乎不会被生成;但如果
T
T
T 大于
1
1
1,则生成的 token 会变得更加随机。
LLM 中的 Top_p 是一个影响输出随机性的参数。
它设置了将 token 纳入模型用于生成输出的候选集的概率阈值。该参数值越低,答案越准确,值越高,则随机性和多样性越高。
因此
-
LLM 中的“温度”是一个影响生成文本多样性和可预测性的参数。
-
在较低“温度”下(接近 0),模型会更具确定性,选择概率最高的单词,并忽略概率较低的变体,从而使输出更可预测。
-
在较高“温度”下(高于 1),模型会变得更加随机,甚至会给概率较低的单词一个机会,这可能会导致更多样化或意想不到的结果。
-
Top_p 是将某个 token 纳入生成候选集所需的概率阈值。
让我们以小型 LLM SmolLM-1.7B-Instruct 为例来看一下这些参数。
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "HuggingFaceTB/SmolLM-1.7B-Instruct"
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
输出:

messages = [{"role": "user", "content": "What is the capital of France?"}]
input_text=tokenizer.apply_chat_template(messages, tokenize=False)
print(input_text)
inputs = tokenizer.encode(input_text, return_tensors="pt")
outputs = model.generate(inputs, max_new_tokens=50, temperature=0.2, top_p=0.9, do_sample=True)
print(tokenizer.decode(outputs[0]))
输出:

print(tokenizer.decode(outputs[0]))
输出:

让我们重新生成以查看模型的响应是否发生变化。
outputs = model.generate(inputs, max_new_tokens=50, temperature=1., top_p=0.9, do_sample=True)
print(tokenizer.decode(outputs[0]))
输出:

现在让我们改变温度。
outputs = model.generate(inputs, max_new_tokens=50, temperature=1.2, top_p=0.9, do_sample=True)
print(tokenizer.decode(outputs[0]))
输出:

RAG 系统
RAG 系统(检索增强生成)是当今大型语言模型最先进的应用之一。RAG 系统是一种结合在现有数据仓库中搜索相关信息和使用语言模型生成文本的技术。简而言之,RAG 系统是一种基于文本生成问题答案的系统,该文本包含指向数据库中源的链接。
RAG 系统的总体架构如下:
-
将计划搜索感兴趣信息的整个文本语料库划分为块,即短片段。如何将文本精确划分为块的问题并没有唯一的答案——存在不同的算法。一个词块可以被认为是一组 n n n 个连续的句子。
-
输入问题被向量化,并(通常使用 KNN 系列算法之一)找到 k k k 个可能包含答案的候选词块。
-
这些候选词块的文本被输入到语言模型的输入中,用于摘要并找到问题的具体答案。
让我们编写一个简单的 RAG 系统,并尝试根据一小段文本生成问题的答案。
import numpy as np
import torch
from sklearn.neighbors import NearestNeighbors
from transformers import AutoTokenizer, AutoModel, DPRContextEncoder, pipeline
from tqdm import tqdm
import warnings
warnings.filterwarnings('ignore')
device = "cuda" if torch.cuda.is_available() else "cpu"
device
输出:cpu
作为向量化知识库和问题的模型,我们将采用密集段落检索模型,该模型经过专门训练,可与 RAG 系统配合使用。
# Model for encoding the context
tokenizer = AutoTokenizer.from_pretrained("facebook/dpr-ctx_encoder-multiset-base", device = device)
model = DPRContextEncoder.from_pretrained("facebook/dpr-ctx_encoder-multiset-base")
输出:
# Model for encoding the question
q_tokenizer = AutoTokenizer.from_pretrained("facebook/dpr-question_encoder-multiset-base", device = device)
q_model = AutoModel.from_pretrained("facebook/dpr-question_encoder-multiset-base")
输出:

我们将采用 Google Flan 作为总结回复的语言模型。
# Model for context question answering
pipe = pipeline("text2text-generation", model="google/flan-t5-base", device = device)
输出:
让我们编写一个块矢量化函数
def vectorize_chunks(chunks, tokenizer, model):
tokenized = tokenizer(chunks, add_special_tokens=True, return_token_type_ids=False, padding=True)
input_ids = torch.tensor(tokenized.input_ids)
attention_mask = torch.tensor(tokenized.attention_mask)
model = model.to(device)
last_hidden_states = []
with torch.no_grad():
for i in tqdm(range(0, len(input_ids), 100)):
tmp1 = input_ids[i:i+100].to(device)
tmp2 = attention_mask[i:i+100].to(device)
last_hidden_states.append(model(tmp1, attention_mask=tmp2).pooler_output.detach().cpu())
features = torch.cat(last_hidden_states, dim=0)
print(f"Done\nShape of features array: {features.shape}")
return features
以及问题的矢量化
def vectorize_question(question, q_tokenizer, q_model):
q_tokenized = q_tokenizer(question, add_special_tokens=True, return_token_type_ids=False)
id = torch.tensor([q_tokenized.input_ids])
mask = torch.tensor([q_tokenized.attention_mask])
outp = q_model(id, attention_mask=mask).pooler_output.detach()
return outp[0]
还有一个搜索附近区块的功能
def find_nearest_chunks(features, question, n_neighbors=5):
features = features.numpy()
nn_model = NearestNeighbors(n_neighbors=n_neighbors, metric="cosine")
nn_model.fit(features)
target_vector = question.reshape(1, -1)
distances, indices = nn_model.kneighbors(target_vector)
return indices[0].tolist()
并使用 LLM 获得有关找到的块的问题的答案:
def answer(question, chunks, features, pipe, NN, q_tokenizer, q_model):
question_vector = vectorize_question(question, q_tokenizer, q_model)
indices = find_nearest_chunks(features, question_vector, n_neighbors=NN)
relevant = [chunks[i] for i in indices]
prompt = "Source: " + " ".join(relevant[:5]) + "\n\nUsing the source answer the question: " + question
answer = pipe(prompt)[0]["generated_text"]
print(f"Q: {question}")
print(f"A: {answer}")
print()
print("Based on:")
for line in relevant:
print(line)
让我们测试一下我们的系统:以一篇英文短文为例——欧内斯特·海明威的小说《印第安营地》。
这个故事很短,我们将逐行将其拆分成多个部分。
text = """
At the lake shore there was another rowboat drawn up. The two Indians stood waiting.
Nick and his father got in the stern of the boat and the Indians shoved it off and one of them got in to row. Uncle George sat in the stern of the camp rowboat. The young Indian shoved the camp boat off and got in to row Uncle George.
The two boats started off in the dark. Nick heard the oar-locks of the other boat quite a way ahead of them in the mist. The Indians rowed with quick choppy strokes. Nick lay back with his father's arm around him. It was cold on the water. The Indian who was rowing them was working very hard, but the other boat moved further ahead in the mist all the time.
"Where are we going, Dad?" Nick asked.
"Over to the Indian camp. There is an Indian lady very sick."
"Oh," said Nick.
Across the bay they found the other boat beached. Uncle George was smoking a cigar in the dark. The young Indian pulled the boat way up the beach. Uncle George gave both the Indians cigars.
They walked up from the beach through a meadow that was soaking wet with dew, follow虹ng the young Indian who carried a lantern. Then they went into the woods and followed a trail that led to the logging road that ran back into the hills. It was much lighter on the logging road as the timber was cut away on both sides. The young Indian stopped and blew out his lantern and they all walked on along the road.
They came around a bend and a dog came out barking. Ahead were the lights of the shanties where the Indian bark-peelers lived. More dogs rushed out at them. The two Indians sent them back to the shanties. In the shanty nearest the road there was a light in the window. An old woman stood in the doorway holding a lamp.
Inside on a wooden bunk lay a young Indian woman. She had been trying to have her baby for two days. All the old women in the camp had been helping her. The men had moved off up the road to sit in the dark and smoke out of range of the noise she made. She screamed just as Nick and the two Indians followed his father and Uncle George into the shanty. She lay in the lower bunk, very big under a quilt. Her head was turned to one side. In the upper bunk was her husband. He had cut his foot very badly with an ax three days before. He was smoking a pipe. The room smelled very bad.
Nick's father ordered some water to be put on the stove, and while it was heating he spoke to Nick.
"This lady is going to have a baby, Nick," he said.
"I know," said Nick.
"You don't know," said his father. "Listen to me. What she is going through is called being in labor. The baby wants to be born and she wants it to be born. All her muscles are trying to get the baby born. That is what is happening when she screams."
"I see," Nick said.
Just then the woman cried out.
"Oh, Daddy, can't you give her something to make her stop screaming?" asked Nick.
"No. I haven't any anæsthetic," his father said. "But her screams are not important. I don't hear them because they are not important."
The husband in the upper bunk rolled over against the wall.
The woman in the kitchen motioned to the doctor that the water was hot. Nick's father went into the kitchen and poured about half of the water out of the big kettle into a basin. Into the water left in the kettle he put several things he unwrapped from a handkerchief.
"Those must boil," he said, and began to scrub his hands in the basin of hot water with a cake of soap he had brought from the camp. Nick watched his father's hands scrubbing each other with the soap. While his father washed his hands very carefully and thoroughly, he talked.
"You see, Nick, babies are supposed to be born head first but sometimes they're not. When they're not they make a lot of trouble for every苑ody. Maybe I'll have to operate on this lady. We'll know in a little while."
When he was satisfied with his hands he went in and went to work.
"Pull back that quilt, will you, George?" he said. "I'd rather not touch it."
Later when he started to operate Uncle George and three Indian men held the woman still. She bit Uncle George on the arm and Uncle George said, "Damn squaw bitch!" and the young Indian who had rowed Uncle George over laughed at him. Nick held the basin for his father. It all took a long time.
His father picked the baby up and slapped it to make it breathe and handed it to the old woman.
"See, it's a boy, Nick," he said. "How do you like being an interne?"
Nick said, "All right." He was looking away so as not to see what his father was doing.
"There. That gets it," said his father and put something into the basin.
Nick didn't look at it.
"Now," his father said, "there's some stitches to put in. You can watch this or not, Nick, just as you like. I'm going to sew up the incision I made."
Nick did not watch. His curiosity has been gone for a long time.
His father finished and stood up. Uncle George and the three Indian men stood up. Nick put the basin out in the kitchen.
Uncle George looked at his arm. The young Indian smiled reminiscently.
"I'll put some peroxide on that, George," the doctor said.
He bent over the Indian woman. She was quiet now and her eyes were closed. She looked very pale. She did not know what had become of the baby or anything.
"I'll be back in the morning," the doctor said, standing up. "The nurse should be here from St. Ignace by noon and she'll bring everything we need."
He was feeling exalted and talkative as football players are in the dressing room after a game.
"That's one for the medical journal, George," he said. "Doing a Caesarian with a jack-knife and sewing it up with nine-foot, tapered gut leaders."
Uncle George was standing against the wall, looking at his arm.
"Oh, you're a great man, all right," he said.
"Ought to have a look at the proud father. They're usually the worst sufferers in these little affairs," the doctor said. "I must say he took it all pretty quietly."
He pulled back the blanket from the Indian's head. His hand came away wet. He mounted on the edge of the lower bunk with the lamp in one hand and looked in. The Indian lay with his face toward the wall. His throat had been cut from ear to ear. The blood had flowed down into a pool where his body sagged the bunk. His head rested on his left arm. The open razor lay, edge up, in the blankets.
"Take Nick out of the shanty, George," the doctor said.
There was no need of that. Nick, standing in the door of the kitchen, had a good view of the upper bunk when his father, the lamp in one hand, tipped the Indian's head back.
It was just beginning to be daylight when they walked along the logging road back toward the lake.
"I'm terribly sorry I brought you along, Nickie," said his father, all his post-operative exhilaration gone. "It was an awful mess to put you through."
"Do ladies always have such a hard time hav虹ng babies?" Nick asked.
"No, that was very, very exceptional."
"Why did he kill himself, Daddy?"
"I don't know, Nick. He couldn't stand things, I guess."
"Do many men kill themselves, Daddy?"
"Not very many, Nick."
"Do many women?"
"Hardly ever."
"Don't they ever?"
"Oh, yes. They do sometimes."
"Daddy?"
"Yes."
"Where did Uncle George go?"
"He'll turn up all right."
"Is dying hard, Daddy?"
"No, I think it's pretty easy, Nick. It all depends."
They were seated in the boat, Nick in the stern, his father rowing. The sun was coming up over the hills. A bass jumped, making a circle in the water. Nick trailed his hand in the water. It felt warm in the sharp chill of the morning.
In the early morning on the lake sitting in the stern of the boat with his father rowing, he felt quite sure that he would never die.
"""
chunks = [line for line in text.split('\n')]
not_empty_chunks = chunks[1::2]
vectorized_chunks = vectorize_chunks(not_empty_chunks, tokenizer, model)
输出:

让我们设置搜索超参数并尝试根据文本找到某些特定问题的答案:
NN = 3
question = "How many indians stood waiting?"
answer(question, not_empty_chunks, vectorized_chunks, pipe, NN, q_tokenizer, q_model)
输出:

question = "On what young Indian woman laid?"
answer(question, not_empty_chunks, vectorized_chunks, pipe, NN, q_tokenizer, q_model)
输出:

因此,我们建立了一个有效的系统,能够对有关文本的问题提供有意义的、合理的答案。


















 3610
3610

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











