







概念简述
聚类是什么呢?我们都听说过“物以类聚”,即把“志同道合”的 数据分到一起归为一类,不同类之间在”志向“上具有较大分歧。举个栗子,茫茫人生中,我们普通大众会被God根据缘分进行聚类,缘分好的话,会成为朋友,甚至成为了可以互诉衷肠,”余生请指教“的男女盘友,那缘分不好的应该是一生从未谋面或者一面之缘或者是如《再见前任3》中那样成为了最熟悉的陌生人…好像扯远了。
言归正传,用标准的普通话来说,聚类是将数据集中的样本划分为若干个通常是不相交的子集,每个子集成为一个“簇”,用正规的外星人语言来说,对于样本
D={x1,x2,...,xm}
D
=
{
x
1
,
x
2
,
.
.
.
,
x
m
}
包含
m
m
个无标记样本,每个样本是一个
n
n
维特征向量,则聚类算法将样本集划分为
k
k
个不相交的簇,其中
Cl′∩l′≠lCl=∅
C
l
′
∩
l
′
≠
l
C
l
=
∅
且
D=∪kl=1Cl
D
=
∪
l
=
1
k
C
l
,相应地,用
λj∈{1,2,...,k}
λ
j
∈
{
1
,
2
,
.
.
.
,
k
}
表示样本
xj
x
j
的“簇标记”,即
xj∈Cλj
x
j
∈
C
λ
j
。于是聚类的结果可用包含m个元素的簇标记,记向量
λ=(λ1;λ2;...;λm)
λ
=
(
λ
1
;
λ
2
;
.
.
.
;
λ
m
)
。举个栗子,对于具有
10
10
个样本的数据集
D
D
,其中每个样本含有
2
2
维特征,分成类的结果如下:
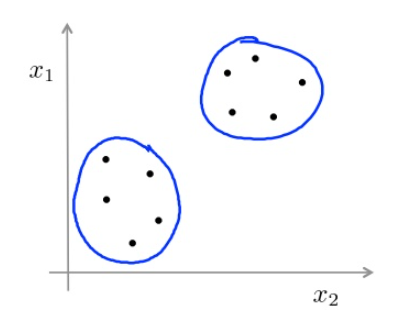
聚类通常用来对无标记训练样本的学习来揭示数据内在性质及规律,为进一步的数据分析提供基础,是“无监督学习”中应用最广的研究方法。那么问题来了,如何衡量聚类结果的好坏呢?按照什么样的“缘分”分类呢?官方的话来说聚类有哪些性能度量以及距离计算方法。
性能度量
我们通常按照一个标准来分析聚类之后的结果,简单来说这个标准是“簇内相似度高,簇间相似度低”,下面我们用一堆“指数”,“系数”来数学化引号里面的内容,权当填补那些好奇心强盛的孩纸们…
性能度量分类:
聚类性能度量的主要分为两类,一类是将聚类结果与某个“参考模型”进行比较,成为“外部指标”;另一类是直接考察聚类结果而不用任何参考模型,成为“内部指标”。
- 外部指标
“外部指标”通常有Jaccard系数(Jaccard Coefficient,简称JC)、FM系数(Fowlkes and Mallows Index,简称FMI)、Rand指数(Rand Index,简称RI)。
- JC:
JC=aa+b+c(1.1) (1.1) J C = a a + b + c - FMI:
FMI=aa+b⋅aa+c−−−−−−−−−−−√(1.2) (1.2) F M I = a a + b ⋅ a a + c - RI
RI=2(a+d))m(m−1)(1.3) (1.3) RI = 2 ( a + d ) ) m ( m − 1 )
假设,数据集 D={x1,x2,...,xm} D = { x 1 , x 2 , . . . , x m } ,经过聚类后得到的簇划分为 C={C1,C2,...,Cs} C = { C 1 , C 2 , . . . , C s } ,参考模型给出的簇划分 C∗={C∗1,C∗2,...,C∗s} C ∗ = { C 1 ∗ , C 2 ∗ , . . . , C s ∗ } ,相应的,令 λ λ 和 λ∗ λ ∗ 分别表示与 C C 和对应的簇标记向量,于是 a、b、c、d a 、 b 、 c 、 d 定义如下:
a=|SS|,SS={(xi,xj)|λi=λj,λ∗i=λ∗j,i<j}(1.4) (1.4) a = | S S | , S S = { ( x i , x j ) | λ i = λ j , λ i ∗ = λ j ∗ , i < j }
b=|SD|,SD={(xi,xj)|λi=λj,λ∗i≠λ∗j,i<j}(1.5) (1.5) b = | S D | , S D = { ( x i , x j ) | λ i = λ j , λ i ∗ ≠ λ j ∗ , i < j }
c=|DS|,DS={(xi,xj)|λi≠λj,λ∗i=λ∗j,i<j}(1.6) (1.6) c = | D S | , D S = { ( x i , x j ) | λ i ≠ λ j , λ i ∗ = λ j ∗ , i < j }
d=|DD|,DD={(xi,xj)|λi≠λj,λ∗i≠λ∗j,i<j}(1.7) (1.7) d = | D D | , D D = { ( x i , x j ) | λ i ≠ λ j , λ i ∗ ≠ λ j ∗ , i < j }
从上述表达式可知,集合 SS S S 包含了在 C C 中隶属于相同簇且在中也隶属于相同簇的样本对,集合 SD S D 包含了在 C C 中隶属于相同簇但在中隶属于不同簇的样本,集合 DS D S 包含了在 C C 中隶属于不同簇但在中隶属于相同簇的样本,集合 DD D D 包含了在 C C 中隶属于不同簇且在中隶属不同簇的样本,由于每个样本对 (xi,xj)(i<j) ( x i , x j ) ( i < j ) 仅能出现在一个集合中,因此有 a+b+c+d=m(m−1)/2 a + b + c + d = m ( m − 1 ) / 2 成立。显然,上述性能度量的结果值均在 [0,1] [ 0 , 1 ] 区间,值越大越好。
2.内部指标
常用的内部指标有DB指数(Davies-Bouldin Index,简称DBI)和Dunn指数(Dunn Index,简称DI)。
- DB:
DBI=1k∑i=1kmaxj≠i(avg(Ci)+avg(Cj)dcen(μi,μj))(2.1) (2.1) D B I = 1 k ∑ i = 1 k m a x j ≠ i ( a v g ( C i ) + a v g ( C j ) d c e n ( μ i , μ j ) ) - DI:
DI=min1≤i≤k{minj≠i(dmin(Ci,Cj)max1≤l≤kdiam(Cl))}(2.2) (2.2) D I = m i n 1 ≤ i ≤ k { m i n j ≠ i ( d m i n ( C i , C j ) m a x 1 ≤ l ≤ k d i a m ( C l ) ) }
其中:
avg(C)=2|C|(|C|−1)∑1≤i<j≤|C|dist(xi,xj)(2.3) (2.3) a v g ( C ) = 2 | C | ( | C | − 1 ) ∑ 1 ≤ i < j ≤ | C | d i s t ( x i , x j )
diam(C)=maxx1≤i<j≤|C|dist(xi,xj)(2.4) (2.4) d i a m ( C ) = m a x x 1 ≤ i < j ≤ | C | d i s t ( x i , x j )
dmin(Ci,Cj)=minxi∈Ci,xj∈Cjdist(xi,xj)(2.5) (2.5) d m i n ( C i , C j ) = m i n x i ∈ C i , x j ∈ C j d i s t ( x i , x j )
dcen(Ci,Cj)=dist(μi,μj)(2.6) (2.6) d c e n ( C i , C j ) = d i s t ( μ i , μ j )
注意: dist(⋅,⋅) d i s t ( ⋅ , ⋅ ) 用于计算两个样本之间的距离; μ μ 代表簇 C C 的中心点, avg(C) a v g ( C ) 对应于簇 C C 内样本间的平均距离,对应于簇内最远距离, dmin(Ci,Cj) d m i n ( C i , C j ) 代表簇 Ci C i 与簇 Cj C j 内最近样本间的距离, dcen(Ci,Cj) d c e n ( C i , C j ) 代表簇 Ci C i 与簇 Cj C j 中心点的距离。显然 DBI D B I 的值越小越好,而 DI D I 则相反,值越大越好。
- DB:
更多机器学习干货、最新论文解读、AI资讯热点等欢迎关注”AI学院(FAICULTY)”
欢迎加入faiculty机器学习交流qq群:451429116 点此进群
版权声明:可以任意转载,转载时请务必标明文章原始出处和作者信息.
参考文献
[1]. 周志华,机器学习,清华大学出版社,2016















 406
406

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









